Per recuperare i dati delle funzionalità per l'addestramento del modello, utilizza recupero dati in batch. Se devi esportare i valori delle caratteristiche per l'archiviazione o l'analisi ad hoc, esporta i valori delle caratteristiche.
Recuperare i valori delle caratteristiche per l'addestramento del modello
Per l'addestramento del modello, è necessario un set di dati di addestramento che contenga esempi dell'attività di previsione. Questi esempi sono costituiti da istanze che includono le relative caratteristiche ed etichette. L'istanza è l'elemento su cui vuoi fare una previsione. Ad esempio, un'istanza potrebbe essere una casa e vuoi determinarne il valore di mercato. Le sue caratteristiche potrebbero includere la posizione, l'età e il prezzo medio delle case vicine vendute di recente. Un'etichetta è una risposta per l'attività di previsione, ad esempio la casa è stata venduta per 100.000 $.
Poiché ogni etichetta è un'osservazione in un momento specifico, devi recuperare i valori delle funzionalità che corrispondono a quel momento in cui è stata effettuata l'osservazione, ad esempio i prezzi delle case vicine quando è stata venduta una casa in particolare. Man mano che le etichette e i valori delle caratteristiche vengono raccolti nel tempo, questi valori delle caratteristiche cambiano. Vertex AI Feature Store (legacy) può eseguire una ricerca point-in-time in modo da poter recuperare i valori delle caratteristiche in un momento specifico.
Esempio di ricerca point-in-time
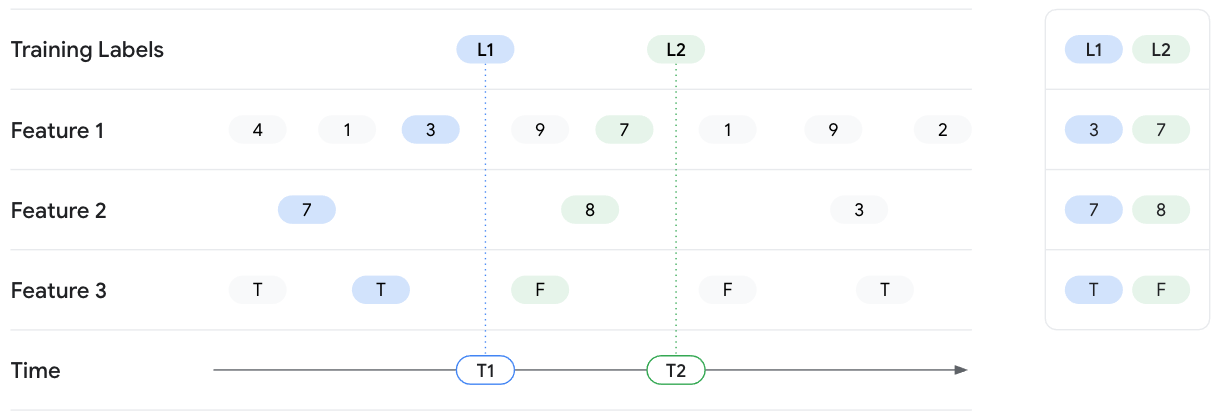
L'esempio seguente prevede il recupero dei valori delle funzionalità per due istanze di training con le etichette L1 e L2. Le due etichette vengono osservate rispettivamente a T1 e T2. Immagina di bloccare lo stato dei valori delle caratteristiche in corrispondenza di questi
timestamp. Pertanto, per la ricerca point-in-time alle ore T1,
Vertex AI Feature Store (legacy) restituisce i valori delle caratteristiche più recenti fino alle ore T1
per Feature 1, Feature 2 e Feature 3 e non rivela alcun valore successivo
alle ore T1. Con il passare del tempo, i valori delle funzionalità cambiano e cambia anche l'etichetta. Pertanto, alle ore T2, Feature Store restituisce valori delle caratteristiche diversi per quel
momento.
Input di recupero di dati in batch
Come parte di una richiesta di recupero dati in batch, sono necessarie le seguenti informazioni:
- Un elenco di caratteristiche esistenti per le quali ottenere i valori.
- Un elenco di istanze di lettura che contiene informazioni per ogni esempio di addestramento.
