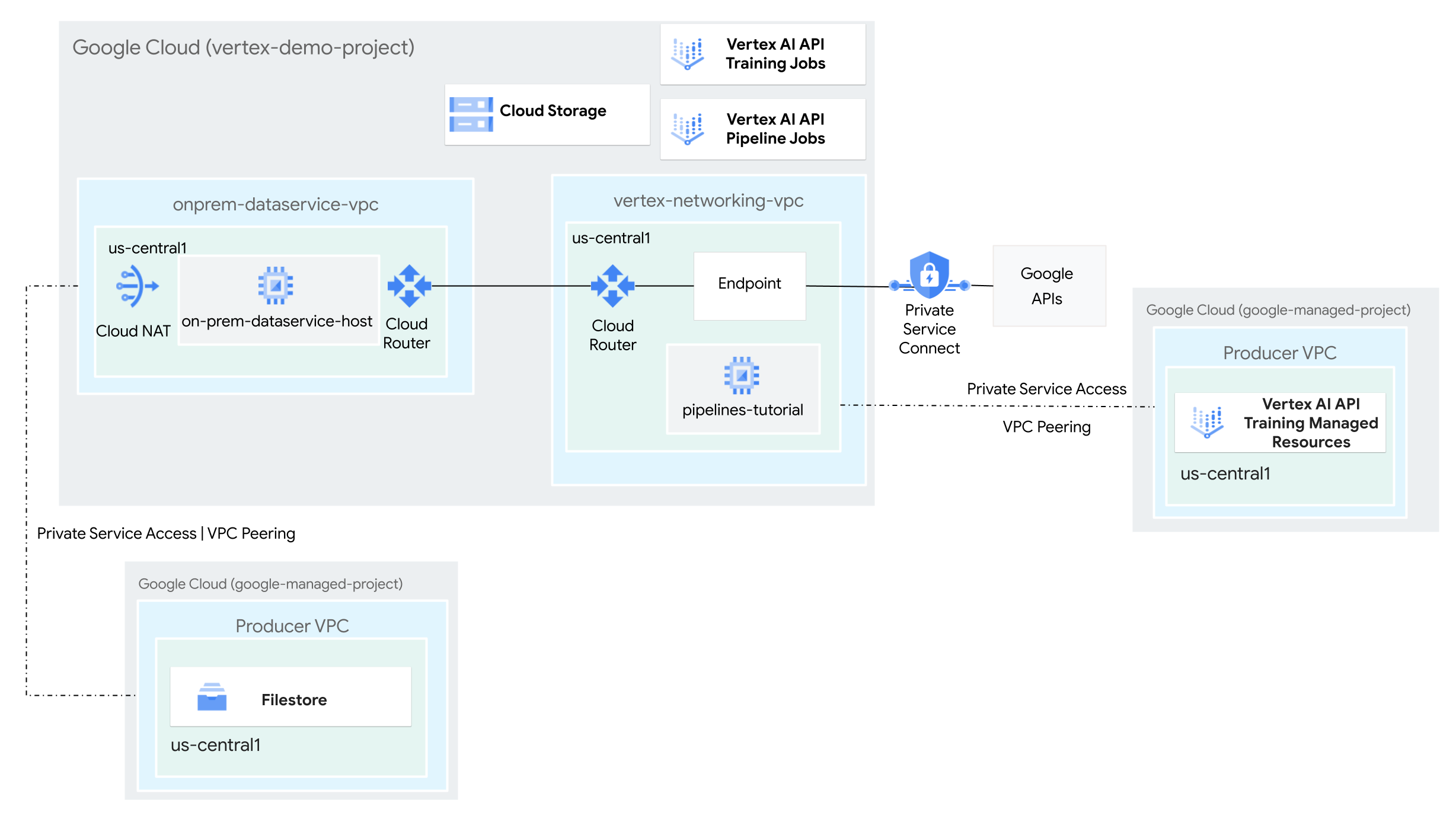
Vertex AI Pipelines는 Google Cloud 플랫폼에서 엔드 투 엔드 머신러닝(ML) 워크플로를 빌드, 배포, 관리하는 데 도움이 되는 관리형 서비스입니다. 파이프라인을 실행할 수 있는 서버리스 환경을 제공하므로 인프라 관리에 관해 걱정할 필요가 없습니다.
이 튜토리얼에서는 Vertex AI Pipelines를 사용하여 커스텀 학습 작업을 실행하고 하이브리드 네트워크 환경에서 Vertex AI에 학습된 모델을 배포합니다.
전체 프로세스를 완료하는 데 2~3시간이 소요되며, 이 중 파이프라인 실행에 약 50분이 소요됩니다.
이 튜토리얼은 Vertex AI, 가상 프라이빗 클라우드 (VPC), Google Cloud 콘솔, Cloud Shell에 익숙한 엔터프라이즈 네트워크 관리자, 데이터 과학자, 연구원을 대상으로 합니다. Vertex AI Workbench에 익숙하면 도움이 되지만 필수는 아닙니다.
VPC 네트워크 만들기
이 섹션에서는 Vertex AI Pipelines용 Google API에 액세스하는 VPC 네트워크 1개와 온프레미스 네트워크를 시뮬레이션하기 위한 VPC 네트워크 1개를 만듭니다. 두 VPC 네트워크 각각에 Cloud Router와 Cloud NAT 게이트웨이를 만듭니다. Cloud NAT 게이트웨이는 외부 IP 주소가 없는 Compute Engine 가상 머신(VM) 인스턴스에 대한 발신 연결을 제공합니다.
Cloud Shell에서 다음 명령어를 실행하고 PROJECT_ID를 프로젝트 ID로 바꿉니다.
projectid=PROJECT_ID gcloud config set project ${projectid}vertex-networking-vpcVPC 네트워크 만들기gcloud compute networks create vertex-networking-vpc \ --subnet-mode customvertex-networking-vpc네트워크에서 기본 IPv4 범위가10.0.0.0/24인pipeline-networking-subnet1이라는 서브넷을 만듭니다.gcloud compute networks subnets create pipeline-networking-subnet1 \ --range=10.0.0.0/24 \ --network=vertex-networking-vpc \ --region=us-central1 \ --enable-private-ip-google-access온프레미스 네트워크(
onprem-dataservice-vpc)를 시뮬레이션하도록 VPC 네트워크를 만듭니다.gcloud compute networks create onprem-dataservice-vpc \ --subnet-mode customonprem-dataservice-vpc네트워크에서 기본 IPv4 범위가172.16.10.0/24인onprem-dataservice-vpc-subnet1이라는 서브넷을 만듭니다.gcloud compute networks subnets create onprem-dataservice-vpc-subnet1 \ --network onprem-dataservice-vpc \ --range 172.16.10.0/24 \ --region us-central1 \ --enable-private-ip-google-access
VPC 네트워크가 올바르게 구성되었는지 확인
Google Cloud 콘솔의 VPC 네트워크 페이지에서 현재 프로젝트의 네트워크 탭으로 이동합니다.
VPC 네트워크 목록에서 네트워크 2개(
vertex-networking-vpc및onprem-dataservice-vpc)가 생성되었는지 확인합니다.현재 프로젝트의 서브넷 탭을 클릭합니다.
