Vertex AI Pipelines 是一項代管服務,可協助您在 Google Cloud 平台上建構、部署及管理端對端機器學習工作流程。這個服務提供無伺服器環境來執行管道,因此您不必擔心基礎架構管理問題。
在本教學課程中,您將使用 Vertex AI Pipelines 執行自訂訓練工作,並在混合式網路環境中,於 Vertex AI 部署訓練好的模型。
整個程序需要 2 到 3 個小時才能完成,包括管道執行作業約 50 分鐘。
本教學課程適用於熟悉 Vertex AI、虛擬私有雲 (VPC)、 Google Cloud 控制台和 Cloud Shell 的企業網路管理員、資料科學家和研究人員。熟悉 Vertex AI Workbench 有助於瞭解本課程,但並非必要條件。
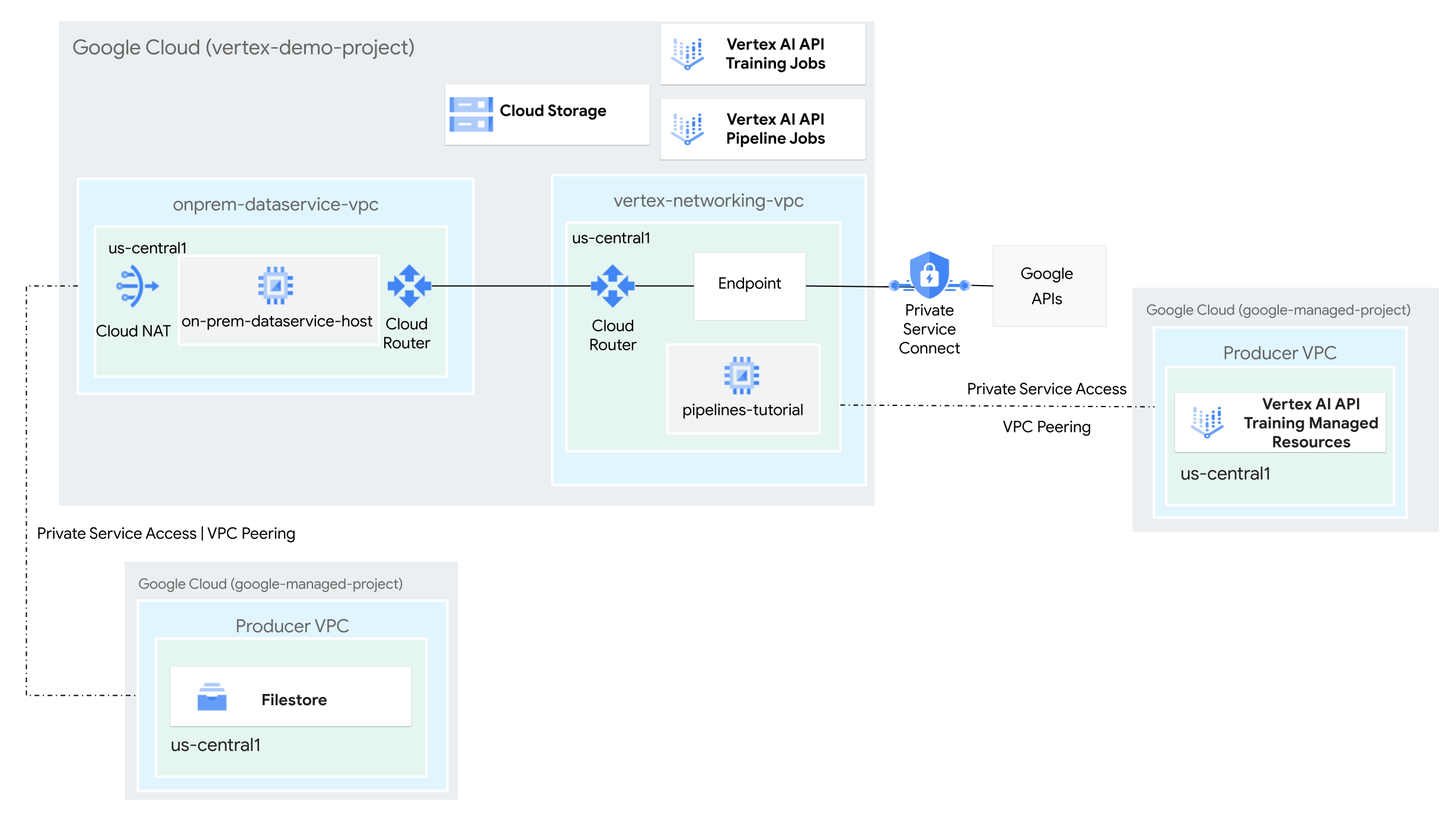
建立虛擬私有雲網路
在本節中,您會建立兩個虛擬私有雲網路:一個用於存取 Vertex AI Pipelines 的 Google API,另一個則用於模擬地端網路。在兩個虛擬私有雲網路中,您會建立 Cloud Router 和 Cloud NAT 閘道。Cloud NAT 閘道可為沒有外部 IP 位址的 Compute Engine 虛擬機器 (VM) 執行個體提供傳出連線。
在 Cloud Shell 中執行下列指令,並將 PROJECT_ID 替換為您的專案 ID:
projectid=PROJECT_ID gcloud config set project ${projectid}建立
vertex-networking-vpc虛擬私有雲網路:gcloud compute networks create vertex-networking-vpc \ --subnet-mode custom在
vertex-networking-vpc網路中,建立名為pipeline-networking-subnet1的子網路,主要 IPv4 範圍為10.0.0.0/24:gcloud compute networks subnets create pipeline-networking-subnet1 \ --range=10.0.0.0/24 \ --network=vertex-networking-vpc \ --region=us-central1 \ --enable-private-ip-google-access建立虛擬私有雲網路,模擬內部部署網路 (
onprem-dataservice-vpc):gcloud compute networks create onprem-dataservice-vpc \ --subnet-mode custom在
onprem-dataservice-vpc網路中,建立名為onprem-dataservice-vpc-subnet1的子網路,主要 IPv4 範圍為172.16.10.0/24:gcloud compute networks subnets create onprem-dataservice-vpc-subnet1 \ --network onprem-dataservice-vpc \ --range 172.16.10.0/24 \ --region us-central1 \ --enable-private-ip-google-access
確認虛擬私有雲網路設定正確無誤
在 Google Cloud 控制台中,前往「VPC networks」(虛擬私有雲網路) 頁面的「Networks in current project」(目前專案中的網路) 分頁。
在虛擬私有雲網路清單中,確認已建立兩個網路:
vertex-networking-vpc和onprem-dataservice-vpc。按一下「目前專案中的子網路」分頁。
在虛擬私有雲子網路清單中,確認已建立
pipeline-networking-subnet1和onprem-dataservice-vpc-subnet1子網路。
設定混合式連線
在本節中,您將建立兩個互相連線的高可用性 VPN 閘道。其中一個位於 vertex-networking-vpc 虛擬私有雲網路。另一個則位於 onprem-dataservice-vpc 虛擬私有雲網路。每個閘道都包含 Cloud Router 和一對 VPN 通道。
建立高可用性 VPN 閘道
在 Cloud Shell 中,為
vertex-networking-vpc虛擬私有雲網路建立高可用性 VPN 閘道:gcloud compute vpn-gateways create vertex-networking-vpn-gw1 \ --network vertex-networking-vpc \ --region us-central1為
onprem-dataservice-vpc虛擬私有雲網路建立高可用性 VPN 閘道:gcloud compute vpn-gateways create onprem-vpn-gw1 \ --network onprem-dataservice-vpc \ --region us-central1在 Google Cloud 控制台中,前往「VPN」頁面的「Cloud VPN Gateways」(Cloud VPN 閘道) 分頁標籤。
確認已建立兩個閘道 (
vertex-networking-vpn-gw1和onprem-vpn-gw1),且每個閘道都有兩個介面 IP 位址。
建立 Cloud Router 和 Cloud NAT 閘道
在兩個虛擬私有雲網路中,您會建立兩個 Cloud Router:一個用於 Cloud NAT,另一個則用於管理高可用性 VPN 的 BGP 工作階段。
在 Cloud Shell 中,為將用於 VPN 的
vertex-networking-vpc虛擬私有雲網路建立 Cloud Router:gcloud compute routers create vertex-networking-vpc-router1 \ --region us-central1 \ --network vertex-networking-vpc \ --asn 65001為用於 VPN 的
onprem-dataservice-vpcVPC 網路建立 Cloud Router:gcloud compute routers create onprem-dataservice-vpc-router1 \ --region us-central1 \ --network onprem-dataservice-vpc \ --asn 65002為 Cloud NAT 使用的
vertex-networking-vpc虛擬私有雲網路建立 Cloud Router:gcloud compute routers create cloud-router-us-central1-vertex-nat \ --network vertex-networking-vpc \ --region us-central1在 Cloud Router 上設定 Cloud NAT 閘道:
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-vertex-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1為 Cloud NAT 使用的
onprem-dataservice-vpcVPC 網路建立 Cloud Router:gcloud compute routers create cloud-router-us-central1-onprem-nat \ --network onprem-dataservice-vpc \ --region us-central1在 Cloud Router 上設定 Cloud NAT 閘道:
gcloud compute routers nats create cloud-nat-us-central1-on-prem \ --router=cloud-router-us-central1-onprem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1前往 Google Cloud 控制台的「Cloud Routers」頁面。
在「Cloud Routers」清單中,確認已建立下列路由器:
cloud-router-us-central1-onprem-natcloud-router-us-central1-vertex-natonprem-dataservice-vpc-router1vertex-networking-vpc-router1
您可能需要重新整理 Google Cloud 控制台瀏覽器分頁,才能看到新值。
在 Cloud Router 清單中,按一下
cloud-router-us-central1-vertex-nat。在「路由器詳細資料」頁面中,確認已建立
cloud-nat-us-central1Cloud NAT 閘道。按一下 返回箭頭,返回「Cloud Routers」頁面。
在 Cloud Router 清單中,按一下
cloud-router-us-central1-onprem-nat。在「路由器詳細資料」頁面中,確認已建立
