批量推理是指直接从模型资源请求推理的异步请求,无需将模型部署到端点。
在本教程中,您将使用高可用性 VPN (HA VPN) 在可用作多云和本地专用连接基础的两个 Virtual Private Cloud 网络之间以私密方式向经过训练的模型发送批量推理请求。
本教程适用于熟悉 Vertex AI、虚拟私有云 (VPC)、 Google Cloud 控制台和 Cloud Shell 的企业网络管理员、数据科学家和研究人员。熟悉 Vertex AI Workbench 会很有帮助,但不强制要求。
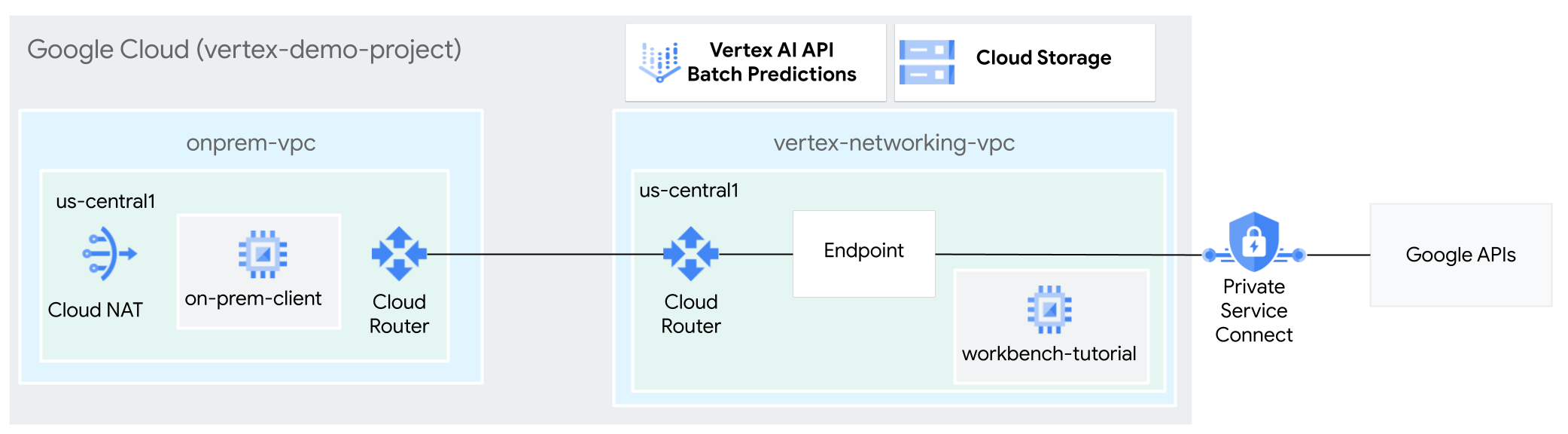
创建 VPC 网络
在本部分中,您将创建两个 VPC 网络:一个用于访问 Google API 以进行批量推理,另一个用于模拟本地网络。在两个 VPC 网络中,您都需要创建一个 Cloud Router 路由器和 Cloud NAT 网关。Cloud NAT 网关为没有外部 IP 地址的 Compute Engine 虚拟机实例提供传出连接。
创建
vertex-networking-vpcVPC 网络:gcloud compute networks create vertex-networking-vpc \ --subnet-mode custom在
vertex-networking-vpc网络中,创建一个名为workbench-subnet的子网,其主要 IPv4 范围为10.0.1.0/28:gcloud compute networks subnets create workbench-subnet \ --range=10.0.1.0/28 \ --network=vertex-networking-vpc \ --region=us-central1 \ --enable-private-ip-google-access创建用于模拟本地网络的 VPC 网络 (
onprem-vpc):gcloud compute networks create onprem-vpc \ --subnet-mode custom在
onprem-vpc网络中,创建一个名为onprem-vpc-subnet1的子网,其主要 IPv4 范围为172.16.10.0/29:gcloud compute networks subnets create onprem-vpc-subnet1 \ --network onprem-vpc \ --range 172.16.10.0/29 \ --region us-central1
验证 VPC 网络是否已正确配置
在 Google Cloud 控制台中,前往 VPC 网络页面上的当前项目中的网络标签页。
在 VPC 网络列表中,验证是否已创建
vertex-networking-vpc和onprem-vpc这两个网络。点击当前项目中的子网标签页。
在 VPC 子网列表中,验证是否已创建
workbench-subnet和onprem-vpc-subnet1子网。
配置混合连接
在本部分中,您将创建两个相互连接的高可用性 VPN 网关。一个位于 vertex-networking-vpc VPC 网络中。另一个位于 onprem-vpc VPC 网络中。 每个网关包含一个 Cloud Router 路由器和一对 VPN 隧道。
创建高可用性 VPN 网关
在 Cloud Shell 中,为
vertex-networking-vpcVPC 网络创建高可用性 VPN 网关:gcloud compute vpn-gateways create vertex-networking-vpn-gw1 \ --network vertex-networking-vpc \ --region us-central1为
onprem-vpcVPC 网络创建高可用性 VPN 网关:gcloud compute vpn-gateways create onprem-vpn-gw1 \ --network onprem-vpc \ --region us-central1在 Google Cloud 控制台中,前往 VPN 页面上的 Cloud VPN 网关标签页。
验证是否已创建两个网关(
vertex-networking-vpn-gw1和onprem-vpn-gw1),并且每个网关具有两个接口 IP 地址。
创建 Cloud Router 路由器和 Cloud NAT 网关
在两个 VPC 网络中,您都将创建两个 Cloud Router 路由器:一个通用路由器和一个区域级路由器。在每个区域级 Cloud Router 路由器中,您都将创建一个 Cloud NAT 网关。Cloud NAT 网关为没有外部 IP 地址的 Compute Engine 虚拟机 (VM) 实例提供传出连接。
在 Cloud Shell 中,为
vertex-networking-vpcVPC 网络创建一个 Cloud Router 路由器:gcloud compute routers create vertex-networking-vpc-router1 \ --region us-central1\ --network vertex-networking-vpc \ --asn 65001为
onprem-vpcVPC 网络创建一个 Cloud Router 路由器:gcloud compute routers create onprem-vpc-router1 \ --region us-central1\ --network onprem-vpc\ --asn 65002为
vertex-networking-vpcVPC 网络创建一个区域级 Cloud Router 路由器:gcloud compute routers create cloud-router-us-central1-vertex-nat \ --network vertex-networking-vpc \ --region us-central1在区域级 Cloud Router 路由器上配置 Cloud NAT 网关:
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-vertex-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1为
onprem-vpcVPC 网络创建一个区域级 Cloud Router 路由器:gcloud compute routers create cloud-router-us-central1-onprem-nat \ --network onprem-vpc \ --region us-central1在区域级 Cloud Router 路由器上配置 Cloud NAT 网关:
gcloud compute routers nats create cloud-nat-us-central1-on-prem \ --router=cloud-router-us-central1-onprem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1在 Google Cloud 控制台中,前往 Cloud Router 页面。
在 Cloud Router 路由器列表中,验证是否已创建以下路由器:
cloud-router-us-central1-onprem-natcloud-router-us-central1-vertex-natonprem-vpc-router1vertex-networking-vpc-router1
您可能需要刷新 Google Cloud 控制台浏览器标签页才能查看新值。