VPC 서브넷 목록에서
pipeline-networking-subnet1및onprem-dataservice-vpc-subnet1서브넷이 생성되었는지 확인합니다.
하이브리드 연결 구성
이 섹션에서는 서로 연결된 HA VPN 게이트웨이 2개를 만듭니다. 하나는 vertex-networking-vpc VPC 네트워크에 있습니다. 다른 하나는 onprem-dataservice-vpc VPC 네트워크에 있습니다. 각 게이트웨이에는 Cloud Router와 VPN 터널 쌍이 포함됩니다.
HA VPN 게이트웨이 만들기
Cloud Shell에서
vertex-networking-vpcVPC 네트워크의 HA VPN 게이트웨이를 만듭니다.gcloud compute vpn-gateways create vertex-networking-vpn-gw1 \ --network vertex-networking-vpc \ --region us-central1onprem-dataservice-vpcVPC 네트워크의 HA VPN 게이트웨이를 만듭니다.gcloud compute vpn-gateways create onprem-vpn-gw1 \ --network onprem-dataservice-vpc \ --region us-central1Google Cloud 콘솔에서 VPN 페이지의 Cloud VPN 게이트웨이 탭으로 이동합니다.
2개의 게이트웨이(
vertex-networking-vpn-gw1및onprem-vpn-gw1)가 생성되었고 각 게이트웨이에 인터페이스 IP 주소 2개가 있는지 확인합니다.
Cloud Router 및 Cloud NAT 게이트웨이 만들기
두 VPC 네트워크 각각에 Cloud Router 두 개를 만듭니다. 하나는 Cloud NAT와 함께 사용하고 하나는 HA VPN의 BGP 세션을 관리합니다.
Cloud Shell에서 VPN에 사용할
vertex-networking-vpcVPC 네트워크의 Cloud Router를 만듭니다.gcloud compute routers create vertex-networking-vpc-router1 \ --region us-central1 \ --network vertex-networking-vpc \ --asn 65001VPN에 사용할
onprem-dataservice-vpcVPC 네트워크의 Cloud Router를 만듭니다.gcloud compute routers create onprem-dataservice-vpc-router1 \ --region us-central1 \ --network onprem-dataservice-vpc \ --asn 65002Cloud NAT에 사용될
vertex-networking-vpcVPC 네트워크의 Cloud Router를 만듭니다.gcloud compute routers create cloud-router-us-central1-vertex-nat \ --network vertex-networking-vpc \ --region us-central1Cloud Router에서 Cloud NAT 게이트웨이를 구성합니다.
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-vertex-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1Cloud NAT에 사용될
onprem-dataservice-vpcVPC 네트워크의 Cloud Router를 만듭니다.gcloud compute routers create cloud-router-us-central1-onprem-nat \ --network onprem-dataservice-vpc \ --region us-central1Cloud Router에서 Cloud NAT 게이트웨이를 구성합니다.
gcloud compute routers nats create cloud-nat-us-central1-on-prem \ --router=cloud-router-us-central1-onprem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1Google Cloud 콘솔에서 Cloud Routers 페이지로 이동합니다.
Cloud Router 목록에서 다음 라우터가 생성되었는지 확인합니다.
cloud-router-us-central1-onprem-natcloud-router-us-central1-vertex-natonprem-dataservice-vpc-router1vertex-networking-vpc-router1
새 값을 보려면 Google Cloud 콘솔 브라우저 탭을 새로고침해야 할 수 있습니다.
Cloud Router 목록에서
cloud-router-us-central1-vertex-nat를 클릭합니다.라우터 세부정보 페이지에서
cloud-nat-us-central1Cloud NAT 게이트웨이가 생성되었는지 확인합니다.뒤로 화살표를 클릭하여 Cloud Router 페이지로 돌아갑니다.
Cloud Router 목록에서
cloud-router-us-central1-onprem-nat를 클릭합니다.라우터 세부정보 페이지에서
cloud-nat-us-central1-on-premCloud NAT 게이트웨이가 생성되었는지 확인합니다.
VPN 터널 만들기
Cloud Shell의
vertex-networking-vpc네트워크에서vertex-networking-vpc-tunnel0이라는 VPN 터널을 만듭니다.gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel0 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 0vertex-networking-vpc네트워크에서vertex-networking-vpc-tunnel1이라는 VPN 터널을 만듭니다.gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel1 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 1onprem-dataservice-vpc네트워크에서onprem-dataservice-vpc-tunnel0이라는 VPN 터널을 만듭니다.gcloud compute vpn-tunnels create onprem-dataservice-vpc-tunnel0 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router onprem-dataservice-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 0onprem-dataservice-vpc네트워크에서onprem-dataservice-vpc-tunnel1이라는 VPN 터널을 만듭니다.gcloud compute vpn-tunnels create onprem-dataservice-vpc-tunnel1 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router onprem-dataservice-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 1Google Cloud 콘솔에서 VPN 페이지로 이동합니다.
VPN 터널 목록에서 VPN 터널 4개가 생성되었는지 확인합니다.
BGP 세션 설정
Cloud Router는 경계 게이트웨이 프로토콜(BGP)을 사용하여 VPC 네트워크(이 경우 vertex-networking-vpc)와 온프레미스 네트워크(onprem-dataservice-vpc로 표시) 간에 경로를 교환합니다. Cloud Router에서 온프레미스 라우터의 인터페이스와 BGP 피어를 구성합니다.
인터페이스와 BGP 피어 구성은 함께 BGP 세션을 구성합니다.
이 섹션에서는 vertex-networking-vpc에 대한 2개의 BGP 세션과 onprem-dataservice-vpc에 대한 2개의 BGP 세션을 만듭니다.
라우터 사이에 인터페이스와 BGP 피어를 구성하면 경로 교환이 자동으로 시작됩니다.
vertex-networking-vpc용 BGP 세션 설정
Cloud Shell의
vertex-networking-vpc네트워크에서vertex-networking-vpc-tunnel0에 대한 BGP 인터페이스를 만듭니다.gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.0.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel0 \ --region us-central1vertex-networking-vpc네트워크에서bgp-onprem-tunnel0에 대한 BGP 피어를 만듭니다.gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel0 \ --interface if-tunnel0-to-onprem \ --peer-ip-address 169.254.0.2 \ --peer-asn 65002 \ --region us-central1vertex-networking-vpc네트워크에서vertex-networking-vpc-tunnel1에 대한 BGP 인터페이스를 만듭니다.gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel1 \ --region us-central1vertex-networking-vpc네트워크에서bgp-onprem-tunnel1에 대한 BGP 피어를 만듭니다.gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel1 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central1
onprem-dataservice-vpc용 BGP 세션 설정
onprem-dataservice-vpc네트워크에서onprem-dataservice-vpc-tunnel0에 대한 BGP 인터페이스를 만듭니다.gcloud compute routers add-interface onprem-dataservice-vpc-router1 \ --interface-name if-tunnel0-to-vertex-networking-vpc \ --ip-address 169.254.0.2 \ --mask-length 30 \ --vpn-tunnel onprem-dataservice-vpc-tunnel0 \ --region us-central1onprem-dataservice-vpc네트워크에서bgp-vertex-networking-vpc-tunnel0에 대한 BGP 피어를 만듭니다.gcloud compute routers add-bgp-peer onprem-dataservice-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel0 \ --interface if-tunnel0-to-vertex-networking-vpc \ --peer-ip-address 169.254.0.1 \ --peer-asn 65001 \ --region us-central1onprem-dataservice-vpc네트워크에서onprem-dataservice-vpc-tunnel1에 대한 BGP 인터페이스를 만듭니다.gcloud compute routers add-interface onprem-dataservice-vpc-router1 \ --interface-name if-tunnel1-to-vertex-networking-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel onprem-dataservice-vpc-tunnel1 \ --region us-central1onprem-dataservice-vpc네트워크에서bgp-vertex-networking-vpc-tunnel1에 대한 BGP 피어를 만듭니다.gcloud compute routers add-bgp-peer onprem-dataservice-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel1 \ --interface if-tunnel1-to-vertex-networking-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central1
BGP 세션 생성 검증
Google Cloud 콘솔에서 VPN 페이지로 이동합니다.
