Vertex AI Pipelines est un service géré qui vous aide à créer, déployer et gérer des workflows de machine learning (ML) de bout en bout sur Google Cloud Platform. Il fournit un environnement sans serveur pour exécuter vos pipelines afin que vous n'ayez pas à vous soucier de la gestion de l'infrastructure.
Dans ce tutoriel, vous allez utiliser Vertex AI Pipelines pour exécuter un job d'entraînement personnalisé et déployer le modèle entraîné dans Vertex AI, dans un environnement de réseau hybride.
L'ensemble du processus prend deux à trois heures, dont environ 50 minutes pour l'exécution du pipeline.
Ce tutoriel est destiné aux administrateurs réseau d'entreprise, aux data scientists et aux chercheurs qui connaissent déjà Vertex AI, le cloud privé virtuel (VPC), la console Google Cloud et Cloud Shell. Une connaissance de Vertex AI Workbench est utile, mais pas obligatoire.
Objectifs
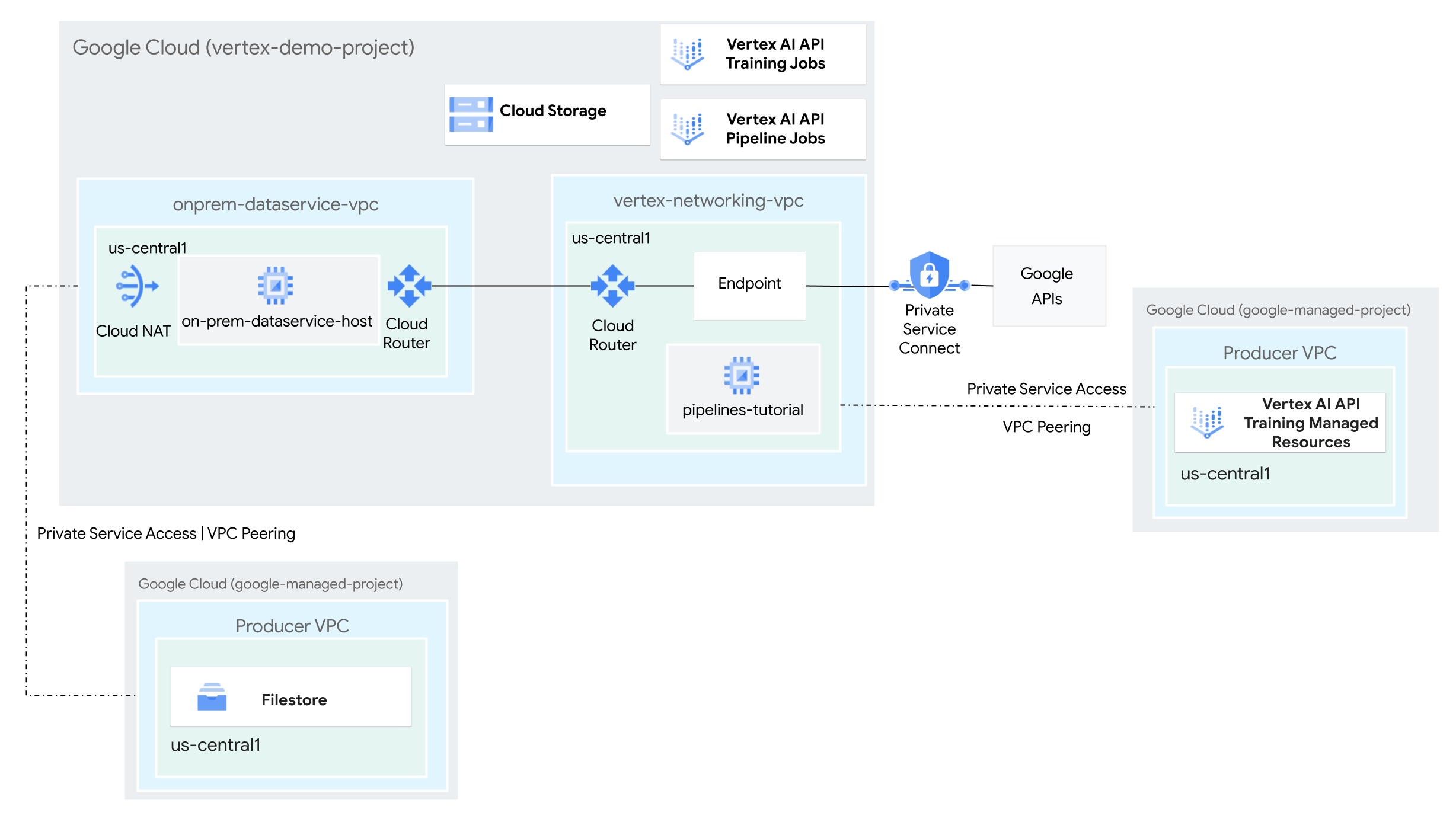
- Créez deux réseaux cloud privés virtuels (VPC) :
- L'un d'eux (
vertex-networking-vpc) permet d'utiliser l'API Vertex AI Pipelines pour créer et héberger un modèle de pipeline afin d'entraîner un modèle de machine learning et de le déployer sur un point de terminaison. - L'autre (
onprem-dataservice-vpc) représente un réseau sur site.
- L'un d'eux (
- Connectez les deux réseaux VPC comme suit :
- Déployer des passerelles VPN haute disponibilité, des tunnels Cloud VPN et des routeurs Cloud Router pour connecter
vertex-networking-vpcetonprem-dataservice-vpc. - Créer un point de terminaison Private Service Connect (PSC) pour transférer des requêtes privées vers l'API REST de Vertex AI Pipelines
- Configurer une annonce de routage personnalisée Cloud Router dans
vertex-networking-vpcpour annoncer les routes du point de terminaison Private Service Connect àonprem-dataservice-vpc.
- Déployer des passerelles VPN haute disponibilité, des tunnels Cloud VPN et des routeurs Cloud Router pour connecter
- Créez une instance Filestore dans le réseau VPC
onprem-dataservice-vpcet ajoutez-y des données d'entraînement dans un partage NFS. - Créez une application de package Python pour le job d'entraînement.
- Créez un modèle de job Vertex AI Pipelines pour effectuer les opérations suivantes :
- Créez et exécutez le job d'entraînement sur les données du partage NFS.
- Importez le modèle entraîné et transférez-le vers Vertex AI Model Registry.
- Créez un point de terminaison Vertex AI pour les prédictions en ligne.
- Déployez le modèle sur le point de terminaison.
- Importez le modèle de pipeline dans un dépôt Artifact Registry.
- Utilisez l'API REST de Vertex AI Pipelines pour déclencher une exécution de pipeline à partir d'un hôte de service de données sur site (
on-prem-dataservice-host).
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
Obtenez une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Une fois que vous avez terminé les tâches décrites dans ce document, vous pouvez éviter de continuer à payer des frais en supprimant les ressources que vous avez créées. Pour en savoir plus, consultez la section Effectuer un nettoyage.
Avant de commencer
-
In the Google Cloud console, go to the project selector page.
-
Select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- Ouvrez Cloud Shell pour exécuter les commandes répertoriées dans ce tutoriel. Cloud Shell est un environnement shell interactif pour Google Cloud qui vous permet de gérer vos projets et vos ressources depuis un navigateur Web.
- Dans Cloud Shell, définissez le projet actuel sur votre ID de projet Google Cloud, puis stockez le même ID de projet dans la variable de shell
projectid:projectid="PROJECT_ID" gcloud config set project ${projectid} - Si vous n'êtes pas le propriétaire du projet, demandez-lui de vous accorder le rôle Administrateur de projet IAM (
roles/resourcemanager.projectIamAdmin). Vous devez disposer de ce rôle pour attribuer des rôles IAM à l'étape suivante. -
Grant roles to your user account. Run the following command once for each of the following IAM roles:
roles/artifactregistry.admin, roles/artifactregistry.repoAdmin, roles/compute.instanceAdmin.v1, roles/compute.networkAdmin, roles/compute.securityAdmin, roles/dns.admin, roles/file.editor, roles/logging.viewer, roles/logging.admin, roles/notebooks.admin, roles/iam.serviceAccountAdmin, roles/iam.serviceAccountUser, roles/servicedirectory.editor, roles/servicemanagement.quotaAdmin, roles/serviceusage.serviceUsageAdmin, roles/storage.admin, roles/storage.objectAdmin, roles/aiplatform.admin, roles/aiplatform.user, roles/aiplatform.viewer, roles/iap.admin, roles/iap.tunnelResourceAccessor, roles/resourcemanager.projectIamAdmingcloud projects add-iam-policy-binding PROJECT_ID --member="user:USER_IDENTIFIER" --role=ROLE
- Replace
PROJECT_IDwith your project ID. -
Replace
USER_IDENTIFIERwith the identifier for your user account. For example,user:myemail@example.com. - Replace
ROLEwith each individual role.
