本地主机可以通过两种方式访问 Vertex AI Online Prediction 端点:公共互联网,或是通过 Cloud VPN 或 Cloud Interconnect 使用 Private Service Connect (PSC) 的混合网络架构(以私密方式访问)。这两个选项都提供 SSL/TLS 加密。但是,专用选项可提供更好的性能,因此建议用于关键应用。
在本教程中,您将使用高可用性 VPN 通过 Cloud NAT 公开访问在线预测端点,在可用作多云端和本地专用连接基础的两个虚拟私有云网络之间以非公开方式访问在线预测端点。
本教程适用于熟悉 Vertex AI、Virtual Private Cloud (VPC)、Google Cloud 控制台和 Cloud Shell 的企业网络管理员、数据科学家和研究人员。熟悉 Vertex AI Workbench 会很有帮助,但不强制要求。
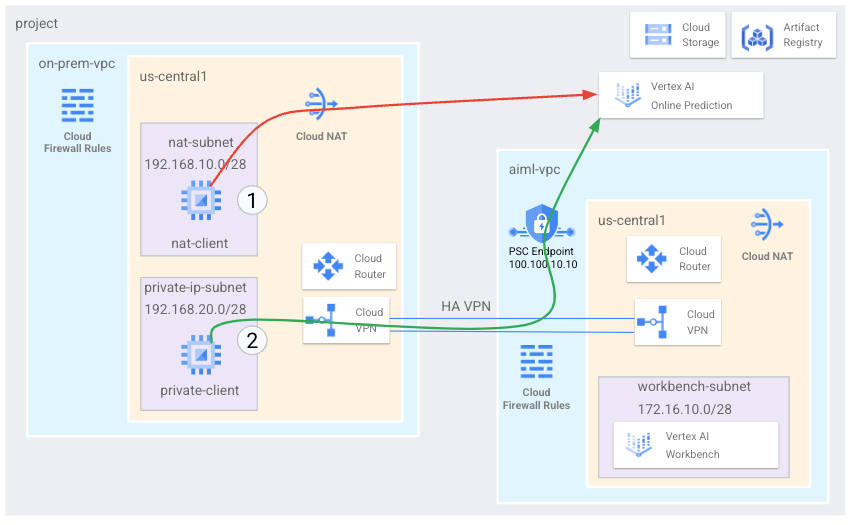
目标
- 创建两个虚拟私有云 (VPC) 网络,如上图所示:
- 一个 (
on-prem-vpc) 表示一个本地网络。 - 另一个 (
aiml-vpc) 用于构建和部署 Vertex AI Online Prediction 模型。
- 一个 (
- 部署高可用性 VPN 网关、Cloud VPN 隧道和 Cloud Router 路由器,以连接
aiml-vpc和on-prem-vpc。 - 构建和部署 Vertex AI Online Prediction 模型。
- 创建 Private Service Connect (PSC) 端点,将专用在线预测请求转发到已部署的模型。
- 在
aiml-vpc中启用 Cloud Router 路由器自定义通告模式,以向on-prem-vpc通告 Private Service Connect 端点的路由。 - 在
on-prem-vpc中创建两个 Compute Engine 虚拟机实例来表示客户端应用:- 一个 (
nat-client) 通过公共互联网发送在线预测请求(通过 Cloud NAT)。此访问方法由图中的红色箭头和数字 1 表示。 - 另一个 (
private-client) 通过高可用性 VPN 以非公开方式发送预测请求。此访问方法由绿色箭头和数字 2 表示。
- 一个 (
费用
在本文档中,您将使用 Google Cloud 的以下收费组件:
您可使用价格计算器根据您的预计使用情况来估算费用。
完成本文档中描述的任务后,您可以通过删除所创建的资源来避免继续计费。如需了解详情,请参阅清理。
准备工作
-
In the Google Cloud console, go to the project selector page.
-
Select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- 打开 Cloud Shell 以执行本教程中列出的命令。Cloud Shell 是 Google Cloud 的交互式 Shell 环境,可让您通过网络浏览器管理项目和资源。
- 在 Cloud Shell 中,将当前项目设置为您的 Google Cloud 项目 ID,并将同一项目 ID 存储在
projectidshell 变量中:projectid="PROJECT_ID" gcloud config set project ${projectid} -
Grant roles to your user account. Run the following command once for each of the following IAM roles:
roles/appengine.appViewer, roles/artifactregistry.admin, roles/compute.instanceAdmin.v1, roles/compute.networkAdmin, roles/compute.securityAdmin, roles/dns.admin, roles/iap.admin, roles/iap.tunnelResourceAccessor, roles/notebooks.admin, roles/oauthconfig.editor, roles/resourcemanager.projectIamAdmin, roles/servicemanagement.quotaAdmin, roles/iam.serviceAccountAdmin, roles/iam.serviceAccountUser, roles/servicedirectory.editor, roles/storage.admin, roles/aiplatform.usergcloud projects add-iam-policy-binding PROJECT_ID --member="user:USER_IDENTIFIER" --role=ROLE
- Replace
PROJECT_IDwith your project ID. -
Replace
USER_IDENTIFIERwith the identifier for your user account. For example,user:myemail@example.com. - Replace
ROLEwith each individual role.