VPN 터널 목록에서 각 터널의 BGP 세션 상태 열 값이 BGP 세션 구성에서 BGP 설정됨으로 변경되었는지 확인합니다. 새 값을 보려면 Google Cloud 콘솔 브라우저 탭을 새로고침해야 할 수 있습니다.
학습된 경로 onprem-dataservice-vpc 검증
Google Cloud 콘솔에서 VPC 네트워크 페이지로 이동합니다.
VPC 네트워크 목록에서
onprem-dataservice-vpc를 클릭합니다.경로 탭을 클릭합니다.
리전 목록에서 us-central1(아이오와)을 선택하고 보기를 클릭합니다.
대상 IP 범위 열에서
pipeline-networking-subnet1서브넷 IP 범위(10.0.0.0/24)가 두 번 표시되는지 확인합니다.두 항목을 모두 보려면 Google Cloud 콘솔 브라우저 탭을 새로고침해야 할 수 있습니다.
학습된 경로 vertex-networking-vpc 검증
뒤로 화살표를 클릭하여 VPC 네트워크 페이지로 돌아갑니다.
VPC 네트워크 목록에서
vertex-networking-vpc를 클릭합니다.경로 탭을 클릭합니다.
리전 목록에서 us-central1(아이오와)을 선택하고 보기를 클릭합니다.
대상 IP 범위 열에서
onprem-dataservice-vpc-subnet1서브넷의 IP 범위(172.16.10.0/24)가 두 번 표시되는지 확인합니다.
Google API용 Private Service Connect 엔드포인트 만들기
이 섹션에서는 온프레미스 네트워크에서 Vertex AI Pipelines REST API에 액세스하는 데 사용할 Google API의 Private Service Connect 엔드포인트를 만듭니다.
Cloud Shell에서 Google API에 액세스하는 데 사용할 소비자 엔드포인트 IP 주소를 예약합니다.
gcloud compute addresses create psc-googleapi-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=192.168.0.1 \ --network=vertex-networking-vpc엔드포인트를 Google API 및 서비스에 연결하는 전달 규칙을 만듭니다.
gcloud compute forwarding-rules create pscvertex \ --global \ --network=vertex-networking-vpc \ --address=psc-googleapi-ip \ --target-google-apis-bundle=all-apis
vertex-networking-vpc용 커스텀 경로 공지 만들기
이 섹션에서는 PSC 엔드포인트의 IP 주소를 onprem-dataservice-vpc VPC 네트워크에 공지하도록 vertex-networking-vpc-router1(vertex-networking-vpc용 Cloud Router)에 대한 커스텀 경로 공지를 만듭니다.
Google Cloud 콘솔에서 Cloud Routers 페이지로 이동합니다.
Cloud Router 목록에서
vertex-networking-vpc-router1을 클릭합니다.라우터 세부정보 페이지에서 수정을 클릭합니다.
공지된 경로 섹션에서 경로에 대해 커스텀 경로 만들기를 선택합니다.
Cloud Router에서 사용할 수 있는 서브넷을 계속 공지하려면 Cloud Router에 표시되는 모든 서브넷 공지 체크박스를 선택합니다. 이 옵션을 사용 설정하면 기본 공지 모드에서 Cloud Router 동작을 모방합니다.
커스텀 경로 추가를 클릭합니다.
소스에 커스텀 IP 범위를 선택합니다.
IP 주소 범위에 다음 IP 주소를 입력합니다.
192.168.0.1설명에 다음 텍스트를 입력합니다.
Custom route to advertise Private Service Connect endpoint IP address완료를 클릭한 다음 저장을 클릭합니다.
onprem-dataservice-vpc에서 공지된 경로를 학습했는지 검증
Google Cloud 콘솔에서 경로 페이지로 이동합니다.
유효한 경로 탭에서 다음을 수행합니다.
- 네트워크에
onprem-dataservice-vpc를 선택합니다. - 리전에
us-central1 (Iowa)을 선택합니다. - 보기를 클릭합니다.
경로 목록에서 이름이
onprem-dataservice-vpc-router1-bgp-vertex-networking-vpc-tunnel0로 시작하는 항목이 2개 있고onprem-dataservice-vpc-router1-bgp-vertex-networking-vpc-tunnel1로 시작하는 항목이 2개 있는지 확인합니다.이러한 항목이 바로 표시되지 않으면 몇 분 정도 기다린 후 Google Cloud 콘솔 브라우저 탭을 새로고침합니다.
항목 중 2개는 대상 IP 범위가
192.168.0.1/32이고 2개는 대상 IP 범위가10.0.0.0/24인지 확인합니다.
- 네트워크에
onprem-dataservice-vpc에 VM 인스턴스 만들기
이 섹션에서는 온프레미스 데이터 서비스 호스트를 시뮬레이션하는 VM 인스턴스를 만듭니다. Compute Engine 및 IAM 권장사항을 준수하는 이 VM은 Compute Engine 기본 서비스 계정 대신 사용자 관리 서비스 계정을 사용합니다.
VM 인스턴스의 사용자 관리형 서비스 계정 만들기
Cloud Shell에서 다음 명령어를 실행하고 PROJECT_ID를 프로젝트 ID로 바꿉니다.
projectid=PROJECT_ID gcloud config set project ${projectid}onprem-user-managed-sa라는 서비스 계정을 만듭니다.gcloud iam service-accounts create onprem-user-managed-sa \ --display-name="onprem-user-managed-sa"서비스 계정에 Vertex AI 사용자(
roles/aiplatform.user) 역할을 할당합니다.gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Vertex AI 뷰어(
roles/aiplatform.viewer) 역할을 할당합니다.gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.viewer"Filestore 편집자(
roles/file.editor) 역할을 할당합니다.gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/file.editor"서비스 계정 관리자(
roles/iam.serviceAccountAdmin) 역할을 할당합니다.gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/iam.serviceAccountAdmin"서비스 계정 사용자(
roles/iam.serviceAccountUser) 역할을 할당합니다.gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/iam.serviceAccountUser"Artifact Registry 리더(
roles/artifactregistry.reader) 역할을 할당합니다.gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.reader"스토리지 객체 관리자(
roles/storage.objectAdmin) 역할을 할당합니다.gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.objectAdmin"로깅 관리자(
roles/logging.admin) 역할을 할당합니다.gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/logging.admin"
on-prem-dataservice-host VM 인스턴스 만들기
생성한 VM 인스턴스에 외부 IP 주소가 없으며 인터넷을 통한 직접 액세스를 허용하지 않습니다. VM에 대한 관리 액세스를 사용 설정하려면 IAP(Identity-Aware Proxy) TCP 전달을 사용하세요.