- Replace
-
Enable the DNS, Artifact Registry, IAM, Compute Engine, Cloud Logging, Network Connectivity, Notebooks, Cloud Filestore, Service Networking, Service Usage, and Vertex AI APIs:
gcloud services enable dns.googleapis.com
artifactregistry.googleapis.com iam.googleapis.com compute.googleapis.com logging.googleapis.com networkconnectivity.googleapis.com notebooks.googleapis.com file.googleapis.com servicenetworking.googleapis.com serviceusage.googleapis.com aiplatform.googleapis.com
Créer les réseaux VPC
Dans cette section, vous allez créer deux réseaux VPC : l'un pour accéder aux API Google pour Vertex AI Pipelines, et l'autre pour simuler un réseau sur site. Dans chacun des deux réseaux VPC, vous créez un routeur Cloud Router et une passerelle Cloud NAT. Une passerelle Cloud NAT fournit une connectivité sortante pour les instances de machines virtuelles (VM) Compute Engine sans adresse IP externe.
Dans Cloud Shell, exécutez les commandes suivantes, en remplaçant PROJECT_ID par votre ID de projet :
projectid=PROJECT_ID gcloud config set project ${projectid}Créer le réseau VPC
vertex-networking-vpc:gcloud compute networks create vertex-networking-vpc \ --subnet-mode customDans le réseau
vertex-networking-vpc, créez un sous-réseau nommépipeline-networking-subnet1, avec10.0.0.0/24comme plage d'adresses IPv4 principale :gcloud compute networks subnets create pipeline-networking-subnet1 \ --range=10.0.0.0/24 \ --network=vertex-networking-vpc \ --region=us-central1 \ --enable-private-ip-google-accessCréez le réseau VPC pour simuler le réseau sur site (
onprem-dataservice-vpc) :gcloud compute networks create onprem-dataservice-vpc \ --subnet-mode customDans le réseau
onprem-dataservice-vpc, créez un sous-réseau nomméonprem-dataservice-vpc-subnet1, avec172.16.10.0/24comme plage d'adresses IPv4 principale :gcloud compute networks subnets create onprem-dataservice-vpc-subnet1 \ --network onprem-dataservice-vpc \ --range 172.16.10.0/24 \ --region us-central1 \ --enable-private-ip-google-access
Vérifier que les réseaux VPC sont correctement configurés
Dans la console Google Cloud, accédez à l'onglet Réseaux du projet en cours sur la page Réseaux VPC.
Dans la liste des réseaux VPC, vérifiez que les deux réseaux ont été créés :
vertex-networking-vpcetonprem-dataservice-vpc.Cliquez sur l'onglet Sous-réseaux dans le projet actuel.
Dans la liste des sous-réseaux VPC, vérifiez que les sous-réseaux
pipeline-networking-subnet1etonprem-dataservice-vpc-subnet1ont été créés.
Configurer la connectivité hybride
Dans cette section, vous allez créer deux passerelles VPN haute disponibilité connectées l'une à l'autre. L'une réside dans le réseau VPC vertex-networking-vpc. L'autre réside dans le réseau VPC onprem-dataservice-vpc. Chaque passerelle contient un routeur Cloud Router et une paire de tunnels VPN.
Créer des passerelles VPN haute disponibilité
Dans Cloud Shell, créez la passerelle VPN haute disponibilité pour le réseau VPC
vertex-networking-vpc:gcloud compute vpn-gateways create vertex-networking-vpn-gw1 \ --network vertex-networking-vpc \ --region us-central1Créez la passerelle VPN haute disponibilité pour le réseau VPC
onprem-dataservice-vpc:gcloud compute vpn-gateways create onprem-vpn-gw1 \ --network onprem-dataservice-vpc \ --region us-central1Dans la console Google Cloud, accédez à l'onglet Passerelles Cloud VPN sur la page VPN.
Vérifiez que les deux passerelles (
vertex-networking-vpn-gw1etonprem-vpn-gw1) ont été créées et que chacune dispose de deux adresses IP d'interface.
Créer des routeurs Cloud et des passerelles Cloud NAT
Dans chacun des deux réseaux VPC, vous créez deux routeurs Cloud Router : un à utiliser avec Cloud NAT et un autre pour gérer les sessions BGP du VPN haute disponibilité.
Dans Cloud Shell, créez un routeur Cloud Router pour le réseau VPC
vertex-networking-vpcqui sera utilisé pour le VPN :gcloud compute routers create vertex-networking-vpc-router1 \ --region us-central1 \ --network vertex-networking-vpc \ --asn 65001Créez un routeur Cloud Router pour le réseau VPC
onprem-dataservice-vpcqui sera utilisé pour le VPN :gcloud compute routers create onprem-dataservice-vpc-router1 \ --region us-central1 \ --network onprem-dataservice-vpc \ --asn 65002Créez un routeur Cloud Router pour le réseau VPC
vertex-networking-vpcqui sera utilisé pour Cloud NAT :gcloud compute routers create cloud-router-us-central1-vertex-nat \ --network vertex-networking-vpc \ --region us-central1Configurez une passerelle Cloud NAT sur le routeur Cloud Router :
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-vertex-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1Créez un routeur Cloud Router pour le réseau VPC
onprem-dataservice-vpcqui sera utilisé pour Cloud NAT :gcloud compute routers create cloud-router-us-central1-onprem-nat \ --network onprem-dataservice-vpc \ --region us-central1Configurez une passerelle Cloud NAT sur le routeur Cloud Router :
gcloud compute routers nats create cloud-nat-us-central1-on-prem \ --router=cloud-router-us-central1-onprem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1Dans Google Cloud Console, accédez à la page Routeurs cloud.
Dans la liste des routeurs cloud, vérifiez que les routeurs suivants ont été créés:
cloud-router-us-central1-onprem-natcloud-router-us-central1-vertex-natonprem-dataservice-vpc-router1vertex-networking-vpc-router1
Vous devrez peut-être actualiser l'onglet du navigateur de la console Google Cloud pour afficher les nouvelles valeurs.
Dans la liste des routeurs Cloud Router, cliquez sur
cloud-router-us-central1-vertex-nat.Sur la page Détails du routeur, vérifiez que la passerelle Cloud NAT
cloud-nat-us-central1a été créée.Cliquez sur la flèche de retour pour revenir à la page Routeurs cloud.
Dans la liste des routeurs Cloud Router, cliquez sur
cloud-router-us-central1-onprem-nat.Sur la page Détails du routeur, vérifiez que la passerelle Cloud NAT
cloud-nat-us-central1-on-prema été créée.
Créer des tunnels VPN
Dans Cloud Shell, dans le réseau
vertex-networking-vpc, créez un tunnel VPN appelévertex-networking-vpc-tunnel0:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel0 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 0Dans le réseau
vertex-networking-vpc, créez un tunnel VPN appelévertex-networking-vpc-tunnel1:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel1 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 1Dans le réseau
onprem-dataservice-vpc, créez un tunnel VPN appeléonprem-dataservice-vpc-tunnel0:gcloud compute vpn-tunnels create onprem-dataservice-vpc-tunnel0 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router onprem-dataservice-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 0Dans le réseau
onprem-dataservice-vpc, créez un tunnel VPN appeléonprem-dataservice-vpc-tunnel1:gcloud compute vpn-tunnels create onprem-dataservice-vpc-tunnel1 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router onprem-dataservice-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 1Dans Google Cloud Console, accédez à la page VPN.
