Vertex AI Pipelines 是一项托管式服务,可帮助您在 Google Cloud 平台上构建、部署和管理端到端机器学习 (ML) 工作流。它提供了一个用于运行流水线的无服务器环境,因此您无需担心管理基础架构。
在本教程中,您将使用 Vertex AI Pipelines 在混合网络环境中运行自定义训练作业,并在 Vertex AI 中部署经过训练的模型。
整个过程需要两到三个小时才能完成,其中流水线运行需要约 50 分钟。
本教程适用于熟悉 Vertex AI、虚拟私有云 (VPC)、 Google Cloud 控制台和 Cloud Shell 的企业网络管理员、数据科学家和研究人员。熟悉 Vertex AI Workbench 会很有帮助,但不强制要求。
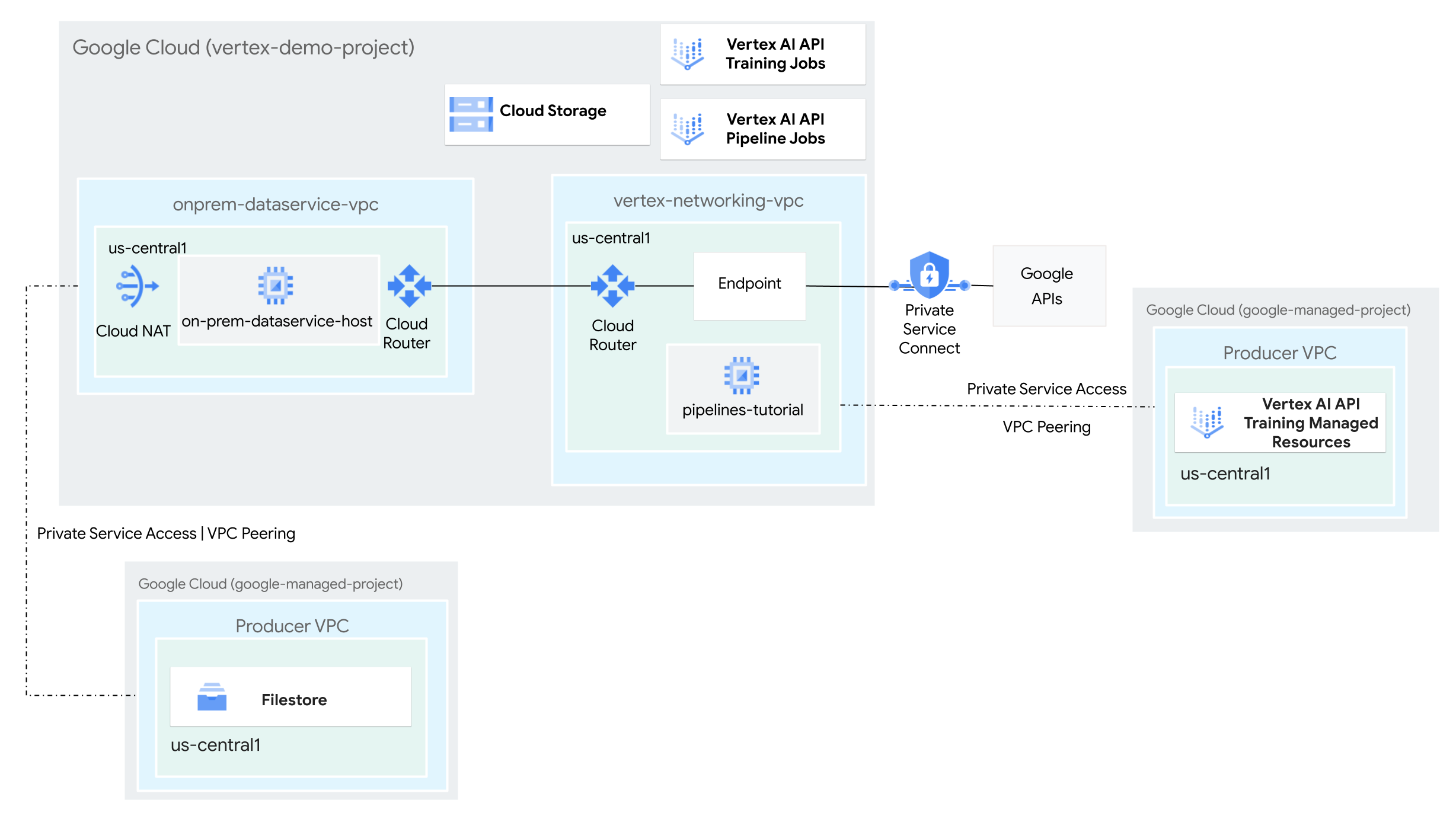
创建 VPC 网络
在本部分中,您将创建两个 VPC 网络:一个用于访问 Vertex AI Pipelines 的 Google API,另一个用于模拟本地网络。在两个 VPC 网络中,您都需要创建一个 Cloud Router 路由器和 Cloud NAT 网关。Cloud NAT 网关为没有外部 IP 地址的 Compute Engine 虚拟机实例提供传出连接。
在 Cloud Shell 中,运行以下命令,并将 PROJECT_ID 替换为您的项目 ID:
projectid=PROJECT_ID gcloud config set project ${projectid}创建
vertex-networking-vpcVPC 网络:gcloud compute networks create vertex-networking-vpc \ --subnet-mode custom在
vertex-networking-vpc网络中,创建一个名为pipeline-networking-subnet1的子网,其主要 IPv4 范围为10.0.0.0/24:gcloud compute networks subnets create pipeline-networking-subnet1 \ --range=10.0.0.0/24 \ --network=vertex-networking-vpc \ --region=us-central1 \ --enable-private-ip-google-access创建用于模拟本地网络的 VPC 网络 (
onprem-dataservice-vpc):gcloud compute networks create onprem-dataservice-vpc \ --subnet-mode custom在
onprem-dataservice-vpc网络中,创建一个名为onprem-dataservice-vpc-subnet1的子网,其主要 IPv4 范围为172.16.10.0/24:gcloud compute networks subnets create onprem-dataservice-vpc-subnet1 \ --network onprem-dataservice-vpc \ --range 172.16.10.0/24 \ --region us-central1 \ --enable-private-ip-google-access
验证 VPC 网络是否已正确配置
在 Google Cloud 控制台中,前往 VPC 网络页面上的当前项目中的网络标签页。
在 VPC 网络列表中,验证是否已创建
vertex-networking-vpc和onprem-dataservice-vpc这两个网络。点击当前项目中的子网标签页。
在 VPC 子网列表中,验证是否已创建
pipeline-networking-subnet1和onprem-dataservice-vpc-subnet1子网。
配置混合连接
在本部分中,您将创建两个相互连接的高可用性 VPN 网关。一个位于 vertex-networking-vpc VPC 网络中。另一个位于 onprem-dataservice-vpc VPC 网络中。 每个网关包含一个 Cloud Router 路由器和一对 VPN 隧道。
创建高可用性 VPN 网关
在 Cloud Shell 中,为
vertex-networking-vpcVPC 网络创建高可用性 VPN 网关:gcloud compute vpn-gateways create vertex-networking-vpn-gw1 \ --network vertex-networking-vpc \ --region us-central1为
onprem-dataservice-vpcVPC 网络创建高可用性 VPN 网关:gcloud compute vpn-gateways create onprem-vpn-gw1 \ --network onprem-dataservice-vpc \ --region us-central1在 Google Cloud 控制台中,前往 VPN 页面上的 Cloud VPN 网关标签页。
验证是否已创建两个网关(
vertex-networking-vpn-gw1和onprem-vpn-gw1),并且每个网关具有两个接口 IP 地址。
创建 Cloud Router 路由器和 Cloud NAT 网关
在两个 VPC 网络中,您都需要创建两个 Cloud Router 路由器:一个用于与 Cloud NAT 搭配使用,另一个用于管理高可用性 VPN 的 BGP 会话。
在 Cloud Shell 中,为将用于 VPN 的
vertex-networking-vpcVPC 网络创建一个 Cloud Router 路由器:gcloud compute routers create vertex-networking-vpc-router1 \ --region us-central1 \ --network vertex-networking-vpc \ --asn 65001为将用于 VPN 的
onprem-dataservice-vpcVPC 网络创建一个 Cloud Router 路由器:gcloud compute routers create onprem-dataservice-vpc-router1 \ --region us-central1 \ --network onprem-dataservice-vpc \ --asn 65002为将用于 Cloud NAT 的
vertex-networking-vpcVPC 网络创建 Cloud Router 路由器:gcloud compute routers create cloud-router-us-central1-vertex-nat \ --network vertex-networking-vpc \ --region us-central1在 Cloud Router 路由器上配置 Cloud NAT 网关:
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-vertex-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1为将用于 Cloud NAT 的
onprem-dataservice-vpcVPC 网络创建 Cloud Router 路由器:gcloud compute routers create cloud-router-us-central1-onprem-nat \ --network onprem-dataservice-vpc \ --region us-central1在 Cloud Router 路由器上配置 Cloud NAT 网关:
gcloud compute routers nats create cloud-nat-us-central1-on-prem \ --router=cloud-router-us-central1-onprem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1在 Google Cloud 控制台中,前往 Cloud Router 页面。
在 Cloud Router 路由器列表中,验证是否已创建以下路由器:
cloud-router-us-central1-onprem-natcloud-router-us-central1-vertex-natonprem-dataservice-vpc-router1vertex-networking-vpc-router1
您可能需要刷新 Google Cloud 控制台浏览器标签页才能查看新值。
在 Cloud Router 路由器列表中,点击
cloud-router-us-central1-vertex-nat。在路由器详情页面中,验证是否已创建
cloud-nat-us-central1Cloud NAT 网关。点击 返回箭头以返回 Cloud Router 路由器页面。
在 Cloud Router 路由器列表中,点击