在 Cloud Router 路由器列表中,点击
cloud-router-us-central1-vertex-nat。在路由器详情页面中,验证是否已创建
cloud-nat-us-central1Cloud NAT 网关。点击 返回箭头以返回 Cloud Router 路由器页面。
在路由器列表中,点击
cloud-router-us-central1-onprem-nat。在路由器详情页面中,验证是否已创建
cloud-nat-us-central1-on-premCloud NAT 网关。
创建 VPN 隧道
在 Cloud Shell 中,在
vertex-networking-vpc网络中创建一个名为vertex-networking-vpc-tunnel0的 VPN 隧道:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel0 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 0在
vertex-networking-vpc网络中,创建一个名为vertex-networking-vpc-tunnel1的 VPN 隧道:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel1 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 1在
onprem-vpc网络中,创建一个名为onprem-vpc-tunnel0的 VPN 隧道:gcloud compute vpn-tunnels create onprem-vpc-tunnel0 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router onprem-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 0在
onprem-vpc网络中,创建一个名为onprem-vpc-tunnel1的 VPN 隧道:gcloud compute vpn-tunnels create onprem-vpc-tunnel1 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router onprem-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 1在 Google Cloud 控制台中,前往 VPN 页面。
在 VPN 隧道列表中,验证是否已创建这四个 VPN 隧道。
建立 BGP 会话
Cloud Router 路由器使用边界网关协议 (BGP) 在 VPC 网络(在本例中为 vertex-networking-vpc)和本地网络(由 onprem-vpc 表示)之间交换路由。在 Cloud Router 路由器上,为本地路由器配置接口和 BGP 对等端。此接口和 BGP 对等配置共同构成了 BGP 会话。在本部分中,您将分别为 vertex-networking-vpc 和 onprem-vpc 创建两个 BGP 会话。
在路由器之间配置接口和 BGP 对等方后,它们将自动开始交换路由。
为 vertex-networking-vpc 建立 BGP 会话
在 Cloud Shell 中,在
vertex-networking-vpc网络中为vertex-networking-vpc-tunnel0创建一个 BGP 接口:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.0.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel0 \ --region us-central1在
vertex-networking-vpc网络中,为bgp-onprem-tunnel0创建一个 BGP 对等方:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel0 \ --interface if-tunnel0-to-onprem \ --peer-ip-address 169.254.0.2 \ --peer-asn 65002 \ --region us-central1在
vertex-networking-vpc网络中,为vertex-networking-vpc-tunnel1创建一个 BGP 接口:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel1 \ --region us-central1在
vertex-networking-vpc网络中,为bgp-onprem-tunnel1创建一个 BGP 对等方:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel1 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central1
为 onprem-vpc 建立 BGP 会话
在
onprem-vpc网络中,为onprem-vpc-tunnel0创建一个 BGP 接口:gcloud compute routers add-interface onprem-vpc-router1 \ --interface-name if-tunnel0-to-vertex-networking-vpc \ --ip-address 169.254.0.2 \ --mask-length 30 \ --vpn-tunnel onprem-vpc-tunnel0 \ --region us-central1在
onprem-vpc网络中,为bgp-vertex-networking-vpc-tunnel0创建一个 BGP 对等方:gcloud compute routers add-bgp-peer onprem-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel0 \ --interface if-tunnel0-to-vertex-networking-vpc \ --peer-ip-address 169.254.0.1 \ --peer-asn 65001 \ --region us-central1在
onprem-vpc网络中,为onprem-vpc-tunnel1创建一个 BGP 接口:gcloud compute routers add-interface onprem-vpc-router1 \ --interface-name if-tunnel1-to-vertex-networking-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel onprem-vpc-tunnel1 \ --region us-central1在
onprem-vpc网络中,为bgp-vertex-networking-vpc-tunnel1创建一个 BGP 对等方:gcloud compute routers add-bgp-peer onprem-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel1 \ --interface if-tunnel1-to-vertex-networking-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central1
