O Vertex AI Pipelines é um serviço gerenciado para criar, implantar e gerenciar fluxos de trabalho completos de machine learning (ML) na plataforma Google Cloud. É um ambiente sem servidor para executar pipelines, para que você não precise se preocupar com o gerenciamento da infraestrutura.
Neste tutorial, você vai usar o Vertex AI Pipelines para executar um job de treinamento personalizado e implantar o modelo treinado na Vertex AI, em um ambiente de rede híbrida.
O processo inteiro leva de duas a três horas, incluindo cerca de 50 minutos para a execução do pipeline.
Este tutorial é destinado a administradores de redes empresariais, cientistas de dados e pesquisadores que estão familiarizados com a Vertex AI, a nuvem privada virtual (VPC), o console do Google Cloud e o Cloud Shell. Conhecer o Vertex AI Workbench é útil, mas não é obrigatório.
Objetivos
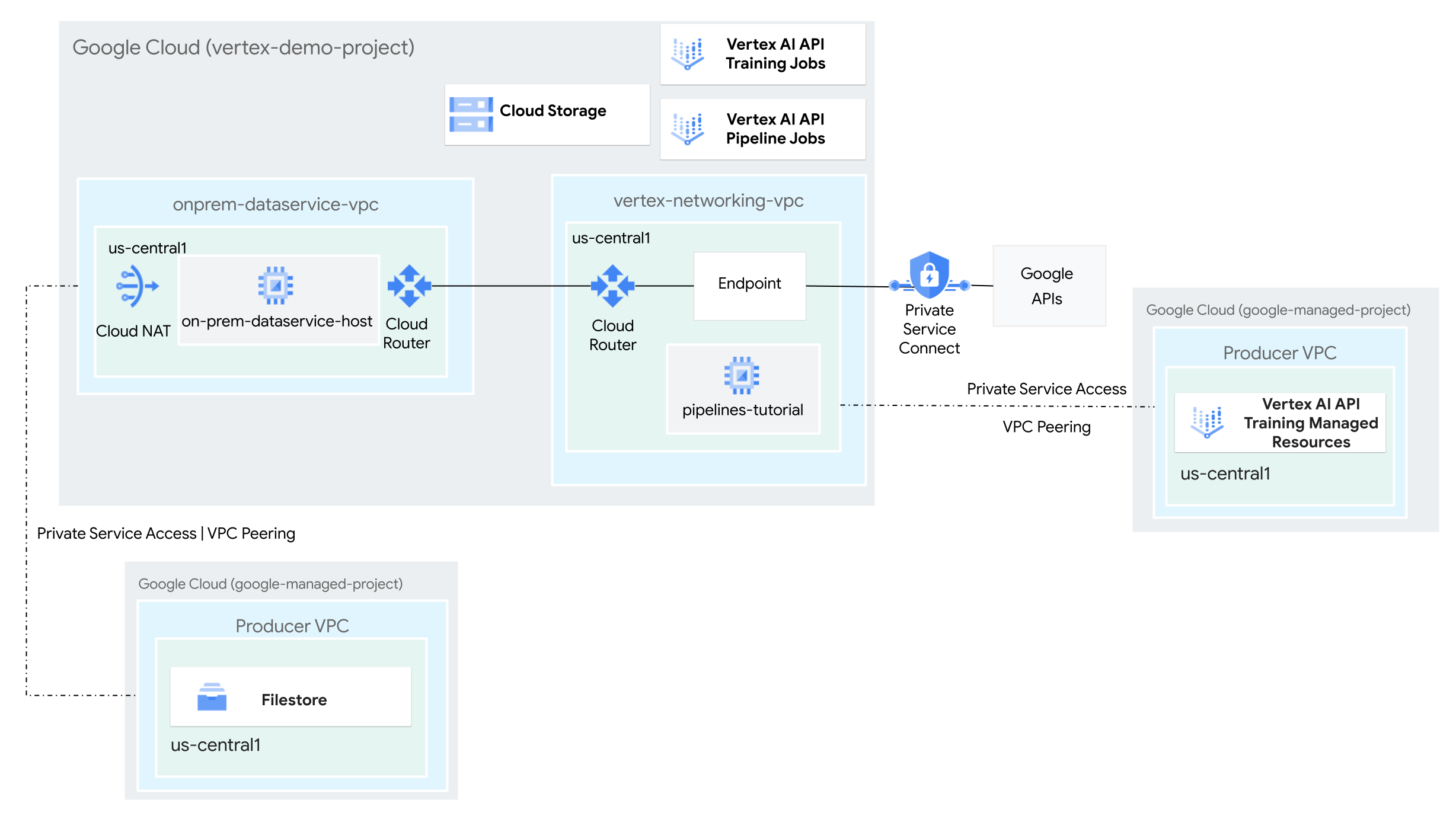
- Crie duas redes de nuvem privada virtual (VPC):
- Uma delas (
vertex-networking-vpc) é para usar a API Vertex AI Pipelines para criar e hospedar um modelo de pipeline, que será usado para treinar um modelo de machine learning e implantá-lo em um endpoint. - A outra (
onprem-dataservice-vpc) representa uma rede local.
- Uma delas (
- Conecte as duas redes VPC da seguinte maneira:
- Implante gateways de VPN de alta disponibilidade, túneis do Cloud VPN e
Cloud Routers para conectar
vertex-networking-vpceonprem-dataservice-vpc. - Crie um endpoint do Private Service Connect (PSC) para encaminhar solicitações particulares à API REST Vertex AI Pipelines.
- Configure uma divulgação de rota personalizada do Cloud Router em
vertex-networking-vpcpara anunciar rotas para o endpoint do Private Service Connect paraonprem-dataservice-vpc.
- Implante gateways de VPN de alta disponibilidade, túneis do Cloud VPN e
Cloud Routers para conectar
- Crie uma instância do Filestore na rede VPC
onprem-dataservice-vpce adicione dados de treinamento a ela em um compartilhamento NFS. - Crie um aplicativo de pacote Python para o job de treinamento.
- Crie um modelo de job do Vertex AI Pipelines para fazer o seguinte:
- Criar e executar o job de treinamento com os dados do compartilhamento NFS.
- Importar o modelo treinado e fazer o upload dele no Vertex AI Model Registry.
- Criar um endpoint da Vertex AI para previsões on-line.
- Implantar o modelo no endpoint.
- Fazer upload do modelo de pipeline em um repositório do Artifact Registry.
- Usar a API REST Vertex AI Pipelines para acionar uma execução de pipeline em um host de serviço de dados local (
on-prem-dataservice-host).
Custos
Neste documento, você vai usar os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custo baseada na sua projeção de uso,
use a calculadora de preços.
Ao concluir as tarefas descritas neste documento, é possível evitar o faturamento contínuo excluindo os recursos criados. Saiba mais em Limpeza.
Antes de começar
-
In the Google Cloud console, go to the project selector page.
-
Select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- Abra o Cloud Shell para executar os comandos listados neste tutorial. O Cloud Shell é um ambiente shell interativo para o Google Cloud que permite gerenciar projetos e recursos a partir do navegador da Web.