Dans la liste des tunnels VPN, vérifiez que les quatre tunnels VPN ont été créés.
Établir des sessions BGP
Cloud Router utilise le protocole BGP (Border Gateway Protocol) pour échanger des routes entre votre réseau VPC (dans ce cas, vertex-networking-vpc) et votre réseau sur site (représenté par onprem-dataservice-vpc). Sur Cloud Router, vous configurez une interface et un pair BGP pour votre routeur sur site.
Ensemble, l'interface et la configuration du pair BGP forment une session BGP.
Dans cette section, vous allez créer deux sessions BGP pour vertex-networking-vpc et deux pour onprem-dataservice-vpc.
Une fois que vous avez configuré les interfaces et les pairs BGP entre vos routeurs, ils commencent automatiquement à échanger des routes.
Établir des sessions BGP pour vertex-networking-vpc
Dans Cloud Shell, dans le réseau
vertex-networking-vpc, créez une interface BGP pourvertex-networking-vpc-tunnel0:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.0.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel0 \ --region us-central1Dans le réseau
vertex-networking-vpc, créez un pair BGP pourbgp-onprem-tunnel0:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel0 \ --interface if-tunnel0-to-onprem \ --peer-ip-address 169.254.0.2 \ --peer-asn 65002 \ --region us-central1Dans le réseau
vertex-networking-vpc, créez une interface BGP pourvertex-networking-vpc-tunnel1:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel1 \ --region us-central1Dans le réseau
vertex-networking-vpc, créez un pair BGP pourbgp-onprem-tunnel1:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel1 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central1
Établir des sessions BGP pour onprem-dataservice-vpc
Dans le réseau
onprem-dataservice-vpc, créez une interface BGP pouronprem-dataservice-vpc-tunnel0:gcloud compute routers add-interface onprem-dataservice-vpc-router1 \ --interface-name if-tunnel0-to-vertex-networking-vpc \ --ip-address 169.254.0.2 \ --mask-length 30 \ --vpn-tunnel onprem-dataservice-vpc-tunnel0 \ --region us-central1Dans le réseau
onprem-dataservice-vpc, créez un pair BGP pourbgp-vertex-networking-vpc-tunnel0:gcloud compute routers add-bgp-peer onprem-dataservice-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel0 \ --interface if-tunnel0-to-vertex-networking-vpc \ --peer-ip-address 169.254.0.1 \ --peer-asn 65001 \ --region us-central1Dans le réseau
onprem-dataservice-vpc, créez une interface BGP pouronprem-dataservice-vpc-tunnel1:gcloud compute routers add-interface onprem-dataservice-vpc-router1 \ --interface-name if-tunnel1-to-vertex-networking-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel onprem-dataservice-vpc-tunnel1 \ --region us-central1Dans le réseau
onprem-dataservice-vpc, créez un pair BGP pourbgp-vertex-networking-vpc-tunnel1:gcloud compute routers add-bgp-peer onprem-dataservice-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel1 \ --interface if-tunnel1-to-vertex-networking-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central1
Valider la création de la session BGP
Dans Google Cloud Console, accédez à la page VPN.
Dans la liste des tunnels VPN, vérifiez que la valeur du champ État de la session BGP pour chacun des tunnels est passée de Configurer la session BGP à BGP établi. Vous devrez peut-être actualiser l'onglet du navigateur de la console Google Cloud pour afficher les nouvelles valeurs.
Valider les routes apprises onprem-dataservice-vpc
Dans la console Google Cloud, accédez à la page Réseaux VPC.
Dans la liste des réseaux VPC, cliquez sur
onprem-dataservice-vpc.Cliquez sur l'onglet Routes.
Sélectionnez us-central1 (Iowa) dans la liste Région, puis cliquez sur Afficher.
Dans la colonne Plage d'adresses IP de destination, vérifiez que la plage d'adresses IP du sous-réseau
pipeline-networking-subnet1(10.0.0.0/24) apparaît deux fois.Vous devrez peut-être actualiser l'onglet du navigateur de la console Google Cloud pour afficher les deux entrées.
Valider les routes apprises vertex-networking-vpc
Cliquez sur la flèche de retour pour revenir à la page Réseaux VPC.
Dans la liste des réseaux VPC, cliquez sur
vertex-networking-vpc.Cliquez sur l'onglet Routes.
Sélectionnez us-central1 (Iowa) dans la liste Région, puis cliquez sur Afficher.
Dans la colonne Plage d'adresses IP de destination, vérifiez que la plage d'adresses IP du sous-réseau
onprem-dataservice-vpc-subnet1(172.16.10.0/24) apparaît deux fois.
Créer un point de terminaison Private Service Connect pour les API Google
Dans cette section, vous allez créer un point de terminaison Private Service Connect pour les API Google que vous utiliserez pour accéder à l'API REST de Vertex AI Pipelines à partir de votre réseau sur site.
Dans Cloud Shell, réservez une adresse IP de point de terminaison client qui servira à accéder aux API Google:
gcloud compute addresses create psc-googleapi-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=192.168.0.1 \ --network=vertex-networking-vpcCréez une règle de transfert pour connecter le point de terminaison aux API et services Google.
gcloud compute forwarding-rules create pscvertex \ --global \ --network=vertex-networking-vpc \ --address=psc-googleapi-ip \ --target-google-apis-bundle=all-apis
Créer des annonces de routage personnalisées pour vertex-networking-vpc
Dans cette section, vous allez créer une annonce de routage personnalisée pour vertex-networking-vpc-router1 (le routeur Cloud Router pour vertex-networking-vpc) afin d'annoncer l'adresse IP du point de terminaison PSC au réseau VPC onprem-dataservice-vpc.
Dans Google Cloud Console, accédez à la page Routeurs cloud.
Dans la liste des routeurs Cloud Router, cliquez sur
vertex-networking-vpc-router1.Sur la page Détails du routeur, cliquez sur Modifier.
Dans la section Routes annoncées, sélectionnez Créer des routes personnalisées pour le paramètre Routes.
Sélectionnez Diffuser tous les sous-réseaux visibles par Cloud Router pour continuer à annoncer les sous-réseaux disponibles pour le routeur cloud. Cette option imite le comportement de Cloud Router en mode d'annonce par défaut.
Cliquez sur Ajouter une route personnalisée.
Dans Source, sélectionnez Plage d'adresses IP personnalisée.
Dans le champ Plage d'adresses IP, saisissez l'adresse IP suivante :
192.168.0.1Dans le champ Description, saisissez le texte suivant :
Custom route to advertise Private Service Connect endpoint IP addressCliquez sur OK, puis sur Enregistrer.
Vérifier que onprem-dataservice-vpc a appris les routes annoncées
Dans la console Google Cloud, accédez à la page Routes.
Dans l'onglet Routes effectives, procédez comme suit :
- Pour Réseau, choisissez
onprem-dataservice-vpc. - Dans le champ Région, choisissez
us-central1 (Iowa). - Cliquez sur Afficher.
Dans la liste des routes, vérifiez qu'il existe deux entrées dont le nom commence par
onprem-dataservice-vpc-router1-bgp-vertex-networking-vpc-tunnel0et deux entrées dont le nom commenc paronprem-dataservice-vpc-router1-bgp-vertex-networking-vpc-tunnel1.Si ces entrées n'apparaissent pas immédiatement, attendez quelques minutes, puis actualisez l'onglet de navigateur de la console Google Cloud.
Vérifiez que deux des entrées ont une plage d'adresses IP de destination de
192.168.0.1/32et que deux entrées ont une plage d'adresses IP de destination de10.0.0.0/24.
- Pour Réseau, choisissez
Créer une VM dans une instance dans onprem-dataservice-vpc
Dans cette section, vous allez créer une instance de VM qui simule un hôte de service de données sur site. En appliquant les bonnes pratiques de Compute Engine et d'IAM, cette VM utilise un compte de service géré par l'utilisateur au lieu du compte de service par défaut de Compute Engine.