验证 BGP 会话创建
在 Google Cloud 控制台中,前往 VPN 页面。
在 VPN 隧道列表中,验证每个隧道的 BGP 会话状态列中的值是否已从 配置 BGP 会话更改为 BGP 已建立。您可能需要刷新 Google Cloud 控制台浏览器标签页才能查看新值。
验证 vertex-networking-vpc 是否了解路由
在 Google Cloud 控制台中,前往 VPC 网络页面。
在 VPC 网络列表中,点击
vertex-networking-vpc。点击路由标签页。
在区域列表中选择 us-central1(爱荷华),然后点击查看。
在目标 IP 范围列中,验证
onprem-vpc-subnet1子网的 IP 范围 (172.16.10.0/29) 是否出现两次。
验证 onprem-vpc 是否了解路由
点击 返回箭头以返回 VPC 网络页面。
在 VPC 网络列表中,点击
onprem-vpc。点击路由标签页。
在区域列表中选择 us-central1(爱荷华),然后点击查看。
在目标 IP 范围列中,验证
workbench-subnet子网 IP 范围 (10.0.1.0/28) 是否出现两次。
创建 Private Service Connect 使用方端点
在 Cloud Shell 中,预留将用于访问 Google API 的使用方端点 IP 地址:
gcloud compute addresses create psc-googleapi-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=192.168.0.1 \ --network=vertex-networking-vpc创建转发规则以将端点连接到 Google API 和服务。
gcloud compute forwarding-rules create pscvertex \ --global \ --network=vertex-networking-vpc\ --address=psc-googleapi-ip \ --target-google-apis-bundle=all-apis
为 vertex-networking-vpc 创建自定义通告路由
在本部分中,您将配置 Cloud Router 自定义通告模式,以通告自定义 IP 范围,从而使 vertex-networking-vpc-router1(vertex-networking-vpc 的 Cloud Router)将 PSC 端点的 IP 地址通告给 onprem-vpc 网络。
在 Google Cloud 控制台中,前往 Cloud Router 页面。
在 Cloud Router 路由器列表中,点击
vertex-networking-vpc-router1。在路由器详情页面上,点击 修改。
在通告的路由部分,对于路由,选择创建自定义路由。
选中通告向 Cloud Router 路由器公开的所有子网复选框,以继续通告 Cloud Router 路由器可用的子网。启用此选项可模拟 Cloud Router 路由器在默认通告模式下的行为。
点击添加自定义路由。
对于来源,选择自定义 IP 范围。
在 IP 地址范围字段中,输入以下 IP 地址:
192.168.0.1在说明字段中,输入以下文本:
Custom route to advertise Private Service Connect endpoint IP address点击完成,然后点击保存。
验证 onprem-vpc 是否已获知通告的路由
在 Google Cloud 控制台中,转到路由页面。
在有效路由标签页上,执行以下操作:
- 在网络字段中,选择
onprem-vpc。 - 在区域字段中,选择
us-central1 (Iowa)。 - 点击视图。
在路由列表中,验证是否存在名称以
onprem-vpc-router1-bgp-vertex-networking-vpc-tunnel0和onprem-vpc-router1-bgp-vfertex-networking-vpc-tunnel1开头的条目,并且两者的目标 IP 范围 为192.168.0.1。如果这些条目没有立即显示,请等待几分钟,然后刷新 Google Cloud 控制台浏览器标签页。
- 在网络字段中,选择
在 onprem-vpc 中创建使用用户管理的服务账号的虚拟机
在本部分中,您将创建一个虚拟机实例,以模拟发送批量推理请求的本地客户端应用。按照 Compute Engine 和 IAM 最佳实践,此虚拟机使用用户管理的服务账号,而不是 Compute Engine 默认服务账号。
创建用户管理的服务账号
在 Cloud Shell 中,运行以下命令,并将 PROJECT_ID 替换为您的项目 ID:
projectid=PROJECT_ID gcloud config set project ${projectid}创建名为
onprem-user-managed-sa的服务账号:gcloud iam service-accounts create onprem-user-managed-sa \ --display-name="onprem-user-managed-sa-onprem-client"将 Vertex AI User (
roles/aiplatform.user) 角色分配给该服务账号:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"将 Storage Object Viewer (
storage.objectViewer) 角色分配给该服务账号:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.objectViewer"
创建 on-prem-client 虚拟机实例
您创建的虚拟机实例没有外部 IP 地址,也不允许通过互联网直接访问。如需启用对虚拟机的管理员权限,请使用 Identity-Aware Proxy (IAP) TCP 转发。
在 Cloud Shell 中,创建
on-prem-client虚拟机实例:gcloud compute instances create on-prem-client \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=onprem-vpc-subnet1 \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --shielded-secure-boot \ --service-account=onprem-user-managed-sa@$projectid.iam.gserviceaccount.com \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"创建一条防火墙规则以允许 IAP 连接到虚拟机实例:
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network onprem-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
验证对 Vertex AI API 的公开访问
在本部分中,您将使用 dig 实用程序执行从 on-prem-client 虚拟机实例到 Vertex AI API (us-central1-aiplatform.googleapis.com) 的 DNS 查找。dig 输出显示默认访问权限仅使用公共 VIP 来访问 Vertex AI API。