- No Cloud Shell, defina o projeto atual como o ID do projeto do Google Cloud e armazene o mesmo ID do projeto na variável de shell
projectid:projectid="PROJECT_ID" gcloud config set project ${projectid} - Se você não é proprietário do projeto, peça ao proprietário que conceda a você o papel Administrador de IAM do projeto (
roles/resourcemanager.projectIamAdmin). É preciso ter esse papel para conceder papéis do IAM na próxima etapa. -
Grant roles to your user account. Run the following command once for each of the following IAM roles:
roles/artifactregistry.admin, roles/artifactregistry.repoAdmin, roles/compute.instanceAdmin.v1, roles/compute.networkAdmin, roles/compute.securityAdmin, roles/dns.admin, roles/file.editor, roles/logging.viewer, roles/logging.admin, roles/notebooks.admin, roles/iam.serviceAccountAdmin, roles/iam.serviceAccountUser, roles/servicedirectory.editor, roles/servicemanagement.quotaAdmin, roles/serviceusage.serviceUsageAdmin, roles/storage.admin, roles/storage.objectAdmin, roles/aiplatform.admin, roles/aiplatform.user, roles/aiplatform.viewer, roles/iap.admin, roles/iap.tunnelResourceAccessor, roles/resourcemanager.projectIamAdmingcloud projects add-iam-policy-binding PROJECT_ID --member="user:USER_IDENTIFIER" --role=ROLE
- Replace
PROJECT_IDwith your project ID. -
Replace
USER_IDENTIFIERwith the identifier for your user account. For example,user:myemail@example.com. - Replace
ROLEwith each individual role.
- Replace
-
Enable the DNS, Artifact Registry, IAM, Compute Engine, Cloud Logging, Network Connectivity, Notebooks, Cloud Filestore, Service Networking, Service Usage, and Vertex AI APIs:
gcloud services enable dns.googleapis.com
artifactregistry.googleapis.com iam.googleapis.com compute.googleapis.com logging.googleapis.com networkconnectivity.googleapis.com notebooks.googleapis.com file.googleapis.com servicenetworking.googleapis.com serviceusage.googleapis.com aiplatform.googleapis.com
Criar as redes VPC
Nesta seção, você vai criar duas redes VPC: uma para acessar as APIs do Google do Vertex AI Pipelines e outra para simular uma rede local. Em cada uma das duas redes VPC, você vai criar um Cloud Router e um gateway do Cloud NAT. O gateway do Cloud NAT permite que instâncias de máquina virtual (VM) do Compute Engine sem endereços IP externos iniciem conexões externas.
No Cloud Shell, execute os seguintes comandos, substituindo PROJECT_ID pelo ID do projeto:
projectid=PROJECT_ID gcloud config set project ${projectid}Crie a rede VPC
vertex-networking-vpc:gcloud compute networks create vertex-networking-vpc \ --subnet-mode customNa rede
vertex-networking-vpc, crie uma sub-rede chamadapipeline-networking-subnet1, com um intervalo IPv4 principal de10.0.0.0/24:gcloud compute networks subnets create pipeline-networking-subnet1 \ --range=10.0.0.0/24 \ --network=vertex-networking-vpc \ --region=us-central1 \ --enable-private-ip-google-accessCrie a rede VPC para simular a rede local (
onprem-dataservice-vpc):gcloud compute networks create onprem-dataservice-vpc \ --subnet-mode customNa rede
onprem-dataservice-vpc, crie uma sub-rede chamadaonprem-dataservice-vpc-subnet1, com um intervalo IPv4 principal de172.16.10.0/24:gcloud compute networks subnets create onprem-dataservice-vpc-subnet1 \ --network onprem-dataservice-vpc \ --range 172.16.10.0/24 \ --region us-central1 \ --enable-private-ip-google-access
Verificar se as redes VPC estão configuradas corretamente
No console do Google Cloud, acesse a guia Redes no projeto atual na página Redes VPC.
Na lista de redes VPC, verifique se as duas redes foram criadas:
vertex-networking-vpceonprem-dataservice-vpc.Clique na guia Sub-redes no projeto atual.
Na lista de sub-redes VPC, verifique se as sub-redes
pipeline-networking-subnet1eonprem-dataservice-vpc-subnet1foram criadas.
Configurar conectividade híbrida
Nesta seção, você cria dois gateways de VPN de alta disponibilidade
conectados entre si. Um fica na
rede VPC vertex-networking-vpc. O outro fica na
rede VPC onprem-dataservice-vpc. Cada gateway contém um Cloud Router e um par de túneis VPN.
Criar os gateways de VPN de alta disponibilidade
No Cloud Shell, crie o gateway de VPN de alta disponibilidade para a rede VPC
vertex-networking-vpc:gcloud compute vpn-gateways create vertex-networking-vpn-gw1 \ --network vertex-networking-vpc \ --region us-central1Crie o gateway de VPN de alta disponibilidade para a rede VPC
onprem-dataservice-vpc:gcloud compute vpn-gateways create onprem-vpn-gw1 \ --network onprem-dataservice-vpc \ --region us-central1No console do Google Cloud, acesse a guia Gateways do Cloud VPN na página VPN.
Verifique se os dois gateways (
vertex-networking-vpn-gw1eonprem-vpn-gw1) foram criados e se cada gateway tem dois endereços IP de interface.
Criar Cloud Routers e gateways do Cloud NAT
Em cada uma das duas redes VPC, você vai criar dois Cloud Routers: um para usar com o Cloud NAT e outro para gerenciar as sessões BGP da VPN de alta disponibilidade.
No Cloud Shell, crie um Cloud Router para a rede VPC
vertex-networking-vpc, que será usada para a VPN:gcloud compute routers create vertex-networking-vpc-router1 \ --region us-central1 \ --network vertex-networking-vpc \ --asn 65001Crie um Cloud Router para a rede VPC
onprem-dataservice-vpc, que será usada para a VPN:gcloud compute routers create onprem-dataservice-vpc-router1 \ --region us-central1 \ --network onprem-dataservice-vpc \ --asn 65002Crie um Cloud Router para a rede VPC
vertex-networking-vpc, que será usada para o Cloud NAT:gcloud compute routers create cloud-router-us-central1-vertex-nat \ --network vertex-networking-vpc \ --region us-central1Configure um gateway do Cloud NAT no Cloud Router:
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-vertex-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1Crie um Cloud Router para a rede VPC
onprem-dataservice-vpc, que será usada para o Cloud NAT:gcloud compute routers create cloud-router-us-central1-onprem-nat \ --network onprem-dataservice-vpc \ --region us-central1Configure um gateway do Cloud NAT no Cloud Router:
gcloud compute routers nats create cloud-nat-us-central1-on-prem \ --router=cloud-router-us-central1-onprem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1No console do Google Cloud, acesse a página do Cloud Routers.
Na lista Cloud Routers, verifique se os seguintes roteadores foram criados:
cloud-router-us-central1-onprem-natcloud-router-us-central1-vertex-natonprem-dataservice-vpc-router1vertex-networking-vpc-router1
Talvez seja necessário atualizar a guia do console do Google Cloud para que os novos valores apareçam.
Na lista de Cloud Routers, clique em
cloud-router-us-central1-vertex-nat.Na página Detalhes do roteador, verifique se o gateway
cloud-nat-us-central1do Cloud NAT foi criado.Clique na seta para voltar e retorne à página Cloud Routers.
Na lista de Cloud Routers, clique em
cloud-router-us-central1-onprem-nat.Na página Detalhes do roteador, verifique se o gateway
cloud-nat-us-central1-on-premdo Cloud NAT foi criado.
Criar túneis VPN
No Cloud Shell, na rede
vertex-networking-vpc, crie um túnel VPN chamadovertex-networking-vpc-tunnel0:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel0 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 0Na rede
vertex-networking-vpc, crie um túnel de VPN chamadovertex-networking-vpc-tunnel1:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel1 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 1Na rede
onprem-dataservice-vpc, crie um túnel de VPN chamadoonprem-dataservice-vpc-tunnel0:gcloud compute vpn-tunnels create onprem-dataservice-vpc-tunnel0 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router onprem-dataservice-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 0Na rede
onprem-dataservice-vpc, crie um túnel de VPN chamadoonprem-dataservice-vpc-tunnel1:gcloud compute vpn-tunnels create onprem-dataservice-vpc-tunnel1 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router onprem-dataservice-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 1No Console do Google Cloud, acesse a página VPN.