- Replace
-
Enable the DNS, Artifact Registry, IAM, Compute Engine, Notebooks, and Vertex AI APIs:
gcloud services enable dns.googleapis.com
artifactregistry.googleapis.com iam.googleapis.com compute.googleapis.com notebooks.googleapis.com aiplatform.googleapis.com
创建 VPC 网络
在本部分中,您将创建两个 VPC 网络:一个用于创建在线预测模型并将其部署到端点,另一个用于对该端点进行专用访问。在两个 VPC 网络中,您都需要创建一个 Cloud Router 路由器和 Cloud NAT 网关。Cloud NAT 网关为没有外部 IP 地址的 Compute Engine 虚拟机实例提供传出连接。
为在线预测端点创建 VPC 网络 (aiml-vpc)
创建 VPC 网络:
gcloud compute networks create aiml-vpc \ --project=$projectid \ --subnet-mode=custom创建一个名为
workbench-subnet的子网,其主要 IPv4 范围为172.16.10.0/28:gcloud compute networks subnets create workbench-subnet \ --project=$projectid \ --range=172.16.10.0/28 \ --network=aiml-vpc \ --region=us-central1 \ --enable-private-ip-google-access创建名为
cloud-router-us-central1-aiml-nat的区域级 Cloud Router 路由器:gcloud compute routers create cloud-router-us-central1-aiml-nat \ --network aiml-vpc \ --region us-central1将 Cloud NAT 网关添加到 Cloud Router 路由器:
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-aiml-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1
创建“本地”VPC 网络 (on-prem-vpc)
创建 VPC 网络:
gcloud compute networks create on-prem-vpc \ --project=$projectid \ --subnet-mode=custom创建一个名为
nat-subnet的子网,其主要 IPv4 范围为192.168.10.0/28:gcloud compute networks subnets create nat-subnet \ --project=$projectid \ --range=192.168.10.0/28 \ --network=on-prem-vpc \ --region=us-central1创建一个名为
private-ip-subnet的子网,其主要 IPv4 范围为192.168.20.0/28:gcloud compute networks subnets create private-ip-subnet \ --project=$projectid \ --range=192.168.20.0/28 \ --network=on-prem-vpc \ --region=us-central1创建名为
cloud-router-us-central1-on-prem-nat的区域级 Cloud Router 路由器:gcloud compute routers create cloud-router-us-central1-on-prem-nat \ --network on-prem-vpc \ --region us-central1将 Cloud NAT 网关添加到 Cloud Router 路由器:
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-on-prem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1
创建 Private Service Connect (PSC) 端点
在本部分中,您将创建 Private Service Connect (PSC) 端点,供 on-prem-vpc 网络中的虚拟机实例用于通过 Vertex AI API 访问在线预测端点。Private Service Connect (PSC) 端点是 on-prem-vpc 网络中的内部 IP 地址,该网络中的客户端可以直接访问该地址。此端点的创建方式是部署一条转发规则,用于将与 PSC 端点的 IP 地址匹配的网络流量定向到一组 Google API。PSC 端点的 IP 地址 (100.100.10.10) 将在后面的步骤中作为自定义通告路由从 aiml-cr-us-central1 Cloud Router 路由器通告给 on-prem-vpc 网络。
为 PSC 端点预留 IP 地址:
gcloud compute addresses create psc-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=100.100.10.10 \ --network=aiml-vpc创建 PSC 端点:
gcloud compute forwarding-rules create pscvertex \ --global \ --network=aiml-vpc \ --address=psc-ip \ --target-google-apis-bundle=all-apis列出已配置的 PSC 端点并验证是否已创建
pscvertex端点:gcloud compute forwarding-rules list \ --filter target="(all-apis OR vpc-sc)" --global获取已配置的 PSC 端点的详细信息,并验证 IP 地址是否为
100.100.10.10:gcloud compute forwarding-rules describe pscvertex \ --global
配置混合连接
在本部分中,您将创建两个相互连接的(高可用性 VPN)网关。每个网关包含一个 Cloud Router 路由器和一对 VPN 隧道。
为
aiml-vpcVPC 网络创建高可用性 VPN 网关:gcloud compute vpn-gateways create aiml-vpn-gw \ --network=aiml-vpc \ --region=us-central1为
on-prem-vpcVPC 网络创建高可用性 VPN 网关:gcloud compute vpn-gateways create on-prem-vpn-gw \ --network=on-prem-vpc \ --region=us-central1在 Google Cloud 控制台中,转到 VPN 页面。
在 VPN 页面上,点击 Cloud VPN 网关标签页。
在 VPN 网关列表中,验证是否有两个网关,并且每个网关有两个 IP 地址。
在 Cloud Shell 中,为
aiml-vpc虚拟私有云网络创建一个 Cloud Router 路由器:gcloud compute routers create aiml-cr-us-central1 \ --region=us-central1 \ --network=aiml-vpc \ --asn=65001为
on-prem-vpc虚拟私有云网络创建一个 Cloud Router 路由器:gcloud compute routers create on-prem-cr-us-central1 \ --region=us-central1 \ --network=on-prem-vpc \ --asn=65002
为 aiml-vpc 创建 VPN 隧道
创建一个名为