在下一部分中,您将配置对 Vertex AI API 的专用访问。
在 Cloud Shell 中,使用 IAP 登录到
on-prem-client虚拟机实例:gcloud compute ssh on-prem-client \ --zone=us-central1-a \ --tunnel-through-iap在
on-prem-client虚拟机实例中,运行dig命令:dig us-central1-aiplatform.googleapis.com您应该会看到类似如下所示的
dig输出,其中回答部分中的 IP 地址是公共 IP 地址:; <<>> DiG 9.16.44-Debian <<>> us-central1.aiplatfom.googleapis.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 42506 ;; flags: qr rd ra; QUERY: 1, ANSWER: 16, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ;; QUESTION SECTION: ;us-central1.aiplatfom.googleapis.com. IN A ;; ANSWER SECTION: us-central1.aiplatfom.googleapis.com. 300 IN A 173.194.192.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.152.95 us-central1.aiplatfom.googleapis.com. 300 IN A 172.217.219.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.146.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.147.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.125.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.136.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.148.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.200.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.234.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.251.171.95 us-central1.aiplatfom.googleapis.com. 300 IN A 108.177.112.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.128.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.251.6.95 us-central1.aiplatfom.googleapis.com. 300 IN A 172.217.212.95 us-central1.aiplatfom.googleapis.com. 300 IN A 74.125.124.95 ;; Query time: 8 msec ;; SERVER: 169.254.169.254#53(169.254.169.254) ;; WHEN: Wed Sep 27 04:10:16 UTC 2023 ;; MSG SIZE rcvd: 321
配置并验证对 Vertex AI API 的专用访问
在本部分中,您将配置对 Vertex AI API 的专用访问,以便在您发送批量推理请求时,这些请求会重定向到您的 PSC 端点。然后,PSC 端点会将这些专用请求转发到 Vertex AI 批量推理 REST API。
更新 /etc/hosts 文件以指向 PSC 端点
在此步骤中,您将在 /etc/hosts 文件中添加一行,以使发送到公共服务端点 (us-central1-aiplatform.googleapis.com) 的请求重定向到 PSC 端点 (192.168.0.1)。
在
on-prem-client虚拟机实例中,使用文本编辑器(例如vim或nano)打开/etc/hosts文件:sudo vim /etc/hosts将以下代码行添加到文件中:
192.168.0.1 us-central1-aiplatform.googleapis.com此行将 PSC 端点的 IP 地址 (
192.168.0.1) 分配给 Vertex AI Google API (us-central1-aiplatform.googleapis.com) 的完全限定域名。修改后的文件应如下所示:
127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 192.168.0.1 us-central1-aiplatform.googleapis.com # Added by you 172.16.10.6 on-prem-client.us-central1-a.c.vertex-genai-400103.internal on-prem-client # Added by Google 169.254.169.254 metadata.google.internal # Added by Google按如下方式保存文件:
- 如果您使用的是
vim,请按Esc键,然后输入:wq以保存文件并退出。 - 如果您使用的是
nano,请输入Control+O并按Enter以保存该文件,然后输入Control+X以退出。
- 如果您使用的是
对 Vertex AI 端点执行 ping 操作,如下所示:
ping us-central1-aiplatform.googleapis.comping命令应返回以下输出。192.168.0.1是 PSC 端点 IP 地址:PING us-central1-aiplatform.googleapis.com (192.168.0.1) 56(84) bytes of data.输入
Control+C以从ping退出。输入
exit以从on-prem-client虚拟机实例退出。
在 vertex-networking-vpc 中为 Vertex AI Workbench 创建用户代管式服务账号
在本部分中,如需控制对 Vertex AI Workbench 实例的访问权限,您将创建一个用户管理的服务账号,然后向该服务账号分配 IAM 角色。创建实例时,您需要指定服务账号。
在 Cloud Shell 中,运行以下命令,并将 PROJECT_ID 替换为您的项目 ID:
projectid=PROJECT_ID gcloud config set project ${projectid}创建名为
workbench-sa的服务账号:gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"将 Vertex AI User (
roles/aiplatform.user) IAM 角色分配给该服务账号:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"将 BigQuery User (