Na lista de túneis de VPN, verifique se os quatro túneis de VPN foram criados.
Criar sessões do BGP
O Cloud Router usa o protocolo de gateway de borda (BGP) para trocar rotas entre
a rede VPC (neste caso, vertex-networking-vpc)
e a rede local (representada por onprem-dataservice-vpc). No Cloud Router,
você configura uma interface e um peering do BGP para o roteador local.
A interface e a configuração de peering do BGP formam uma sessão do BGP.
Nesta seção, você vai criar duas sessões do BGP para vertex-networking-vpc e duas para onprem-dataservice-vpc.
Depois que você configurar as interfaces e os peerings do BGP entre os roteadores, eles começarão a trocar rotas de forma automática.
Estabelecer as sessões do BGP de vertex-networking-vpc
No Cloud Shell, na rede
vertex-networking-vpc, crie uma interface do BGP paravertex-networking-vpc-tunnel0:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.0.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel0 \ --region us-central1Na rede
vertex-networking-vpc, crie um peering do BGP parabgp-onprem-tunnel0:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel0 \ --interface if-tunnel0-to-onprem \ --peer-ip-address 169.254.0.2 \ --peer-asn 65002 \ --region us-central1Na rede
vertex-networking-vpc, crie uma interface do BGP paravertex-networking-vpc-tunnel1:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel1 \ --region us-central1Na rede
vertex-networking-vpc, crie um peering do BGP parabgp-onprem-tunnel1:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel1 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central1
Estabeleça sessões do BGP para onprem-dataservice-vpc
Na rede
onprem-dataservice-vpc, crie uma interface do BGP paraonprem-dataservice-vpc-tunnel0:gcloud compute routers add-interface onprem-dataservice-vpc-router1 \ --interface-name if-tunnel0-to-vertex-networking-vpc \ --ip-address 169.254.0.2 \ --mask-length 30 \ --vpn-tunnel onprem-dataservice-vpc-tunnel0 \ --region us-central1Na rede
onprem-dataservice-vpc, crie um peering do BGP parabgp-vertex-networking-vpc-tunnel0:gcloud compute routers add-bgp-peer onprem-dataservice-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel0 \ --interface if-tunnel0-to-vertex-networking-vpc \ --peer-ip-address 169.254.0.1 \ --peer-asn 65001 \ --region us-central1Na rede
onprem-dataservice-vpc, crie uma interface do BGP paraonprem-dataservice-vpc-tunnel1:gcloud compute routers add-interface onprem-dataservice-vpc-router1 \ --interface-name if-tunnel1-to-vertex-networking-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel onprem-dataservice-vpc-tunnel1 \ --region us-central1Na rede
onprem-dataservice-vpc, crie um peering do BGP parabgp-vertex-networking-vpc-tunnel1:gcloud compute routers add-bgp-peer onprem-dataservice-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel1 \ --interface if-tunnel1-to-vertex-networking-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central1
Valide a criação da sessão do BGP
No Console do Google Cloud, acesse a página VPN.
Na lista de túneis de VPN, verifique se o valor na coluna Status da sessão do BGP de cada túnel mudou de Configurar sessão do BGP para O BGP foi estabelecido. Talvez seja necessário atualizar a guia do console do Google Cloud para que os novos valores apareçam.
Validar as rotas aprendidas de onprem-dataservice-vpc
No Console do Google Cloud, acesse a página Redes VPC.
Na lista de redes VPC, clique em
onprem-dataservice-vpc.Clique na guia Rotas.
Selecione us-central1 (Iowa) na lista Região e clique em Visualizar.
Na coluna Intervalo de IPs de destino, verifique se o intervalo de IP de sub-rede
pipeline-networking-subnet1(10.0.0.0/24) aparece duas vezes.Talvez seja necessário atualizar a guia do console do Google Cloud para que as duas entradas apareçam.
Validar as rotas aprendidas de vertex-networking-vpc
Clique na seta para voltar e retorne à página Redes VPC.
Na lista de redes VPC, clique em
vertex-networking-vpc.Clique na guia Rotas.
Selecione us-central1 (Iowa) na lista Região e clique em Visualizar.
Na coluna Intervalo de IPs de destino, verifique se o intervalo de IP da sub-rede
onprem-dataservice-vpc-subnet1(172.16.10.0/24) aparece duas vezes.
Criar um endpoint do Private Service Connect para APIs do Google
Nesta seção, você vai criar um endpoint do Private Service Connect para APIs do Google que serão usadas para acessar a API REST Vertex AI Pipelines na rede local.
No Cloud Shell, reserve um endereço IP de endpoint do consumidor, que será usado para acessar as APIs do Google:
gcloud compute addresses create psc-googleapi-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=192.168.0.1 \ --network=vertex-networking-vpcCrie uma regra de encaminhamento para conectar o endpoint aos serviços e APIs do Google.
gcloud compute forwarding-rules create pscvertex \ --global \ --network=vertex-networking-vpc \ --address=psc-googleapi-ip \ --target-google-apis-bundle=all-apis
Criar divulgações de rota personalizadas para vertex-networking-vpc
Nesta seção, você vai criar uma
divulgação de rota personalizada
para vertex-networking-vpc-router1 (o Cloud Router de
vertex-networking-vpc) para divulgar o endereço IP do endpoint do PSC
para a rede VPC onprem-dataservice-vpc.
No console do Google Cloud, acesse a página do Cloud Routers.
Na lista de Cloud Routers, clique em
vertex-networking-vpc-router1.Na página Detalhes do Router, clique em Editar.
Na seção Rotas divulgadas, para Rotas, selecione Criar rotas personalizadas.
Selecione a caixa de seleção Divulgar todas as sub-redes visíveis para o Cloud Router para continuar divulgando as sub-redes disponíveis para o Cloud Router. A ativação dessa opção imita o comportamento do Cloud Router no modo de divulgação padrão.
Clique em Adicionar uma rota personalizada.
Em Origem, selecione Intervalo de IP personalizado.
Em Intervalo de endereços IP, insira o seguinte endereço IP:
192.168.0.1Para Descrição, insira o seguinte texto:
Custom route to advertise Private Service Connect endpoint IP addressClique em Concluído e depois em Salvar.
Valide se o onprem-dataservice-vpc aprendeu as rotas divulgadas
No console do Google Cloud, acesse a página Rotas.
Na guia Rotas efetivas, faça o seguinte:
- Em Rede, escolha
onprem-dataservice-vpc. - Em Região, escolha
us-central1 (Iowa). - Clique em Visualizar.
Na lista de rotas, verifique se há duas entradas com nomes que começam com
onprem-dataservice-vpc-router1-bgp-vertex-networking-vpc-tunnel0e duas que começam comonprem-dataservice-vpc-router1-bgp-vertex-networking-vpc-tunnel1.Se essas entradas não aparecerem imediatamente, aguarde alguns minutos e atualize a guia do console do Google Cloud.
Verifique se duas das entradas têm o Intervalo de IP de destino
192.168.0.1/32e duas têm o Intervalo de IP de destino10.0.0.0/24.
- Em Rede, escolha
Criar uma instância de VM em onprem-dataservice-vpc
Nesta seção, você vai criar uma instância de VM que simula um host de serviço de dados local. Seguindo as práticas recomendadas do Compute Engine e IAM, essa VM usa uma conta de serviço gerenciada pelo usuário em vez da conta padrão de serviço do Compute Engine.
