Verwenden Sie die Batchbereitstellung, um Featuredaten für das Modelltraining abzurufen. Wenn Sie Featurewerte für die Archivierung oder Ad-hoc-Analyse exportieren müssen, exportieren Sie stattdessen Featurewerte.
Featurewerte für das Modelltraining abrufen
Für das Modelltraining benötigen Sie ein Trainings-Dataset, das Beispiele für Ihre Vorhersageaufgabe enthält. Diese Beispiele bestehen aus Instanzen, die ihre Features und Labels enthalten. Die Instanz ist das Element, für das Sie eine Vorhersage treffen möchten. Beispiel: Eine Instanz ist möglicherweise ein Haus und Sie möchten seinen Marktwert ermitteln. Zu den Features können der Standort, das Alter und der durchschnittliche Preis von Häusern in der Nähe gehören, die vor Kurzem verkauft wurden. Ein Label ist eine Antwort auf die Vorhersageaufgabe, z. B. das Haus, das letztendlich für 100.000 $ verkauft wird.
Da jedes Label eine Beobachtung zu einem bestimmten Zeitpunkt ist, müssen Sie Featurewerte abrufen, die sich auf den Zeitpunkt der Beobachtung beziehen, also beispielsweise die Preise von Häusern in der Umgebung, als ein bestimmtes Haus verkauft wurde. Beim Erfassen von Labels und Featurewerten im Zeitverlauf ändern sich diese Featurewerte. Vertex AI Feature Store (Legacy) kann eine Suche zu einer bestimmten Zeit ausführen, sodass Sie die Featurewerte zu diesem Zeitpunkt abrufen können.
Beispielsuche zu einem bestimmten Zeitpunkt
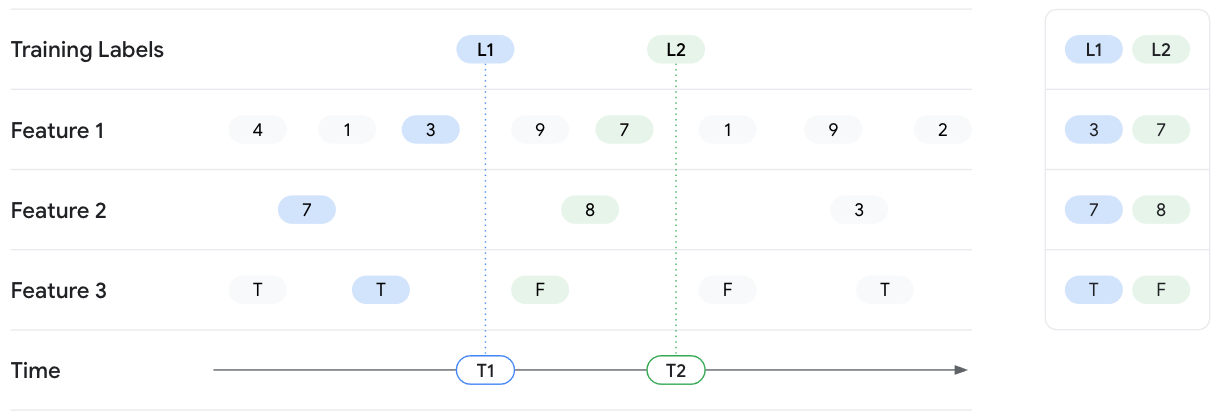
Das folgende Beispiel umfasst das Abrufen von Featurewerten für zwei Trainingsinstanzen mit den Labels L1 und L2. Die beiden Labels werden unter T1 bzw. T2 angezeigt. Stellen Sie sich vor, den Zustand der Featurewerte an diesen Zeitstempeln einzufrieren. Bei der Suche nach einem bestimmten Zeitpunkt bei T1 gibt Vertex AI Feature Store (Legacy) die neuesten Featurewerte bis zum Zeitpunkt T1 für Feature 1, Feature 2 und Feature 3 zurück, gibt aber keine Werte nach T1 weiter. Mit der Zeit ändern sich die Featurewerte und das Label. Bei T2 gibt Feature Store also unterschiedliche Featurewerte für diesen Zeitpunkt zurück.
Batchbereitstellungseingaben
Bei einer Batchbereitstellungsanfrage sind folgende Informationen erforderlich:
- Eine Liste der Features, für die Werte abgerufen werden sollen.
- Eine Liste mit Leseinstanzen, die Informationen für jedes Trainingsbeispiel enthält.
Darin werden Beobachtungen zu einem bestimmten Zeitpunkt aufgelistet. Dies kann entweder eine CSV-Datei oder eine BigQuery-Tabelle sein. Die Liste muss die folgenden Informationen enthalten:
- Zeitstempel: Die Zeiten, zu denen Labels beobachtet oder gemessen wurden. Die Zeitstempel sind erforderlich, damit Vertex AI Feature Store (Legacy) eine Suche zu einem bestimmten Zeitpunkt ausführen kann.