Elenca le osservazioni in un determinato momento. Può trattarsi di un file CSV
o di una tabella BigQuery. L'elenco deve includere le seguenti
informazioni:
- Timestamp: gli orari in cui sono state osservate o misurate le etichette. I timestamp sono necessari per consentire a Vertex AI Feature Store (legacy) di eseguire una ricerca in un momento specifico.
- ID entità: uno o più ID delle entità che corrispondono all'etichetta.
- L'URI di destinazione e il formato in cui viene scritto l'output. Nell'output,
Vertex AI Feature Store (legacy) unisce essenzialmente la tabella dall'elenco
delle istanze lette e i valori delle caratteristiche dall'archivio di caratteristiche. Specifica uno dei seguenti formati e posizioni per l'output:
- Tabella BigQuery in un set di dati regionale o multiregionale.
- File CSV in un bucket Cloud Storage regionale o multiregionale. Ma se i valori delle caratteristiche includono array, devi scegliere un altro formato.
- File Tfrecord in un bucket Cloud Storage.
Requisiti per le regioni
Per le istanze di lettura e la destinazione, il
set di dati o il bucket di origine deve trovarsi nella stessa regione o nella stessa
posizione multiregionale del feature store. Ad esempio, un featurestore in
us-central1 può leggere o pubblicare dati solo da bucket Cloud Storage
o set di dati BigQuery che si trovano in us-central1 o nella località multiregionale
Stati Uniti. Non puoi utilizzare dati provenienti, ad esempio, da us-east1. Inoltre,
la lettura o la pubblicazione di dati utilizzando bucket a due regioni non è supportata.
Elenco delle istanze di lettura
L'elenco delle istanze di lettura specifica le entità e i timestamp per i valori delle caratteristiche che vuoi recuperare. Il file CSV o la tabella BigQuery deve contenere le seguenti colonne, in qualsiasi ordine. Ogni colonna richiede un'intestazione.
- Devi includere una colonna timestamp, in cui il nome dell'intestazione è
timestampe i valori della colonna sono timestamp nel formato RFC 3339. - Devi includere una o più colonne del tipo di entità, in cui l'intestazione è l'ID del tipo di entità e i valori delle colonne sono gli ID entità.
- (Facoltativo) Puoi includere valori pass-through (colonne aggiuntive), che vengono passati così come sono all'output. Ciò è utile se hai dati che non si trovano in Vertex AI Feature Store (legacy), ma vuoi includerli nell'output.
Esempio (CSV)
Immagina un featurestore che contenga i tipi di entità users e movies insieme
alle loro caratteristiche. Ad esempio, le funzionalità per users potrebbero includere age e
gender, mentre quelle per movies potrebbero includere ratings e genre.
Per questo esempio, vuoi raccogliere dati di addestramento sulle preferenze cinematografiche degli utenti. Recuperi i valori delle caratteristiche per le due entità utente alice e
bob insieme alle caratteristiche dei film che hanno guardato. Da un set di dati separato,
sai che alice ha guardato movie_01 e ha messo Mi piace. bob ha guardato movie_02
e non gli è piaciuto. Pertanto, l'elenco delle istanze di lettura potrebbe avere il seguente aspetto:
users,movies,timestamp,liked "alice","movie_01",2021-04-15T08:28:14Z,true "bob","movie_02",2021-04-15T08:28:14Z,false
Vertex AI Feature Store (legacy) recupera i valori delle caratteristiche per le entità elencate in corrispondenza o prima dei timestamp specificati. Specifichi le funzionalità specifiche da ottenere come parte della richiestarecupero dati in batchh, non nell'elenco delle istanze di lettura.
Questo esempio include anche una colonna denominata liked, che indica se un utente ha messo Mi piace a un film. Questa colonna non è inclusa nello store delle funzionalità, ma puoi comunque passare questi valori all'output del recupero dati in batch. Nell'output, questi
valori pass-through vengono uniti ai valori dell'archivio di caratteristiche.
Valori null
Se, in un determinato timestamp, un valore della funzionalità è nullo, Vertex AI Feature Store (legacy) restituisce il valore della funzionalità precedente non nullo. Se non sono presenti valori precedenti, Vertex AI Feature Store (legacy) restituisce null.
Recupera i valori delle caratteristiche in batch
Esegui il servizio batch dei valori delle caratteristiche da un archivio di caratteristiche per ottenere i dati, come determinato dal file dell'elenco delle istanze di lettura.