cloud-nat-us-central1-on-premCloud NAT 閘道。
建立 VPN 通道
在 Cloud Shell 中,於
vertex-networking-vpc網路中建立名為vertex-networking-vpc-tunnel0的 VPN 通道:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel0 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 0在
vertex-networking-vpc網路中,建立名為vertex-networking-vpc-tunnel1的 VPN 通道:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel1 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 1在
onprem-dataservice-vpc網路中,建立名為onprem-dataservice-vpc-tunnel0的 VPN 通道:gcloud compute vpn-tunnels create onprem-dataservice-vpc-tunnel0 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router onprem-dataservice-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 0在
onprem-dataservice-vpc網路中,建立名為onprem-dataservice-vpc-tunnel1的 VPN 通道:gcloud compute vpn-tunnels create onprem-dataservice-vpc-tunnel1 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router onprem-dataservice-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 1前往 Google Cloud 控制台的「VPN」VPN頁面。
在 VPN 通道清單中,確認已建立四個 VPN 通道。
建立 BGP 工作階段
Cloud Router 會透過邊界閘道通訊協定 (BGP),在 VPC 網路 (本例中為 vertex-networking-vpc) 和地端部署網路 (以 onprem-dataservice-vpc 表示) 之間交換路徑。在 Cloud Router 上,您會為地端部署路由器設定介面和 BGP 對等互連。這個介面和 BGP 對等點設定組合起來,就會形成 BGP 工作階段。在本節中,您將為 vertex-networking-vpc 建立兩個 BGP 工作階段,並為 onprem-dataservice-vpc 建立兩個 BGP 工作階段。
設定路由器之間的介面和 BGP 對等互連後,路由器就會自動開始交換路徑。
為「vertex-networking-vpc」建立 BGP 工作階段
在 Cloud Shell 中,於
vertex-networking-vpc網路中為vertex-networking-vpc-tunnel0建立 BGP 介面:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.0.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel0 \ --region us-central1在
vertex-networking-vpc網路中,為bgp-onprem-tunnel0建立 BGP 對等點:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel0 \ --interface if-tunnel0-to-onprem \ --peer-ip-address 169.254.0.2 \ --peer-asn 65002 \ --region us-central1在
vertex-networking-vpc網路中,為vertex-networking-vpc-tunnel1建立 BGP 介面:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel1 \ --region us-central1在
vertex-networking-vpc網路中,為bgp-onprem-tunnel1建立 BGP 對等點:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel1 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central1
為「onprem-dataservice-vpc」建立 BGP 工作階段
在
onprem-dataservice-vpc網路中,為onprem-dataservice-vpc-tunnel0建立 BGP 介面:gcloud compute routers add-interface onprem-dataservice-vpc-router1 \ --interface-name if-tunnel0-to-vertex-networking-vpc \ --ip-address 169.254.0.2 \ --mask-length 30 \ --vpn-tunnel onprem-dataservice-vpc-tunnel0 \ --region us-central1在
onprem-dataservice-vpc網路中,為bgp-vertex-networking-vpc-tunnel0建立 BGP 對等點:gcloud compute routers add-bgp-peer onprem-dataservice-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel0 \ --interface if-tunnel0-to-vertex-networking-vpc \ --peer-ip-address 169.254.0.1 \ --peer-asn 65001 \ --region us-central1在
onprem-dataservice-vpc網路中,為onprem-dataservice-vpc-tunnel1建立 BGP 介面:gcloud compute routers add-interface onprem-dataservice-vpc-router1 \ --interface-name if-tunnel1-to-vertex-networking-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel onprem-dataservice-vpc-tunnel1 \ --region us-central1在
onprem-dataservice-vpc網路中,為bgp-vertex-networking-vpc-tunnel1建立 BGP 對等點:gcloud compute routers add-bgp-peer onprem-dataservice-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel1 \ --interface if-tunnel1-to-vertex-networking-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central1
驗證 BGP 工作階段建立作業
前往 Google Cloud 控制台的「VPN」VPN頁面。
在 VPN 通道清單中,確認每個通道的「BGP 工作階段狀態」欄值已從「設定 BGP 工作階段」變更為「已建立 BGP」。您可能需要重新整理 Google Cloud 控制台瀏覽器分頁,才能看到新值。
驗證onprem-dataservice-vpc已知的路徑
在 Google Cloud 控制台中,前往「VPC networks」(虛擬私有雲網路) 頁面。
在虛擬私有雲網路清單中,按一下
onprem-dataservice-vpc。按一下「Routes」(路徑) 分頁標籤。
在「Region」(區域) 清單中選取「us-central1 (Iowa)」(us-central1 (愛荷華州)),然後按一下「View」(查看)。
在「目的地 IP 範圍」欄中,確認
pipeline-networking-subnet1子網路 IP 範圍 (10.0.0.0/24) 出現兩次。您可能需要重新整理 Google Cloud 控制台瀏覽器分頁,才能看到這兩個項目。
驗證vertex-networking-vpc已知的路徑
按一下返回箭頭,返回「VPC 網路」頁面。
在虛擬私有雲網路清單中,按一下
vertex-networking-vpc。按一下「Routes」(路徑) 分頁標籤。
在「Region」(區域) 清單中選取「us-central1 (Iowa)」(us-central1 (愛荷華州)),然後按一下「View」(查看)。