Criar a conta de serviço gerenciada pelo usuário para a instância de VM
No Cloud Shell, execute os seguintes comandos, substituindo PROJECT_ID pelo ID do projeto:
projectid=PROJECT_ID gcloud config set project ${projectid}Crie uma conta de serviço chamada
onprem-user-managed-sa:gcloud iam service-accounts create onprem-user-managed-sa \ --display-name="onprem-user-managed-sa"Atribua o papel Usuário da Vertex AI (
roles/aiplatform.user) à conta de serviço:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Atribua o papel Leitor da Vertex AI (
roles/aiplatform.viewer):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.viewer"Atribua o papel Editor do Cloud Filestore (
roles/file.editor):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/file.editor"Atribua o papel Administrador da conta de serviço (
roles/iam.serviceAccountAdmin):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/iam.serviceAccountAdmin"Atribua o papel Usuário da conta de serviço (
roles/iam.serviceAccountUser):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/iam.serviceAccountUser"Atribua o papel Leitor do Artifact Registry (
roles/artifactregistry.reader):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.reader"Atribua o papel Administrador de objetos do Storage (
roles/storage.objectAdmin):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.objectAdmin"Atribua o papel Administrador da geração de registros (
roles/logging.admin):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/logging.admin"
Criar a instância de VM on-prem-dataservice-host
A instância de VM criada não tem um endereço IP externo e não permite acesso direto pela Internet. Para ativar o acesso administrativo à VM, use o encaminhamento de TCP do Identity-Aware Proxy (IAP).
No Cloud Shell, crie a instância de VM
on-prem-dataservice-host:gcloud compute instances create on-prem-dataservice-host \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=onprem-dataservice-vpc-subnet1 \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --shielded-secure-boot \ --service-account=onprem-user-managed-sa@$projectid.iam.gserviceaccount.com \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"Crie uma regra de firewall para permitir que o IAP se conecte à sua instância de VM:
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network onprem-dataservice-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
Atualizar o arquivo /etc/hosts para apontar para o endpoint do PSC
Nesta seção, você vai adicionar uma linha ao arquivo /etc/hosts que faz com que as solicitações
enviadas ao endpoint de serviço público (us-central1-aiplatform.googleapis.com)
sejam redirecionadas para o endpoint do PSC (192.168.0.1).
No Cloud Shell, faça login na instância de VM
on-prem-dataservice-hostusando o IAP:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapNa instância de VM
on-prem-dataservice-host, use um editor de texto, comovimounanopara abrir o arquivo/etc/hosts, por exemplo:sudo vim /etc/hostsAdicione a linha a seguir ao arquivo:
192.168.0.1 us-central1-aiplatform.googleapis.comEssa linha atribui o endereço IP do endpoint do PSC (
192.168.0.1) ao nome de domínio totalmente qualificado da API Vertex AI do Google (us-central1-aiplatform.googleapis.com).O arquivo editado deve ficar assim:
127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 192.168.0.1 us-central1-aiplatform.googleapis.com # Added by you 172.16.10.6 on-prem-dataservice-host.us-central1-a.c.PROJECT_ID.internal on-prem-dataservice-host # Added by Google 169.254.169.254 metadata.google.internal # Added by GoogleSalve o arquivo da seguinte maneira:
- Se você estiver usando
vim, pressione a teclaEsce, em seguida, digite:wqpara salvar o arquivo e sair. - Se você estiver usando
nano, digiteControl+Oe pressioneEnterpara salvar o arquivo. Em seguida, digiteControl+Xpara sair.
- Se você estiver usando
Dê um ping no endpoint da API Vertex AI da seguinte maneira:
ping us-central1-aiplatform.googleapis.comO comando
pingvai mostrar a seguinte saída.192.168.0.1é o endereço IP do endpoint do PSC:PING us-central1-aiplatform.googleapis.com (192.168.0.1) 56(84) bytes of data.Digite
Control+Cpara sair deping.Digite
exitpara sair da instância de VMon-prem-dataservice-hoste retornar ao prompt do Cloud Shell.
Configurar a rede de uma instância do Filestore
Nesta seção, você vai ativar o acesso a serviços particulares para a rede VPC, uma etapa preparatória para criar uma instância do Filestore e montá-la como um compartilhamento do sistema de arquivos de rede (NFS, na sigla em inglês). Para entender o que você vai fazer nesta seção e na próxima, consulte Ativar um compartilhamento de NFS para treinamento personalizado e Configurar o peering de rede VPC.
Ativar o acesso a serviços particulares em uma rede VPC
Nesta seção, você vai criar uma conexão de rede de serviços e usá-la para ativar o acesso a serviços particulares à rede VPC onprem-dataservice-vpc por meio do peering de rede VPC.
No Cloud Shell, defina um intervalo de endereços IP reservados usando
gcloud compute addresses create:gcloud compute addresses create filestore-subnet \ --global \ --purpose=VPC_PEERING \ --addresses=10.243.208.0 \ --prefix-length=24 \ --description="filestore subnet" \ --network=onprem-dataservice-vpcEstabeleça uma conexão de peering entre a rede VPC
onprem-dataservice-vpce a rede de serviços do Google usandogcloud services vpc-peerings connect:gcloud services vpc-peerings connect \ --service=servicenetworking.googleapis.com \ --ranges=filestore-subnet \ --network=onprem-dataservice-vpcModifique o peering de rede VPC para ativar a importação e exportação de rotas aprendidas personalizadas:
gcloud compute networks peerings update servicenetworking-googleapis-com \ --network=onprem-dataservice-vpc \ --import-custom-routes \ --export-custom-routesNo console do Google Cloud, acesse a página Peering de rede VPC.
Na lista de peerings de VPC, verifique se há uma entrada para o peering entre
servicenetworking.googleapis.come a rede VPConprem-dataservice-vpc.
Criar divulgações de rota personalizadas para filestore-subnet
No console do Google Cloud, acesse a página do Cloud Routers.
Na lista de Cloud Routers, clique em
onprem-dataservice-vpc-router1.Na página Detalhes do Router, clique em Editar.
Na seção Rotas divulgadas, para Rotas, selecione Criar rotas personalizadas.
Selecione a caixa de seleção Divulgar todas as sub-redes visíveis para o Cloud Router para continuar divulgando as sub-redes disponíveis para o Cloud Router. A ativação dessa opção imita o comportamento do Cloud Router no modo de divulgação padrão.
Clique em Adicionar uma rota personalizada.
Em Origem, selecione Intervalo de IP personalizado.
Em Intervalo de endereços IP, digite o seguinte endereço IP:
10.243.208.0/24Em Descrição, digite o seguinte:
Filestore reserved IP address rangeClique em Concluído e depois em Salvar.
Criar a instância do Filestore na rede onprem-dataservice-vpc
Depois de ativar o acesso a serviços particulares na sua rede VPC, crie uma instância do Filestore e monte a instância como um compartilhamento NFS para o job de treinamento personalizado. Isso permite que os jobs de treinamento acessem arquivos remotos como se fossem locais, permitindo alta capacidade de processamento e baixa latência.
Criar a instância do Filestore
No console do Google Cloud, acesse a página Instâncias do Filestore.
Clique em Criar instância e configure a instância da seguinte maneira:
Em ID da instância, digite o seguinte:
image-data-instanceEm Tipo de instância, selecione Básico.
Em Tipo de armazenamento, selecione HDD.
Em Alocar capacidade, configure 1
TiB.Em Região, selecione us-central1. Em Zona, selecione us-central1-c.