cloud-router-us-central1-onprem-nat。在路由器详情页面中,验证是否已创建
cloud-nat-us-central1-on-premCloud NAT 网关。
创建 VPN 隧道
在 Cloud Shell 中,在
vertex-networking-vpc网络中创建一个名为vertex-networking-vpc-tunnel0的 VPN 隧道:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel0 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 0在
vertex-networking-vpc网络中,创建一个名为vertex-networking-vpc-tunnel1的 VPN 隧道:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel1 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 1在
onprem-dataservice-vpc网络中,创建一个名为onprem-dataservice-vpc-tunnel0的 VPN 隧道:gcloud compute vpn-tunnels create onprem-dataservice-vpc-tunnel0 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router onprem-dataservice-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 0在
onprem-dataservice-vpc网络中,创建一个名为onprem-dataservice-vpc-tunnel1的 VPN 隧道:gcloud compute vpn-tunnels create onprem-dataservice-vpc-tunnel1 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router onprem-dataservice-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 1在 Google Cloud 控制台中,前往 VPN 页面。
在 VPN 隧道列表中,验证是否已创建这四个 VPN 隧道。
建立 BGP 会话
Cloud Router 路由器使用边界网关协议 (BGP) 在 VPC 网络(在本例中为 vertex-networking-vpc)和本地网络(由 onprem-dataservice-vpc 表示)之间交换路由。在 Cloud Router 路由器上,为本地路由器配置接口和 BGP 对等端。此接口和 BGP 对等配置共同构成了 BGP 会话。在本部分中,您将分别为 vertex-networking-vpc 和 onprem-dataservice-vpc 创建两个 BGP 会话。
在路由器之间配置接口和 BGP 对等方后,它们将自动开始交换路由。
为 vertex-networking-vpc 建立 BGP 会话
在 Cloud Shell 中,在
vertex-networking-vpc网络中为vertex-networking-vpc-tunnel0创建一个 BGP 接口:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.0.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel0 \ --region us-central1在
vertex-networking-vpc网络中,为bgp-onprem-tunnel0创建一个 BGP 对等方:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel0 \ --interface if-tunnel0-to-onprem \ --peer-ip-address 169.254.0.2 \ --peer-asn 65002 \ --region us-central1在
vertex-networking-vpc网络中,为vertex-networking-vpc-tunnel1创建一个 BGP 接口:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel1 \ --region us-central1在
vertex-networking-vpc网络中,为bgp-onprem-tunnel1创建一个 BGP 对等方:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel1 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central1
为 onprem-dataservice-vpc 建立 BGP 会话
在
onprem-dataservice-vpc网络中,为onprem-dataservice-vpc-tunnel0创建一个 BGP 接口:gcloud compute routers add-interface onprem-dataservice-vpc-router1 \ --interface-name if-tunnel0-to-vertex-networking-vpc \ --ip-address 169.254.0.2 \ --mask-length 30 \ --vpn-tunnel onprem-dataservice-vpc-tunnel0 \ --region us-central1在
onprem-dataservice-vpc网络中,为bgp-vertex-networking-vpc-tunnel0创建一个 BGP 对等方:gcloud compute routers add-bgp-peer onprem-dataservice-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel0 \ --interface if-tunnel0-to-vertex-networking-vpc \ --peer-ip-address 169.254.0.1 \ --peer-asn 65001 \ --region us-central1在
onprem-dataservice-vpc网络中,为onprem-dataservice-vpc-tunnel1创建一个 BGP 接口:gcloud compute routers add-interface onprem-dataservice-vpc-router1 \ --interface-name if-tunnel1-to-vertex-networking-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel onprem-dataservice-vpc-tunnel1 \ --region us-central1在
onprem-dataservice-vpc网络中,为bgp-vertex-networking-vpc-tunnel1创建一个 BGP 对等方:gcloud compute routers add-bgp-peer onprem-dataservice-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel1 \ --interface if-tunnel1-to-vertex-networking-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central1
验证 BGP 会话创建
在 Google Cloud 控制台中,前往 VPN 页面。
在 VPN 隧道列表中,验证每个隧道的 BGP 会话状态列中的值是否已从 配置 BGP 会话更改为 BGP 已建立。您可能需要刷新 Google Cloud 控制台浏览器标签页才能查看新值。
验证 onprem-dataservice-vpc 是否了解路由
在 Google Cloud 控制台中,前往 VPC 网络页面。
在 VPC 网络列表中,点击
onprem-dataservice-vpc。点击路由标签页。
在区域列表中选择 us-central1(爱荷华),然后点击查看。
在目标 IP 范围列中,验证
pipeline-networking-subnet1子网 IP 范围 (10.0.0.0/24) 是否出现两次。您可能需要刷新 Google Cloud 控制台浏览器标签页才能看到这两项条目。
验证 vertex-networking-vpc 是否了解路由
点击 返回箭头以返回 VPC 网络页面。
在 VPC 网络列表中,点击
vertex-networking-vpc。点击路由标签页。