Créer le compte de service géré par l'utilisateur pour l'instance de VM
Dans Cloud Shell, exécutez les commandes suivantes, en remplaçant PROJECT_ID par votre ID de projet :
projectid=PROJECT_ID gcloud config set project ${projectid}Créez un compte de service nommé
onprem-user-managed-sa:gcloud iam service-accounts create onprem-user-managed-sa \ --display-name="onprem-user-managed-sa"Attribuez le rôle Utilisateur Vertex AI (
roles/aiplatform.user) au compte de service :gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Attribuez le rôle Lecteur Vertex AI (
roles/aiplatform.viewer) :gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.viewer"Attribuez le rôle Filestore Editor (
roles/file.editor) :gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/file.editor"Attribuez le rôle Administrateur du compte de service (
roles/iam.serviceAccountAdmin) :gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/iam.serviceAccountAdmin"Attribuez le rôle Utilisateur du compte de service
roles/iam.serviceAccountUser() :gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/iam.serviceAccountUser"Attribuez le rôle Lecteur Artifact Registry (
roles/artifactregistry.reader) :gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.reader"Attribuez le rôle Administrateur des objets de l'espace de stockage
roles/storage.objectAdmin() :gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.objectAdmin"Attribuez le rôle Administrateur Logging (
roles/logging.admin) :gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/logging.admin"
Créer l'instance de VM on-prem-dataservice-host
L'instance de VM que vous créez ne possède pas d'adresse IP externe et n'autorise pas l'accès direct sur Internet. Pour activer l'accès administrateur à la VM, vous utilisez le transfert TCP d'Identity-Aware Proxy (IAP).
Dans Cloud Shell, créez l'instance de VM
on-prem-dataservice-host:gcloud compute instances create on-prem-dataservice-host \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=onprem-dataservice-vpc-subnet1 \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --shielded-secure-boot \ --service-account=onprem-user-managed-sa@$projectid.iam.gserviceaccount.com \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"Créez une règle de pare-feu pour autoriser IAP à se connecter à votre instance de VM:
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network onprem-dataservice-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
Mettre à jour le fichier /etc/hosts pour qu'il pointe vers le point de terminaison PSC
Au cours de cette étape, vous allez ajouter une ligne au fichier /etc/hosts qui entraîne la redirection des requêtes envoyées au point de terminaison du service public (us-central1-aiplatform.googleapis.com) vers le point de terminaison PSC (192.168.0.1).
Dans Cloud Shell, connectez-vous à l'instance de VM
on-prem-dataservice-hostà l'aide d'IAP:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapDans l'instance de VM
on-prem-dataservice-host, utilisez un éditeur de texte tel quevimounanopour ouvrir le fichier/etc/hosts, par exemple :sudo vim /etc/hostsAjoutez la ligne suivante au fichier :
192.168.0.1 us-central1-aiplatform.googleapis.comCette ligne attribue l'adresse IP du point de terminaison PSC (
192.168.0.1) au nom de domaine complet de l'API Google Vertex AI (us-central1-aiplatform.googleapis.com).Le fichier modifié doit se présenter comme suit :
127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 192.168.0.1 us-central1-aiplatform.googleapis.com # Added by you 172.16.10.6 on-prem-dataservice-host.us-central1-a.c.PROJECT_ID.internal on-prem-dataservice-host # Added by Google 169.254.169.254 metadata.google.internal # Added by GoogleEnregistrez le fichier comme suit :
- Si vous utilisez
vim, appuyez sur la toucheEsc, puis saisissez:wqpour enregistrer le fichier et quitter. - Si vous utilisez
nano, saisissezControl+Oet appuyez surEnterpour enregistrer le fichier, puis saisissezControl+Xpour quitter.
- Si vous utilisez
Pinguez le point de terminaison de l'API Vertex AI comme suit :
ping us-central1-aiplatform.googleapis.comLa commande
pingdoit renvoyer le résultat suivant.192.168.0.1correspond à l'adresse IP du point de terminaison PSC :PING us-central1-aiplatform.googleapis.com (192.168.0.1) 56(84) bytes of data.Saisissez
Control+Cpour quitterping.Saisissez
exitpour quitter l'instance de VMon-prem-dataservice-hostet revenir à l'invite Cloud Shell.
Configurer la mise en réseau d'une instance Filestore
Dans cette section, vous allez activer l'accès aux services privés pour votre réseau VPC, en vue de créer une instance Filestore et de l'installer en tant que partage Network File System (NFS). Pour comprendre ce que vous faites dans cette section et la suivante, consultez les pages Installer un partage NFS pour l'entraînement personnalisé et Configurer l'appairage de réseaux VPC.
Activer l'accès aux services privés sur un réseau VPC
Dans cette section, vous allez créer une connexion Service Networking et l'utiliser pour activer l'accès aux services privés au réseau VPC onprem-dataservice-vpc via l'appairage de réseaux VPC.
Dans Cloud Shell, définissez une plage d'adresses IP réservées à l'aide de
gcloud compute addresses create:gcloud compute addresses create filestore-subnet \ --global \ --purpose=VPC_PEERING \ --addresses=10.243.208.0 \ --prefix-length=24 \ --description="filestore subnet" \ --network=onprem-dataservice-vpcÉtablissez une connexion d'appairage entre le réseau VPC
onprem-dataservice-vpcet Service Networking de Google à l'aide degcloud services vpc-peerings connect:gcloud services vpc-peerings connect \ --service=servicenetworking.googleapis.com \ --ranges=filestore-subnet \ --network=onprem-dataservice-vpcMettez à jour l'appairage de réseaux VPC pour activer l'importation et l'exportation des routes apprises personnalisées :
gcloud compute networks peerings update servicenetworking-googleapis-com \ --network=onprem-dataservice-vpc \ --import-custom-routes \ --export-custom-routesDans la consoe Google Cloud, accédez à la page Appairage de réseaux VPC.
Dans la liste des appairages de VPC, vérifiez qu'il existe une entrée pour l'appairage entre
servicenetworking.googleapis.comet le réseau VPConprem-dataservice-vpc.
Créer des annonces de routage personnalisées pour filestore-subnet
Dans Google Cloud Console, accédez à la page Routeurs cloud.
Dans la liste des routeurs Cloud Router, cliquez sur
onprem-dataservice-vpc-router1.Sur la page Détails du routeur, cliquez sur Modifier.
Dans la section Routes annoncées, sélectionnez Créer des routes personnalisées pour le paramètre Routes.
Sélectionnez Diffuser tous les sous-réseaux visibles par Cloud Router pour continuer à annoncer les sous-réseaux disponibles pour le routeur cloud. Cette option imite le comportement de Cloud Router en mode d'annonce par défaut.
Cliquez sur Ajouter une route personnalisée.
Dans Source, sélectionnez Plage d'adresses IP personnalisée.
Dans le champ Plage d'adresses IP, saisissez l'adresse IP suivante :
10.243.208.0/24Dans le champ Description, saisissez le texte suivant :
Filestore reserved IP address rangeCliquez sur OK, puis sur Enregistrer.
Créer l'instance Filestore dans le réseau onprem-dataservice-vpc
Après avoir activé l'accès aux services privés pour votre réseau VPC, vous créez une instance Filestore et l'installez en tant que partage NFS pour votre job d'entraînement personnalisée. Vos jobs peuvent ainsi accéder à des fichiers distants comme s'ils étaient locaux, ce qui permet un haut débit et une latence faible.
Créez l'instance Filestore
Dans la console Google Cloud, accédez à la page Instances Filestore.
Cliquez sur Créer une instance et configurez l'instance comme suit :
Définissez le paramètre ID d'instance sur la valeur suivante :
image-data-instanceDéfinissez Type d'instance sur De base.
Définissez Type de stockage sur HDD.
Définissez l'Allocation de la capacité sur 1
TiB.Définissez la région sur us-central1 et la zone sur us-central1-a.
Définissez Réseau VPC sur
onprem-dataservice-vpc.Définissez Plage d'adresses IP allouée sur Utiliser une plage d'adresses IP allouée existante, puis sélectionnez
filestore-subnet.Définissez le nom du partage de fichiers sur :
vol1Définissez Contrôles des accès sur Accorder l'accès à tous les clients sur le réseau VPC.