- Entitäts-IDs: Eine oder mehrere IDs der Entitäten, die dem Label entsprechen.
- Das Ziel-URI und sein Format, in das die Ausgabe geschrieben wird. In der Ausgabe führt Vertex AI Feature Store (Legacy) im Grunde die Tabelle der "read instances list" mit den Featurewerten aus dem Featurestore zusammen. Geben Sie eines der folgenden Formate und Speicherorte für die Ausgabe an:
- BigQuery-Tabelle in einem regionalen oder multiregionalen Dataset
- CSV-Datei in einem regionalen oder multiregionalen Cloud Storage-Bucket. Wenn Ihre Featurewerte jedoch Arrays enthalten, müssen Sie ein anderes Format auswählen.
- Tfrecord-Datei in einem Cloud Storage-Bucket.
Anforderungen an die Region
Sowohl für Leseinstanzen als auch für das Ziel muss sich das Quell-Dataset oder der Quell-Bucket in derselben Region oder am selben multiregionalen Standort wie Ihr Featurestore befinden. Beispielsweise kann ein Featurestore in us-central1 nur Daten aus Cloud Storage-Buckets oder BigQuery-Datasets in us-central1 oder am multiregionalen Standort „US“ lesen oder dorthin bereitstellen. Sie können keine Daten von beispielsweise us-east1 verwenden. Außerdem wird das Lesen oder Bereitstellen von Daten mit Dual-Region-Buckets nicht unterstützt.
Read-instance-Liste
Die Liste der Leseinstanzen gibt die Entitäten und Zeitstempel für die Featurewerte an, die Sie abrufen möchten. Die CSV-Datei oder die BigQuery-Tabelle muss die folgenden Spalten in beliebiger Reihenfolge enthalten. Jede Spalte erfordert eine Spaltenüberschrift.
- Sie müssen eine Zeitstempelspalte hinzufügen, bei der der Headername
timestampist und die Spaltenwerte Zeitstempel im RFC 3339-Format sind. - Sie müssen mindestens eine Spalte für den Entitätstyp einbeziehen, deren Header die ID des Entitätstyps ist und die Spaltenwerte die Entitäts-IDs sind.
- Optional können Sie Pass-Through-Werte (zusätzliche Spalten) einfügen, die unverändert an die Ausgabe übergeben werden. Dies ist nützlich, wenn Sie Daten haben, die sich nicht in Vertex AI Feature Store (Legacy) befinden, sie diese Daten aber in die Ausgabe aufnehmen möchten.
CSV-Beispieldatei
Stellen Sie sich einen Feature Store vor, der die Entitätstypen users und movies sowie deren Features enthält. Beispielsweise können Features für users age und gender enthalten, Features für movies hingegen ratings und genre.
In diesem Beispiel möchten Sie Trainingsdaten zu den Filmpräferenzen der Nutzer erfassen. Sie rufen Featurewerte für die beiden Nutzerentitäten alice und bob zusammen mit Features aus den von ihnen angesehenen Filmen ab. Aus einem separaten Dataset wissen Sie, dass alice movie_01 angesehen und ihr der Film gefallen hat. bob hat movie_02 angesehen und der Film hat ihm nicht gefallen. Die Liste der Leseinstanzen könnte also so aussehen:
users,movies,timestamp,liked "alice","movie_01",2021-04-15T08:28:14Z,true "bob","movie_02",2021-04-15T08:28:14Z,false
Vertex AI Feature Store (Legacy) ruft Featurewerte für die aufgeführten Entitäten mit oder vor den angegebenen Zeitstempeln ab. Sie geben die spezifischen Features, die abgerufen werden sollen, als Teil der Batchbereitstellungsanfrage an, nicht in der Liste der Leseinstanzen.
Dieses Beispiel enthält auch eine Spalte namens liked, die angibt, ob einem Nutzer ein Film gefallen hat. Diese Spalte ist nicht im Feature Store enthalten, Sie können diese Werte jedoch weiterhin an die Batchbereitstellungsausgabe übergeben. In der Ausgabe werden diese Pass-Through-Werte mit den Werten aus dem Featurestore zusammengeführt.
Nullwerte
Wenn bei einem bestimmten Zeitstempel ein Featurewert null ist, gibt Vertex AI Feature Store (Legacy) den vorherigen Nicht-Null-Featurewert zurück. Wenn keine vorherigen Werte vorhanden sind, gibt Vertex AI Feature Store (Legacy) null zurück.
Featurewerte für die Batchbereitstellung
Stellen Sie zum Abrufen von Daten Featurewerte aus einem Feature Store im Batch bereit, gemäß der Liste mit den Leseinstanzen.