Defina a rede VPC como
onprem-dataservice-vpc.Em Intervalo de IPs alocado, selecione Use um intervalo de IP alocado vigente e escolha
filestore-subnet.Em Nome do compartilhamento de arquivos, digite:
vol1Em Controles de acesso, selecione Permitir acesso a todos os clientes na rede VPC.
Clique em Criar.
Anote o endereço IP da nova instância do Filestore. Talvez seja necessário atualizar a guia do console do Google Cloud para que a nova instância apareça.
Montar o compartilhamento de arquivos do Filestore
No Cloud Shell, execute os seguintes comandos, substituindo PROJECT_ID pelo ID do projeto:
projectid=PROJECT_ID gcloud config set project ${projectid}Faça login na instância de VM
on-prem-dataservice-host:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapInstale o pacote NFS na instância de VM:
sudo apt-get update -y sudo apt-get -y install nfs-commonCrie um diretório de montagem para o compartilhamento de arquivos do Filestore:
sudo mkdir -p /mnt/nfsMonte o compartilhamento de arquivos, substituindo FILESTORE_INSTANCE_IP pelo endereço IP da sua instância do Filestore:
sudo mount FILESTORE_INSTANCE_IP:/vol1 /mnt/nfsSe a conexão expirar, verifique se o endereço IP da instância do Filestore está correto.
Execute este comando para verificar se a montagem do NFS foi concluída:
df -hVerifique se o compartilhamento de arquivos
/mnt/nfsaparece no resultado:Filesystem Size Used Avail Use% Mounted on udev 1.8G 0 1.8G 0% /dev tmpfs 368M 396K 368M 1% /run /dev/sda1 9.7G 1.9G 7.3G 21% / tmpfs 1.8G 0 1.8G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock /dev/sda15 124M 11M 114M 9% /boot/efi tmpfs 368M 0 368M 0% /run/user 10.243.208.2:/vol1 1007G 0 956G 0% /mnt/nfsMude as permissões para tornar o compartilhamento de arquivos acessível:
sudo chmod go+rw /mnt/nfs
Baixar o conjunto de dados no compartilhamento de arquivos
Na instância de VM
on-prem-dataservice-host, baixe o conjunto de dados para o compartilhamento de arquivos:gcloud storage cp gs://cloud-samples-data/vertex-ai/dataset-management/datasets/fungi_dataset /mnt/nfs/ --recursiveO download leva alguns minutos.
Execute este comando para confirmar se o conjunto de dados foi copiado:
sudo du -sh /mnt/nfsA resposta esperada é:
104M /mnt/nfsDigite
exitpara sair da instância de VMon-prem-dataservice-hoste retornar ao prompt do Cloud Shell.
Criar um bucket de preparo para o pipeline
O Vertex AI Pipelines armazena os artefatos das execuções de pipeline usando o Cloud Storage. Antes de executar o pipeline, você precisa criar um bucket do Cloud Storage para preparar as execuções de pipeline.
No Cloud Shell, crie um bucket do Cloud Storage.
gcloud storage buckets create gs://pipelines-staging-bucket-$projectid --location=us-central1
Criar uma conta de serviço gerenciada pelo usuário para o Vertex AI Workbench
No Cloud Shell, crie uma conta de serviço:
gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"Atribua o papel Usuário da Vertex AI (
roles/aiplatform.user) à conta de serviço:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Atribua o papel Administrador do Artifact Registry (
artifactregistry.admin):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.admin"Atribua o papel Administrador de armazenamento (
storage.admin):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.admin"
Criar o aplicativo de treinamento Python
Nesta seção, você vai criar uma instância do Vertex AI Workbench e usá-la para criar um pacote de aplicativo de treinamento personalizado em Python.
Criar uma instância do Vertex AI Workbench
No console do Google Cloud, acesse a guia Instâncias na página do Vertex AI Workbench.
Clique em Criar novo e em Opções avançadas.
A página Nova instância será aberta.
Na página Nova instância, na seção Detalhes, digite as seguintes informações da nova instância e clique em Continuar:
Nome: digite o seguinte, substituindo PROJECT_ID pelo ID do projeto:
pipeline-tutorial-PROJECT_IDRegião: selecione us-central1.
Zona: selecione us-central1-a.
Desmarque a caixa de seleção Ativar sessões interativas do Dataproc sem servidor.
Na seção Ambiente, clique em Continuar.
Na seção Tipo de máquina, preencha as seguintes informações e clique em Continuar:
- Tipo de máquina: escolha N1 e selecione
n1-standard-4no menu Tipo de máquina. VM protegida: marque as seguintes caixas de seleção:
- inicialização segura;
- Módulo de plataforma confiável e virtual (vTPM)
- monitoramento de integridade
- Tipo de máquina: escolha N1 e selecione
Na seção Discos, verifique se a Chave de criptografia gerenciada pelo Google está selecionada e clique em Continuar:
Na seção Rede, forneça as informações a seguir e clique em Continuar:
Rede: selecione Rede neste projeto e siga as seguintes etapas:
No campo Rede, selecione vertex-networking-vpc.
No campo Sub-rede, selecione pipeline-networking-subnet1.
Desmarque a caixa de seleção Atribuir endereço IP externo. A não atribuição de um endereço IP externo impede que a instância receba comunicações não solicitadas da Internet ou de outras redes VPC.
Marque a caixa de seleção Permitir acesso ao proxy.
Na seção IAM e segurança, forneça as informações a seguir e clique em Continuar:
IAM e segurança: para conceder a um único usuário acesso à interface do JupyterLab da instância, siga as seguintes etapas:
- Selecione Conta de serviço.
- Desmarque a caixa de seleção Usar conta de serviço padrão do Compute Engine.
Essa etapa é importante porque a conta de serviço padrão
do Compute Engine (e, portanto, o único usuário que você acabou de especificar) pode receber o papel de Editor (
roles/editor) no projeto. No campo E-mail da conta de serviço, digite o seguinte, substituindo PROJECT_ID pelo ID do projeto:
workbench-sa@PROJECT_ID.iam.gserviceaccount.comEsse é o endereço de e-mail da conta de serviço personalizada que você criou anteriormente. Essa conta de serviço tem permissões limitadas.
Para saber mais sobre como conceder acesso, consulte Gerenciar o acesso à interface do JupyterLab de uma instância do Vertex AI Workbench.
Opções de segurança: desmarque a caixa de seleção a seguir:
- Acesso raiz à instância
Marque a seguinte caixa de seleção:
- O nbconvert
nbconvertpermite que os usuários exportem e baixem um arquivo de notebook como outro tipo de arquivo, como HTML, PDF ou LaTeX. Essa configuração é exigida por alguns dos notebooks no repositório do GitHub da IA generativa do Google Cloud.
Desmarque a seguinte caixa de seleção:
- Permitir downloads do arquivo
Marque a seguinte caixa de seleção, a menos que você esteja em um ambiente de produção:
- Acesso ao terminal: permite acessar a instância pelo terminal na interface de usuário do JupyterLab.
Na seção Integridade do sistema, remova Upgrade automático do ambiente e preencha o seguinte:
Em Relatórios, marque as seguintes caixas de seleção:
- Relatar a integridade do sistema
- Relatar métricas personalizadas para o Cloud Monitoring
- Instalar o Cloud Monitoring
- Informar o status de DNS dos domínios obrigatórios do Google
Clique em Criar e aguarde alguns minutos para que a instância do Vertex AI Workbench seja criada.
Executar o aplicativo de treinamento na instância do Vertex AI Workbench
No console do Google Cloud, acesse a guia Instâncias na página do Vertex AI Workbench.
Ao lado do nome da instância do Vertex AI Workbench (
pipeline-tutorial-PROJECT_ID), em que PROJECT_ID é o ID do projeto, clique em Abrir JupyterLab.A instância do Vertex AI Workbench será aberta no JupyterLab.