在「Destination IP range」(目的地 IP 範圍) 欄中,確認子網路的 IP 範圍 (
172.16.10.0/24) 顯示兩次。onprem-dataservice-vpc-subnet1
為 Google API 建立 Private Service Connect 端點
在本節中,您將為 Google API 建立 Private Service Connect 端點,用於從內部部署網路存取 Vertex AI Pipelines REST API。
在 Cloud Shell 中,預留用於存取 Google API 的消費者端點 IP 位址:
gcloud compute addresses create psc-googleapi-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=192.168.0.1 \ --network=vertex-networking-vpc建立轉送規則,將端點連線至 Google API 和服務。
gcloud compute forwarding-rules create pscvertex \ --global \ --network=vertex-networking-vpc \ --address=psc-googleapi-ip \ --target-google-apis-bundle=all-apis
為「vertex-networking-vpc」建立自訂路徑通告
在本節中,您將為 vertex-networking-vpc-router1 (vertex-networking-vpc 的 Cloud Router) 建立自訂路徑通告,將 PSC 端點的 IP 位址通告至 onprem-dataservice-vpc 虛擬私有雲網路。
前往 Google Cloud 控制台的「Cloud Routers」頁面。
在 Cloud Router 清單中,按一下
vertex-networking-vpc-router1。在「路由器詳細資料」頁面中,按一下「編輯」。
在「公告路徑」區段中,選取「路徑」的「建立自訂路徑」。
選取「公告 Cloud Router 可使用的所有子網路」核取方塊,繼續公告 Cloud Router 可用的子網路。啟用這個選項後,即可模擬預設通告模式下的 Cloud Router 行為。
按一下「新增自訂路徑」。
在「來源」中選取「自訂 IP 範圍」。
在「IP address range」(IP 位址範圍) 中,輸入下列 IP 位址:
192.168.0.1在「說明」中輸入下列文字:
Custom route to advertise Private Service Connect endpoint IP address依序按一下 [完成] 及 [儲存]。
驗證 onprem-dataservice-vpc 是否已瞭解通告路徑
前往 Google Cloud 控制台的「Routes」(路徑) 頁面。
在「有效路徑」分頁中,執行下列操作:
- 在「Network」(網路) 中選擇
onprem-dataservice-vpc。 - 在「區域」部分,選擇
us-central1 (Iowa)。 - 點按「查看」。
在路徑清單中,確認有兩個名稱開頭為
onprem-dataservice-vpc-router1-bgp-vertex-networking-vpc-tunnel0的項目,以及兩個名稱開頭為onprem-dataservice-vpc-router1-bgp-vertex-networking-vpc-tunnel1的項目。如果這些項目沒有立即顯示,請稍候幾分鐘,然後重新整理 Google Cloud 控制台瀏覽器分頁。
確認其中兩項的「目的地 IP 範圍」為
192.168.0.1/32,另外兩項的「目的地 IP 範圍」為10.0.0.0/24。
- 在「Network」(網路) 中選擇
在 onprem-dataservice-vpc 中建立 VM 執行個體
在本節中,您將建立 VM 執行個體,模擬地端資料服務主機。根據 Compute Engine 和 IAM 最佳做法,這個 VM 使用的是使用者管理的服務帳戶,而非 Compute Engine 預設服務帳戶。
為 VM 執行個體建立使用者管理的服務帳戶
在 Cloud Shell 中執行下列指令,並將 PROJECT_ID 替換為您的專案 ID:
projectid=PROJECT_ID gcloud config set project ${projectid}建立名為
onprem-user-managed-sa的服務帳戶:gcloud iam service-accounts create onprem-user-managed-sa \ --display-name="onprem-user-managed-sa"將 Vertex AI 使用者 (
roles/aiplatform.user) 角色指派給服務帳戶:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"指派 Vertex AI 檢視者 (
roles/aiplatform.viewer) 角色:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.viewer"指派 Filestore 編輯者 (
roles/file.editor) 角色:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/file.editor"指派服務帳戶管理員 (
roles/iam.serviceAccountAdmin) 角色:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/iam.serviceAccountAdmin"指派「服務帳戶使用者 (
roles/iam.serviceAccountUser)」角色:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/iam.serviceAccountUser"指派 Artifact Registry Reader (
roles/artifactregistry.reader) 角色:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.reader"指派「Storage 物件管理員 (
roles/storage.objectAdmin)」角色:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.objectAdmin"指派「Logging 管理員 (
roles/logging.admin)」角色:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/logging.admin"
建立 on-prem-dataservice-host VM 執行個體
您建立的 VM 執行個體沒有外部 IP 位址,且不允許直接透過網際網路存取。如要啟用 VM 的管理員存取權,請使用 Identity-Aware Proxy (IAP) TCP 轉送功能。
在 Cloud Shell 中,建立
on-prem-dataservice-hostVM 執行個體:gcloud compute instances create on-prem-dataservice-host \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=onprem-dataservice-vpc-subnet1 \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --shielded-secure-boot \ --service-account=onprem-user-managed-sa@$projectid.iam.gserviceaccount.com \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"建立防火牆規則,允許 IAP 連線至 VM 執行個體:
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network onprem-dataservice-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
更新 /etc/hosts 檔案,指向 PSC 端點
在本節中,您會在 /etc/hosts 檔案中新增一行,導致傳送至公開服務端點 (us-central1-aiplatform.googleapis.com) 的要求重新導向至 PSC 端點 (192.168.0.1)。
在 Cloud Shell 中,使用 IAP 登入
on-prem-dataservice-hostVM 執行個體:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iap在