Cloud Shell에서
on-prem-dataservice-hostVM 인스턴스를 만듭니다.gcloud compute instances create on-prem-dataservice-host \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=onprem-dataservice-vpc-subnet1 \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --shielded-secure-boot \ --service-account=onprem-user-managed-sa@$projectid.iam.gserviceaccount.com \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"IAP가 VM 인스턴스에 연결할 수 있도록 방화벽 규칙을 만듭니다.
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network onprem-dataservice-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
PSC 엔드포인트를 가리키도록 /etc/hosts 파일을 업데이트합니다.
이 섹션에서는 공개 서비스 엔드포인트(us-central1-aiplatform.googleapis.com)로 전송된 요청이 PSC 엔드포인트(192.168.0.1)로 리디렉션되는 /etc/hosts 파일에 줄을 추가합니다.
Cloud Shell에서 IAP를 사용하여
on-prem-dataservice-hostVM 인스턴스에 로그인합니다.gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapon-prem-dataservice-hostVM 인스턴스에서vim또는nano와 같은 텍스트 편집기를 사용하여/etc/hosts파일을 엽니다. 예를 들면 다음과 같습니다.sudo vim /etc/hosts다음 줄을 파일에 추가합니다.
192.168.0.1 us-central1-aiplatform.googleapis.com이 줄은 PSC 엔드포인트의 IP 주소(
192.168.0.1)를 Vertex AI Google API(us-central1-aiplatform.googleapis.com)의 정규화된 도메인 이름에 할당합니다.수정된 파일은 다음과 같습니다.
127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 192.168.0.1 us-central1-aiplatform.googleapis.com # Added by you 172.16.10.6 on-prem-dataservice-host.us-central1-a.c.PROJECT_ID.internal on-prem-dataservice-host # Added by Google 169.254.169.254 metadata.google.internal # Added by Google다음과 같이 파일을 저장합니다.
vim을 사용하는 경우Esc키를 누른 후:wq를 입력하여 파일을 저장하고 종료합니다.nano를 사용하는 경우Control+O을 입력하고Enter를 눌러 파일을 저장한 후Control+X를 입력하여 종료합니다.
다음과 같이 Vertex AI API 엔드포인트를 핑합니다.
ping us-central1-aiplatform.googleapis.comping명령어에서 다음 출력을 반환합니다.192.168.0.1은 PSC 엔드포인트 IP 주소입니다.PING us-central1-aiplatform.googleapis.com (192.168.0.1) 56(84) bytes of data.ping에서 종료하려면Control+C를 입력합니다.exit를 입력하여on-prem-dataservice-hostVM 인스턴스를 종료하고 Cloud Shell 프롬프트로 돌아갑니다.
Filestore 인스턴스의 네트워킹 구성
이 섹션에서는 Filestore 인스턴스를 만들고 네트워크 파일 시스템(NFS) 공유로 마운트하기 위해 VPC 네트워크에 비공개 서비스 액세스를 사용 설정합니다. 이 섹션과 다음 섹션에서 수행하는 작업을 알아보려면 커스텀 학습을 위한 NFS 공유 마운트 및 VPC 네트워크 피어링 설정을 참고하세요.
VPC 네트워크에서 비공개 서비스 액세스 사용 설정
이 섹션에서는 서비스 네트워킹 연결을 만들고 이를 사용하여 VPC 네트워크 피어링을 통해 onprem-dataservice-vpc VPC 네트워크에 대한 비공개 서비스 액세스를 사용 설정합니다.
Cloud Shell에서
gcloud compute addresses create를 사용하여 예약된 IP 주소 범위를 설정합니다.gcloud compute addresses create filestore-subnet \ --global \ --purpose=VPC_PEERING \ --addresses=10.243.208.0 \ --prefix-length=24 \ --description="filestore subnet" \ --network=onprem-dataservice-vpcgcloud services vpc-peerings connect를 사용하여onprem-dataservice-vpcVPC 네트워크와 Google 서비스 네트워킹 간에 피어링 연결을 설정합니다.gcloud services vpc-peerings connect \ --service=servicenetworking.googleapis.com \ --ranges=filestore-subnet \ --network=onprem-dataservice-vpcVPC 네트워크 피어링을 업데이트하여 학습된 커스텀 경로의 가져오기 및 내보내기를 사용 설정합니다.
gcloud compute networks peerings update servicenetworking-googleapis-com \ --network=onprem-dataservice-vpc \ --import-custom-routes \ --export-custom-routesGoogle Cloud 콘솔에서 VPC 네트워크 피어링 페이지로 이동합니다.
VPC 피어링 목록에서
servicenetworking.googleapis.com와onprem-dataservice-vpcVPC 네트워크 간의 피어링 항목이 있는지 확인합니다.
filestore-subnet용 커스텀 경로 공지 만들기
Google Cloud 콘솔에서 Cloud Routers 페이지로 이동합니다.
Cloud Router 목록에서
onprem-dataservice-vpc-router1을 클릭합니다.라우터 세부정보 페이지에서 수정을 클릭합니다.
공지된 경로 섹션에서 경로에 대해 커스텀 경로 만들기를 선택합니다.
Cloud Router에서 사용할 수 있는 서브넷을 계속 공지하려면 Cloud Router에 표시되는 모든 서브넷 공지 체크박스를 선택합니다. 이 옵션을 사용 설정하면 기본 공지 모드에서 Cloud Router 동작을 모방합니다.
커스텀 경로 추가를 클릭합니다.
소스에 커스텀 IP 범위를 선택합니다.
IP 주소 범위에 다음 IP 주소 범위를 입력합니다.
10.243.208.0/24설명에 다음 텍스트를 입력합니다.
Filestore reserved IP address range완료를 클릭한 다음 저장을 클릭합니다.
onprem-dataservice-vpc 네트워크에 Filestore 인스턴스 만들기
VPC 네트워크에 비공개 서비스 액세스를 사용 설정한 후 Filestore 인스턴스를 만들고 커스텀 학습 작업의 NFS 공유로 인스턴스를 마운트합니다. 이렇게 하면 학습 작업이 로컬처럼 원격 파일에 액세스하여 높은 처리량과 짧은 지연 시간을 지원할 수 있습니다.
Filestore 인스턴스 만들기
Google Cloud 콘솔에서 Filestore 인스턴스 페이지로 이동합니다.
인스턴스 만들기를 클릭하고 다음과 같이 인스턴스를 구성합니다.
인스턴스 ID를 다음으로 설정합니다.
image-data-instance인스턴스 유형을 기본으로 설정합니다.
스토리지 유형을 HDD로 설정합니다.