Selecione Arquivo > Novo > Terminal.
No terminal JupyterLab (não no Cloud Shell), defina uma variável de ambiente para o projeto. Substitua PROJECT_ID pelo código do projeto:
projectid=PROJECT_IDCrie os diretórios pai do aplicativo de treinamento (ainda no terminal do JupyterLab):
mkdir fungi_training_package mkdir fungi_training_package/trainerNo Navegador de arquivos, clique duas vezes na pasta
fungi_training_packagee depois na pastatrainer.No File Browser, clique com o botão direito do mouse na lista de arquivos vazia (sob o título Nome) e selecione Novo arquivo.
Clique com o botão direito do mouse no novo arquivo e selecione Renomear arquivo.
Renomeie o arquivo de
untitled.txtparatask.py.Clique duas vezes no arquivo do
task.pypara abri-lo.Copie o seguinte código em
task.py:# Import the libraries import tensorflow as tf from tensorflow.python.client import device_lib import argparse import os import sys # add parser arguments parser = argparse.ArgumentParser() parser.add_argument('--data-dir', dest='dataset_dir', type=str, help='Dir to access dataset.') parser.add_argument('--model-dir', dest='model_dir', default=os.getenv("AIP_MODEL_DIR"), type=str, help='Dir to save the model.') parser.add_argument('--epochs', dest='epochs', default=10, type=int, help='Number of epochs.') parser.add_argument('--batch-size', dest='batch_size', default=32, type=int, help='Number of images per batch.') parser.add_argument('--distribute', dest='distribute', default='single', type=str, help='distributed training strategy.') args = parser.parse_args() # print the tf version and config print('Python Version = {}'.format(sys.version)) print('TensorFlow Version = {}'.format(tf.__version__)) print('TF_CONFIG = {}'.format(os.environ.get('TF_CONFIG', 'Not found'))) print('DEVICES', device_lib.list_local_devices()) # Single Machine, single compute device if args.distribute == 'single': if tf.test.is_gpu_available(): strategy = tf.distribute.OneDeviceStrategy(device="/gpu:0") else: strategy = tf.distribute.OneDeviceStrategy(device="/cpu:0") # Single Machine, multiple compute device elif args.distribute == 'mirror': strategy = tf.distribute.MirroredStrategy() # Multiple Machine, multiple compute device elif args.distribute == 'multi': strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy() # Multi-worker configuration print('num_replicas_in_sync = {}'.format(strategy.num_replicas_in_sync)) # Preparing dataset BUFFER_SIZE = 1000 IMG_HEIGHT = 224 IMG_WIDTH = 224 def make_datasets_batched(dataset_path, global_batch_size): # Configure the training data generator train_data_dir = os.path.join(dataset_path,"train/") train_ds = tf.keras.utils.image_dataset_from_directory( train_data_dir, seed=36, image_size=(IMG_HEIGHT, IMG_WIDTH), batch_size=global_batch_size ) # Configure the validation data generator val_data_dir = os.path.join(dataset_path,"valid/") val_ds = tf.keras.utils.image_dataset_from_directory( val_data_dir, seed=36, image_size=(IMG_HEIGHT, IMG_WIDTH), batch_size=global_batch_size ) # get the number of classes in the data num_classes = len(train_ds.class_names) # Configure the dataset for performance AUTOTUNE = tf.data.AUTOTUNE train_ds = train_ds.cache().shuffle(BUFFER_SIZE).prefetch(buffer_size=AUTOTUNE) val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE) return train_ds, val_ds, num_classes # Build the Keras model def build_and_compile_cnn_model(num_classes): # build a CNN model model = tf.keras.models.Sequential([ tf.keras.layers.Rescaling(1./255, input_shape=(IMG_HEIGHT, IMG_WIDTH, 3)), tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(num_classes) ]) # compile the CNN model model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) return model # Get the strategy data NUM_WORKERS = strategy.num_replicas_in_sync # Here the batch size scales up by number of workers GLOBAL_BATCH_SIZE = args.batch_size * NUM_WORKERS # Create dataset generator objects train_ds, val_ds, num_classes = make_datasets_batched(args.dataset_dir, GLOBAL_BATCH_SIZE) # Compile the model with strategy.scope(): # Creation of dataset, and model building/compiling need to be within # `strategy.scope()`. model = build_and_compile_cnn_model(num_classes) # fit the model on the data history = model.fit(train_ds, validation_data=val_ds, epochs=args.epochs) # save the model to the output dir model.save(args.model_dir)Selecione Arquivo > Salvar arquivo Python.
No terminal do JupyterLab, crie um arquivo
__init__.pyem cada subdiretório para torná-lo um pacote:touch fungi_training_package/__init__.py touch fungi_training_package/trainer/__init__.pyNo Navegador de arquivos, clique duas vezes na nova pasta
fungi_training_package.Selecione Arquivo > Novo > Arquivo Python.
Clique com o botão direito do mouse no novo arquivo e selecione Renomear arquivo.
Renomeie o arquivo de
untitled.pyparasetup.py.Clique duas vezes no arquivo
setup.pypara abri-lo.Copie o seguinte código para
setup.py:from setuptools import find_packages from setuptools import setup setup( name='trainer', version='0.1', packages=find_packages(), include_package_data=True, description='Training application package for fungi-classification.' )Selecione Arquivo > Salvar arquivo Python.
No terminal, acesse o diretório
fungi_training_package:cd fungi_training_packageUse o comando
sdistpara criar a distribuição de origem do aplicativo de treinamento:python setup.py sdist --formats=gztarNavegue até o diretório pai:
cd ..Verifique se você está no diretório correto:
pwdA saída será semelhante ao seguinte:
/home/jupyterCopie o pacote Python para o bucket de preparo:
gcloud storage cp fungi_training_package/dist/trainer-0.1.tar.gz gs://pipelines-staging-bucket-$projectid/training_package/Verifique se o bucket de preparo contém o pacote:
gcloud storage ls gs://pipelines-staging-bucket-$projectid/training_packageA resposta é:
gs://pipelines-staging-bucket-PROJECT_ID/training_package/trainer-0.1.tar.gz
Criar a conexão de rede de serviços para o Vertex AI Pipelines
Nesta seção, você vai criar uma conexão de rede de serviços
que é usada para estabelecer serviços de produtor conectados à
rede VPC vertex-networking-vpc pelo
peering de rede VPC. Para mais informações, consulte Peering de rede VPC.
No Cloud Shell, execute os seguintes comandos, substituindo PROJECT_ID pelo ID do projeto:
projectid=PROJECT_ID gcloud config set project ${projectid}Defina um intervalo de endereços IP reservado usando
gcloud compute addresses create:gcloud compute addresses create vertex-pipeline-subnet \ --global \ --purpose=VPC_PEERING \ --addresses=192.168.10.0 \ --prefix-length=24 \ --description="pipeline subnet" \ --network=vertex-networking-vpcEstabeleça uma conexão de peering entre a rede VPC
vertex-networking-vpce a rede de serviços do Google usandogcloud services vpc-peerings connect:gcloud services vpc-peerings connect \ --service=servicenetworking.googleapis.com \ --ranges=vertex-pipeline-subnet \ --network=vertex-networking-vpcModifique a conexão de peering de VPC para ativar a importação e exportação de rotas aprendidas personalizadas:
gcloud compute networks peerings update servicenetworking-googleapis-com \ --network=vertex-networking-vpc \ --import-custom-routes \ --export-custom-routes
Anunciar a sub-rede do pipeline no Cloud Router pipeline-networking
No console do Google Cloud, acesse a página do Cloud Router.