aiml-vpc-tunnel0的 VPN 隧道:gcloud compute vpn-tunnels create aiml-vpc-tunnel0 \ --peer-gcp-gateway on-prem-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router aiml-cr-us-central1 \ --vpn-gateway aiml-vpn-gw \ --interface 0创建一个名为
aiml-vpc-tunnel1的 VPN 隧道:gcloud compute vpn-tunnels create aiml-vpc-tunnel1 \ --peer-gcp-gateway on-prem-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router aiml-cr-us-central1 \ --vpn-gateway aiml-vpn-gw \ --interface 1
为 on-prem-vpc 创建 VPN 隧道
创建一个名为
on-prem-vpc-tunnel0的 VPN 隧道:gcloud compute vpn-tunnels create on-prem-tunnel0 \ --peer-gcp-gateway aiml-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router on-prem-cr-us-central1 \ --vpn-gateway on-prem-vpn-gw \ --interface 0创建一个名为
on-prem-vpc-tunnel1的 VPN 隧道:gcloud compute vpn-tunnels create on-prem-tunnel1 \ --peer-gcp-gateway aiml-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router on-prem-cr-us-central1 \ --vpn-gateway on-prem-vpn-gw \ --interface 1在 Google Cloud 控制台中,转到 VPN 页面。
在 VPN 页面上,点击 Cloud VPN 隧道标签页。
在 VPN 隧道列表中,验证是否已建立四个 VPN 隧道。
建立 BGP 会话
Cloud Router 路由器使用边界网关协议 (BGP) 在 VPC 网络(在本例中为 aiml-vpc)和本地网络(由 on-prem-vpc 表示)之间交换路由。在 Cloud Router 路由器上,请为本地路由器配置接口和 BGP 对等端。此接口和 BGP 对等配置共同构成了 BGP 会话。在本部分中,您将分别为 aiml-vpc 和 on-prem-vpc 创建两个 BGP 会话。
为 aiml-vpc 建立 BGP 会话
在 Cloud Shell 中,创建第一个 BGP 接口:
gcloud compute routers add-interface aiml-cr-us-central1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel aiml-vpc-tunnel0 \ --region us-central1创建第一个 BGP 对等方:
gcloud compute routers add-bgp-peer aiml-cr-us-central1 \ --peer-name bgp-on-premises-tunnel0 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central1创建第二个 BGP 接口:
gcloud compute routers add-interface aiml-cr-us-central1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.2.1 \ --mask-length 30 \ --vpn-tunnel aiml-vpc-tunnel1 \ --region us-central1创建第二个 BGP 对等方:
gcloud compute routers add-bgp-peer aiml-cr-us-central1 \ --peer-name bgp-on-premises-tunnel1 \ --interface if-tunnel2-to-onprem \ --peer-ip-address 169.254.2.2 \ --peer-asn 65002 \ --region us-central1
为 on-prem-vpc 建立 BGP 会话
创建第一个 BGP 接口:
gcloud compute routers add-interface on-prem-cr-us-central1 \ --interface-name if-tunnel0-to-aiml-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel on-prem-tunnel0 \ --region us-central1创建第一个 BGP 对等方:
gcloud compute routers add-bgp-peer on-prem-cr-us-central1 \ --peer-name bgp-aiml-vpc-tunnel0 \ --interface if-tunnel1-to-aiml-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central1创建第二个 BGP 接口:
gcloud compute routers add-interface on-prem-cr-us-central1 \ --interface-name if-tunnel1-to-aiml-vpc \ --ip-address 169.254.2.2 \ --mask-length 30 \ --vpn-tunnel on-prem-tunnel1 \ --region us-central1创建第二个 BGP 对等方:
gcloud compute routers add-bgp-peer on-prem-cr-us-central1 \ --peer-name bgp-aiml-vpc-tunnel1 \ --interface if-tunnel2-to-aiml-vpc \ --peer-ip-address 169.254.2.1 \ --peer-asn 65001 \ --region us-central1
验证 BGP 会话创建
在 Google Cloud 控制台中,转到 VPN 页面。
在 VPN 页面上,点击 Cloud VPN 隧道标签页。
在 VPN 隧道列表中,此时可以看到,BGP 会话状态列中四条隧道的值已从配置 BGP 会话变为已建立 BGP。您可能需要刷新 Google Cloud 控制台浏览器标签页才能查看新值。
验证 aiml-vpc 已通过高可用性 VPN 获知子网路由
在 Google Cloud 控制台中,转到 VPC 网络页面。
在 VPC 网络列表中,点击
aiml-vpc。点击路由标签页。
在区域列表中选择 us-central1(爱荷华),然后点击查看。
在目标 IP 范围列中,验证
aiml-vpcVPC 网络是否已从on-prem-vpcVPC 网络的nat-subnet子网 (192.168.10.0/28) 和private-ip-subnet(192.168.20.0/28) 子网获知路由。
验证 on-prem-vpc 已通过高可用性 VPN 获知子网路由
在 Google Cloud 控制台中,转到 VPC 网络页面。
在 VPC 网络列表中,点击
on-prem-vpc。点击路由标签页。
在区域列表中选择 us-central1(爱荷华),然后点击查看。
在目标 IP 范围列中,验证
on-prem-vpcVPC 网络是否已从aiml-vpcVPC 网络的workbench-subnet子网 (172.16.10.0/28) 获知路由。
为 aiml-vpc 创建自定义通告路由
aiml-cr-us-central1 Cloud Router 路由器不会自动通告 Private Service Connect 端点 IP 地址,因为 VPC 网络中未配置子网。
因此,您需要为端点 IP 地址 100.100.10.10 创建从 aiml-cr-us-central Cloud Router 路由器到 on-prem-vpc 的自定义通告路由,从而将该地址通过 BGP 通告给本地环境。