Cliquez sur Créer.
Notez l'adresse IP de votre nouvelle instance Filestore. Vous devrez peut-être actualiser l'onglet du navigateur de la console Google Cloud pour afficher la nouvelle instance.
Installer le partage de fichiers Filestore
Dans Cloud Shell, exécutez les commandes suivantes, en remplaçant PROJECT_ID par votre ID de projet :
projectid=PROJECT_ID gcloud config set project ${projectid}Connectez-vous à l'instance de VM
on-prem-dataservice-host:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapInstallez le package NFS sur l'instance de VM :
sudo apt-get update -y sudo apt-get -y install nfs-commonCréez un répertoire d'installation pour le partage de fichiers Filestore :
sudo mkdir -p /mnt/nfsInstallez le partage de fichiers en remplaçant FILESTORE_INSTANCE_IP par l'adresse IP de votre instance Filestore :
sudo mount FILESTORE_INSTANCE_IP:/vol1 /mnt/nfsSi la connexion expire, assurez-vous que vous fournissez l'adresse IP correcte de l'instance Filestore.
Vérifiez que l'installation NFS a réussi en exécutant la commande suivante :
df -hVérifiez que le partage de fichiers
/mnt/nfsapparaît dans le résultat :Filesystem Size Used Avail Use% Mounted on udev 1.8G 0 1.8G 0% /dev tmpfs 368M 396K 368M 1% /run /dev/sda1 9.7G 1.9G 7.3G 21% / tmpfs 1.8G 0 1.8G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock /dev/sda15 124M 11M 114M 9% /boot/efi tmpfs 368M 0 368M 0% /run/user 10.243.208.2:/vol1 1007G 0 956G 0% /mnt/nfsRendez le partage de fichiers accessible en modifiant les autorisations :
sudo chmod go+rw /mnt/nfs
Télécharger l'ensemble de données sur le partage de fichiers
Dans l'instance de VM
on-prem-dataservice-host, téléchargez l'ensemble de données sur le partage de fichiers :gcloud storage cp gs://cloud-samples-data/vertex-ai/dataset-management/datasets/fungi_dataset /mnt/nfs/ --recursiveLe téléchargement prend plusieurs minutes.
Pour vérifier que l'ensemble de données a bien été copié, exécutez la commande suivante :
sudo du -sh /mnt/nfsLe résultat attendu est :
104M /mnt/nfsSaisissez
exitpour quitter l'instance de VMon-prem-dataservice-hostet revenir à l'invite Cloud Shell.
Créer un bucket de préproduction pour votre pipeline
Vertex AI Pipelines stocke les artefacts des exécutions de votre pipeline à l'aide de Cloud Storage. Avant d'exécuter le pipeline, vous devez créer un bucket Cloud Storage pour les exécutions de pipeline de préproduction.
Dans Cloud Shell, créez un bucket Cloud Storage.
gcloud storage buckets create gs://pipelines-staging-bucket-$projectid --location=us-central1
Créer un compte de service géré par l'utilisateur pour Vertex AI Workbench
Dans Cloud Shell, créez un compte de service à l'aide des commandes suivantes :
gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"Attribuez le rôle Utilisateur Vertex AI (
roles/aiplatform.user) au compte de service :gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Attribuez le rôle Administrateur Artifact Registry (
artifactregistry.admin) :gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.admin"Attribuez le rôle Administrateur de l'espace de stockage (
storage.admin) :gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.admin"
Créer l'application d'entraînement Python
Dans cette section, vous allez créer une instance Vertex AI Workbench et l'utiliser pour créer un package d'application d'entraînement personnalisé Python.
Créer une instance Vertex AI Workbench
Dans la console Google Cloud, accédez à l'onglet Instances sur la page Vertex AI Workbench.
Cliquez sur Créer, puis sélectionnez Options avancées.
La page Nouvelle instance s'ouvre.
Dans la section Détails de la page Nouvelle instance, fournissez les informations suivantes pour la nouvelle instance, puis cliquez sur Continuer :
Nom : saisissez le code suivant en remplaçant PROJECT_ID par l'ID du projet :
pipeline-tutorial-PROJECT_IDRégion : sélectionnez us-central1.
Zone : sélectionnez us-central1-a.
Décochez la case Activer les sessions interactives de Dataproc sans serveur.
Dans la section Environnement, cliquez sur Continuer.
Dans la section Type de machine, fournissez les informations suivantes, puis cliquez sur Continuer :
- Type de machine : sélectionnez N1, puis
n1-standard-4dans le menu Type de machine. VM protégée : cochez les cases suivantes :
- Démarrage sécurisé
- Module vTPM (Virtual Trusted Platform Module)
- Surveillance de l'intégrité
- Type de machine : sélectionnez N1, puis
Dans la section Disques, assurez-vous que l'option Clé de chiffrement gérée par Google est sélectionnée, puis cliquez sur Continuer :
Dans la section Mise en réseau, fournissez les informations suivantes, puis cliquez sur Continuer :
Mise en réseau : sélectionnez Réseau dans ce projet et procédez comme suit :
Dans le champ Réseau, sélectionnez vertex-networking-vpc.
Dans le champ Sous-réseau, sélectionnez pipeline-networking-subnet1.
Décochez la case Attribuer une adresse IP externe. Le fait de ne pas attribuer d'adresse IP externe empêche l'instance de recevoir des communications non sollicitées en provenance d'Internet ou d'autres réseaux VPC.
Cochez la case Autoriser l'accès proxy.
Dans la section IAM et sécurité, spécifiez les éléments suivants, puis cliquez sur Continuer :
IAM et sécurité : pour accorder à un seul utilisateur l'accès à l'interface JupyterLab de l'instance, procédez comme suit :
- Sélectionnez Service Account (Compte de service).
- Décochez la case Utiliser le compte de service Compute Engine par défaut.
Cette étape est importante, car le compte de service Compute Engine par défaut (et donc l'utilisateur que vous venez de spécifier) peut disposer du rôle Éditeur (
roles/editor) sur votre projet. Dans le champ Adresse e-mail du compte de service, saisissez l'adresse suivante en remplaçant PROJECT_ID par l'ID de projet :
workbench-sa@PROJECT_ID.iam.gserviceaccount.com(Il s'agit de l'adresse e-mail du compte de service personnalisé que vous avez créé précédemment.) Ce compte de service dispose d'autorisations limitées.
Pour en savoir plus sur l'attribution d'autorisations d'accès, consultez la section Gérer l'accès à l'interface JupyterLab d'une instance Vertex AI Workbench.
Options de sécurité : décochez la case suivante :
- Accès root à l'instance
Cochez la case suivante :
- nbconvert :
nbconvertpermet aux utilisateurs d'exporter et de télécharger un fichier notebook sous un type de fichier différent, tel que HTML, PDF ou LaTeX. Ce paramètre est requis par certains notebooks du dépôt GitHub Google Cloud Generative AI.
Décochez la case suivante :
- Téléchargement de fichiers
Cochez la case suivante, sauf si vous êtes dans un environnement de production :
- Accès au terminal : cette option permet d'accéder au terminal de votre instance à partir de l'interface utilisateur de JupyterLab.
Dans la section État du système, supprimez l'option Mise à niveau automatique de l'environnement et fournissez les informations suivantes :
Dans Création de rapports, cochez les cases suivantes :
- Rendez compte de l'état du système
- Transmettre des métriques personnalisées à Cloud Monitoring
- Installer Cloud Monitoring
- Signaler l'état DNS des domaines Google requis
Cliquez sur Créer et attendez quelques minutes que l'instance Vertex AI Workbench soit créée.
Exécuter l'application d'entraînement dans l'instance Vertex AI Workbench
Dans la console Google Cloud, accédez à l'onglet Instances sur la page Vertex AI Workbench.
À côté du nom de votre instance Vertex AI Workbench (
pipeline-tutorial-PROJECT_ID), où PROJECT_ID est l'ID de projet, cliquez sur Ouvrir JupyterLab.Votre instance Vertex AI Workbench ouvre JupyterLab.
Sélectionnez Fichier > Nouveau > Terminal.