在区域列表中选择 us-central1(爱荷华),然后点击查看。
在目标 IP 范围列中,验证
onprem-dataservice-vpc-subnet1子网的 IP 范围 (172.16.10.0/24) 是否出现两次。
为 Google API 创建 Private Service Connect 端点
在本部分中,您将为 Google API 创建 Private Service Connect 端点,以便通过该端点从您的本地网络访问 Vertex AI Pipelines REST API。
在 Cloud Shell 中,预留将用于访问 Google API 的使用方端点 IP 地址:
gcloud compute addresses create psc-googleapi-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=192.168.0.1 \ --network=vertex-networking-vpc创建转发规则以将端点连接到 Google API 和服务。
gcloud compute forwarding-rules create pscvertex \ --global \ --network=vertex-networking-vpc \ --address=psc-googleapi-ip \ --target-google-apis-bundle=all-apis
为 vertex-networking-vpc 创建自定义路由通告
在本部分中,您将为 vertex-networking-vpc-router1(vertex-networking-vpc 的 Cloud Route 路由器)创建自定义路由通告,以将 PSC 端点的 IP 地址通告给 onprem-dataservice-vpc VPC 网络。
在 Google Cloud 控制台中,前往 Cloud Router 页面。
在 Cloud Router 路由器列表中,点击
vertex-networking-vpc-router1。在路由器详情页面上,点击 修改。
在通告的路由部分,对于路由,选择创建自定义路由。
选中通告向 Cloud Router 路由器公开的所有子网复选框,以继续通告 Cloud Router 路由器可用的子网。启用此选项可模拟 Cloud Router 路由器在默认通告模式下的行为。
点击添加自定义路由。
对于来源,选择自定义 IP 范围。
在 IP 地址范围字段中,输入以下 IP 地址:
192.168.0.1在说明字段中,输入以下文本:
Custom route to advertise Private Service Connect endpoint IP address点击完成,然后点击保存。
验证 onprem-dataservice-vpc 是否已获知通告的路由
在 Google Cloud 控制台中,转到路由页面。
在有效路由标签页上,执行以下操作:
- 在网络字段中,选择
onprem-dataservice-vpc。 - 在区域字段中,选择
us-central1 (Iowa)。 - 点击视图。
在路由列表中,验证是否存在名称以
onprem-dataservice-vpc-router1-bgp-vertex-networking-vpc-tunnel0开头的两个条目,以及名称以onprem-dataservice-vpc-router1-bgp-vertex-networking-vpc-tunnel1开头的两个条目。如果这些条目没有立即显示,请等待几分钟,然后刷新 Google Cloud 控制台浏览器标签页。
验证其中两个条目的目标 IP 范围为
192.168.0.1/32,另外两个条目的目标 IP 范围为10.0.0.0/24。
- 在网络字段中,选择
在 onprem-dataservice-vpc 中创建虚拟机实例
在本部分中,您将创建一个虚拟机实例,以模拟本地数据服务主机。按照 Compute Engine 和 IAM 最佳实践,此虚拟机使用用户管理的服务账号,而不是 Compute Engine 默认服务账号。
为虚拟机实例创建用户管理的服务账号
在 Cloud Shell 中,运行以下命令,并将 PROJECT_ID 替换为您的项目 ID:
projectid=PROJECT_ID gcloud config set project ${projectid}创建名为
onprem-user-managed-sa的服务账号:gcloud iam service-accounts create onprem-user-managed-sa \ --display-name="onprem-user-managed-sa"将 Vertex AI User (
roles/aiplatform.user) 角色分配给该服务账号:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"分配 Vertex AI Viewer (
roles/aiplatform.viewer) 角色:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.viewer"分配 Filestore Editor (
roles/file.editor) 角色:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/file.editor"分配 Service Account Admin (
roles/iam.serviceAccountAdmin) 角色:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/iam.serviceAccountAdmin"分配 Service Account User
roles/iam.serviceAccountUser() 角色。gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/iam.serviceAccountUser"分配 Artifact Registry Reader (
roles/artifactregistry.reader) 角色:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.reader"分配 Storage Object Admin
roles/storage.objectAdmin() 角色。gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.objectAdmin"分配 Logging Admin (
roles/logging.admin) 角色:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/logging.admin"
创建 on-prem-dataservice-host 虚拟机实例
您创建的虚拟机实例没有外部 IP 地址,也不允许通过互联网直接访问。如需启用对虚拟机的管理员权限,请使用 Identity-Aware Proxy (IAP) TCP 转发。
在 Cloud Shell 中,创建
on-prem-dataservice-host虚拟机实例:gcloud compute instances create on-prem-dataservice-host \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=onprem-dataservice-vpc-subnet1 \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --shielded-secure-boot \ --service-account=onprem-user-managed-sa@$projectid.iam.gserviceaccount.com \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"创建一条防火墙规则以允许 IAP 连接到虚拟机实例:
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network onprem-dataservice-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
更新 /etc/hosts 文件以指向 PSC 端点
在本部分中,您将在 /etc/hosts 文件中添加一行,以使发送到公共服务端点 (us-central1-aiplatform.googleapis.com) 的请求重定向到 PSC 端点 (192.168.0.1)。
在 Cloud Shell 中,使用 IAP 登录到
on-prem-dataservice-host虚拟机实例:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iap在