在 Google Cloud 控制台中,前往 Cloud Router 路由器页面。
在 Cloud Router 路由器列表中,点击
aiml-cr-us-central1。在路由器详情页面上,点击 修改。
在通告的路由部分,对于路由,选择创建自定义路由。
点击添加自定义路由。
对于来源,选择自定义 IP 范围。
对于 IP 地址范围,输入
100.100.10.10。对于说明,输入
Private Service Connect Endpoint IP。点击完成,然后点击保存。
验证 on-prem-vpc 是否已通过高可用性 VPN 获知 PSC 端点 IP 地址
在 Google Cloud 控制台中,进入 VPC 网络页面。
在 VPC 网络列表中,点击
on-prem-vpc。点击路由标签页。
在区域列表中选择 us-central1(爱荷华),然后点击查看。
在目标 IP 范围列中,验证
on-prem-vpcVPC 网络是否已获知 PSC 端点的 IP 地址 (100.100.10.10)。
为 on-prem-vpc 创建自定义通告路由
默认情况下,on-prem-vpc Cloud Router 路由器会通告所有子网,但只需要 private-ip-subnet 子网。
在以下部分中,更新 on-prem-cr-us-central1 Cloud Router 路由器中的路由通告。
在 Google Cloud 控制台中,前往 Cloud Router 路由器页面。
在 Cloud Router 路由器列表中,点击
on-prem-cr-us-central1。在路由器详情页面上,点击 修改。
在通告的路由部分,对于路由,选择创建自定义路由。
如果选中通告向 Cloud Router 公开的所有子网复选框,请将其清除。
点击添加自定义路由。
对于来源,选择自定义 IP 范围。
对于 IP 地址范围,输入
192.168.20.0/28。对于说明,输入
Private Service Connect Endpoint IP subnet (private-ip-subnet)。点击完成,然后点击保存。
验证 aiml-vpc 是否已从 on-prem-vpc 获知 private-ip-subnet 路由
在 Google Cloud 控制台中,转到 VPC 网络页面。
在 VPC 网络列表中,点击
aiml-vpc。点击路由标签页。
在区域列表中选择 us-central1(爱荷华),然后点击查看。
在目标 IP 范围列中,验证
aiml-vpcVPC 网络是否已获知private-ip-subnet路由 (192.168.20.0/28)。
创建测试虚拟机实例
创建用户管理的服务账号
如果您的应用需要调用 Google Cloud API,Google 建议您将用户管理的服务账号关联到运行应用或工作负载的虚拟机。因此,在本部分中,您将创建一个用户管理的服务账号,该服务账号将应用于您稍后将在本教程中创建的虚拟机实例。
在 Cloud Shell 中创建服务账号:
gcloud iam service-accounts create gce-vertex-sa \ --description="service account for vertex" \ --display-name="gce-vertex-sa"将 Compute Instance Admin (v1) (
roles/compute.instanceAdmin.v1) IAM 角色分配给服务账号:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:gce-vertex-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/compute.instanceAdmin.v1"将 Vertex AI User (
roles/aiplatform.user) IAM 角色分配给该服务账号:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:gce-vertex-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"
创建测试虚拟机实例
在此步骤中,您将创建测试虚拟机实例来验证访问 Vertex AI API 的不同方法,具体如下:
nat-client实例使用 Cloud NAT 解析 Vertex AI,以通过公共互联网访问在线预测端点。private-client实例使用 Private Service Connect IP 地址100.100.10.10通过高可用性 VPN 访问在线预测端点。
如需允许 Identity-Aware Proxy (IAP) 连接到您的虚拟机实例,请创建一条防火墙规则,该规则应:
- 适用于您要通过 IAP 访问的所有虚拟机实例。
- 允许来自 IP 地址范围
35.235.240.0/20的、通过端口 22 的 TCP 流量此范围包含 IAP 用于 TCP 转发的所有 IP 地址。
创建
nat-client虚拟机实例:gcloud compute instances create nat-client \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=nat-subnet \ --service-account=gce-vertex-sa@$projectid.iam.gserviceaccount.com \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"创建
private-client虚拟机实例:gcloud compute instances create private-client \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=private-ip-subnet \ --service-account=gce-vertex-sa@$projectid.iam.gserviceaccount.com \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"创建 IAP 防火墙规则:
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network on-prem-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
创建 Vertex AI Workbench 实例
为 Vertex AI Workbench 创建用户管理的服务账号
Google 强烈建议您在创建 Vertex AI Workbench 实例时,指定用户管理的服务账号,而不是使用 Compute Engine 默认服务账号。如果您的组织不强制执行 iam.automaticIamGrantsForDefaultServiceAccounts 组织政策限制,则 Compute Engine 默认服务账号(以及您指定为实例用户的任何人)将被授予您的 Google Cloud 项目的 Editor 角色 (roles/editor)。如需关闭此行为,请参阅为默认服务账号停用自动角色授予功能。
在 Cloud Shell 中,创建一个名为
workbench-sa的服务账号:gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"将 Storage Admin (
roles/storage.admin) IAM 角色分配给该服务账号:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.admin"将 Vertex AI User (
roles/aiplatform.user) IAM 角色分配给该服务账号:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"将 Artifact Registry Administrator IAM 角色分配给该服务账号:
gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.admin"
创建 Vertex AI Workbench 实例
在 Cloud Shell 中,指定