Dans le terminal JupyterLab (et non dans Cloud Shell), définissez une variable d'environnement pour votre projet. en remplaçant PROJECT_ID par votre ID de projet :
projectid=PROJECT_IDCréez les répertoires parents de l'application d'entraînement (toujours dans le terminal JupyterLab) :
mkdir fungi_training_package mkdir fungi_training_package/trainerDans l'explorateur de fichiers , double-cliquez sur le dossier
fungi_training_package, puis sur le dossiertrainer.Dans l'explorateur de fichiers , effectuez un clic droit sur la liste de fichiers vide (sous l'en-tête Nom), puis sélectionnez Nouveau fichier.
Effectuez un clic droit sur le nouveau fichier, puis sélectionnez Renommer le fichier.
Renommez le fichier
untitled.txtentask.py.Double-cliquez sur le fichier
task.pypour l'ouvrir.Copiez le code suivant dans
task.py:# Import the libraries import tensorflow as tf from tensorflow.python.client import device_lib import argparse import os import sys # add parser arguments parser = argparse.ArgumentParser() parser.add_argument('--data-dir', dest='dataset_dir', type=str, help='Dir to access dataset.') parser.add_argument('--model-dir', dest='model_dir', default=os.getenv("AIP_MODEL_DIR"), type=str, help='Dir to save the model.') parser.add_argument('--epochs', dest='epochs', default=10, type=int, help='Number of epochs.') parser.add_argument('--batch-size', dest='batch_size', default=32, type=int, help='Number of images per batch.') parser.add_argument('--distribute', dest='distribute', default='single', type=str, help='distributed training strategy.') args = parser.parse_args() # print the tf version and config print('Python Version = {}'.format(sys.version)) print('TensorFlow Version = {}'.format(tf.__version__)) print('TF_CONFIG = {}'.format(os.environ.get('TF_CONFIG', 'Not found'))) print('DEVICES', device_lib.list_local_devices()) # Single Machine, single compute device if args.distribute == 'single': if tf.test.is_gpu_available(): strategy = tf.distribute.OneDeviceStrategy(device="/gpu:0") else: strategy = tf.distribute.OneDeviceStrategy(device="/cpu:0") # Single Machine, multiple compute device elif args.distribute == 'mirror': strategy = tf.distribute.MirroredStrategy() # Multiple Machine, multiple compute device elif args.distribute == 'multi': strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy() # Multi-worker configuration print('num_replicas_in_sync = {}'.format(strategy.num_replicas_in_sync)) # Preparing dataset BUFFER_SIZE = 1000 IMG_HEIGHT = 224 IMG_WIDTH = 224 def make_datasets_batched(dataset_path, global_batch_size): # Configure the training data generator train_data_dir = os.path.join(dataset_path,"train/") train_ds = tf.keras.utils.image_dataset_from_directory( train_data_dir, seed=36, image_size=(IMG_HEIGHT, IMG_WIDTH), batch_size=global_batch_size ) # Configure the validation data generator val_data_dir = os.path.join(dataset_path,"valid/") val_ds = tf.keras.utils.image_dataset_from_directory( val_data_dir, seed=36, image_size=(IMG_HEIGHT, IMG_WIDTH), batch_size=global_batch_size ) # get the number of classes in the data num_classes = len(train_ds.class_names) # Configure the dataset for performance AUTOTUNE = tf.data.AUTOTUNE train_ds = train_ds.cache().shuffle(BUFFER_SIZE).prefetch(buffer_size=AUTOTUNE) val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE) return train_ds, val_ds, num_classes # Build the Keras model def build_and_compile_cnn_model(num_classes): # build a CNN model model = tf.keras.models.Sequential([ tf.keras.layers.Rescaling(1./255, input_shape=(IMG_HEIGHT, IMG_WIDTH, 3)), tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(num_classes) ]) # compile the CNN model model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) return model # Get the strategy data NUM_WORKERS = strategy.num_replicas_in_sync # Here the batch size scales up by number of workers GLOBAL_BATCH_SIZE = args.batch_size * NUM_WORKERS # Create dataset generator objects train_ds, val_ds, num_classes = make_datasets_batched(args.dataset_dir, GLOBAL_BATCH_SIZE) # Compile the model with strategy.scope(): # Creation of dataset, and model building/compiling need to be within # `strategy.scope()`. model = build_and_compile_cnn_model(num_classes) # fit the model on the data history = model.fit(train_ds, validation_data=val_ds, epochs=args.epochs) # save the model to the output dir model.save(args.model_dir)Sélectionnez Fichier > Enregistrer le fichier Python.
Dans le terminal JupyterLab, créez un fichier
__init__.pydans chaque sous-répertoire pour en faire un package :touch fungi_training_package/__init__.py touch fungi_training_package/trainer/__init__.pyDans l'explorateur de fichiers , double-cliquez sur le nouveau dossier
fungi_training_package.Sélectionnez Fichier > Nouveau > Fichier Python.
Effectuez un clic droit sur le nouveau fichier, puis sélectionnez Renommer le fichier.
Renommez le fichier
untitled.pyensetup.py.Double-cliquez sur le fichier
setup.pypour l'ouvrir.Copiez le code suivant dans
setup.py:from setuptools import find_packages from setuptools import setup setup( name='trainer', version='0.1', packages=find_packages(), include_package_data=True, description='Training application package for fungi-classification.' )Sélectionnez Fichier > Enregistrer le fichier Python.
Dans le terminal, accédez au répertoire
fungi_training_package:cd fungi_training_packageExécutez la commande
sdistpour créer la distribution source de l'application d'entraînement:python setup.py sdist --formats=gztarAccédez au répertoire parent :
cd ..Vérifiez que vous êtes dans le bon répertoire :
pwdLe résultat ressemble à ceci :
/home/jupyterCopiez le package Python dans le bucket de préproduction:
gcloud storage cp fungi_training_package/dist/trainer-0.1.tar.gz gs://pipelines-staging-bucket-$projectid/training_package/Vérifiez que le bucket de préproduction contient le package :
gcloud storage ls gs://pipelines-staging-bucket-$projectid/training_packageVoici le résultat :
gs://pipelines-staging-bucket-PROJECT_ID/training_package/trainer-0.1.tar.gz
Créer la connexion Service Networking pour Vertex AI Pipelines
Dans cette section, vous allez créer une connexion Service Networking qui permet d'établir des services producteurs connectés au réseau VPC vertex-networking-vpc via l'appairage de réseaux VPC. Pour en savoir plus, consultez la section Appairage de réseaux VPC.
Dans Cloud Shell, exécutez les commandes suivantes, en remplaçant PROJECT_ID par votre ID de projet :
projectid=PROJECT_ID gcloud config set project ${projectid}Définissez une plage d'adresses IP réservées à l'aide de
gcloud compute addresses create:gcloud compute addresses create vertex-pipeline-subnet \ --global \ --purpose=VPC_PEERING \ --addresses=192.168.10.0 \ --prefix-length=24 \ --description="pipeline subnet" \ --network=vertex-networking-vpcÉtablissez une connexion d'appairage entre le réseau VPC
vertex-networking-vpcet Service Networking de Google à l'aide degcloud services vpc-peerings connect:gcloud services vpc-peerings connect \ --service=servicenetworking.googleapis.com \ --ranges=vertex-pipeline-subnet \ --network=vertex-networking-vpcMettez à jour la connexion d'appairage de VPC pour activer l'importation et l'exportation des routes apprises personnalisées :
gcloud compute networks peerings update servicenetworking-googleapis-com \ --network=vertex-networking-vpc \ --import-custom-routes \ --export-custom-routes
Annoncer le sous-réseau de pipeline à partir du routeur Cloud Router pipeline-networking
Dans la console Google Cloud, accédez à la page Cloud Router.
Dans la liste des routeurs Cloud Router, cliquez sur
vertex-networking-vpc-router1.Sur la page Détails du routeur, cliquez sur Modifier.
Cliquez sur Ajouter une route personnalisée.
Dans Source, sélectionnez Plage d'adresses IP personnalisée.