roles/bigquery.user) IAM 角色分配给该服务账号:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/bigquery.user"将 Storage Admin (
roles/storage.admin) IAM 角色分配给该服务账号:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.admin"将 Logs Viewer (
roles/logging.viewer) IAM 角色分配给该服务账号:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/logging.viewer"
创建 Vertex AI Workbench 实例
在 Cloud Shell 中,指定
workbench-sa服务账号,创建一个 Vertex AI Workbench 实例:gcloud workbench instances create workbench-tutorial \ --vm-image-project=deeplearning-platform-release \ --vm-image-family=common-cpu-notebooks \ --machine-type=n1-standard-4 \ --location=us-central1-a \ --subnet-region=us-central1 \ --shielded-secure-boot=True \ --subnet=workbench-subnet \ --disable-public-ip \ --service-account-email=workbench-sa@$projectid.iam.gserviceaccount.com在 Google Cloud 控制台中,前往 Vertex AI Workbench 页面上的实例标签页。
在 Vertex AI Workbench 实例名称 (
workbench-tutorial) 旁边,点击打开 JupyterLab。您的 Vertex AI Workbench 实例会打开 JupyterLab。
选择文件 > 新建 > 笔记本。
在选择内核菜单中,选择 Python 3(本地),然后点击选择。
当您的新笔记本打开时,有一个默认代码单元,您可以在其中输入代码。它类似于
[ ]:,后跟一个文本字段。您的代码将粘贴到该文本字段中。如需安装 Vertex AI SDK for Python,请将以下代码粘贴到相应单元中,然后点击 运行所选单元并前进:
!pip3 install --upgrade google-cloud-bigquery scikit-learn==1.2在此步骤以及下面的每个步骤中,点击 在下方插入单元以添加新的代码单元(如有必要),将代码粘贴到该单元中,然后点击 运行所选单元并前进。
如需在此 Jupyter 运行时中使用新安装的软件包,您需要重启运行时:
# Restart kernel after installs so that your environment can access the new packages import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True)在 JupyterLab 笔记本中设置以下环境变量,并将 PROJECT_ID 替换为您的项目 ID。
# set project ID and location PROJECT_ID = "PROJECT_ID" REGION = "us-central1"创建一个 Cloud Storage 存储桶以暂存训练作业:
BUCKET_NAME = f"{PROJECT_ID}-ml-staging" BUCKET_URI = f"gs://{BUCKET_NAME}" !gcloud storage buckets create {BUCKET_URI} --location={REGION} --project={PROJECT_ID}
准备训练数据
在本部分中,您将准备用于训练推理模型的数据。
在 JupyterLab 笔记本中,创建一个 BigQuery 客户端:
from google.cloud import bigquery bq_client = bigquery.Client(project=PROJECT_ID)从 BigQuery
ml_datasets公共数据集中提取数据:DATA_SOURCE = "bigquery-public-data.ml_datasets.census_adult_income" # Define the SQL query to fetch the dataset query = f""" SELECT * FROM `{DATA_SOURCE}` LIMIT 20000 """ # Download the dataset to a dataframe df = bq_client.query(query).to_dataframe() df.head()使用
sklearn库拆分数据以用于训练和测试:from sklearn.model_selection import train_test_split # Split the dataset X_train, X_test = train_test_split(df, test_size=0.3, random_state=43) # Print the shapes of train and test sets print(X_train.shape, X_test.shape)将训练和测试 DataFrame 导出到暂存存储桶中的 CSV 文件:
X_train.to_csv(f"{BUCKET_URI}/train.csv",index=False, quoting=1, quotechar='"') X_test[[i for i in X_test.columns if i != "income_bracket"]].iloc[:20].to_csv(f"{BUCKET_URI}/test.csv",index=False,quoting=1, quotechar='"')
准备训练应用
在本部分中,您将创建并构建 Python 训练应用,并将其保存到暂存存储桶中。
在 JupyterLab 笔记本中,为训练应用文件创建一个新文件夹:
!mkdir -p training_package/trainer现在,您应该会在 JupyterLab 导航菜单中看到名为
training_package的文件夹。定义用于训练模型并将模型导出到文件的特征、目标、标签和步骤:
%%writefile training_package/trainer/task.py from sklearn.ensemble import RandomForestClassifier from sklearn.feature_selection import SelectKBest from sklearn.pipeline import FeatureUnion, Pipeline from sklearn.preprocessing import LabelBinarizer import pandas as pd import argparse import joblib import os TARGET = "income_bracket" # Define the feature columns that you use from the dataset COLUMNS = ( "age", "workclass", "functional_weight", "education", "education_num", "marital_status", "occupation", "relationship", "race", "sex", "capital_gain", "capital_loss", "hours_per_week", "native_country", ) # Categorical columns are columns that have string values and # need to be turned into a numerical value to be used for training CATEGORICAL_COLUMNS = ( "workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country", ) # load the arguments parser = argparse.ArgumentParser() parser.add_argument('--training-dir', dest='training_dir', default=os.getenv('AIP_MODEL_DIR'), type=str,help='get the staging directory') args = parser.parse_args() # Load the training data X_train = pd.read_csv(os.path.join(args.training_dir,"train.csv")) # Remove the column we are trying to predict ('income-level') from our features list # Convert the Dataframe to a lists of lists train_features = X_train.drop(TARGET, axis=1).to_numpy().tolist() # Create our training labels list, convert the Dataframe to a lists of lists train_labels = X_train[TARGET].to_numpy().tolist() # Since the census data set has categorical features, we need to convert # them to numerical values. We'll use a list of pipelines to convert each # categorical column and then use FeatureUnion to combine them before calling # the RandomForestClassifier. categorical_pipelines = [] # Each categorical column needs to be extracted individually and converted to a numerical value. # To do this, each categorical column will use a pipeline that extracts one feature column via # SelectKBest(k=1) and a LabelBinarizer() to convert the categorical value to a numerical one. # A scores array (created below) will select and extract the feature column. The scores array is # created by iterating over the COLUMNS and checking if it is a CATEGORICAL_COLUMN. for i, col in enumerate(COLUMNS): if col in CATEGORICAL_COLUMNS: # Create a scores array to get the individual categorical column. # Example: # data = [39, 'State-gov', 77516, 'Bachelors', 13, 'Never-married', 'Adm-clerical', # 'Not-in-family', 'White', 'Male', 2174, 0, 40, 'United-States'] # scores = [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] # # Returns: [['Sate-gov']] scores = [] # Build the scores array for j in range(len(COLUMNS)): if i == j: # This column is the categorical column we want to extract. scores.append(1) # Set to 1 to select this column else: # Every other column should be ignored. scores.append(0) skb = SelectKBest(k=1) skb.scores_ = scores # Convert the categorical column to a numerical value lbn = LabelBinarizer() r = skb.transform(train_features) lbn.fit(r) # Create the pipeline to extract the categorical feature categorical_pipelines.append( ( "categorical-{}".format(i), Pipeline([("SKB-{}".format(i), skb), ("LBN-{}".format(i), lbn)]), ) ) # Create pipeline to extract the numerical features skb = SelectKBest(k=6) # From COLUMNS use the features that are numerical skb.scores_ = [1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0] categorical_pipelines.append(("numerical", skb)) # Combine all the features using FeatureUnion preprocess = FeatureUnion(categorical_pipelines) # Create the classifier classifier = RandomForestClassifier() # Transform the features and fit them to the classifier classifier.fit(preprocess.transform(train_features), train_labels) # Create the overall model as a single pipeline pipeline = Pipeline([("union", preprocess), ("classifier", classifier)]) # Save the model pipeline joblib.dump(pipeline, os.path.join(args.training_dir,"model.joblib"))在每个子目录中创建一个