용량 할당을 1
TiB로 설정합니다.리전을 us-central1로, 영역을 us-central1-c로 설정합니다.
VPC 네트워크를
onprem-dataservice-vpc로 설정합니다.할당된 IP 범위를 기존 할당 IP 범위 사용으로 설정하고
filestore-subnet을 선택합니다.파일 공유 이름을 다음으로 설정합니다.
vol1액세스 제어를 VPC 네트워크의 모든 클라이언트에 액세스 권한 부여로 설정합니다.
만들기를 클릭합니다.
새 Filestore 인스턴스의 IP 주소를 기록합니다. 새 인스턴스를 보려면 Google Cloud 콘솔 브라우저 탭을 새로고침해야 할 수 있습니다.
Filestore 파일 공유 마운트
Cloud Shell에서 다음 명령어를 실행하고 PROJECT_ID를 프로젝트 ID로 바꿉니다.
projectid=PROJECT_ID gcloud config set project ${projectid}on-prem-dataservice-hostVM 인스턴스에 로그인합니다.gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapVM 인스턴스에 NFS 패키지를 설치합니다.
sudo apt-get update -y sudo apt-get -y install nfs-commonFilestore 파일 공유의 마운트 디렉터리를 만듭니다.
sudo mkdir -p /mnt/nfsFILESTORE_INSTANCE_IP를 Filestore 인스턴스의 IP 주소로 바꾸고 파일 공유를 마운트합니다.
sudo mount FILESTORE_INSTANCE_IP:/vol1 /mnt/nfs연결 시간이 초과되면 Filestore 인스턴스의 올바른 IP 주소를 제공하고 있는지 확인합니다.
다음 명령어를 실행하여 NFS 마운트가 성공했는지 확인합니다.
df -h결과에
/mnt/nfs파일 공유가 표시되는지 확인합니다.Filesystem Size Used Avail Use% Mounted on udev 1.8G 0 1.8G 0% /dev tmpfs 368M 396K 368M 1% /run /dev/sda1 9.7G 1.9G 7.3G 21% / tmpfs 1.8G 0 1.8G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock /dev/sda15 124M 11M 114M 9% /boot/efi tmpfs 368M 0 368M 0% /run/user 10.243.208.2:/vol1 1007G 0 956G 0% /mnt/nfs파일 공유 액세스가 가능하도록 권한을 변경합니다.
sudo chmod go+rw /mnt/nfs
파일 공유에 데이터 세트 다운로드
on-prem-dataservice-hostVM 인스턴스에서 데이터 세트를 파일 공유에 다운로드합니다.gcloud storage cp gs://cloud-samples-data/vertex-ai/dataset-management/datasets/fungi_dataset /mnt/nfs/ --recursive다운로드하는 데 몇 분 정도 걸립니다.
다음 명령어를 실행하여 데이터 세트가 성공적으로 복사되었는지 확인합니다.
sudo du -sh /mnt/nfs예상되는 출력은 다음과 같습니다.
104M /mnt/nfsexit를 입력하여on-prem-dataservice-hostVM 인스턴스를 종료하고 Cloud Shell 프롬프트로 돌아갑니다.
파이프라인의 스테이징 버킷 만들기
Vertex AI Pipelines는 Cloud Storage를 사용하여 파이프라인 실행의 아티팩트를 저장합니다. 파이프라인을 실행하기 전에 파이프라인 실행을 스테이징할 Cloud Storage 버킷을 만들어야 합니다.
Cloud Shell에서 Cloud Storage 버킷을 만듭니다.
gcloud storage buckets create gs://pipelines-staging-bucket-$projectid --location=us-central1
Vertex AI Workbench용 사용자 관리형 서비스 계정 만들기
Cloud Shell에서 서비스 계정을 만듭니다.
gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"서비스 계정에 Vertex AI 사용자(
roles/aiplatform.user) 역할을 할당합니다.gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Artifact Registry 관리자(
artifactregistry.admin) 역할을 할당합니다.gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.admin"스토리지 관리자(
storage.admin) 역할을 할당합니다.gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.admin"
Python 학습 애플리케이션 만들기
이 섹션에서는 Vertex AI Workbench 인스턴스를 만들고 이를 사용하여 Python 커스텀 학습 애플리케이션 패키지를 만듭니다.
Vertex AI Workbench 인스턴스 생성
Google Cloud 콘솔에서 Vertex AI Workbench 페이지의 인스턴스 탭으로 이동합니다.
새로 만들기를 클릭한 후 고급 옵션을 선택합니다.
새 인스턴스 페이지가 열립니다.
새 인스턴스 페이지의 세부정보 섹션에서 새 인스턴스에 대한 다음 정보를 제공한 후 계속을 클릭합니다.
이름: PROJECT_ID를 프로젝트 ID로 바꾸고 다음을 입력합니다.
pipeline-tutorial-PROJECT_ID리전: us-central1을 선택합니다.
영역: us-central1-a를 선택합니다.
Dataproc 서버리스 대화형 세션 사용 설정 체크박스를 선택 취소합니다.
환경 섹션에서 계속을 클릭합니다.
머신 유형 섹션에서 다음을 입력한 후 계속을 클릭합니다.
- 머신 유형: N1을 선택한 다음 머신 유형 메뉴에서
n1-standard-4를 선택합니다. 보안 VM: 다음 체크박스를 선택합니다.
- 보안 부팅
- 가상 신뢰 플랫폼 모듈(vTPM)
- 무결성 모니터링
- 머신 유형: N1을 선택한 다음 머신 유형 메뉴에서
디스크 섹션에서 Google-managed encryption key가 선택되었는지 확인한 후 계속을 클릭합니다.
네트워킹 섹션에서 다음을 입력한 후 계속을 클릭합니다.
네트워킹: 이 프로젝트의 네트워크를 선택하고 다음 단계를 완료합니다.
네트워크 필드에서 vertex-networking-vpc를 선택합니다.
서브네트워크 필드에서 pipeline-networking-subnet1을 선택합니다.
외부 IP 주소 할당 체크박스를 선택 취소합니다. 외부 IP 주소를 할당하지 않으면 인스턴스가 인터넷이나 다른 VPC 네트워크에서 요청하지 않은 통신을 수신하지 못합니다.
프록시 액세스 허용 체크박스를 선택합니다.
IAM 및 보안 섹션에서 다음을 입력한 후 계속을 클릭합니다.
IAM 및 보안: 단일 사용자에게 인스턴스의 JupyterLab 인터페이스에 대한 액세스 권한을 부여하려면 다음 단계를 완료합니다.
- 서비스 계정을 선택합니다.
- Compute Engine 기본 서비스 계정 사용 체크박스를 선택 취소합니다.
Compute Engine 기본 서비스 계정(및 방금 지정한 단일 사용자)에 프로젝트에 대한 편집자 역할(
roles/editor)이 부여되므로 이 단계가 중요합니다. 서비스 계정 이메일 필드에서 다음을 입력하여 PROJECT_ID를 프로젝트 ID로 바꿉니다.
workbench-sa@PROJECT_ID.iam.gserviceaccount.com이전에 만든 커스텀 서비스 계정 이메일 주소입니다. 이 서비스 계정에는 제한된 권한이 있습니다.