Dans le champ Plage d'adresses IP, saisissez l'adresse IP suivante :
192.168.10.0/24Dans le champ Description, saisissez le texte suivant :
Vertex AI Pipelines reserved subnetCliquez sur OK, puis sur Enregistrer.
Créer un modèle de pipeline et l'importer dans Artifact Registry
Dans cette section, vous allez créer et importer un modèle de pipeline Kubeflow Pipelines (KFP). Ce modèle contient une définition de workflow qui peut être réutilisée plusieurs fois, par un seul utilisateur ou par plusieurs utilisateurs.
Définir et compiler le pipeline
Dans JupyterLab, dans l'explorateur de fichiers , double-cliquez sur le dossier de premier niveau.
Sélectionnez Fichier > Nouveau > Notebook.
Dans le menu Sélectionner le kernel, sélectionnez
Python 3 (ipykernel), puis cliquez sur Sélectionner.Dans une nouvelle cellule de notebook, exécutez la commande suivante pour vous assurer que vous disposez de la dernière version de
pip:!python -m pip install --upgrade pipExécutez la commande suivante pour installer le SDK des composants du pipeline Google Cloud à partir de l'index de packages Python (PyPI) :
!pip install --upgrade google-cloud-pipeline-componentsUne fois l'installation terminée, sélectionnez Kernel > Redémarrer le kernel pour redémarrer le kernel et vous assurer que la bibliothèque est disponible pour l'importation.
Exécutez le code suivant dans une nouvelle cellule de notebook pour définir le pipeline :
from kfp import dsl # define the train-deploy pipeline @dsl.pipeline(name="custom-image-classification-pipeline") def custom_image_classification_pipeline( project: str, training_job_display_name: str, worker_pool_specs: list, base_output_dir: str, model_artifact_uri: str, prediction_container_uri: str, model_display_name: str, endpoint_display_name: str, network: str = '', location: str="us-central1", serving_machine_type: str="n1-standard-4", serving_min_replica_count: int=1, serving_max_replica_count: int=1 ): from google_cloud_pipeline_components.types import artifact_types from google_cloud_pipeline_components.v1.custom_job import CustomTrainingJobOp from google_cloud_pipeline_components.v1.model import ModelUploadOp from google_cloud_pipeline_components.v1.endpoint import (EndpointCreateOp, ModelDeployOp) from kfp.dsl import importer # Train the model task custom_job_task = CustomTrainingJobOp( project=project, display_name=training_job_display_name, worker_pool_specs=worker_pool_specs, base_output_directory=base_output_dir, location=location, network=network ) # Import the model task import_unmanaged_model_task = importer( artifact_uri=model_artifact_uri, artifact_class=artifact_types.UnmanagedContainerModel, metadata={ "containerSpec": { "imageUri": prediction_container_uri, }, }, ).after(custom_job_task) # Model upload task model_upload_op = ModelUploadOp( project=project, display_name=model_display_name, unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"], ) model_upload_op.after(import_unmanaged_model_task) # Create Endpoint task endpoint_create_op = EndpointCreateOp( project=project, display_name=endpoint_display_name, ) # Deploy the model to the endpoint ModelDeployOp( endpoint=endpoint_create_op.outputs["endpoint"], model=model_upload_op.outputs["model"], dedicated_resources_machine_type=serving_machine_type, dedicated_resources_min_replica_count=serving_min_replica_count, dedicated_resources_max_replica_count=serving_max_replica_count, )Exécutez le code suivant dans une nouvelle cellule de notebook pour compiler la définition du pipeline :
from kfp import compiler PIPELINE_FILE = "pipeline_config.yaml" compiler.Compiler().compile( pipeline_func=custom_image_classification_pipeline, package_path=PIPELINE_FILE, )Dans l'explorateur de fichiers , un fichier nommé
pipeline_config.yamlapparaît dans la liste des fichiers.
Créer un dépôt Artifact Registry
Exécutez le code suivant dans une nouvelle cellule de notebook pour créer un dépôt d'artefacts de type KFP :
REPO_NAME="fungi-repo" REGION="us-central1" !gcloud artifacts repositories create $REPO_NAME --location=$REGION --repository-format=KFP
Importer le modèle de pipeline dans Artifact Registry
Dans cette section, vous allez configurer un client de registre du SDK Kubeflow Pipelines et importer votre modèle de pipeline compilé dans Artifact Registry à partir de votre notebook JupyterLab.
Dans votre notebook JupyterLab, exécutez le code suivant pour importer le modèle de pipeline, en remplaçant PROJECT_ID par l'ID de votre projet :
PROJECT_ID = "PROJECT_ID" from kfp.registry import RegistryClient host = f"https://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}" client = RegistryClient(host=host) TEMPLATE_NAME, VERSION_NAME = client.upload_pipeline( file_name=PIPELINE_FILE, tags=["v1", "latest"], extra_headers={"description":"This is an example pipeline template."})Dans la console Google Cloud, pour vérifier que votre modèle a bien été importé, accédez à Modèles Vertex AI Pipelines.
Pour ouvrir le volet Sélectionner un dépôt, cliquez sur Sélectionner un dépôt.
Dans la liste des dépôts, cliquez sur le dépôt que vous avez créé (
fungi-repo), puis sur Sélectionner.Vérifiez que votre pipeline (
custom-image-classification-pipeline) apparaît dans la liste.
Déclencher une exécution de pipeline sur site
Dans cette section, maintenant que votre modèle de pipeline et votre package d'entraînement sont prêts, vous allez utiliser cURL pour déclencher une exécution de pipeline à partir de votre application sur site.
Fournir les paramètres du pipeline
Dans votre notebook JupyterLab, exécutez la commande suivante pour vérifier le nom du modèle de pipeline :
print (TEMPLATE_NAME)Le nom du modèle renvoyé est le suivant :
custom-image-classification-pipelineExécutez la commande suivante pour obtenir la version du modèle de pipeline :
print (VERSION_NAME)Le nom de la version du modèle de pipeline renvoyé se présente comme suit :
sha256:41eea21e0d890460b6e6333c8070d7d23d314afd9c7314c165efd41cddff86c7Notez la chaîne de nom de version complète.
Dans Cloud Shell, exécutez les commandes suivantes, en remplaçant PROJECT_ID par votre ID de projet :
projectid=PROJECT_ID gcloud config set project ${projectid}Connectez-vous à l'instance de VM
on-prem-dataservice-host:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapDans l'instance de VM
on-prem-dataservice-host, utilisez un éditeur de texte tel quevimounanopour créer le fichierrequest_body.json, par exemple :sudo vim request_body.jsonAjoutez le texte suivant au fichier
request_body.json:{ "displayName": "fungi-image-pipeline-job", "serviceAccount": "onprem-user-managed-sa@PROJECT_ID.iam.gserviceaccount.com", "runtimeConfig":{ "gcsOutputDirectory":"gs://pipelines-staging-bucket-PROJECT_ID/pipeline_root/", "parameterValues": { "project": "PROJECT_ID", "training_job_display_name": "fungi-image-training-job", "worker_pool_specs": [{ "machine_spec": { "machine_type": "n1-standard-4" }, "replica_count": 1, "python_package_spec":{ "executor_image_uri":"us-docker.pkg.dev/vertex-ai/training/tf-cpu.2-8.py310:latest", "package_uris": ["gs://pipelines-staging-bucket-PROJECT_ID/training_package/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args": ["--data-dir","/mnt/nfs/fungi_dataset/", "--epochs", "10"], "env": [{"name": "AIP_MODEL_DIR", "value": "gs://pipelines-staging-bucket-PROJECT_ID/model/"}] }, "nfs_mounts": [{ "server": "FILESTORE_INSTANCE_IP", "path": "/vol1", "mount_point": "/mnt/nfs/" }] }], "base_output_dir":"gs://pipelines-staging-bucket-PROJECT_ID", "model_artifact_uri":"gs://pipelines-staging-bucket-PROJECT_ID/model/", "prediction_container_uri":"us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest", "model_display_name":"fungi-image-model", "endpoint_display_name":"fungi-image-endpoint", "location": "us-central1", "serving_machine_type":"n1-standard-4", "network":"projects/PROJECT_NUMBER/global/networks/vertex-networking-vpc" } }, "templateUri": "https://us-central1-kfp.pkg.dev/PROJECT_ID/fungi-repo/custom-image-classification-pipeline/latest", "templateMetadata": { "version":"VERSION_NAME" } }Remplacez les valeurs suivantes :
- PROJECT_ID : ID de votre projet.