workbench-sa服务账号,创建一个 Vertex AI Workbench 实例:gcloud workbench instances create workbench-tutorial \ --vm-image-project=deeplearning-platform-release \ --vm-image-family=common-cpu-notebooks \ --machine-type=n1-standard-4 \ --location=us-central1-a \ --subnet-region=us-central1 \ --shielded-secure-boot=True \ --subnet=workbench-subnet \ --disable-public-ip \ --service-account-email=workbench-sa@$projectid.iam.gserviceaccount.com
创建和部署在线预测模型
准备环境
在 Google Cloud 控制台中,前往 Vertex AI Workbench 页面上的实例标签页。
在 Vertex AI Workbench 实例名称 (
workbench-tutorial) 旁边,点击打开 JupyterLab。您的 Vertex AI Workbench 实例会打开 JupyterLab。
在本节的其余部分(包括模型部署)中,您将使用 Jupyterlab,而不是 Google Cloud 控制台或 Cloud Shell。
选择文件 > 新建 > 终端。
在 JupyterLab 终端(而不是 Cloud Shell)中,为您的项目定义环境变量。请将 PROJECT_ID 替换为您的项目 ID:
PROJECT_ID=PROJECT_ID在其中创建名为
cpr-codelab和cd的新目录(仍然在 JupyterLab 终端中):mkdir cpr-codelab cd cpr-codelab在 文件浏览器中,双击新的
cpr-codelab文件夹。如果此文件夹未显示在文件浏览器中,请刷新 Google Cloud 控制台浏览器标签页,然后重试。
选择文件 >新建 >笔记本。
在选择内核菜单中,选择 Python [conda env:base] *(本地),然后点击选择。
按如下方式重命名新的笔记本文件:
在 文件浏览器中,右键点击
Untitled.ipynb文件图标,然后输入task.ipynb。您的
cpr-codelab目录现在应如下所示:+ cpr-codelab/ + task.ipynb在以下步骤中,您将创建新的笔记本单元、将代码粘贴到其中并运行这些单元,以此在 Jupyterlab 笔记本中创建模型。
安装依赖项,如下所示。
当您打开新的笔记本时,有一个默认代码单元,您可以在其中输入代码。它类似于
[ ]:,后跟一个文本字段。您的代码将粘贴到该文本字段中。将以下代码粘贴到单元中,然后点击 运行所选单元并前进以创建
requirements.txt文件,后续步骤将使用该文件作为输入:%%writefile requirements.txt fastapi uvicorn==0.17.6 joblib~=1.1.1 numpy>=1.17.3, <1.24.0 scikit-learn>=1.2.2 pandas google-cloud-storage>=2.2.1,<3.0.0dev google-cloud-aiplatform[prediction]>=1.18.2在此步骤以及下面的每个步骤中,点击 在下方插入单元,将代码粘贴到该单元中,然后点击 运行所选单元并前进。
使用
Pip在笔记本实例中安装依赖项:!pip install -U --user -r requirements.txt安装完成后,依次选择内核 > 重启内核来重启内核,并确保该库可用于导入。
将以下代码粘贴到新的笔记本单元,以创建用于存储模型和预处理工件的目录:
USER_SRC_DIR = "src_dir" !mkdir $USER_SRC_DIR !mkdir model_artifacts # copy the requirements to the source dir !cp requirements.txt $USER_SRC_DIR/requirements.txt
在 文件浏览器中,您的
cpr-codelab目录结构现在应如下所示:+ cpr-codelab/ + model_artifacts/ + src_dir/ + requirements.txt + requirements.txt + task.ipynb
训练模型
继续向 task.ipynb 笔记本添加代码单元,并在每个新单元中粘贴并运行以下代码:
导入库:
import seaborn as sns import numpy as np import pandas as pd from sklearn import preprocessing from sklearn.ensemble import RandomForestRegressor from sklearn.pipeline import make_pipeline from sklearn.compose import make_column_transformer import joblib import logging # set logging to see the docker container logs logging.basicConfig(level=logging.INFO)定义以下变量,将 PROJECT_ID 替换为您的项目 ID:
REGION = "us-central1" MODEL_ARTIFACT_DIR = "sklearn-model-artifacts" REPOSITORY = "diamonds" IMAGE = "sklearn-image" MODEL_DISPLAY_NAME = "diamonds-cpr" PROJECT_ID = "PROJECT_ID" BUCKET_NAME = "gs://PROJECT_ID-cpr-bucket"创建 Cloud Storage 存储桶,请运行以下命令:
!gcloud storage buckets create $BUCKET_NAME --location=us-central1从 seaborn 库加载数据,然后创建两个数据帧,一个包含特征,另一个包含标签:
data = sns.load_dataset('diamonds', cache=True, data_home=None) label = 'price' y_train = data['price'] x_train = data.drop(columns=['price'])查看训练数据,并验证每行是否代表一颗钻石。
x_train.head()查看标签,这代表相应的价格。
y_train.head()定义 sklearn 列转换以对分类特征进行独热编码并缩放数值特征:
column_transform = make_column_transformer( (preprocessing.OneHotEncoder(), [1,2,3]), (preprocessing.StandardScaler(), [0,4,5,6,7,8]))定义随机森林模型:
regr = RandomForestRegressor(max_depth=10, random_state=0)创建 sklearn 流水线。此流水线接受输入数据,对其进行编码和缩放,然后将其传递给模型。
my_pipeline = make_pipeline(column_transform, regr)训练模型:
my_pipeline.fit(x_train, y_train)对该模型调用预测方法,并传入测试样本。
my_pipeline.predict([[0.23, 'Ideal', 'E', 'SI2', 61.5, 55.0, 3.95, 3.98, 2.43]])您可能会看到
"X does not have valid feature names, but"之类的警告,但可以忽略它们。将流水线保存到
model_artifacts目录,并将其复制到您的 Cloud Storage 存储桶:joblib.dump(my_pipeline, 'model_artifacts/model.joblib') !gcloud storage cp model_artifacts/model.joblib {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