on-prem-dataservice-host虚拟机实例中,使用文本编辑器(例如vim或nano)打开/etc/hosts文件,例如:sudo vim /etc/hosts将以下代码行添加到文件中:
192.168.0.1 us-central1-aiplatform.googleapis.com此行将 PSC 端点的 IP 地址 (
192.168.0.1) 分配给 Vertex AI Google API (us-central1-aiplatform.googleapis.com) 的完全限定域名。修改后的文件应如下所示:
127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 192.168.0.1 us-central1-aiplatform.googleapis.com # Added by you 172.16.10.6 on-prem-dataservice-host.us-central1-a.c.PROJECT_ID.internal on-prem-dataservice-host # Added by Google 169.254.169.254 metadata.google.internal # Added by Google按如下方式保存文件:
- 如果您使用的是
vim,请按Esc键,然后输入:wq以保存文件并退出。 - 如果您使用的是
nano,请输入Control+O并按Enter以保存该文件,然后输入Control+X以退出。
- 如果您使用的是
对 Vertex AI API 端点执行 Ping 操作,如下所示:
ping us-central1-aiplatform.googleapis.comping命令应返回以下输出。192.168.0.1是 PSC 端点 IP 地址:PING us-central1-aiplatform.googleapis.com (192.168.0.1) 56(84) bytes of data.输入
Control+C以从ping退出。输入
exit以退出on-prem-dataservice-host虚拟机实例并返回到 Cloud Shell 提示。
为 Filestore 实例配置网络
在本部分中,您将为 VPC 网络启用专用服务访问通道,为创建 Filestore 实例并将其作为网络文件系统 (NFS) 共享内容进行装载做好准备。如需了解您将在本部分和下一部分中执行的操作,请参阅为自定义训练挂载 NFS 共享和设置 VPC 网络对等互连。
在 VPC 网络上启用专用服务访问通道
在本部分中,您将创建一个 Service Networking 连接,并使用该连接通过 VPC 网络对等互连实现专用服务对 onprem-dataservice-vpc VPC 网络的访问。
在 Cloud Shell 中,使用
gcloud compute addresses create设置预留 IP 地址范围:gcloud compute addresses create filestore-subnet \ --global \ --purpose=VPC_PEERING \ --addresses=10.243.208.0 \ --prefix-length=24 \ --description="filestore subnet" \ --network=onprem-dataservice-vpc使用
gcloud services vpc-peerings connect在onprem-dataservice-vpcVPC 网络与 Google 的 Service Networking 之间建立对等互连连接:gcloud services vpc-peerings connect \ --service=servicenetworking.googleapis.com \ --ranges=filestore-subnet \ --network=onprem-dataservice-vpc更新 VPC 网络对等互连以启用自定义已学路由的导入和导出:
gcloud compute networks peerings update servicenetworking-googleapis-com \ --network=onprem-dataservice-vpc \ --import-custom-routes \ --export-custom-routes在 Google Cloud 控制台中,打开 VPC 网络对等互连页面。
在 VPC 对等互连列表中,验证是否存在
servicenetworking.googleapis.com与onprem-dataservice-vpcVPC 网络之间的对等互连条目。
为 filestore-subnet 创建自定义路由通告
在 Google Cloud 控制台中,前往 Cloud Router 页面。
在 Cloud Router 路由器列表中,点击
onprem-dataservice-vpc-router1。在路由器详情页面上,点击 修改。
在通告的路由部分,对于路由,选择创建自定义路由。
选中通告向 Cloud Router 路由器公开的所有子网复选框,以继续通告 Cloud Router 路由器可用的子网。启用此选项可模拟 Cloud Router 路由器在默认通告模式下的行为。
点击添加自定义路由。
对于来源,选择自定义 IP 范围。
在 IP 地址范围字段中,输入以下 IP 地址范围:
10.243.208.0/24在说明字段中,输入以下文本:
Filestore reserved IP address range点击完成,然后点击保存。
在 onprem-dataservice-vpc 网络中创建 Filestore 实例
为 VPC 网络启用专用服务访问权限后,您可以创建 Filestore 实例,并将该实例作为NFS 共享挂载到自定义训练作业。这允许您的训练作业访问远程文件,就像它们在本地一样,从而实现高吞吐量和短延时。
创建 Filestore 实例
在 Google Cloud 控制台中,前往 Filestore 实例页面。
点击创建实例,然后按如下所示配置实例。
将实例 ID 设置为以下值:
image-data-instance将实例类型设置为基本。
将存储类型设置为 HDD。
将分配容量设置为 1
TiB。将地区设置为 us-central1,将区域设置为 us-central1-c。
将 VPC 网络设置为
onprem-dataservice-vpc。将分配的 IP 范围设置为使用现有的已分配 IP 范围,然后选择
filestore-subnet。将文件共享名称设置为以下内容:
vol1将访问权限控制设置为向 VPC 网络中的所有客户端授予访问权限。
点击创建。
记下新 Filestore 实例的 IP 地址。您可能需要刷新 Google Cloud 控制台浏览器标签页才能看到新实例。
装载 Filestore 文件共享
在 Cloud Shell 中,运行以下命令,并将 PROJECT_ID 替换为您的项目 ID:
projectid=PROJECT_ID gcloud config set project ${projectid}登录到
on-prem-dataservice-host虚拟机实例:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iap在虚拟机实例上安装 NFS 软件包:
sudo apt-get update -y sudo apt-get -y install nfs-common为 Filestore 文件共享创建一个装载目录:
sudo mkdir -p /mnt/nfs将文件共享装载到 FILESTORE_INSTANCE_IP,并将其替换为 Filestore 实例的 IP 地址:
sudo mount FILESTORE_INSTANCE_IP:/vol1 /mnt/nfs如果连接超时,请检查以确保提供 Filestore 实例的正确 IP 地址。
通过运行以下命令验证 NFS 装载是否成功:
df -h验证
/mnt/nfs文件共享是否显示在结果中:Filesystem Size Used Avail Use% Mounted on udev 1.8G 0 1.8G 0% /dev tmpfs 368M 396K 368M 1% /run /dev/sda1 9.7G 1.9G 7.3G 21% / tmpfs 1.8G 0 1.8G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock /dev/sda15 124M 11M 114M 9% /boot/efi tmpfs 368M 0 368M 0% /run/user 10.243.208.2:/vol1 1007G 0 956G 0% /mnt/nfs更改权限,将文件共享设置为可访问:
sudo chmod go+rw /mnt/nfs
将数据集下载到文件共享空间