Na lista de Cloud Routers, clique em
vertex-networking-vpc-router1.Na página Detalhes do roteador, clique em Editar.
Clique em Adicionar uma rota personalizada.
Em Origem, selecione Intervalo de IP personalizado.
Em Intervalo de endereços IP, digite o seguinte endereço IP:
192.168.10.0/24Em Descrição, digite o seguinte:
Vertex AI Pipelines reserved subnetClique em Concluído e depois em Salvar.
Criar um modelo de pipeline e fazer upload dele para o Artifact Registry
Nesta seção, você vai criar e fazer upload de um modelo de pipeline do Kubeflow Pipelines (KFP). Esse modelo contém uma definição de fluxo de trabalho que pode ser reutilizada várias vezes por um ou vários usuários.
Definir e compilar o pipeline
No JupyterLab, no Navegador de arquivos, clique duas vezes na pasta de nível superior.
Selecione Arquivo -> Novo -> Notebook.
No menu Selecionar kernel, selecione
Python 3 (ipykernel)e clique em Selecionar.Em uma nova célula do notebook, execute o seguinte comando para usar a versão mais recente do
pip:!python -m pip install --upgrade pipExecute o seguinte comando para instalar o SDK dos componentes do Google Cloud Pipeline pelo índice de pacotes do Python (PyPI):
!pip install --upgrade google-cloud-pipeline-componentsQuando a instalação estiver concluída, selecione Kernel -> Reiniciar kernel para reiniciar o kernel e garantir que a biblioteca esteja disponível para importação.
Execute o seguinte código em uma nova célula do notebook para definir o pipeline:
from kfp import dsl # define the train-deploy pipeline @dsl.pipeline(name="custom-image-classification-pipeline") def custom_image_classification_pipeline( project: str, training_job_display_name: str, worker_pool_specs: list, base_output_dir: str, model_artifact_uri: str, prediction_container_uri: str, model_display_name: str, endpoint_display_name: str, network: str = '', location: str="us-central1", serving_machine_type: str="n1-standard-4", serving_min_replica_count: int=1, serving_max_replica_count: int=1 ): from google_cloud_pipeline_components.types import artifact_types from google_cloud_pipeline_components.v1.custom_job import CustomTrainingJobOp from google_cloud_pipeline_components.v1.model import ModelUploadOp from google_cloud_pipeline_components.v1.endpoint import (EndpointCreateOp, ModelDeployOp) from kfp.dsl import importer # Train the model task custom_job_task = CustomTrainingJobOp( project=project, display_name=training_job_display_name, worker_pool_specs=worker_pool_specs, base_output_directory=base_output_dir, location=location, network=network ) # Import the model task import_unmanaged_model_task = importer( artifact_uri=model_artifact_uri, artifact_class=artifact_types.UnmanagedContainerModel, metadata={ "containerSpec": { "imageUri": prediction_container_uri, }, }, ).after(custom_job_task) # Model upload task model_upload_op = ModelUploadOp( project=project, display_name=model_display_name, unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"], ) model_upload_op.after(import_unmanaged_model_task) # Create Endpoint task endpoint_create_op = EndpointCreateOp( project=project, display_name=endpoint_display_name, ) # Deploy the model to the endpoint ModelDeployOp( endpoint=endpoint_create_op.outputs["endpoint"], model=model_upload_op.outputs["model"], dedicated_resources_machine_type=serving_machine_type, dedicated_resources_min_replica_count=serving_min_replica_count, dedicated_resources_max_replica_count=serving_max_replica_count, )Execute o código abaixo em uma nova célula do notebook para compilar a definição do pipeline:
from kfp import compiler PIPELINE_FILE = "pipeline_config.yaml" compiler.Compiler().compile( pipeline_func=custom_image_classification_pipeline, package_path=PIPELINE_FILE, )No Navegador de arquivos , um arquivo chamado
pipeline_config.yamlvai aparecer na lista de arquivos.
Criar um repositório do Artifact Registry
Execute o código abaixo em uma nova célula do notebook para criar um repositório de artefatos do tipo KFP:
REPO_NAME="fungi-repo" REGION="us-central1" !gcloud artifacts repositories create $REPO_NAME --location=$REGION --repository-format=KFP
Fazer upload do modelo de pipeline para o Artifact Registry
Nesta seção, você vai configurar um cliente de registro do SDK do Kubeflow Pipelines e fazer upload do modelo de pipeline compilado para o Artifact Registry pelo notebook do JupyterLab.
No notebook do JupyterLab, execute o seguinte código para fazer upload do modelo de pipeline, substituindo PROJECT_ID pelo ID do projeto:
PROJECT_ID = "PROJECT_ID" from kfp.registry import RegistryClient host = f"https://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}" client = RegistryClient(host=host) TEMPLATE_NAME, VERSION_NAME = client.upload_pipeline( file_name=PIPELINE_FILE, tags=["v1", "latest"], extra_headers={"description":"This is an example pipeline template."})No console do Google Cloud, para verificar se o modelo foi enviado, acesse modelos do Vertex AI Pipelines.
Para abrir o painel Selecionar repositório, clique em Selecionar repositório.
Na lista de repositórios, clique no repositório que você criou (
fungi-repo) e em Selecionar.Verifique se seu pipeline (
custom-image-classification-pipeline) aparece na lista.
Acionar uma execução de pipeline no local
Nesta seção, agora que o modelo de pipeline e o pacote de treinamento estão prontos, você vai usar o cURL para acionar uma execução de pipeline pelo aplicativo local.
Informar os parâmetros do pipeline
No notebook do JupyterLab, execute o seguinte comando para verificar qual é nome do modelo do pipeline:
print (TEMPLATE_NAME)O nome do modelo retornado é:
custom-image-classification-pipelineExecute o seguinte comando para conferir a versão do modelo do pipeline:
print (VERSION_NAME)O nome da versão do modelo de pipeline retornado é parecido com este:
sha256:41eea21e0d890460b6e6333c8070d7d23d314afd9c7314c165efd41cddff86c7Anote a string inteira do nome da versão.
No Cloud Shell, execute os seguintes comandos, substituindo PROJECT_ID pelo ID do projeto:
projectid=PROJECT_ID gcloud config set project ${projectid}Faça login na instância de VM
on-prem-dataservice-host:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapNa instância de VM
on-prem-dataservice-host, use um editor de texto, comovimounanopara criar o arquivorequest_body.json, por exemplo:sudo vim request_body.jsonAdicione o seguinte texto ao arquivo
request_body.json:{ "displayName": "fungi-image-pipeline-job", "serviceAccount": "onprem-user-managed-sa@PROJECT_ID.iam.gserviceaccount.com", "runtimeConfig":{ "gcsOutputDirectory":"gs://pipelines-staging-bucket-PROJECT_ID/pipeline_root/", "parameterValues": { "project": "PROJECT_ID", "training_job_display_name": "fungi-image-training-job", "worker_pool_specs": [{ "machine_spec": { "machine_type": "n1-standard-4" }, "replica_count": 1, "python_package_spec":{ "executor_image_uri":"us-docker.pkg.dev/vertex-ai/training/tf-cpu.2-8.py310:latest", "package_uris": ["gs://pipelines-staging-bucket-PROJECT_ID/training_package/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args": ["--data-dir","/mnt/nfs/fungi_dataset/", "--epochs", "10"], "env": [{"name": "AIP_MODEL_DIR", "value": "gs://pipelines-staging-bucket-PROJECT_ID/model/"}] }, "nfs_mounts": [{ "server": "FILESTORE_INSTANCE_IP", "path": "/vol1", "mount_point": "/mnt/nfs/" }] }], "base_output_dir":"gs://pipelines-staging-bucket-PROJECT_ID", "model_artifact_uri":"gs://pipelines-staging-bucket-PROJECT_ID/model/", "prediction_container_uri":"us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest", "model_display_name":"fungi-image-model", "endpoint_display_name":"fungi-image-endpoint", "location": "us-central1", "serving_machine_type":"n1-standard-4", "network":"projects/PROJECT_NUMBER/global/networks/vertex-networking-vpc" } }, "templateUri": "https://us-central1-kfp.pkg.dev/PROJECT_ID/fungi-repo/custom-image-classification-pipeline/latest", "templateMetadata": { "version":"VERSION_NAME" } }Substitua os seguintes valores:
- PROJECT_ID: ID do projeto;
- PROJECT_NUMBER: o número do projeto. Ele é diferente do ID do projeto. Encontre esse número na página Configurações do projeto no console do Google Cloud.