on-prem-dataservice-hostVM 執行個體中,使用vim或nano等文字編輯器開啟/etc/hosts檔案,例如:sudo vim /etc/hosts在檔案中新增下列這行文字:
192.168.0.1 us-central1-aiplatform.googleapis.com這行會將 PSC 端點的 IP 位址 (
192.168.0.1) 指派給 Vertex AI Google API 的完整網域名稱 (us-central1-aiplatform.googleapis.com)。編輯後的檔案應如下所示:
127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 192.168.0.1 us-central1-aiplatform.googleapis.com # Added by you 172.16.10.6 on-prem-dataservice-host.us-central1-a.c.PROJECT_ID.internal on-prem-dataservice-host # Added by Google 169.254.169.254 metadata.google.internal # Added by Google按照下列方式儲存檔案:
- 如果使用
vim,請按下Esc鍵,然後輸入:wq儲存檔案並結束。 - 如果使用
nano,請輸入Control+O並按下Enter儲存檔案,然後輸入Control+X結束。
- 如果使用
按照下列方式 Ping Vertex AI API 端點:
ping us-central1-aiplatform.googleapis.comping指令應傳回下列輸出內容。192.168.0.1是 PSC 端點 IP 位址:PING us-central1-aiplatform.googleapis.com (192.168.0.1) 56(84) bytes of data.輸入
Control+C即可退出ping。輸入
exit即可退出on-prem-dataservice-hostVM 執行個體,並返回 Cloud Shell 提示。
設定 Filestore 執行個體的網路
在本節中,您要為虛擬私有雲網路啟用私人服務存取權,為建立 Filestore 執行個體並將其掛接為網路檔案系統 (NFS) 共用區做準備。如要瞭解本節和下一節的操作內容,請參閱「掛接 NFS 共用資料夾以進行自訂訓練」和「設定 VPC 網路對等互連」。
在虛擬私有雲網路中啟用私人服務連線
在本節中,您會建立 Service Networking 連線,並透過虛擬私有雲網路對等互連,使用該連線啟用虛擬私有雲網路的私人服務存取權。onprem-dataservice-vpc
在 Cloud Shell 中,使用
gcloud compute addresses create設定保留的 IP 位址範圍:gcloud compute addresses create filestore-subnet \ --global \ --purpose=VPC_PEERING \ --addresses=10.243.208.0 \ --prefix-length=24 \ --description="filestore subnet" \ --network=onprem-dataservice-vpc使用
gcloud services vpc-peerings connect,在虛擬私有雲網路與 Google 的 Service Networking 之間建立對等互連連線:onprem-dataservice-vpcgcloud services vpc-peerings connect \ --service=servicenetworking.googleapis.com \ --ranges=filestore-subnet \ --network=onprem-dataservice-vpc更新虛擬私有雲網路對等互連,啟用匯入及匯出自訂學習路徑:
gcloud compute networks peerings update servicenetworking-googleapis-com \ --network=onprem-dataservice-vpc \ --import-custom-routes \ --export-custom-routes在 Google Cloud 控制台中,前往「VPC network peering」(VPC 網路對等互連) 頁面。
在虛擬私有雲對等互連清單中,確認 和
onprem-dataservice-vpc虛擬私有雲網路之間有對等互連項目。servicenetworking.googleapis.com
為「filestore-subnet」建立自訂路徑通告
前往 Google Cloud 控制台的「Cloud Routers」頁面。
在 Cloud Router 清單中,按一下
onprem-dataservice-vpc-router1。在「路由器詳細資料」頁面中,按一下「編輯」。
在「公告路徑」區段中,選取「路徑」的「建立自訂路徑」。
選取「公告 Cloud Router 可使用的所有子網路」核取方塊,繼續公告 Cloud Router 可用的子網路。啟用這個選項後,即可模擬預設通告模式下的 Cloud Router 行為。
按一下「新增自訂路徑」。
在「來源」中選取「自訂 IP 範圍」。
在「IP address range」(IP 位址範圍) 中,輸入下列 IP 位址範圍:
10.243.208.0/24在「說明」中輸入下列文字:
Filestore reserved IP address range依序按一下 [完成] 及 [儲存]。
在 onprem-dataservice-vpc 網路中建立 Filestore 執行個體
為虛擬私有雲網路啟用私人服務存取權後,請建立 Filestore 執行個體,並將該執行個體掛接為自訂訓練作業的 NFS 共用區。這樣一來,訓練工作就能存取遠端檔案,就像存取本機檔案一樣,進而實現高總處理量和低延遲。
建立 Filestore 執行個體
前往 Google Cloud 控制台的「Filestore Instances」(Filestore 執行個體) 頁面。
按一下「建立執行個體」,然後按照下列方式設定執行個體:
將「Instance ID」(執行個體 ID) 設為下列值:
image-data-instance將「Instance type」(執行個體類型) 設定為「Basic」(基本)。
將「儲存空間類型」設為「HDD」。
將「Allocate capacity」(分配容量) 設為 1
TiB。將「Region」(地區) 設為 us-central1,「Zone」(區域) 設為 us-central1-c。
將「VPC network」(虛擬私有雲網路) 設為
onprem-dataservice-vpc。將「已分配的 IP 範圍」設為「使用已分配的現有 IP 範圍」,然後選擇
filestore-subnet。將「File share name」(檔案共用區名稱) 設為下列項目:
vol1將「存取控制」設為「為虛擬私有雲網路中的所有用戶端授予存取權限」。
點選「建立」。
記下新 Filestore 執行個體的 IP 位址。您可能需要重新整理控制台瀏覽器分頁,才能看到新執行個體。 Google Cloud
掛接 Filestore 檔案共用區
在 Cloud Shell 中執行下列指令,並將 PROJECT_ID 替換為您的專案 ID:
projectid=PROJECT_ID gcloud config set project ${projectid}登入
on-prem-dataservice-hostVM 執行個體:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iap在 VM 執行個體上安裝 NFS 套件:
sudo apt-get update -y sudo apt-get -y install nfs-common為 Filestore 檔案共用區建立掛接目錄:
sudo mkdir -p /mnt/nfs掛接檔案共用區,並將 FILESTORE_INSTANCE_IP 替換為 Filestore 執行個體的 IP 位址:
sudo mount FILESTORE_INSTANCE_IP:/vol1 /mnt/nfs如果連線逾時,請檢查您是否提供 Filestore 執行個體的正確 IP 位址。
執行下列指令,確認 NFS 掛接作業是否成功:
df -h確認結果中顯示
/mnt/nfs檔案共用:Filesystem Size Used Avail Use% Mounted on udev 1.8G 0 1.8G 0% /dev tmpfs 368M 396K 368M 1% /run /dev/sda1 9.7G 1.9G 7.3G 21% / tmpfs 1.8G 0 1.8G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock /dev/sda15 124M 11M 114M 9% /boot/efi tmpfs 368M 0 368M 0% /run/user 10.243.208.2:/vol1 1007G 0 956G 0% /mnt/nfs變更設定,開放檔案共用區的存取權限:
sudo chmod go+rw /mnt/nfs
將資料集下載到檔案共用區
在
on-prem-dataservice-hostVM 執行個體中,將資料集下載至檔案共用區:gcloud storage cp gs://cloud-samples-data/vertex-ai/dataset-management/datasets/fungi_dataset /mnt/nfs/ --recursive下載作業需要幾分鐘才能完成。
執行下列指令,確認資料集是否已成功複製:
sudo du -sh /mnt/nfs預期的輸出內容如下:
104M /mnt/nfs輸入
exit即可退出on-prem-dataservice-hostVM 執行個體,並返回 Cloud Shell 提示。
為管道建立暫存 bucket
Vertex AI Pipelines 會使用 Cloud Storage 儲存管道執行的構件。執行管道前,您需要建立 Cloud Storage 值區,做為管道執行的暫存區。
在 Cloud Shell 中,建立 Cloud Storage bucket:
gcloud storage buckets create gs://pipelines-staging-bucket-$projectid --location=us-central1
為 Vertex AI Workbench 建立使用者管理的服務帳戶
在 Cloud Shell 中建立服務帳戶:
gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"將 Vertex AI 使用者 (
roles/aiplatform.user) 角色指派給服務帳戶:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"指派 Artifact Registry 管理員 (
artifactregistry.admin) 角色:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.admin"指派「Storage 管理員 (
storage.admin)」角色:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.admin"
建立 Python 訓練應用程式
在本節中,您將建立 Vertex AI Workbench 執行個體,並使用該執行個體建立 Python 自訂訓練應用程式套件。
建立 Vertex AI Workbench 執行個體
前往 Google Cloud 控制台的「Vertex AI Workbench」頁面,然後點選「Instances」分頁標籤。
依序點選「建立新項目」和「進階選項」。
「New instance」(新增執行個體) 頁面隨即開啟。
在「New instance」(新增執行個體) 頁面的「Details」(詳細資料) 區段中,為新執行個體提供下列資訊,然後按一下「Continue」(繼續):
名稱:輸入下列內容,並將 PROJECT_ID 替換為專案 ID:
pipeline-tutorial-PROJECT_ID地區:選取 us-central1。
區域:選取 us-central1-a。
取消勾選「Enable Dataproc Serverless Interactive Sessions」(啟用 Dataproc Serverless 互動工作階段) 核取方塊。
在「環境」部分中,按一下「繼續」。
在「Machine type」(機器類型) 區段中,提供下列資訊,然後按一下「Continue」(繼續):
- 機器類型:選擇「N1」,然後從「機器類型」選單中選取
n1-standard-4。 受防護的 VM:勾選下列核取方塊:
- 安全啟動
- 虛擬信任平台模組 (vTPM)
- 完整性監控
- 機器類型:選擇「N1」,然後從「機器類型」選單中選取
在「Disks」(磁碟) 區段中,確認已選取 Google-managed encryption key,然後按一下「Continue」(繼續):
在「Networking」(網路) 專區中,提供下列資訊,然後按一下「Continue」(繼續):
網路:選取「這項專案中的網路」,然後完成下列步驟:
在「Network」(網路) 欄位中,選取「vertex-networking-vpc」。
在「Subnetwork」(子網路) 欄位中,選取「pipeline-networking-subnet1」。
取消勾選「指派外部 IP 位址」核取方塊。不指派外部 IP 位址可防止執行個體接收來自網際網路或其他虛擬私有雲網路的未經要求通訊。
勾選「允許 Proxy 存取」核取方塊。
在「IAM and security」(IAM 和安全性) 部分中,提供下列資訊,然後按一下「繼續」:
IAM 和安全性:如要將執行個體 JupyterLab 介面的存取權授予單一使用者,請完成下列步驟:
- 選取 [服務帳戶]。
- 取消勾選「使用 Compute Engine 的預設服務帳戶」核取方塊。
這個步驟非常重要,因為 Compute Engine 預設服務帳戶 (以及您剛才指定的單一使用者) 可能具有專案的「編輯者」角色 (
roles/editor)。 在「Service account email」(服務帳戶電子郵件地址) 欄位中輸入下列內容,並將 PROJECT_ID 替換為專案 ID:
workbench-sa@PROJECT_ID.iam.gserviceaccount.com(這是您先前建立的自訂服務帳戶電子郵件地址)。這個服務帳戶的權限有限。
如要進一步瞭解如何授予存取權,請參閱「管理 Vertex AI Workbench 執行個體 JupyterLab 介面的存取權」。
安全性選項:取消勾選下列核取方塊:
- 執行個體的根目錄存取權
勾選下列核取方塊:
- nbconvert:
nbconvert可讓使用者匯出筆記本檔案,並下載為其他檔案類型,例如 HTML、PDF 或 LaTeX。Google Cloud Generative AI GitHub 存放區中的部分筆記本需要這項設定。
取消勾選下列核取方塊:
- 下載檔案
除非您位於正式環境,否則請選取下列核取方塊:
- 終端機存取權:從 JupyterLab 使用者介面內啟用執行個體的終端機存取權。
在「系統健康狀態」部分中,清除「環境自動升級」,並提供下列資訊:
在「報表」中,勾選下列核取方塊:
- 回報系統健康狀態
- 向 Cloud Monitoring 回報自訂指標
- 安裝 Cloud Monitoring
- 回報所需 Google 網域的 DNS 狀態
按一下「建立」,然後等待幾分鐘,讓系統建立 Vertex AI Workbench 執行個體。
在 Vertex AI Workbench 執行個體中執行訓練應用程式
前往 Google Cloud 控制台的「Vertex AI Workbench」頁面,然後點選「Instances」分頁標籤。
在 Vertex AI Workbench 執行個體名稱 (
pipeline-tutorial-PROJECT_ID) 旁,其中 PROJECT_ID 是專案 ID,按一下「Open JupyterLab」(開啟 JupyterLab)。Vertex AI Workbench 執行個體會在 JupyterLab 中開啟。
依序選取「File」>「New」>「Terminal」。
在 JupyterLab 終端機 (不是 Cloud Shell) 中,為專案定義環境變數。將 PROJECT_ID 替換為您的專案 ID:
projectid=PROJECT_ID建立訓練應用程式的上層目錄 (仍在 JupyterLab 終端機中):
mkdir fungi_training_package mkdir fungi_training_package/trainer在「File Browser」 中,依序按兩下
fungi_training_package資料夾和trainer資料夾。在 「File Browser」中, 在空白檔案清單 (「Name」標題下方) 上按一下滑鼠右鍵,然後選取「New file」。
在新檔案上按一下滑鼠右鍵,然後選取「重新命名檔案」。
將檔案從
untitled.txt重新命名為task.py。按兩下
task.py檔案即可開啟。將下列程式碼複製到