액세스 권한 부여에 대한 자세한 내용은 Vertex AI Workbench 인스턴스의 JupyterLab 인터페이스에 대한 액세스 관리를 참조하세요.
보안 옵션: 다음 체크박스를 선택 취소합니다.
- 인스턴스에 대한 루트 액세스
다음 체크박스를 선택합니다.
- nbconvert:
nbconvert를 사용하면 사용자가 노트북 파일을 HTML, PDF 또는 LaTeX와 같은 다른 파일 형식으로 내보내고 다운로드할 수 있습니다. 이 설정은 Google Cloud 생성형 AI GitHub 저장소에서 일부 노트북에 필요합니다.
다음 체크박스를 선택 취소합니다.
- 파일 다운로드
프로덕션 환경이 아닌 경우 다음 체크박스를 선택합니다.
- 터미널 액세스: JupyterLab 사용자 인터페이스 내에서 인스턴스에 대한 터미널 액세스를 사용 설정합니다.
시스템 상태 섹션에서 환경 자동 업그레이드를 지우고 다음을 입력합니다.
보고에서 다음 체크박스를 선택합니다.
- 시스템 상태 보고
- Cloud Monitoring에 커스텀 측정항목 보고
- Cloud Monitoring 설치
- 필수 Google 도메인의 DNS 상태 보고
만들기를 클릭한 후에, Vertex AI Workbench 인스턴스가 생성될 때까지 몇 분 정도 기다립니다.
Vertex AI Workbench 인스턴스에서 학습 애플리케이션 실행
Google Cloud 콘솔에서 Vertex AI Workbench 페이지의 인스턴스 탭으로 이동합니다.
Vertex AI Workbench 인스턴스 이름(
pipeline-tutorial-PROJECT_ID, 여기서 PROJECT_ID는 프로젝트 ID임) 옆에 있는 JupyterLab 열기를 클릭합니다.Vertex AI Workbench 인스턴스가 JupyterLab을 엽니다.
File(파일) > New(새로 만들기) > Terminal(터미널)을 선택합니다.
JupyterLab 터미널(Cloud Shell 아님)에서 프로젝트의 환경 변수를 정의합니다. PROJECT_ID를 프로젝트 ID로 바꿉니다.
projectid=PROJECT_IDJupyterLab 터미널에서 학습 애플리케이션의 상위 디렉터리를 만듭니다.
mkdir fungi_training_package mkdir fungi_training_package/trainerFile Browser(파일 브라우저)에서
fungi_training_package폴더를 더블클릭한 다음trainer폴더를 더블클릭합니다.File Browser(파일 브라우저)에서 Name(이름) 제목 아래에 있는 빈 파일 목록을 마우스 오른쪽 버튼으로 클릭하고 New file(새 파일)을 선택합니다.
새 파일을 마우스 오른쪽 버튼으로 클릭하고 Rename file(파일 이름 바꾸기)를 선택합니다.
파일 이름을
untitled.txt에서task.py로 바꿉니다.task.py파일을 더블클릭하면 열립니다.다음 코드를
task.py에 복사합니다.# Import the libraries import tensorflow as tf from tensorflow.python.client import device_lib import argparse import os import sys # add parser arguments parser = argparse.ArgumentParser() parser.add_argument('--data-dir', dest='dataset_dir', type=str, help='Dir to access dataset.') parser.add_argument('--model-dir', dest='model_dir', default=os.getenv("AIP_MODEL_DIR"), type=str, help='Dir to save the model.') parser.add_argument('--epochs', dest='epochs', default=10, type=int, help='Number of epochs.') parser.add_argument('--batch-size', dest='batch_size', default=32, type=int, help='Number of images per batch.') parser.add_argument('--distribute', dest='distribute', default='single', type=str, help='distributed training strategy.') args = parser.parse_args() # print the tf version and config print('Python Version = {}'.format(sys.version)) print('TensorFlow Version = {}'.format(tf.__version__)) print('TF_CONFIG = {}'.format(os.environ.get('TF_CONFIG', 'Not found'))) print('DEVICES', device_lib.list_local_devices()) # Single Machine, single compute device if args.distribute == 'single': if tf.test.is_gpu_available(): strategy = tf.distribute.OneDeviceStrategy(device="/gpu:0") else: strategy = tf.distribute.OneDeviceStrategy(device="/cpu:0") # Single Machine, multiple compute device elif args.distribute == 'mirror': strategy = tf.distribute.MirroredStrategy() # Multiple Machine, multiple compute device elif args.distribute == 'multi': strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy() # Multi-worker configuration print('num_replicas_in_sync = {}'.format(strategy.num_replicas_in_sync)) # Preparing dataset BUFFER_SIZE = 1000 IMG_HEIGHT = 224 IMG_WIDTH = 224 def make_datasets_batched(dataset_path, global_batch_size): # Configure the training data generator train_data_dir = os.path.join(dataset_path,"train/") train_ds = tf.keras.utils.image_dataset_from_directory( train_data_dir, seed=36, image_size=(IMG_HEIGHT, IMG_WIDTH), batch_size=global_batch_size ) # Configure the validation data generator val_data_dir = os.path.join(dataset_path,"valid/") val_ds = tf.keras.utils.image_dataset_from_directory( val_data_dir, seed=36, image_size=(IMG_HEIGHT, IMG_WIDTH), batch_size=global_batch_size ) # get the number of classes in the data num_classes = len(train_ds.class_names) # Configure the dataset for performance AUTOTUNE = tf.data.AUTOTUNE train_ds = train_ds.cache().shuffle(BUFFER_SIZE).prefetch(buffer_size=AUTOTUNE) val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE) return train_ds, val_ds, num_classes # Build the Keras model def build_and_compile_cnn_model(num_classes): # build a CNN model model = tf.keras.models.Sequential([ tf.keras.layers.Rescaling(1./255, input_shape=(IMG_HEIGHT, IMG_WIDTH, 3)), tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(num_classes) ]) # compile the CNN model model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) return model # Get the strategy data NUM_WORKERS = strategy.num_replicas_in_sync # Here the batch size scales up by number of workers GLOBAL_BATCH_SIZE = args.batch_size * NUM_WORKERS # Create dataset generator objects train_ds, val_ds, num_classes = make_datasets_batched(args.dataset_dir, GLOBAL_BATCH_SIZE) # Compile the model with strategy.scope(): # Creation of dataset, and model building/compiling need to be within # `strategy.scope()`. model = build_and_compile_cnn_model(num_classes) # fit the model on the data history = model.fit(train_ds, validation_data=val_ds, epochs=args.epochs) # save the model to the output dir model.save(args.model_dir)File(파일) > Save Python file(Python 파일 저장)을 선택합니다.
JupyterLab 터미널에서 각 하위 디렉터리에
__init__.py파일을 만들어 패키지로 만듭니다.touch fungi_training_package/__init__.py touch fungi_training_package/trainer/__init__.pyFile Browser(파일 브라우저)에서
fungi_training_package폴더를 더블클릭합니다.File(파일) > New(새로 만들기) > Python file(Python 파일)을 선택합니다.