Wenn Sie die Offline-Speichernutzungskosten durch das Lesen aktueller Trainingsdaten und den Ausschluss alter Daten senken möchten, geben Sie eine Startzeit an. Informationen zum Senken der Kosten für die Offlinespeichernutzung durch Angabe einer Startzeit finden Sie unter Startzeit für die Optimierung der Offlinespeicherkosten während Batchbereitstellung und Batch-Export angeben.
Web-UI
Verwenden Sie eine andere Methode. Sie können Features nicht über dieGoogle Cloud Console im Batch bereitstellen.
REST
Senden Sie zum Bereitstellen von Featurewerten in Batches eine POST-Anfrage mit der Methode featurestores.batchReadFeatureValues.
Im folgenden Beispiel wird eine BigQuery-Tabelle ausgegeben, die Featurewerte für die Entitätstypen users und movies enthält. Für jedes Ausgabeziel gelten möglicherweise einige Voraussetzungen, bevor Sie eine Anfrage senden können. Wenn Sie beispielsweise einen Tabellennamen für das Feld bigqueryDestination angeben, benötigen Sie ein vorhandenes Dataset. Diese Anforderungen sind in der API-Referenz dokumentiert.
Ersetzen Sie dabei folgende Werte für die Anfragedaten:
- LOCATION_ID: Region, in der der Featurestore erstellt wird. Beispiel:
us-central1. - PROJECT_ID: Ihre Projekt-ID.
- FEATURESTORE_ID: ID des Featurestores.
- DATASET_NAME: Name des BigQuery-Ziel-Datasets.
- TABLE_NAME: Name der BigQuery-Zieltabelle.
- STORAGE_LOCATION: Cloud Storage-URI zur CSV-Datei "read-instances".
HTTP-Methode und URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/featurestores/FEATURESTORE_ID:batchReadFeatureValues
JSON-Text der Anfrage:
{
"destination": {
"bigqueryDestination": {
"outputUri": "bq://PROJECT_ID.DATASET_NAME.TABLE_NAME"
}
},
"csvReadInstances": {
"gcsSource": {
"uris": ["STORAGE_LOCATION"]
}
},
"entityTypeSpecs": [
{
"entityTypeId": "users",
"featureSelector": {
"idMatcher": {
"ids": ["age", "liked_genres"]
}
}
},
{
"entityTypeId": "movies",
"featureSelector": {
"idMatcher": {
"ids": ["title", "average_rating", "genres"]
}
}
}
],
"passThroughFields": [
{
"fieldName": "liked"
}
]
}
Wenn Sie die Anfrage senden möchten, wählen Sie eine der folgenden Optionen aus:
curl
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/featurestores/FEATURESTORE_ID:batchReadFeatureValues"
PowerShell
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/featurestores/FEATURESTORE_ID:batchReadFeatureValues" | Select-Object -Expand Content
Die Ausgabe sieht in etwa so aus: Sie können OPERATION_ID in der Antwort verwenden, um den Status des Vorgangs abzurufen.
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION_ID/featurestores/FEATURESTORE_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.BatchReadFeatureValuesOperationMetadata",
"genericMetadata": {
"createTime": "2021-03-02T00:03:41.558337Z",
"updateTime": "2021-03-02T00:03:41.558337Z"
}
}
}
Python
Informationen zur Installation des Vertex AI SDK for Python finden Sie unter Vertex AI SDK for Python installieren. Weitere Informationen finden Sie in der Python-API-Referenzdokumentation.
Weitere Sprachen
Sie können die folgenden Vertex AI-Clientbibliotheken installieren und sie verwenden, um die Vertex AI API aufzurufen. Cloud-Clientbibliotheken erleichtern Entwicklern die Programmierung, da die natürlichen Konventionen und Stile der jeweils unterstützten Sprache verwendet werden.
Batchbereitstellungsjobs ansehen
Verwenden Sie die Google Cloud Console, um Batchbereitstellungsjobs in einemGoogle Cloud -Projekt anzusehen.
Web-UI
- Rufen Sie im Bereich „Vertex AI“ der Google Cloud Console die Seite Features auf.
- Wählen Sie eine Region aus der Drop-down-Liste Region aus.
- Klicken Sie in der Aktionsleiste auf Batchbereitstellungsjobs ansehen, um Batchbereitstellungsjobs für alle Feature Stores aufzulisten.
- Klicken Sie auf die ID eines Batchbereitstellungsjobs, um die zugehörigen Details anzusehen, z. B. die verwendete Quell-Leseinstanz und das Ausgabeziel.
Nächste Schritte
- Featurewerte im Batchverfahren aufnehmen
- Features über die Onlinebereitstellung bereitstellen
- Sehen Sie sich das Kontingent für gleichzeitige Batchjobs von Vertex AI Feature Store (Legacy) an.
- Fehlerbehebung bei häufigen Problemen mit Vertex AI Feature Store (Legacy)