保存预处理工件
创建预处理工件。模型服务器启动时,此工件将加载到自定义容器中。预处理工件几乎可以是任何形式(例如 pickle 文件),但在这种情况下,需要将字典写入 JSON 文件:
clarity_dict={"Flawless": "FL", "Internally Flawless": "IF", "Very Very Slightly Included": "VVS1", "Very Slightly Included": "VS2", "Slightly Included": "S12", "Included": "I3"}
使用 CPR 模型服务器构建自定义传送容器
训练数据中的
clarity特征始终采用缩写形式(即“FL”而非“Flawless”)。在传送时,我们希望检查此特征的数据是否也采用缩写。这是因为我们的模型知道如何对“FL”进行独热编码,但不知道如何对“Flawless”进行独热编码。稍后您将编写此自定义预处理逻辑。但是,目前只需将此对照表保存到 JSON 文件,然后将其写入 Cloud Storage 存储桶:import json with open("model_artifacts/preprocessor.json", "w") as f: json.dump(clarity_dict, f) !gcloud storage cp model_artifacts/preprocessor.json {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/在 文件浏览器中,您的目录结构现在应如下所示:
+ cpr-codelab/ + model_artifacts/ + model.joblib + preprocessor.json + src_dir/ + requirements.txt + requirements.txt + task.ipynb在笔记本中,粘贴并运行以下代码,以设置
SklearnPredictor的子类,并将其写入src_dir/中的 Python 文件。请注意,在此示例中,我们仅自定义加载、预处理和后处理方法,而不会自定义预测方法。%%writefile $USER_SRC_DIR/predictor.py import joblib import numpy as np import json from google.cloud import storage from google.cloud.aiplatform.prediction.sklearn.predictor import SklearnPredictor class CprPredictor(SklearnPredictor): def __init__(self): return def load(self, artifacts_uri: str) -> None: """Loads the sklearn pipeline and preprocessing artifact.""" super().load(artifacts_uri) # open preprocessing artifact with open("preprocessor.json", "rb") as f: self._preprocessor = json.load(f) def preprocess(self, prediction_input: np.ndarray) -> np.ndarray: """Performs preprocessing by checking if clarity feature is in abbreviated form.""" inputs = super().preprocess(prediction_input) for sample in inputs: if sample[3] not in self._preprocessor.values(): sample[3] = self._preprocessor[sample[3]] return inputs def postprocess(self, prediction_results: np.ndarray) -> dict: """Performs postprocessing by rounding predictions and converting to str.""" return {"predictions": [f"${value}" for value in np.round(prediction_results)]}使用 Vertex AI SDK for Python 通过自定义预测例程构建映像。系统会生成 Dockerfile 并为您构建映像。
from google.cloud import aiplatform aiplatform.init(project=PROJECT_ID, location=REGION) import os from google.cloud.aiplatform.prediction import LocalModel from src_dir.predictor import CprPredictor # Should be path of variable $USER_SRC_DIR local_model = LocalModel.build_cpr_model( USER_SRC_DIR, f"{REGION}-docker.pkg.dev/{PROJECT_ID}/{REPOSITORY}/{IMAGE}", predictor=CprPredictor, requirements_path=os.path.join(USER_SRC_DIR, "requirements.txt"), )编写包含两个预测样本的测试文件。其中一个实例具有缩写的清晰名称,但其他实例需要先进行转换。
import json sample = {"instances": [ [0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43], [0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]} with open('instances.json', 'w') as fp: json.dump(sample, fp)通过部署本地模型在本地测试容器。
with local_model.deploy_to_local_endpoint( artifact_uri = 'model_artifacts/', # local path to artifacts ) as local_endpoint: predict_response = local_endpoint.predict( request_file='instances.json', headers={"Content-Type": "application/json"}, ) health_check_response = local_endpoint.run_health_check()您可以通过以下方式查看预测结果:
predict_response.content输出如下所示:
b'{"predictions": ["$479.0", "$586.0"]}'
将模型部署到在线预测模型端点
现在您已在本地测试了容器,接下来可以将映像推送到 Artifact Registry 并将模型上传到 Vertex AI Model Registry。
配置 Docker 以访问 Artifact Registry。
!gcloud artifacts repositories create {REPOSITORY} \ --repository-format=docker \ --location=us-central1 \ --description="Docker repository" !gcloud auth configure-docker {REGION}-docker.pkg.dev --quiet推送映像。
local_model.push_image()上传模型。
model = aiplatform.Model.upload(local_model = local_model, display_name=MODEL_DISPLAY_NAME, artifact_uri=f"{BUCKET_NAME}/{MODEL_ARTIFACT_DIR}",)部署模型:
endpoint = model.deploy(machine_type="n1-standard-2")等待模型部署,然后再转到下一步。 预计部署过程大约需要 10 到 15 分钟。
通过获取预测结果来测试已部署的模型:
endpoint.predict(instances=[[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43]])输出如下所示:
Prediction(predictions=['$479.0'], deployed_model_id='3171115779319922688', metadata=None, model_version_id='1', model_resource_name='projects/721032480027/locations/us-central1/models/8554949231515795456', explanations=None)
验证对 Vertex AI API 的公共互联网访问
在此部分中,您将在一个 Cloud Shell 会话标签页中登录 nat-client 虚拟机实例,并使用另一个会话标签页对网域 us-central1-aiplatform.googleapis.com 运行 dig 和 tcpdump 命令来验证与 Vertex AI API 的连接。
在 Cloud Shell(第一个标签页)中,运行以下命令,将 PROJECT_ID 替换为您的项目 ID:
projectid=PROJECT_ID gcloud config set project ${projectid}使用 IAP 登录到
nat-client虚拟机实例:gcloud compute ssh nat-client \ --project=$projectid \ --zone=us-central1-a \ --tunnel-through-iap运行
dig命令:dig us-central1-aiplatform.googleapis.com在
nat-client虚拟机(第一个标签页)中,在向端点发送在线预测请求时运行以下命令,以验证 DNS 解析。sudo tcpdump -i any port 53 -n点击 Cloud Shell 中的 打开新标签页,打开新的 Cloud Shell 会话(第二个标签页)。
在新的 Cloud Shell 会话(第二个标签页)中,运行以下命令,将 PROJECT_ID 替换为您的项目 ID:
projectid=PROJECT_ID gcloud config set project ${projectid}登录到
nat-client虚拟机实例:gcloud compute ssh --zone "us-central1-a" "nat-client" --project "$projectid"在
nat-client虚拟机(第二个标签页)中,使用文本编辑器(例如vim或nano)创建instances.json文件。您需要前置sudo才有权写入文件,例如:sudo vim instances.json将以下数据字符串添加到文件中:
{"instances": [ [0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43], [0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]}按如下方式保存文件:
- 如果您使用的是
vim,请按Esc键,然后输入:wq以保存文件并退出。 - 如果您使用的是
nano,请输入Control+O并按Enter以保存该文件,然后输入Control+X以退出。
- 如果您使用的是
找到 PSC 端点的在线预测端点 ID:
在 Google Cloud 控制台的 Vertex AI 部分中,转到在线预测页面中的端点标签页。
找到您创建的端点(名为
diamonds-cpr_endpoint)所在的行。在 ID 列中找到 19 位的端点 ID,然后复制此 ID。
在 Cloud Shell 中,从
nat-client虚拟机(第二个标签页)运行以下命令,将 PROJECT_ID 替换为您的项目 ID,将 ENDPOINT_ID 替换为 PSC 端点 ID:projectid=PROJECT_ID gcloud config set project ${projectid} ENDPOINT_ID=ENDPOINT_ID在
nat-client虚拟机(第二个标签页)中运行以下命令,以发送在线预测请求:curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://us-central1-aiplatform.googleapis.com/v1/projects/${projectid}/locations/us-central1/endpoints/${ENDPOINT_ID}:predict -d @instances.json
现在您已运行预测,接下来会看到 tcpdump 结果(第一个标签页)显示 nat-client 虚拟机实例 (192.168.10.2) 在为 Vertex AI API 网域 (us-central1-aiplatform.googleapis.com) 执行对本地 DNS 服务器 (169.254.169.254) 的 Cloud DNS 查询。DNS 查询返回 Vertex AI API 的公共虚拟 IP 地址 (VIP)。
验证对 Vertex AI API 的专用访问
在本部分中,您将在新的 Cloud Shell 会话(第三个标签页)中使用 Identity-Aware Proxy 登录 private-client 虚拟机实例,然后通过对 Vertex AI 网域 (us-central1-aiplatform.googleapis.com) 运行 dig 命令来验证与 Vertex AI API 的连接。
点击 Cloud Shell 中的 打开新标签页,打开新的 Cloud Shell 会话(第三个标签页)。这是第三个标签页。
在新的 Cloud Shell 会话(第三个标签页)中,运行以下命令,将 PROJECT_ID 替换为您的项目 ID:
projectid=PROJECT_ID gcloud config set project ${projectid}使用 IAP 登录到
private-client虚拟机实例:gcloud compute ssh private-client \ --project=$projectid \ --zone=us-central1-a \ --tunnel-through-iap运行
dig命令:dig us-central1-aiplatform.googleapis.com在
private-client虚拟机实例(第三个标签页)中,使用文本编辑器(如vim或nano)将以下行添加到/etc/hosts文件中:100.100.10.10 us-central1-aiplatform.googleapis.com此行将 PSC 端点的 IP 地址 (
100.100.10.10) 分配给 Vertex AI Google API (us-central1-aiplatform.googleapis.com) 的完全限定域名。修改后的文件应如下所示:127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 100.100.10.10 us-central1-aiplatform.googleapis.com # Added by you 192.168.20.2 private-client.c.$projectid.internal private-client # Added by Google 169.254.169.254 metadata.google.internal # Added by Google在
private-client虚拟机(第三个标签页)中,对 Vertex AI 端点执行 ping 操作,并在看到输出时退出Control+C:ping us-central1-aiplatform.googleapis.comping命令会返回以下输出,其中包含 PSC 端点的 IP 地址:PING us-central1-aiplatform.googleapis.com (100.100.10.10) 56(84) bytes of data.在