새 파일을 마우스 오른쪽 버튼으로 클릭하고 Rename file(파일 이름 바꾸기)를 선택합니다.
파일 이름을
untitled.py에서setup.py로 바꿉니다.setup.py파일을 더블클릭하면 열립니다.다음 코드를
setup.py에 복사합니다.from setuptools import find_packages from setuptools import setup setup( name='trainer', version='0.1', packages=find_packages(), include_package_data=True, description='Training application package for fungi-classification.' )File(파일) > Save Python file(Python 파일 저장)을 선택합니다.
터미널에서
fungi_training_package디렉터리로 이동합니다.cd fungi_training_packagesdist명령어를 사용하여 학습 애플리케이션의 소스 배포를 만듭니다.python setup.py sdist --formats=gztar상위 디렉터리로 이동합니다.
cd ..올바른 디렉터리에 있는지 확인합니다.
pwd출력 형식은 다음과 같습니다.
/home/jupyterPython 패키지를 스테이징 버킷에 복사합니다.
gcloud storage cp fungi_training_package/dist/trainer-0.1.tar.gz gs://pipelines-staging-bucket-$projectid/training_package/스테이징 버킷에 패키지가 포함되어 있는지 확인합니다.
gcloud storage ls gs://pipelines-staging-bucket-$projectid/training_package출력은 다음과 같습니다.
gs://pipelines-staging-bucket-PROJECT_ID/training_package/trainer-0.1.tar.gz
Vertex AI Pipelines의 서비스 네트워킹 연결 만들기
이 섹션에서는 VPC 네트워크 피어링을 통해 vertex-networking-vpc VPC 네트워크에 연결된 프로듀서 서비스를 설정하는 데 사용되는 서비스 네트워킹 연결을 만듭니다. 자세한 내용은 VPC 네트워크 피어링을 참조하세요.
Cloud Shell에서 다음 명령어를 실행하고 PROJECT_ID를 프로젝트 ID로 바꿉니다.
projectid=PROJECT_ID gcloud config set project ${projectid}gcloud compute addresses create를 사용하여 예약된 IP 주소 범위를 설정합니다.gcloud compute addresses create vertex-pipeline-subnet \ --global \ --purpose=VPC_PEERING \ --addresses=192.168.10.0 \ --prefix-length=24 \ --description="pipeline subnet" \ --network=vertex-networking-vpcgcloud services vpc-peerings connect를 사용하여vertex-networking-vpcVPC 네트워크와 Google 서비스 네트워킹 간에 피어링 연결을 설정합니다.gcloud services vpc-peerings connect \ --service=servicenetworking.googleapis.com \ --ranges=vertex-pipeline-subnet \ --network=vertex-networking-vpc커스텀 학습된 경로의 가져오기 및 내보내기를 사용 설정하도록 VPC 피어링 연결을 업데이트합니다.
gcloud compute networks peerings update servicenetworking-googleapis-com \ --network=vertex-networking-vpc \ --import-custom-routes \ --export-custom-routes
pipeline-networking Cloud Router에서 파이프라인 서브넷 공지
Google Cloud 콘솔에서 Cloud Router 페이지로 이동합니다.
Cloud Router 목록에서
vertex-networking-vpc-router1을 클릭합니다.라우터 세부정보 페이지에서 수정을 클릭합니다.
커스텀 경로 추가를 클릭합니다.
소스에 커스텀 IP 범위를 선택합니다.
IP 주소 범위에 다음 IP 주소 범위를 입력합니다.
192.168.10.0/24설명에 다음 텍스트를 입력합니다.
Vertex AI Pipelines reserved subnet완료를 클릭한 다음 저장을 클릭합니다.
파이프라인 템플릿을 만들고 Artifact Registry에 업로드
이 섹션에서는 Kubeflow Pipelines(KFP) 파이프라인 템플릿을 만들고 업로드합니다. 이 템플릿에는 단일 사용자 또는 여러 사용자가 여러 번 재사용할 수 있는 워크플로 정의가 포함되어 있습니다.
파이프라인 정의 및 컴파일
Jupyterlab의 파일 브라우저에서 최상위 폴더를 더블클릭합니다.
파일 > 새로 만들기 > 노트북을 선택합니다.
Select Kernel(커널 선택) 메뉴에서
Python 3 (ipykernel)을 선택하고 Select(선택)를 클릭합니다.새 노트북 셀에서 다음 명령어를 실행하여
pip의 최신 버전을 실행하고 있는지 확인합니다.!python -m pip install --upgrade pip다음 명령어를 실행하여 Python 패키지 색인 (PyPI)에서 Google Cloud 파이프라인 구성요소 SDK를 설치합니다.
!pip install --upgrade google-cloud-pipeline-components설치가 완료되면 Kernel(커널) > Restart kernel(커널 다시 시작)을 선택하여 커널을 다시 시작하고 라이브러리를 가져올 수 있는지 확인합니다.
새 노트북 셀에서 다음 코드를 실행하여 파이프라인을 정의합니다.
from kfp import dsl # define the train-deploy pipeline @dsl.pipeline(name="custom-image-classification-pipeline") def custom_image_classification_pipeline( project: str, training_job_display_name: str, worker_pool_specs: list, base_output_dir: str, model_artifact_uri: str, prediction_container_uri: str, model_display_name: str, endpoint_display_name: str, network: str = '', location: str="us-central1", serving_machine_type: str="n1-standard-4", serving_min_replica_count: int=1, serving_max_replica_count: int=1 ): from google_cloud_pipeline_components.types import artifact_types from google_cloud_pipeline_components.v1.custom_job import CustomTrainingJobOp from google_cloud_pipeline_components.v1.model import ModelUploadOp from google_cloud_pipeline_components.v1.endpoint import (EndpointCreateOp, ModelDeployOp) from kfp.dsl import importer # Train the model task custom_job_task = CustomTrainingJobOp( project=project, display_name=training_job_display_name, worker_pool_specs=worker_pool_specs, base_output_directory=base_output_dir, location=location, network=network ) # Import the model task import_unmanaged_model_task = importer( artifact_uri=model_artifact_uri, artifact_class=artifact_types.UnmanagedContainerModel, metadata={ "containerSpec": { "imageUri": prediction_container_uri, }, }, ).after(custom_job_task) # Model upload task model_upload_op = ModelUploadOp( project=project, display_name=model_display_name, unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"], ) model_upload_op.after(import_unmanaged_model_task) # Create Endpoint task endpoint_create_op = EndpointCreateOp( project=project, display_name=endpoint_display_name, ) # Deploy the model to the endpoint ModelDeployOp( endpoint=endpoint_create_op.outputs["endpoint"], model=model_upload_op.outputs["model"], dedicated_resources_machine_type=serving_machine_type, dedicated_resources_min_replica_count=serving_min_replica_count, dedicated_resources_max_replica_count=serving_max_replica_count, )새 노트북 셀에서 다음 코드를 실행하여 파이프라인 정의를 컴파일합니다.
from kfp import compiler PIPELINE_FILE = "pipeline_config.yaml" compiler.Compiler().compile( pipeline_func=custom_image_classification_pipeline, package_path=PIPELINE_FILE, )File Browser(파일 브라우저)에서
pipeline_config.yaml이라는 파일이 파일 목록에 표시됩니다.