在
on-prem-dataservice-host虚拟机实例中,将数据集下载到文件共享:gcloud storage cp gs://cloud-samples-data/vertex-ai/dataset-management/datasets/fungi_dataset /mnt/nfs/ --recursive下载过程需要几分钟时间。
通过运行以下命令确认数据集已成功复制:
sudo du -sh /mnt/nfs预期输出为:
104M /mnt/nfs输入
exit以退出on-prem-dataservice-host虚拟机实例并返回到 Cloud Shell 提示。
为流水线创建暂存存储桶
Vertex AI Pipelines 使用 Cloud Storage 存储流水线运行的制品。在运行流水线之前,您需要为暂存流水线运行创建一个 Cloud Storage 存储桶。
在 Cloud Shell 中,创建一个 Cloud Storage 存储桶:
gcloud storage buckets create gs://pipelines-staging-bucket-$projectid --location=us-central1
为 Vertex AI Workbench 创建用户管理的服务账号
在 Cloud Shell 中,创建服务账号:
gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"将 Vertex AI User (
roles/aiplatform.user) 角色分配给该服务账号:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"分配 Artifact Registry Administrator (
artifactregistry.admin) 角色:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.admin"分配 Storage Admin (
storage.admin) 角色:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.admin"
创建 Python 训练应用
在本部分中,您将创建 Vertex AI Workbench 实例,并使用该实例创建 Python 自定义训练应用软件包。
创建 Vertex AI Workbench 实例
在 Google Cloud 控制台中,前往 Vertex AI Workbench 页面中的实例标签页。
点击 新建,然后单击高级选项。
系统会打开新建实例页面。
在新建实例页面的详细信息部分中,为新实例提供以下信息,然后点击继续:
名称:输入以下内容,并将 PROJECT_ID 替换为项目 ID:
pipeline-tutorial-PROJECT_ID区域:选择 us-central1。
可用区:选择 us-central1-a。
清除启用 Dataproc Serverless Interactive 会话复选框。
在环境部分中,点击继续。
在机器类型部分中,提供以下内容,然后点击继续:
- 机器类型:选择 N1,然后从机器类型菜单中选择
n1-standard-4。 安全强化型虚拟机:选中以下复选框:
- 安全启动
- 虚拟可信平台模块 (vTPM)
- 完整性监控
- 机器类型:选择 N1,然后从机器类型菜单中选择
在磁盘部分中,确保选中 Google-managed encryption key,然后点击继续:
在网络部分中,提供以下内容,然后点击继续:
网络:选择此项目中的网络并完成以下步骤:
在网络字段中,选择 vertex-networking-vpc。
在子网字段中,选择 pipeline-networking-subnet1。
清除分配外部 IP 地址复选框。不分配外部 IP 地址可防止实例接收来自互联网或其他 VPC 网络的未经请求的通信。
选中允许代理访问复选框。
在 IAM 和安全部分,提供以下内容,然后点击继续:
IAM 和安全:要向单个用户授予对实例的 JupyterLab 界面的访问权限,请完成以下步骤:
- 选择 Service account(服务账号)。
- 清除使用 Compute Engine 默认服务账号复选框。此步骤非常重要,因为 Compute Engine 默认服务账号(以及您刚刚指定的单个用户)可能拥有项目的 Editor 角色 (
roles/editor)。 在服务账号电子邮件地址字段中,输入以下内容,并将 PROJECT_ID 替换为项目 ID:
workbench-sa@PROJECT_ID.iam.gserviceaccount.com(这是您先前创建的自定义服务账号电子邮件地址。)此服务账号的权限有限。
如需详细了解如何授予访问权限,请参阅管理对 Vertex AI Workbench 实例的 JupyterLab 界面的访问权限。
安全选项:清除以下复选框:
- 对实例的根访问权限
选中以下复选框:
- nbconvert:
nbconvert可让用户以其他文件类型(如 HTML、PDF 或 LaTeX)导出和下载笔记本文件。Google Cloud 生成式 AI GitHub 代码库中的某些笔记本需要此设置。
清除以下复选框:
- 文件下载
除非您处于生产环境,否则请选择以下复选框:
- 终端访问权限:这将从 JupyterLab 界面对终端进行终端访问。
在系统健康状况部分中,清除环境自动升级并提供以下信息:
在报告中,选中以下复选框:
- 报告系统健康状况
- 向 Cloud Monitoring 报告自定义指标
- 安装 Cloud Monitoring
- 报告所需 Google 网域的 DNS 状态
点击创建,然后等待几分钟,让 Vertex AI Workbench 实例完成创建。
在 Vertex AI Workbench 实例中运行训练应用
在 Google Cloud 控制台中,前往 Vertex AI Workbench 页面上的实例标签页。
在 Vertex AI Workbench 实例名称 (
pipeline-tutorial-PROJECT_ID) 旁边(其中 PROJECT_ID 是项目 ID),点击打开 JupyterLab。您的 Vertex AI Workbench 实例会打开 JupyterLab。
选择文件 > 新建 > 终端。
在 JupyterLab 终端(而不是 Cloud Shell)中,为您的项目定义环境变量。请将 PROJECT_ID 替换为您的项目 ID:
projectid=PROJECT_ID为训练应用创建父级目录(仍然在 JupyterLab 终端中):
mkdir fungi_training_package mkdir fungi_training_package/trainer在 文件浏览器中,双击
fungi_training_package文件夹,然后双击trainer文件夹。在 文件浏览器中,右键点击空白文件列表(名称标题下方),然后选择新建文件。
右键点击新文件,然后选择重命名文件。
将文件从
untitled.txt重命名为task.py。双击
task.py文件即可将其打开。将以下代码复制到
task.py:# Import the libraries import tensorflow as tf from tensorflow.python.client import device_lib import argparse import os import sys # add parser arguments parser = argparse.ArgumentParser() parser.add_argument('--data-dir', dest='dataset_dir', type=str, help='Dir to access dataset.') parser.add_argument('--model-dir', dest='model_dir', default=os.getenv("AIP_MODEL_DIR"), type=str, help='Dir to save the model.') parser.add_argument('--epochs', dest='epochs', default=10, type=int, help='Number of epochs.') parser.add_argument('--batch-size', dest='batch_size', default=32, type=int, help='Number of images per batch.') parser.add_argument('--distribute', dest='distribute', default='single', type=str, help='distributed training strategy.') args = parser.parse_args() # print the tf version and config print('Python Version = {}'.format(sys.version)) print('TensorFlow Version = {}'.format(tf.