__init__.py文件,使其成为软件包:!touch training_package/__init__.py !touch training_package/trainer/__init__.py创建 Python 软件包设置脚本:
%%writefile training_package/setup.py from setuptools import find_packages from setuptools import setup setup( name='trainer', version='0.1', packages=find_packages(), include_package_data=True, description='Training application package for census income classification.' )使用
sdist命令创建训练应用的源代码分发:!cd training_package && python setup.py sdist --formats=gztar将 Python 软件包复制到暂存存储桶:
!gcloud storage cp training_package/dist/trainer-0.1.tar.gz $BUCKET_URI/验证暂存存储桶是否包含三个文件:
!gcloud storage ls $BUCKET_URI输出应如下所示:
gs://$BUCKET_NAME/test.csv gs://$BUCKET_NAME/train.csv gs://$BUCKET_NAME/trainer-0.1.tar.gz
训练模型
在本部分中,您将通过创建和运行自定义训练作业来训练模型。
在 JupyterLab 笔记本中,运行以下命令以创建自定义训练作业:
!gcloud ai custom-jobs create --display-name=income-classification-training-job \ --project=$PROJECT_ID \ --worker-pool-spec=replica-count=1,machine-type='e2-highmem-2',executor-image-uri='us-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest',python-module=trainer.task \ --python-package-uris=$BUCKET_URI/trainer-0.1.tar.gz \ --args="--training-dir","/gcs/$BUCKET_NAME" \ --region=$REGION输出应如下所示。每个自定义作业路径中的第一个编号都是项目编号 (PROJECT_NUMBER)。第二个编号是自定义作业 ID (CUSTOM_JOB_ID)。请记下这些编号,以便在下一步中使用它们。
Using endpoint [https://us-central1-aiplatform.googleapis.com/] CustomJob [projects/721032480027/locations/us-central1/customJobs/1100328496195960832] is submitted successfully. Your job is still active. You may view the status of your job with the command $ gcloud ai custom-jobs describe projects/721032480027/locations/us-central1/customJobs/1100328496195960832 or continue streaming the logs with the command $ gcloud ai custom-jobs stream-logs projects/721032480027/locations/us-central1/customJobs/1100328496195960832运行自定义训练作业,并通过从作业中流式传输日志来显示进度(作业运行时):
!gcloud ai custom-jobs stream-logs projects/PROJECT_NUMBER/locations/us-central1/customJobs/CUSTOM_JOB_ID替换以下值:
- PROJECT_NUMBER:上一个命令的输出中的项目编号
- CUSTOM_JOB_ID:上一个命令的输出中的自定义作业 ID
自定义训练作业现已运行。该作业大约需要 10 分钟才能完成。
作业完成后,您可以将模型从暂存存储桶导入 Vertex AI Model Registry。
导入模型
自定义训练作业会将经过训练的模型上传到暂存存储桶。作业完成后,您可以将模型从该存储桶导入 Vertex AI Model Registry。
在 JupyterLab 笔记本中,运行以下命令以导入模型:
!gcloud ai models upload --container-image-uri="us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-2:latest" \ --display-name=income-classifier-model \ --artifact-uri=$BUCKET_URI \ --project=$PROJECT_ID \ --region=$REGION列出项目中的 Vertex AI 模型,如下所示:
!gcloud ai models list --region=us-central1输出应如下所示。如果列出了两个或更多模型,则列表中的第一个模型是您最近导入的模型。
请记下 MODEL_ID 列中的值。您需要使用该值来创建批量推理请求。
Using endpoint [https://us-central1-aiplatform.googleapis.com/] MODEL_ID DISPLAY_NAME 1871528219660779520 income-classifier-model或者,您也可以按如下方式列出项目中的模型:
在 Google Cloud 控制台的 Vertex AI 部分中,前往 Vertex AI Model Registry 页面。
进入 Vertex AI Model Registry 页面
如需查看模型的 ID 和其他详细信息,请点击模型名称,然后点击版本详情标签页。
从模型获取批量推理结果
现在,您可以通过模型请求批量推理。批量推理请求是从 on-prem-client 虚拟机实例发出的。
创建批量推理请求
在此步骤中,您将使用 ssh 登录 on-prem-client 虚拟机实例。
在虚拟机实例中,您将创建一个名为 request.json 的文本文件,其中包含您向模型发送以进行批量推理的示例 curl 请求的载荷。
在 Cloud Shell 中,运行以下命令,并将 PROJECT_ID 替换为您的项目 ID:
projectid=PROJECT_ID gcloud config set project ${projectid}使用
ssh登录on-prem-client虚拟机实例:gcloud compute ssh on-prem-client \ --project=$projectid \ --zone=us-central1-a在
on-prem-client虚拟机实例中,使用文本编辑器(例如vim或nano)创建一个名为request.json的新文件,其中包含以下文本:{ "displayName": "income-classification-batch-job", "model": "projects/PROJECT_ID/locations/us-central1/models/MODEL_ID", "inputConfig": { "instancesFormat": "csv", "gcsSource": { "uris": ["BUCKET_URI/test.csv"] } }, "outputConfig": { "predictionsFormat": "jsonl", "gcsDestination": { "outputUriPrefix": "BUCKET_URI" } }, "dedicatedResources": { "machineSpec": { "machineType": "n1-standard-4", "acceleratorCount": "0" }, "startingReplicaCount": 1, "maxReplicaCount": 2 } }替换以下值:
- PROJECT_ID:您的项目 ID
- MODEL_ID:您的模型 ID
- BUCKET_URI:您在其中暂存模型的存储桶的 URI
运行以下命令以发送批量推理请求:
curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ -d @request.json \ "https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/batchPredictionJobs"将 PROJECT_ID 替换为您的项目 ID。
您应该会在响应中看到以下行:
"state": "JOB_STATE_PENDING"批量推理作业现已异步运行。运行该作业大约需要 20 分钟。
在 Google Cloud 控制台的 Vertex AI 部分中,前往批量预测页面。
当批量推理作业正在运行时,其状态为
Running。作业完成后,其状态会变为Finished。点击批量推理作业的名称 (
income-classification-batch-job),然后点击详情页面中的导出位置链接,以查看 Cloud Storage 中批量作业的输出文件。或者,您也可以点击 查看 Cloud Storage 上的预测输出图标(位于上次更新时间列和 操作菜单之间)。
点击
prediction.results-00000-of-00002或prediction.results-00001-of-00002文件链接,然后点击要求验证身份的网址链接以打开该文件。批量推理作业输出应如以下示例所示:
{"instance": ["27", " Private", "391468", " 11th", "7", " Divorced", " Craft-repair", " Own-child", " White", " Male", "0", "0", "40", " United-States"], "prediction": " <=50K"} {"instance": ["47", " Self-emp-not-inc", "192755", " HS-grad", "9", " Married-civ-spouse", " Machine-op-inspct", " Wife", " White", " Female", "0", "0", "20", " United-States"], "prediction": " <=50K"} {"instance": ["32", " Self-emp-not-inc", "84119", " HS-grad", "9", " Married-civ-spouse", " Craft-repair", " Husband", " White", " Male", "0", "0", "45", " United-States"], "prediction": " <=50K"} {"instance": ["32", " Private", "236543", " 12th", "8", " Divorced", " Protective-serv", " Own-child", " White", " Male", "0", "0", "54", " Mexico"], "prediction": " <=50K"} {"instance": ["60", " Private", "160625", " HS-grad", "9", " Married-civ-spouse", " Prof-specialty", " Husband", " White", " Male", "5013", "0", "40", " United-States"], "prediction": " <=50K"} {"instance": ["34", " Local-gov", "22641", " HS-grad", "9", " Never-married", " Protective-serv", " Not-in-family", " Amer-Indian-Eskimo", " Male", "0", "0", "40", " United-States"], "prediction": " <=50K"} {"instance": ["32", " Private", "178623", " HS-grad", "9", " Never-married", " Other-service", " Not-in-family", " Black", " Female", "0", "0", "40", " ?"], "prediction": " <=50K"} {"instance": ["28", " Private", "54243", " HS-grad", "9", " Divorced", " Transport-moving", " Not-in-family", " White", " Male", "0", "0", "60", " United-States"], "prediction": " <=50K"} {"instance": ["29", " Local-gov", "214385", " 11th", "7", " Divorced", " Other-service", " Unmarried", " Black", " Female", "0", "0", "20", " United-States"], "prediction": " <=50K"} {"instance": ["49", " Self-emp-inc", "213140", " HS-grad", "9", " Married-civ-spouse", " Exec-managerial", " Husband", " White", " Male", "0", "1902", "60", " United-States"], "prediction": " >50K"}