Artifact Registry 저장소 만들기
새 노트북 셀에서 다음 코드를 실행하여 KFP 유형의 아티팩트 저장소를 만듭니다.
REPO_NAME="fungi-repo" REGION="us-central1" !gcloud artifacts repositories create $REPO_NAME --location=$REGION --repository-format=KFP
Artifact Registry에 파이프라인 템플릿 업로드
이 섹션에서는 Kubeflow Pipelines SDK 레지스트리 클라이언트를 구성하고 JupyterLab 노트북에서 컴파일된 파이프라인 템플릿을 Artifact Registry에 업로드합니다.
JupyterLab 노트북에서 다음 코드를 실행하여 파이프라인 템플릿을 업로드하고 PROJECT_ID를 프로젝트 ID로 바꿉니다.
PROJECT_ID = "PROJECT_ID" from kfp.registry import RegistryClient host = f"https://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}" client = RegistryClient(host=host) TEMPLATE_NAME, VERSION_NAME = client.upload_pipeline( file_name=PIPELINE_FILE, tags=["v1", "latest"], extra_headers={"description":"This is an example pipeline template."})Google Cloud 콘솔에서 템플릿이 업로드되었는지 확인하려면 Vertex AI Pipelines 템플릿으로 이동합니다.
저장소 선택 창을 열려면 저장소 선택을 클릭합니다.
저장소 목록에서 만든 저장소(
fungi-repo)를 클릭한 다음 선택을 클릭합니다.파이프라인(
custom-image-classification-pipeline)이 목록에 표시되는지 확인합니다.
온프레미스에서 파이프라인 실행 트리거
이제 파이프라인 템플릿과 학습 패키지가 준비되었으므로 이 섹션에서는 cURL을 사용하여 온프레미스 애플리케이션에서 파이프라인 실행을 트리거합니다.
파이프라인 매개변수 제공
JupyterLab 노트북에서 다음 명령어를 실행하여 파이프라인 템플릿 이름을 확인합니다.
print (TEMPLATE_NAME)반환된 템플릿 이름은 다음과 같습니다.
custom-image-classification-pipeline다음 명령어를 실행하여 파이프라인 템플릿 버전을 가져옵니다.
print (VERSION_NAME)반환된 파이프라인 템플릿 버전 이름은 다음과 같습니다.
sha256:41eea21e0d890460b6e6333c8070d7d23d314afd9c7314c165efd41cddff86c7전체 버전 이름 문자열을 기록해 둡니다.
Cloud Shell에서 다음 명령어를 실행하고 PROJECT_ID를 프로젝트 ID로 바꿉니다.
projectid=PROJECT_ID gcloud config set project ${projectid}on-prem-dataservice-hostVM 인스턴스에 로그인합니다.gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapon-prem-dataservice-hostVM 인스턴스에서vim또는nano와 같은 텍스트 편집기를 사용하여request_body.json파일을 만듭니다. 예를 들면 다음과 같습니다.sudo vim request_body.jsonrequest_body.json파일에 다음 텍스트를 추가합니다.{ "displayName": "fungi-image-pipeline-job", "serviceAccount": "onprem-user-managed-sa@PROJECT_ID.iam.gserviceaccount.com", "runtimeConfig":{ "gcsOutputDirectory":"gs://pipelines-staging-bucket-PROJECT_ID/pipeline_root/", "parameterValues": { "project": "PROJECT_ID", "training_job_display_name": "fungi-image-training-job", "worker_pool_specs": [{ "machine_spec": { "machine_type": "n1-standard-4" }, "replica_count": 1, "python_package_spec":{ "executor_image_uri":"us-docker.pkg.dev/vertex-ai/training/tf-cpu.2-8.py310:latest", "package_uris": ["gs://pipelines-staging-bucket-PROJECT_ID/training_package/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args": ["--data-dir","/mnt/nfs/fungi_dataset/", "--epochs", "10"], "env": [{"name": "AIP_MODEL_DIR", "value": "gs://pipelines-staging-bucket-PROJECT_ID/model/"}] }, "nfs_mounts": [{ "server": "FILESTORE_INSTANCE_IP", "path": "/vol1", "mount_point": "/mnt/nfs/" }] }], "base_output_dir":"gs://pipelines-staging-bucket-PROJECT_ID", "model_artifact_uri":"gs://pipelines-staging-bucket-PROJECT_ID/model/", "prediction_container_uri":"us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest", "model_display_name":"fungi-image-model", "endpoint_display_name":"fungi-image-endpoint", "location": "us-central1", "serving_machine_type":"n1-standard-4", "network":"projects/PROJECT_NUMBER/global/networks/vertex-networking-vpc" } }, "templateUri": "https://us-central1-kfp.pkg.dev/PROJECT_ID/fungi-repo/custom-image-classification-pipeline/latest", "templateMetadata": { "version":"VERSION_NAME" } }다음 값을 바꿉니다.
- PROJECT_ID: 프로젝트 ID입니다.
- PROJECT_NUMBER: 프로젝트 번호입니다. 프로젝트 ID와는 다릅니다.Google Cloud 콘솔에 있는 프로젝트의 프로젝트 설정 페이지에서 프로젝트 번호를 찾을 수 있습니다.
- FILESTORE_INSTANCE_IP: Filestore 인스턴스 IP 주소입니다(예:
10.243.208.2). 인스턴스의 Filestore 인스턴스 페이지에서 확인할 수 있습니다. - VERSION_NAME: 2단계에서 메모한 파이프라인 템플릿 버전 이름(
sha256:...)입니다.
다음과 같이 파일을 저장합니다.
vim을 사용하는 경우Esc키를 누른 후:wq를 입력하여 파일을 저장하고 종료합니다.nano를 사용하는 경우Control+O을 입력하고Enter를 눌러 파일을 저장한 후Control+X를 입력하여 종료합니다.
템플릿에서 파이프라인 실행 제출
on-prem-dataservice-hostVM 인스턴스에서 PROJECT_ID를 프로젝트 ID로 바꿔 다음 명령어를 실행합니다.curl -v -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ -d @request_body.json \ https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/pipelineJobs출력은 길지만 서비스가 파이프라인을 실행할 준비 중임을 나타내는 다음 줄을 확인해야 합니다.
"state": "PIPELINE_STATE_PENDING"전체 파이프라인 실행에는 약 45~50분이 소요됩니다.
Google Cloud 콘솔의 Vertex AI 섹션에서 파이프라인 페이지의 실행 탭으로 이동합니다.
파이프라인 실행의 실행 이름(
custom-image-classification-pipeline)을 클릭합니다.파이프라인 실행 페이지가 표시되고 파이프라인의 런타임 그래프가 표시됩니다. 파이프라인 요약이 파이프라인 실행 분석 창에 표시됩니다.
로그를 보고 Vertex ML Metadata를 사용하여 파이프라인의 아티팩트에 관해 자세히 알아보는 방법을 비롯하여 런타임 그래프에 표시되는 정보를 이해하는 데 도움이 필요한 경우 파이프라인 결과 시각화 및 분석을 참고하세요.