__version__)) print('TF_CONFIG = {}'.format(os.environ.get('TF_CONFIG', 'Not found'))) print('DEVICES', device_lib.list_local_devices()) # Single Machine, single compute device if args.distribute == 'single': if tf.test.is_gpu_available(): strategy = tf.distribute.OneDeviceStrategy(device="/gpu:0") else: strategy = tf.distribute.OneDeviceStrategy(device="/cpu:0") # Single Machine, multiple compute device elif args.distribute == 'mirror': strategy = tf.distribute.MirroredStrategy() # Multiple Machine, multiple compute device elif args.distribute == 'multi': strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy() # Multi-worker configuration print('num_replicas_in_sync = {}'.format(strategy.num_replicas_in_sync)) # Preparing dataset BUFFER_SIZE = 1000 IMG_HEIGHT = 224 IMG_WIDTH = 224 def make_datasets_batched(dataset_path, global_batch_size): # Configure the training data generator train_data_dir = os.path.join(dataset_path,"train/") train_ds = tf.keras.utils.image_dataset_from_directory( train_data_dir, seed=36, image_size=(IMG_HEIGHT, IMG_WIDTH), batch_size=global_batch_size ) # Configure the validation data generator val_data_dir = os.path.join(dataset_path,"valid/") val_ds = tf.keras.utils.image_dataset_from_directory( val_data_dir, seed=36, image_size=(IMG_HEIGHT, IMG_WIDTH), batch_size=global_batch_size ) # get the number of classes in the data num_classes = len(train_ds.class_names) # Configure the dataset for performance AUTOTUNE = tf.data.AUTOTUNE train_ds = train_ds.cache().shuffle(BUFFER_SIZE).prefetch(buffer_size=AUTOTUNE) val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE) return train_ds, val_ds, num_classes # Build the Keras model def build_and_compile_cnn_model(num_classes): # build a CNN model model = tf.keras.models.Sequential([ tf.keras.layers.Rescaling(1./255, input_shape=(IMG_HEIGHT, IMG_WIDTH, 3)), tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(num_classes) ]) # compile the CNN model model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) return model # Get the strategy data NUM_WORKERS = strategy.num_replicas_in_sync # Here the batch size scales up by number of workers GLOBAL_BATCH_SIZE = args.batch_size * NUM_WORKERS # Create dataset generator objects train_ds, val_ds, num_classes = make_datasets_batched(args.dataset_dir, GLOBAL_BATCH_SIZE) # Compile the model with strategy.scope(): # Creation of dataset, and model building/compiling need to be within # `strategy.scope()`. model = build_and_compile_cnn_model(num_classes) # fit the model on the data history = model.fit(train_ds, validation_data=val_ds, epochs=args.epochs) # save the model to the output dir model.save(args.model_dir)依次选择文件 > 保存 Python 文件。
在 JupyterLab 终端中,在每个子目录中创建一个
__init__.py文件,使其成为软件包:touch fungi_training_package/__init__.py touch fungi_training_package/trainer/__init__.py在 文件浏览器中,双击
fungi_training_package文件夹。依次选择文件 > 新建 > Python 文件。
右键点击新文件,然后选择重命名文件。
将文件从
untitled.py重命名为setup.py。双击
setup.py文件即可将其打开。将以下代码复制到
setup.py:from setuptools import find_packages from setuptools import setup setup( name='trainer', version='0.1', packages=find_packages(), include_package_data=True, description='Training application package for fungi-classification.' )依次选择文件 > 保存 Python 文件。
在终端中,前往
fungi_training_package目录:cd fungi_training_package使用
sdist命令创建训练应用的源代码分发:python setup.py sdist --formats=gztar导航到父级目录:
cd ..验证您位于正确的目录中:
pwd输出类似于以下内容:
/home/jupyter将 Python 软件包复制到暂存存储桶:
gcloud storage cp fungi_training_package/dist/trainer-0.1.tar.gz gs://pipelines-staging-bucket-$projectid/training_package/验证暂存存储桶是否包含该软件包:
gcloud storage ls gs://pipelines-staging-bucket-$projectid/training_package输出为:
gs://pipelines-staging-bucket-PROJECT_ID/training_package/trainer-0.1.tar.gz
为 Vertex AI Pipelines 创建 Service Networking 连接
在本部分中,您将创建一个 Service Networking 连接,用于通过 VPC 网络对等互连建立与 vertex-networking-vpc VPC 网络相关联的提供方服务。如需了解详情,请参阅 VPC 网络对等互连。