- FILESTORE_INSTANCE_IP: o endereço IP da instância do Filestore,
por exemplo,
10.243.208.2. Essa informação está na página "Instâncias do Filestore" da instância. - VERSION_NAME: o nome da versão do modelo do pipeline (
sha256:...) que você anotou na etapa 2.
Salve o arquivo da seguinte maneira:
- Se você estiver usando
vim, pressione a teclaEsce, em seguida, digite:wqpara salvar o arquivo e sair. - Se você estiver usando
nano, digiteControl+Oe pressioneEnterpara salvar o arquivo. Em seguida, digiteControl+Xpara sair.
- Se você estiver usando
Enviar uma execução de pipeline com base no modelo
Na instância da VM
on-prem-dataservice-host, execute o seguinte comando, substituindo PROJECT_ID pelo ID do projeto:curl -v -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ -d @request_body.json \ https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/pipelineJobsA saída mostrada é longa, mas o principal que você precisa procurar é a seguinte linha, que indica que o serviço está se preparando para executar o pipeline:
"state": "PIPELINE_STATE_PENDING"A execução completa do pipeline leva de 45 a 50 minutos.
No console do Google Cloud, na seção Vertex AI, acesse a guia Execuções da página Pipelines.
Clique no nome da execução do pipeline (
custom-image-classification-pipeline).Na página de execução do pipeline, será exibido o gráfico de tempo de execução. O resumo do pipeline é exibido no painel Análise da execução do pipeline.
Para entender melhor as informações do gráfico de execução, saber como conferir logs e usar o Vertex ML Metadata para saber mais sobre os artefatos do pipeline, consulte Visualizar e analisar resultados de pipeline.
Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto que os contém ou mantenha o projeto e exclua os recursos individuais.
É possível excluir os recursos individuais no projeto da seguinte maneira:
Exclua todas as execuções de pipeline da seguinte maneira:
No console do Google Cloud, na seção Vertex AI, acesse a guia Execuções da página Pipelines.
Selecione as execuções de pipeline que você quer excluir e clique em Excluir.
Exclua o modelo de pipeline da seguinte maneira:
Na seção Vertex AI, acesse a guia Seus modelos na página Pipelines.
Ao lado do modelo de pipeline
custom-image-classification-pipeline, clique em Ações e selecione Excluir.
Exclua o repositório do Artifact Registry da seguinte maneira:
Na página Artifact Registry, acesse a guia Repositórios.
Selecione o repositório
fungi-repoe clique em Excluir.
Cancele a implantação do modelo do endpoint da seguinte maneira:
Na seção Vertex AI, acesse a guia Endpoints na página Previsões on-line.
Clique em
fungi-image-endpointpara acessar a página de detalhes do endpoint.Na linha do modelo,
fungi-image-model, clique em Ações e selecione Cancelar a implantação do modelo do endpoint.Na caixa de diálogo Cancelar a implantação do modelo do endpoint, clique em Cancelar a implantação.
Exclua o endpoint da seguinte maneira:
Na seção Vertex AI, acesse a guia Endpoints na página Previsões on-line.
Selecione
fungi-image-endpointe clique em Excluir.
Exclua o modelo da seguinte maneira:
Acessar a página Modelo de registro.
Na linha do modelo,
fungi-image-model, clique em Ações e selecione Excluir modelo.
Exclua o bucket de preparação da seguinte maneira:
Acesse a página do Cloud Storage.
Selecione
pipelines-staging-bucket-PROJECT_ID, em que PROJECT_ID é o ID do projeto, e clique em Excluir.
Exclua a instância do Vertex AI Workbench da seguinte maneira:
Na seção Vertex AI, acesse a guia Instâncias na página Workbench.
Selecione a instância
pipeline-tutorial-PROJECT_IDdo Vertex AI Workbench, em que PROJECT_ID é o ID do projeto, e clique em Excluir.
Exclua a instância de VM do Compute Engine da seguinte maneira:
Acessar a página do Compute Engine.
Selecione a instância de VM
on-prem-dataservice-hoste clique em Excluir.
Exclua os túneis VPN da seguinte maneira:
Acesse a página VPN.
Na página VPN, clique na guia Túneis do Cloud VPN.
Na lista de túneis de VPN, selecione os quatro túneis de VPN criados neste tutorial e clique em Excluir.
Exclua os gateways da VPN de alta disponibilidade da seguinte maneira:
Na página VPN, clique na guia Gateways do Cloud VPN.
Na lista de gateways de VPN, clique em
onprem-vpn-gw1.Na página Detalhes do gateway do Cloud VPN, clique em Excluir gateway da VPN.
Se necessário, clique na seta para voltar para retornar à lista de gateways de VPN e clique em
vertex-networking-vpn-gw1.Na página Detalhes do gateway do Cloud VPN, clique em Excluir gateway da VPN.
Exclua os Cloud Routers da seguinte maneira:
Acesse a página Cloud Routers.
Na lista de Cloud Routers, selecione os quatro roteadores que você criou neste tutorial.
Para excluir os roteadores, clique em Excluir.
Isso também exclui os dois gateways do Cloud NAT conectados aos Cloud Routers.
Exclua as conexões de rede de serviço com as redes VPC
vertex-networking-vpceonprem-dataservice-vpcda seguinte maneira:Acesse a página Peering de rede VPC.
Selecione
servicenetworking-googleapis-com.Para excluir as conexões, clique em Excluir.
Exclua a regra de encaminhamento
pscvertexpara a rede VPCvertex-networking-vpcda seguinte maneira:Acesse a guia Front-ends da página Balanceamento de carga.
Na lista de regras de encaminhamento, clique em
pscvertex.Na página Detalhes da regra de encaminhamento global, clique em Excluir.
Exclua a instância do Filestore da seguinte maneira:
Acessar a página do Filestore.
Selecione a instância
image-data-instance.Para excluir a instância, clique em Ações e em Excluir instância.
Exclua as redes VPC da seguinte maneira:
Acesse a página Redes VPC.
Na lista de redes VPC, clique em
onprem-dataservice-vpc.Na página Detalhes da rede VPC, clique em Excluir rede VPC.
Com a exclusão de uma rede, as respectivas sub-redes, rotas e regras de firewall também são excluídas.
Na lista de redes VPC, clique em
vertex-networking-vpc.Na página Detalhes da rede VPC, clique em Excluir rede VPC.
Exclua as contas de serviço
workbench-saeonprem-user-managed-sada seguinte maneira:Acesse a página Contas de serviço.
Selecione as contas de serviço
onprem-user-managed-saeworkbench-sae clique em Excluir.
A seguir
Aprenda a usar o Vertex AI Pipelines para orquestrar o processo de criação e implantação de modelos de machine learning.
Saiba mais sobre o conjunto de dados deFungi.