task.py:# Import the libraries import tensorflow as tf from tensorflow.python.client import device_lib import argparse import os import sys # add parser arguments parser = argparse.ArgumentParser() parser.add_argument('--data-dir', dest='dataset_dir', type=str, help='Dir to access dataset.') parser.add_argument('--model-dir', dest='model_dir', default=os.getenv("AIP_MODEL_DIR"), type=str, help='Dir to save the model.') parser.add_argument('--epochs', dest='epochs', default=10, type=int, help='Number of epochs.') parser.add_argument('--batch-size', dest='batch_size', default=32, type=int, help='Number of images per batch.') parser.add_argument('--distribute', dest='distribute', default='single', type=str, help='distributed training strategy.') args = parser.parse_args() # print the tf version and config print('Python Version = {}'.format(sys.version)) print('TensorFlow Version = {}'.format(tf.__version__)) print('TF_CONFIG = {}'.format(os.environ.get('TF_CONFIG', 'Not found'))) print('DEVICES', device_lib.list_local_devices()) # Single Machine, single compute device if args.distribute == 'single': if tf.test.is_gpu_available(): strategy = tf.distribute.OneDeviceStrategy(device="/gpu:0") else: strategy = tf.distribute.OneDeviceStrategy(device="/cpu:0") # Single Machine, multiple compute device elif args.distribute == 'mirror': strategy = tf.distribute.MirroredStrategy() # Multiple Machine, multiple compute device elif args.distribute == 'multi': strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy() # Multi-worker configuration print('num_replicas_in_sync = {}'.format(strategy.num_replicas_in_sync)) # Preparing dataset BUFFER_SIZE = 1000 IMG_HEIGHT = 224 IMG_WIDTH = 224 def make_datasets_batched(dataset_path, global_batch_size): # Configure the training data generator train_data_dir = os.path.join(dataset_path,"train/") train_ds = tf.keras.utils.image_dataset_from_directory( train_data_dir, seed=36, image_size=(IMG_HEIGHT, IMG_WIDTH), batch_size=global_batch_size ) # Configure the validation data generator val_data_dir = os.path.join(dataset_path,"valid/") val_ds = tf.keras.utils.image_dataset_from_directory( val_data_dir, seed=36, image_size=(IMG_HEIGHT, IMG_WIDTH), batch_size=global_batch_size ) # get the number of classes in the data num_classes = len(train_ds.class_names) # Configure the dataset for performance AUTOTUNE = tf.data.AUTOTUNE train_ds = train_ds.cache().shuffle(BUFFER_SIZE).prefetch(buffer_size=AUTOTUNE) val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE) return train_ds, val_ds, num_classes # Build the Keras model def build_and_compile_cnn_model(num_classes): # build a CNN model model = tf.keras.models.Sequential([ tf.keras.layers.Rescaling(1./255, input_shape=(IMG_HEIGHT, IMG_WIDTH, 3)), tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(num_classes) ]) # compile the CNN model model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) return model # Get the strategy data NUM_WORKERS = strategy.num_replicas_in_sync # Here the batch size scales up by number of workers GLOBAL_BATCH_SIZE = args.batch_size * NUM_WORKERS # Create dataset generator objects train_ds, val_ds, num_classes = make_datasets_batched(args.dataset_dir, GLOBAL_BATCH_SIZE) # Compile the model with strategy.scope(): # Creation of dataset, and model building/compiling need to be within # `strategy.scope()`. model = build_and_compile_cnn_model(num_classes) # fit the model on the data history = model.fit(train_ds, validation_data=val_ds, epochs=args.epochs) # save the model to the output dir model.save(args.model_dir)選取「檔案」> 儲存 Python 檔案。
在 JupyterLab 終端機中,於每個子目錄中建立
__init__.py檔案,將子目錄設為套件:touch fungi_training_package/__init__.py touch fungi_training_package/trainer/__init__.py在「檔案瀏覽器」中,按兩下「
fungi_training_package」資料夾。依序選取「File」>「New」>「Python file」。
在新檔案上按一下滑鼠右鍵,然後選取「重新命名檔案」。
將檔案從
untitled.py重新命名為setup.py。按兩下
setup.py檔案即可開啟。將下列程式碼複製到
setup.py:from setuptools import find_packages from setuptools import setup setup( name='trainer', version='0.1', packages=find_packages(), include_package_data=True, description='Training application package for fungi-classification.' )選取「檔案」> 儲存 Python 檔案。
在終端機中,前往
fungi_training_package目錄:cd fungi_training_package使用
sdist指令建立訓練應用程式的來源發布版本:python setup.py sdist --formats=gztar前往父項目錄:
cd ..確認您位於正確的目錄:
pwd輸出如下所示:
/home/jupyter將 Python 套件複製到暫存值區:
gcloud storage cp fungi_training_package/dist/trainer-0.1.tar.gz gs://pipelines-staging-bucket-$projectid/training_package/確認暫存 bucket 包含套件:
gcloud storage ls gs://pipelines-staging-bucket-$projectid/training_package輸出內容會如下所示:
gs://pipelines-staging-bucket-PROJECT_ID/training_package/trainer-0.1.tar.gz
為 Vertex AI Pipelines 建立 Service Networking 連線
在本節中,您將建立 Service Networking 連線,用於透過虛擬私有雲網路對等互連,建立連至 vertex-networking-vpc 虛擬私有雲網路的生產端服務。詳情請參閱「虛擬私有雲網路對等互連」。
在 Cloud Shell 中執行下列指令,並將 PROJECT_ID 替換為您的專案 ID:
projectid=PROJECT_ID gcloud config set project ${projectid}使用
gcloud compute addresses create設定保留的 IP 位址範圍:gcloud compute addresses create vertex-pipeline-subnet \ --global \ --purpose=VPC_PEERING \ --addresses=192.168.10.0 \ --prefix-length=24 \ --description="pipeline subnet" \ --network=vertex-networking-vpc使用
gcloud services vpc-peerings connect,在虛擬私有雲網路與 Google 的 Service Networking 之間建立對等互連連線:vertex-networking-vpcgcloud services vpc-peerings connect \ --service=servicenetworking.googleapis.com \ --ranges=vertex-pipeline-subnet \ --network=vertex-networking-vpc更新虛擬私有雲對等互連連線,啟用自訂學習路徑的匯入和匯出功能:
gcloud compute networks peerings update servicenetworking-googleapis-com \ --network=vertex-networking-vpc \ --import-custom-routes \ --export-custom-routes
從 pipeline-networking Cloud Router 公告管道子網路
前往 Google Cloud 控制台的「Cloud Router」頁面。
在 Cloud Router 清單中,按一下
vertex-networking-vpc-router1。在「路由器詳細資料」頁面中,按一下「編輯」。
按一下「新增自訂路徑」。
在「來源」中選取「自訂 IP 範圍」。
在「IP address range」(IP 位址範圍) 中,輸入下列 IP 位址範圍:
192.168.10.0/24在「說明」中輸入下列文字:
Vertex AI Pipelines reserved subnet依序按一下 [完成] 及 [儲存]。
建立管道範本並上傳至 Artifact Registry
在本節中,您將建立並上傳 Kubeflow Pipelines (KFP) 管道範本。這個範本包含可重複使用的工作流程定義,可供單一或多位使用者使用。
定義及編譯管道
在 Jupyterlab 的「File Browser」中,按兩下頂層資料夾。
依序選取「File」>「New」>「Notebook」。
在「Select Kernel」選單中,選取
Python 3 (ipykernel)並按一下「Select」。在新的筆記本儲存格中執行下列指令,確認您擁有最新版本的
pip:!python -m pip install --upgrade pip執行下列指令,從 Python 套件索引 (PyPI) 安裝 Google Cloud Pipeline Components SDK:
!pip install --upgrade google-cloud-pipeline-components安裝完成後,請選取「Kernel」>「Restart kernel」,重新啟動核心,並確保程式庫可用於匯入。
在新的筆記本儲存格中執行下列程式碼,定義管道:
from kfp import dsl # define the train-deploy pipeline @dsl.pipeline(name="custom-image-classification-pipeline") def custom_image_classification_pipeline( project: str, training_job_display_name: str, worker_pool_specs: list, base_output_dir: str, model_artifact_uri: str, prediction_container_uri: str, model_display_name: str, endpoint_display_name: str, network: str = '', location: str="us-central1", serving_machine_type: str="n1-standard-4", serving_min_replica_count: int=1, serving_max_replica_count: int=1 ): from google_cloud_pipeline_components.types import artifact_types from google_cloud_pipeline_components.v1.custom_job import CustomTrainingJobOp from google_cloud_pipeline_components.v1.model import ModelUploadOp from google_cloud_pipeline_components.v1.endpoint import (EndpointCreateOp, ModelDeployOp) from kfp.dsl import importer # Train the model task custom_job_task = CustomTrainingJobOp( project=project, display_name=training_job_display_name, worker_pool_specs=worker_pool_specs, base_output_directory=base_output_dir, location=location, network=network ) # Import the model task import_unmanaged_model_task = importer( artifact_uri=model_artifact_uri, artifact_class=artifact_types.UnmanagedContainerModel, metadata={ "containerSpec": { "imageUri": prediction_container_uri, }, }, ).after(custom_job_task) # Model upload task model_upload_op = ModelUploadOp( project=project, display_name=model_display_name, unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"], ) model_upload_op.after(import_unmanaged_model_task) # Create Endpoint task endpoint_create_op = EndpointCreateOp( project=project, display_name=endpoint_display_name, ) # Deploy the model to the endpoint ModelDeployOp( endpoint=endpoint_create_op.outputs["endpoint"], model=model_upload_op.outputs["model"], dedicated_resources_machine_type=serving_machine_type, dedicated_resources_min_replica_count=serving_min_replica_count, dedicated_resources_max_replica_count=serving_max_replica_count, )在新的筆記本儲存格中執行下列程式碼,編譯管道定義:
from kfp import compiler PIPELINE_FILE = "pipeline_config.yaml" compiler.Compiler().compile( pipeline_func=custom_image_classification_pipeline, package_path=PIPELINE_FILE, )在 「檔案瀏覽器」中,檔案清單會顯示名為
pipeline_config.yaml的檔案。
建立 Artifact Registry 存放區
在新的筆記本儲存格中執行下列程式碼,建立 KFP 類型的構件存放區:
REPO_NAME="fungi-repo" REGION="us-central1" !gcloud artifacts repositories create $REPO_NAME --location=$REGION --repository-format=KFP
將管道範本上傳至 Artifact Registry
在本節中,您會設定 Kubeflow Pipelines SDK 登錄用戶端,並從 JupyterLab 筆記本將已編譯的管道範本上傳至 Artifact Registry。
在 JupyterLab 筆記本中執行下列程式碼,上傳管道範本,並將 PROJECT_ID 替換為您的專案 ID:
PROJECT_ID = "PROJECT_ID" from kfp.registry import RegistryClient host = f"https://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}" client = RegistryClient(host=host) TEMPLATE_NAME, VERSION_NAME = client.upload_pipeline( file_name=PIPELINE_FILE, tags=["v1", "latest"], extra_headers={"description":"This is an example pipeline template."})在 Google Cloud 控制台中,如要確認範本已上傳,請前往 Vertex AI Pipelines 範本。
如要開啟「Select repository」(選取存放區) 窗格,請按一下「Select repository」(選取存放區)。
在存放區清單中,按一下您建立的存放區 (
fungi-repo),然後按一下「選取」。確認管道 (
custom-image-classification-pipeline) 顯示在清單中。
從地端觸發管道執行作業
在本節中,管道範本和訓練套件都已準備就緒,您將使用 cURL 從地端應用程式觸發管道執行作業。
提供管道參數
在 JupyterLab 筆記本中,執行下列指令來驗證管道範本名稱:
print (TEMPLATE_NAME)傳回的範本名稱為:
custom-image-classification-pipeline執行下列指令,取得管道範本版本:
print (VERSION_NAME)傳回的管道範本版本名稱如下所示:
sha256:41eea21e0d890460b6e6333c8070d7d23d314afd9c7314c165efd41cddff86c7請記下整個版本名稱字串。
在 Cloud Shell 中執行下列指令,並將 PROJECT_ID 替換為您的專案 ID:
projectid=PROJECT_ID gcloud config set project ${projectid}登入
on-prem-dataservice-hostVM 執行個體:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iap在
on-prem-dataservice-hostVM 執行個體中,使用文字編輯器 (例如vim或nano) 建立request_body.json檔案,例如:sudo vim request_body.json將下列這行文字新增到
request_body.json檔案:{ "displayName": "fungi-image-pipeline-job", "serviceAccount": "onprem-user-managed-sa@PROJECT_ID.iam.gserviceaccount.com", "runtimeConfig":{ "gcsOutputDirectory":"gs://pipelines-staging-bucket-PROJECT_ID/pipeline_root/", "parameterValues": { "project": "PROJECT_ID", "training_job_display_name": "fungi-image-training-job", "worker_pool_specs": [{ "machine_spec": { "machine_type": "n1-standard-4" }, "replica_count": 1, "python_package_spec":{ "executor_image_uri":"us-docker.pkg.dev/vertex-ai/training/tf-cpu.2-8.py310:latest", "package_uris": ["gs://pipelines-staging-bucket-PROJECT_ID/training_package/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args": ["--data-dir","/mnt/nfs/fungi_dataset/", "--epochs", "10"], "env": [{"name": "AIP_MODEL_DIR", "value": "gs://pipelines-staging-bucket-PROJECT_ID/model/"}] }, "nfs_mounts": [{ "server": "FILESTORE_INSTANCE_IP", "path": "/vol1", "mount_point": "/mnt/nfs/" }] }], "base_output_dir":"gs://pipelines-staging-bucket-PROJECT_ID", "model_artifact_uri":"gs://pipelines-staging-bucket-PROJECT_ID/model/", "prediction_container_uri":"us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest", "model_display_name":"fungi-image-model", "endpoint_display_name":"fungi-image-endpoint", "location": "us-central1", "serving_machine_type":"n1-standard-4", "network":"projects/PROJECT_NUMBER/global/networks/vertex-networking-vpc" } }, "templateUri": "https://us-central1-kfp.pkg.dev/PROJECT_ID/fungi-repo/custom-image-classification-pipeline/latest", "templateMetadata": { "version":"VERSION_NAME" } }替換下列值:
按照下列方式儲存檔案:
- 如果使用
vim,請按下Esc鍵,然後輸入:wq儲存檔案並結束。 - 如果使用
nano,請輸入Control+O並按下Enter儲存檔案,然後輸入Control+X結束。
- 如果使用
從範本提交管道執行作業
在
on-prem-dataservice-hostVM 執行個體中執行下列指令,並將 PROJECT_ID 替換為您的專案 ID:curl -v -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ -d @request_body.json \ https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/pipelineJobs您會看到很長的輸出內容,但主要需要尋找的是下列這行,表示服務正在準備執行管道:
"state": "PIPELINE_STATE_PENDING"整個 pipeline 執行作業約需 45 到 50 分鐘。
在 Google Cloud 控制台的「Vertex AI」專區,前往「Pipelines」頁面的「Runs」分頁。
按一下管道執行的執行名稱 (
custom-image-classification-pipeline)。系統會顯示管道執行頁面,並顯示管道的執行階段圖表。 管道摘要會顯示在「管道執行作業分析結果」窗格中。
如要瞭解如何解讀執行階段圖表顯示的資訊,包括如何查看記錄檔及使用 Vertex ML Metadata 進一步瞭解管道的構件,請參閱「視覺化及分析管道結果」。