private-client虚拟机(第三个标签页)中,在向端点发送在线预测请求时,使用tcpdump运行以下命令来验证 DNS 解析和 IP 数据路径:sudo tcpdump -i any port 53 -n or host 100.100.10.10点击 Cloud Shell 中的 打开新标签页,打开新的 Cloud Shell 会话(第四个标签页)。
在新的 Cloud Shell 会话(第四个标签页)中,运行以下命令,将 PROJECT_ID 替换为您的项目 ID:
projectid=PROJECT_ID gcloud config set project ${projectid}在第四个标签页中,登录到
private-client实例:gcloud compute ssh \ --zone "us-central1-a" "private-client" \ --project "$projectid"在
private-client虚拟机(第四个标签页)中,使用文本编辑器(例如vim或nano)创建包含以下数据字符串的instances.json文件。{"instances": [ [0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43], [0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]}在
private-client虚拟机(第四个标签页)中,运行以下命令,将 PROJECT_ID 替换为您的项目名称,将 ENDPOINT_ID 替换为 PSC 端点 ID:projectid=PROJECT_ID echo $projectid ENDPOINT_ID=ENDPOINT_ID在
private-client虚拟机(第四个标签页)中运行以下命令,以发送在线预测请求:curl -v -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://us-central1-aiplatform.googleapis.com/v1/projects/${projectid}/locations/us-central1/endpoints/${ENDPOINT_ID}:predict -d @instances.json在 Cloud Shell(第三个标签页)中的
private-client虚拟机中,验证是否使用 PSC 端点 IP 地址 (100.100.10.10) 访问 Vertex AI API。在 Cloud Shell 第三个标签页中的
private-clienttcpdump终端中,您可以看到不需要对us-central1-aiplatform.googleapis.com进行 DNS 查找,因为已添加到/etc/hosts文件的行优先级更高,并且数据路径中使用了 PSC IP 地址100.100.10.10。
清理
为避免因本教程中使用的资源导致您的 Google Cloud 账号产生费用,请删除包含这些资源的项目,或者保留项目但删除各个资源。
您可以按如下方式删除项目中的各个资源:
按如下方式删除 Vertex AI Workbench 实例:
在 Google Cloud 控制台的 Vertex AI 部分中,转到 Workbench 页面中的实例标签页。
选择
workbench-tutorialVertex AI Workbench 实例,然后点击 删除。
按如下方式删除容器映像:
在 Google Cloud 控制台中,转到 Artifact Registry 页面。
选择
diamondsDocker 容器,然后点击 删除。
按如下方式删除存储桶:
在 Google Cloud 控制台中,转到 Cloud Storage 页面。
选择您的存储桶,然后点击 删除。
从端点取消部署模型,如下所示:
在 Google Cloud 控制台的 Vertex AI 部分中,转到端点页面。
点击
diamonds-cpr_endpoint以转到端点详情页面。在模型所对应的行中 (
diamonds-cpr),点击取消部署模型 。在从端点取消部署模型对话框中,点击取消部署。
按如下方式删除模型:
在 Google Cloud 控制台的 Vertex AI 部分中,转到 Model Registry 页面。
选择
diamonds-cpr模型。如需删除模型,请点击 操作,然后点击删除模型。
删除在线预测端点,如下所示:
在 Google Cloud 控制台的 Vertex AI 部分中,转到在线预测页面。
选择
diamonds-cpr_endpoint端点。如需删除端点,请点击 操作,然后点击删除端点。
在 Cloud Shell 中,通过执行以下命令删除其余资源。
projectid=PROJECT_ID gcloud config set project ${projectid}gcloud compute forwarding-rules delete pscvertex \ --global \ --quietgcloud compute addresses delete psc-ip \ --global \ --quietgcloud compute networks subnets delete workbench-subnet \ --region=us-central1 \ --quietgcloud compute vpn-tunnels delete aiml-vpc-tunnel0 aiml-vpc-tunnel1 on-prem-tunnel0 on-prem-tunnel1 \ --region=us-central1 \ --quietgcloud compute vpn-gateways delete aiml-vpn-gw on-prem-vpn-gw \ --region=us-central1 \ --quietgcloud compute routers nats delete cloud-nat-us-central1 \ --router=cloud-router-us-central1-aiml-nat \ --region=us-central1 \ --quietgcloud compute routers delete aiml-cr-us-central1 cloud-router-us-central1-aiml-nat \ --region=us-central1 \ --quietgcloud compute routers delete cloud-router-us-central1-on-prem-nat on-prem-cr-us-central1 \ --region=us-central1 \ --quietgcloud compute instances delete nat-client private-client \ --zone=us-central1-a \ --quietgcloud compute firewall-rules delete ssh-iap-on-prem-vpc \ --quietgcloud compute networks subnets delete nat-subnet private-ip-subnet \ --region=us-central1 \ --quietgcloud compute networks delete on-prem-vpc \ --quietgcloud compute networks delete aiml-vpc \ --quietgcloud iam service-accounts delete gce-vertex-sa@$projectid.iam.gserviceaccount.com \ --quietgcloud iam service-accounts delete workbench-sa@$projectid.iam.gserviceaccount.com \ --quiet
后续步骤
- 了解用于访问 Vertex AI 端点和服务的企业网络选项
- 了解 Private Service Connect 的工作原理及其提供显著性能优势的原因。
- 了解如何使用 VPC Service Controls 创建安全边界,以允许或拒绝对在线预测端点上的 Vertex AI 和其他 Google API 的访问。
- 了解如何以及为何在大型和生产环境中使用 DNS 转发区域而不是更新
/etc/hosts文件。