在 Cloud Shell 中,运行以下命令,并将 PROJECT_ID 替换为您的项目 ID:
projectid=PROJECT_ID gcloud config set project ${projectid}使用
gcloud compute addresses create设置预留 IP 地址范围:gcloud compute addresses create vertex-pipeline-subnet \ --global \ --purpose=VPC_PEERING \ --addresses=192.168.10.0 \ --prefix-length=24 \ --description="pipeline subnet" \ --network=vertex-networking-vpc使用
gcloud services vpc-peerings connect在vertex-networking-vpcVPC 网络与 Google 的 Service Networking 之间建立对等互连连接:gcloud services vpc-peerings connect \ --service=servicenetworking.googleapis.com \ --ranges=vertex-pipeline-subnet \ --network=vertex-networking-vpc更新 VPC 对等互连连接以启用自定义已学路由的导入和导出:
gcloud compute networks peerings update servicenetworking-googleapis-com \ --network=vertex-networking-vpc \ --import-custom-routes \ --export-custom-routes
从 pipeline-networking Cloud Router 通告流水线子网
在 Google Cloud 控制台中,前往 Cloud Router 页面。
在 Cloud Router 路由器列表中,点击
vertex-networking-vpc-router1。在路由器详情页面上,点击 修改。
点击添加自定义路由。
对于来源,选择自定义 IP 范围。
在 IP 地址范围字段中,输入以下 IP 地址范围:
192.168.10.0/24在说明字段中,输入以下文本:
Vertex AI Pipelines reserved subnet点击完成,然后点击保存。
创建流水线模板并将其上传到 Artifact Registry
在本部分中,您将创建和上传 Kubeflow Pipelines (KFP) 流水线模板。此模板包含一个工作流定义,可供单个用户或多个用户多次重复使用。
定义并编译流水线
在 JupyterLab 的 文件浏览器中,双击顶级文件夹。
选择文件 >新建 >笔记本。
在选择内核菜单中,选择
Python 3 (ipykernel),然后点击选择。在新的笔记本单元格中,运行以下命令,确保您拥有最新版本的
pip:!python -m pip install --upgrade pip运行以下命令,从 Python Package Index (PyPI) 安装 Google Cloud Pipeline Components SDK:
!pip install --upgrade google-cloud-pipeline-components安装完成后,依次选择内核 > 重启内核来重启内核,并确保该库可用于导入。
在新的笔记本单元中运行以下代码,以定义流水线:
from kfp import dsl # define the train-deploy pipeline @dsl.pipeline(name="custom-image-classification-pipeline") def custom_image_classification_pipeline( project: str, training_job_display_name: str, worker_pool_specs: list, base_output_dir: str, model_artifact_uri: str, prediction_container_uri: str, model_display_name: str, endpoint_display_name: str, network: str = '', location: str="us-central1", serving_machine_type: str="n1-standard-4", serving_min_replica_count: int=1, serving_max_replica_count: int=1 ): from google_cloud_pipeline_components.types import artifact_types from google_cloud_pipeline_components.v1.custom_job import CustomTrainingJobOp from google_cloud_pipeline_components.v1.model import ModelUploadOp from google_cloud_pipeline_components.v1.endpoint import (EndpointCreateOp, ModelDeployOp) from kfp.dsl import importer # Train the model task custom_job_task = CustomTrainingJobOp( project=project, display_name=training_job_display_name, worker_pool_specs=worker_pool_specs, base_output_directory=base_output_dir, location=location, network=network ) # Import the model task import_unmanaged_model_task = importer( artifact_uri=model_artifact_uri, artifact_class=artifact_types.UnmanagedContainerModel, metadata={ "containerSpec": { "imageUri": prediction_container_uri, }, }, ).after(custom_job_task) # Model upload task model_upload_op = ModelUploadOp( project=project, display_name=model_display_name, unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"], ) model_upload_op.after(import_unmanaged_model_task) # Create Endpoint task endpoint_create_op = EndpointCreateOp( project=project, display_name=endpoint_display_name, ) # Deploy the model to the endpoint ModelDeployOp( endpoint=endpoint_create_op.outputs["endpoint"], model=model_upload_op.outputs["model"], dedicated_resources_machine_type=serving_machine_type, dedicated_resources_min_replica_count=serving_min_replica_count, dedicated_resources_max_replica_count=serving_max_replica_count, )在新的笔记本单元格中运行以下代码,以编译流水线定义:
from kfp import compiler PIPELINE_FILE = "pipeline_config.yaml" compiler.Compiler().compile( pipeline_func=custom_image_classification_pipeline, package_path=PIPELINE_FILE, )在 文件浏览器中,文件列表中会显示一个名为
pipeline_config.yaml的文件。
创建 Artifact Registry 仓库
在新的笔记本单元中运行以下代码,以创建 KFP 类型的制品存储库:
REPO_NAME="fungi-repo" REGION="us-central1" !gcloud artifacts repositories create $REPO_NAME --location=$REGION --repository-format=KFP
将流水线模板上传到 Artifact Registry
在本部分中,您将配置 Kubeflow Pipelines SDK 注册表客户端,并从 JupyterLab 笔记本将已编译的流水线模板上传到 Artifact Registry。
在 JupyterLab 笔记本中,运行以下代码以上传流水线模板,并将 PROJECT_ID 替换为您的项目 ID:
PROJECT_ID = "PROJECT_ID" from kfp.registry import RegistryClient host = f"https://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}" client = RegistryClient(host=host) TEMPLATE_NAME, VERSION_NAME = client.upload_pipeline( file_name=PIPELINE_FILE, tags=["v1", "latest"], extra_headers={"description":"This is an example pipeline template."})在 Google Cloud 控制台中,如需验证您的模板是否已上传,请前往 Vertex AI Pipelines 模板。
如需打开选择制品库窗格,请点击选择制品库。
在代码库列表中,点击您创建的代码库 (
fungi-repo),然后点击选择。验证您的流水线 (
custom-image-classification-pipeline) 是否显示在列表中。
从本地触发流水线运行
在本部分中,您将使用 cURL 触发从本地应用运行的流水线,因为您的流水线模板和训练软件包已准备就绪。
提供流水线参数
在 JupyterLab 笔记本中,运行以下命令以验证流水线模板名称:
print (TEMPLATE_NAME)返回的模板名称为:
custom-image-classification-pipeline运行以下命令以获取流水线模板版本:
print (VERSION_NAME)返回的流水线模板版本名称如下所示:
sha256:41eea21e0d890460b6e6333c8070d7d23d314afd9c7314c165efd41cddff86c7记下完整的版本名称字符串。
在 Cloud Shell 中,运行以下命令,并将 PROJECT_ID 替换为您的项目 ID:
projectid=PROJECT_ID gcloud config set project ${projectid}登录到
on-prem-dataservice-host虚拟机实例:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iap在
on-prem-dataservice-host虚拟机实例中,使用文本编辑器(例如vim或nano)创建request_body.json文件,例如:sudo vim request_body.json将以下文本添加到
request_body.json文件:{ "displayName": "fungi-image-pipeline-job", "serviceAccount": "onprem-user-managed-sa@PROJECT_ID.iam.gserviceaccount.com", "runtimeConfig":{ "gcsOutputDirectory":"gs://pipelines-staging-bucket-PROJECT_ID/pipeline_root/", "parameterValues": { "project": "PROJECT_ID", "training_job_display_name": "fungi-image-training-job", "worker_pool_specs": [{ "machine_spec": { "machine_type": "n1-standard-4" }, "replica_count": 1, "python_package_spec":{ "executor_image_uri":"us-docker.pkg.dev/vertex-ai/training/tf-cpu.2-8.py310:latest", "package_uris": ["gs://pipelines-staging-bucket-PROJECT_ID/training_package/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args": ["--data-dir","/mnt/nfs/fungi_dataset/", "--epochs", "10"], "env": [{"name": "AIP_MODEL_DIR", "value": "gs://pipelines-staging-bucket-PROJECT_ID/model/"}] }, "nfs_mounts": [{ "server": "FILESTORE_INSTANCE_IP", "path": "/vol1", "mount_point": "/mnt/nfs/" }] }], "base_output_dir":"gs://pipelines-staging-bucket-PROJECT_ID", "model_artifact_uri":"gs://pipelines-staging-bucket-PROJECT_ID/model/", "prediction_container_uri":"us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest", "model_display_name":"fungi-image-model", "endpoint_display_name":"fungi-image-endpoint", "location": "us-central1", "serving_machine_type":"n1-standard-4", "network":"projects/PROJECT_NUMBER/global/networks/vertex-networking-vpc" } }, "templateUri": "https://us-central1-kfp.pkg.dev/PROJECT_ID/fungi-repo/custom-image-classification-pipeline/latest", "templateMetadata": { "version":"VERSION_NAME" } }替换以下值:
- PROJECT_ID:您的项目 ID
- PROJECT_NUMBER:项目编号。该编号与项目 ID 不同。您可以在Google Cloud 控制台中项目的项目设置页面上找到项目编号。
- FILESTORE_INSTANCE_IP:Filestore 实例 IP 地址,例如
10.243.208.2。您可以在实例的 Filestore 实例页面中找到此信息。 - VERSION_NAME:您在第 2 步中记下的流水线模板版本名称 (
sha256:...)。
按如下方式保存文件:
- 如果您使用的是
vim,请按Esc键,然后输入:wq以保存文件并退出。 - 如果您使用的是
nano,请输入Control+O并按Enter以保存该文件,然后输入Control+X以退出。
- 如果您使用的是
基于模板提交流水线运行
在
on-prem-dataservice-host虚拟机实例中,运行以下命令,将 PROJECT_ID 替换为您的项目 ID:curl -v -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ -d @request_body.json \ https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/pipelineJobs您看到的输出内容很长,但您需要关注的主要内容是以下这行,它表示服务正在准备运行流水线:
"state": "PIPELINE_STATE_PENDING"整个流水线运行大约需要 45 到 50 分钟。
在 Google Cloud 控制台的 Vertex AI 部分中,前往流水线页面中的运行标签页。
点击流水线运行的运行名称 (
custom-image-classification-pipeline)。此时会显示流水线运行页面,其中显示流水线的运行时图。流水线的摘要会显示在流水线运行分析窗格中。
如需了解如何理解运行时图中显示的信息,包括如何查看日志以及如何使用 Vertex ML Metadata 详细了解流水线的制品,请参阅直观呈现和分析流水线结果。