- PROJECT_NUMBER : Numéro du projet Cette valeur est différente de l'ID du projet. Vous pouvez trouver le numéro de projet sur la page Paramètres du projet du projet dans la console Google Cloud.
- FILESTORE_INSTANCE_IP : adresse IP de l'instance Filestore, par exemple
10.243.208.2. Vous pouvez la trouver sur la page "Instances Filestore" de votre instance. - VERSION_NAME : nom de la version du modèle de pipeline (
sha256:...) que vous avez noté à l'étape 2.
Enregistrez le fichier comme suit :
- Si vous utilisez
vim, appuyez sur la toucheEsc, puis saisissez:wqpour enregistrer le fichier et quitter. - Si vous utilisez
nano, saisissezControl+Oet appuyez surEnterpour enregistrer le fichier, puis saisissezControl+Xpour quitter.
- Si vous utilisez
Créer une exécution de pipeline à partir de votre modèle
Dans l'instance de VM
on-prem-dataservice-host, exécutez la commande suivante en remplaçant PROJECT_ID par l'ID de votre projet :curl -v -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ -d @request_body.json \ https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/pipelineJobsLa sortie est longue, mais l'élément principal à rechercher est la ligne suivante, qui indique que le service se prépare à exécuter le pipeline :
"state": "PIPELINE_STATE_PENDING"L'exécution complète du pipeline prend environ 45 à 50 minutes.
Dans la section Vertex AI de la console Google Cloud, accédez à l'onglet Exécutions de la page Pipelines.
Cliquez sur le nom de l'exécution de votre pipeline (
custom-image-classification-pipeline).La page d'exécution du pipeline apparaît et affiche le graphique d'exécution du pipeline. Le résumé du pipeline s'affiche dans le volet Analyse de l'exécution du pipeline.
Pour comprendre les informations affichées dans le graphique d'exécution, y compris comment afficher les journaux et utiliser Vertex ML Metadata pour en savoir plus sur les artefacts de votre pipeline, consultez Visualiser et analyser les résultats du pipeline.
Effectuer un nettoyage
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez chaque ressource individuellement.
Vous pouvez supprimer les ressources individuelles du projet comme suit :
Supprimez toutes les exécutions de pipeline comme suit :
Dans la section Vertex AI de la console Google Cloud, accédez à l'onglet Exécutions de la page Pipelines.
Sélectionnez les exécutions de pipeline à supprimer, puis cliquez sur Supprimer.
Supprimez le modèle de pipeline comme suit :
Dans la section Vertex AI, accédez à l'onglet Vos modèles de la page Pipelines.
À côté du modèle de pipeline
custom-image-classification-pipeline, cliquez sur Actions, puis sélectionnez Supprimer.
Supprimez le dépôt d'Artifact Registry comme suit :
Sur la page Artifact Registry, accédez à l'onglet Dépôts.
Sélectionnez le dépôt
fungi-repo, puis cliquez sur Supprimer.
Annulez le déploiement du modèle sur le point de terminaison comme suit :
Dans la section Vertex AI, accédez à l'onglet Points de terminaison de la page Prédictions en ligne.
Cliquez sur
fungi-image-endpointpour accéder à la page d'informations du point de terminaison.Sur la ligne correspondant à votre modèle,
fungi-image-model, cliquez sur Actions, puis sélectionnez Annuler le déploiement du modèle sur le point de terminaison.Dans la boîte de dialogue Annuler le déploiement du modèle sur le point de terminaison, cliquez sur Annuler le déploiement.
Supprimez le point de terminaison comme suit :
Dans la section Vertex AI, accédez à l'onglet Points de terminaison de la page Prédictions en ligne.
Sélectionnez
fungi-image-endpoint, puis cliquez sur Supprimer.
Supprimez le modèle comme suit :
Accédez à la page Registre de modèles.
Sur la ligne de votre modèle,
fungi-image-model, cliquez sur Actions, puis sélectionnez Supprimer le modèle.
Supprimez le bucket d'aiguillage comme suit :
Accédez à la page Cloud Storage.
Sélectionnez
pipelines-staging-bucket-PROJECT_ID, où PROJECT_ID est l'ID du projet, puis cliquez sur Supprimer.
Supprimez l'instance Vertex AI Workbench comme suit:
Dans la section Vertex AI, accédez à l'onglet Instances de la page Workbench.
Sélectionnez l'instance Vertex AI Workbench
pipeline-tutorial-PROJECT_ID, où PROJECT_ID est l'ID du projet, puis cliquez sur Supprimer.
Supprimez l'instance de VM Compute Engine comme suit:
Accédez à la page Compute Engine.
Sélectionnez l'instance de VM
on-prem-dataservice-host, puis cliquez sur Supprimer.
Supprimez les tunnels VPN comme suit:
Accédez à la page VPN.
Sur la page VPN, cliquez sur l'onglet Tunnels Cloud VPN.
Dans la liste des tunnels VPN, sélectionnez les quatre tunnels VPN que vous avez créés dans ce tutoriel, puis cliquez sur Supprimer.
Supprimez les passerelles VPN haute disponibilité comme suit:
Sur la page VPN, cliquez sur l'onglet Passerelles Cloud VPN.
Dans la liste des passerelles VPN, cliquez sur
onprem-vpn-gw1.Sur la page Informations sur la passerelle Cloud VPN, cliquez sur Supprimer la passerelle VPN.
Si nécessaire, cliquez sur la flèche de retour pour revenir à la liste des passerelles VPN, puis cliquez sur
vertex-networking-vpn-gw1.Sur la page Informations sur la passerelle Cloud VPN, cliquez sur Supprimer la passerelle VPN.
Supprimez les routeurs cloud comme suit:
Accédez à la page Routeurs cloud.
Dans la liste des routeurs cloud, sélectionnez les quatre routeurs que vous avez créés dans ce tutoriel.
Pour supprimer les routeurs, cliquez sur Supprimer.
Cela supprimera également les deux passerelles Cloud NAT connectées aux routeurs Cloud.
Supprimez les connexions de Service Networking aux réseaux VPC
vertex-networking-vpcetonprem-dataservice-vpccomme suit :Accédez à la page Appairage de réseaux VPC.
Sélectionnez
servicenetworking-googleapis-com.Pour supprimer les connexions, cliquez sur Supprimer.
Supprimez la règle de transfert
pscvertexpour le réseau VPCvertex-networking-vpccomme suit:Accédez à l'onglet Interfaces de la page Équilibrage de charge.
Dans la liste des règles de transfert, cliquez sur
pscvertex.Sur la page Détails de la règle de transfert globale, cliquez sur Supprimer.
Supprimez l'instance Filestore comme suit :
Accédez à la page Filestore.
Sélectionnez l'instance
image-data-instance.Pour supprimer l'instance, cliquez sur Actions, puis sur Supprimer l'instance.
Supprimez les réseaux VPC comme suit:
Accédez à la page des réseaux VPC.
Dans la liste des réseaux VPC, cliquez sur
onprem-dataservice-vpc.Sur la page Détails du réseau VPC, cliquez sur Supprimer le réseau VPC.
Lorsque vous supprimez un réseau, ses sous-réseaux, ses routes et ses règles de pare-feu sont également supprimés.
Dans la liste des réseaux VPC, cliquez sur
vertex-networking-vpc.Sur la page Détails du réseau VPC, cliquez sur Supprimer le réseau VPC.
Supprimez les comptes de service
workbench-saetonprem-user-managed-sacomme suit:Accédez à la page Comptes de service.
Sélectionnez les comptes de service
onprem-user-managed-saetworkbench-sa, puis cliquez sur Supprimer.
Étape suivante
Découvrez comment utiliser Vertex AI Pipelines pour orchestrer le processus de création et de déploiement de vos modèles de machine learning.
Apprenez-en plus sur l'ensemble de données deFungi.