Se vuoi ridurre i costi di utilizzo dello spazio di archiviazione offline leggendo i dati di addestramento recenti ed escludendo i dati precedenti, specifica un orario di inizio. Per scoprire come ridurre i costi di utilizzo dello spazio di archiviazione offline specificando un orario di inizio, consulta Specificare un orario di inizio per ottimizzare i costi dello spazio di archiviazione offline durante la pubblicazione batch e l'esportazione batch.
UI web
Utilizza un altro metodo. Non puoi recuperare le caratteristiche in batch dalla consoleGoogle Cloud .
REST
Per recuperare in batch i valori delle caratteristiche, invia una richiesta POST utilizzando il metodo featurestores.batchReadFeatureValues.
Il seguente esempio restituisce una tabella BigQuery che contiene valori delle funzionalità
per i tipi di entità users e movies. Tieni presente
che ogni destinazione di output potrebbe avere alcuni prerequisiti prima di poter inviare
una richiesta. Ad esempio, se specifichi un nome tabella per il campo
bigqueryDestination, devi disporre di un set di dati esistente. Questi
requisiti sono documentati nel riferimento API.
Prima di utilizzare i dati della richiesta, apporta le seguenti sostituzioni:
- LOCATION_ID: Regione in cui viene creato lo store delle funzionalità. Ad esempio,
us-central1. - PROJECT_ID: il tuo ID progetto
- FEATURESTORE_ID: ID dello store di funzionalità.
- DATASET_NAME: nome del set di dati BigQuery di destinazione.
- TABLE_NAME: nome della tabella BigQuery di destinazione.
- STORAGE_LOCATION: URI Cloud Storage del file CSV read-instances.
Metodo HTTP e URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/featurestores/FEATURESTORE_ID:batchReadFeatureValues
Corpo JSON della richiesta:
{
"destination": {
"bigqueryDestination": {
"outputUri": "bq://PROJECT_ID.DATASET_NAME.TABLE_NAME"
}
},
"csvReadInstances": {
"gcsSource": {
"uris": ["STORAGE_LOCATION"]
}
},
"entityTypeSpecs": [
{
"entityTypeId": "users",
"featureSelector": {
"idMatcher": {
"ids": ["age", "liked_genres"]
}
}
},
{
"entityTypeId": "movies",
"featureSelector": {
"idMatcher": {
"ids": ["title", "average_rating", "genres"]
}
}
}
],
"passThroughFields": [
{
"fieldName": "liked"
}
]
}
Per inviare la richiesta, scegli una di queste opzioni:
curl
Salva il corpo della richiesta in un file denominato request.json,
ed esegui questo comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/featurestores/FEATURESTORE_ID:batchReadFeatureValues"
PowerShell
Salva il corpo della richiesta in un file denominato request.json,
ed esegui questo comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/featurestores/FEATURESTORE_ID:batchReadFeatureValues" | Select-Object -Expand Content
Dovresti vedere un output simile al seguente. Puoi utilizzare OPERATION_ID nella risposta per ottenere lo stato dell'operazione.
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION_ID/featurestores/FEATURESTORE_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.BatchReadFeatureValuesOperationMetadata",
"genericMetadata": {
"createTime": "2021-03-02T00:03:41.558337Z",
"updateTime": "2021-03-02T00:03:41.558337Z"
}
}
}
Python
Per scoprire come installare o aggiornare l'SDK Vertex AI Python, consulta Installare l'SDK Vertex AI Python. Per saperne di più, consulta la documentazione di riferimento dell'API Python.
Linguaggi aggiuntivi
Puoi installare e utilizzare le seguenti librerie client di Vertex AI per chiamare l'API Vertex AI. Le librerie client di Cloud offrono un'esperienza ottimizzata per gli sviluppatori utilizzando gli stili e le convenzioni naturali di ogni linguaggio supportato.
Visualizza i job di recupero dati in batch
Utilizza la console Google Cloud per visualizzare i job di recupero dati in batch in un progettoGoogle Cloud .
UI web
- Nella sezione Vertex AI della console Google Cloud , vai alla pagina Funzionalità.
- Seleziona una regione dall'elenco a discesa Regione.
- Dalla barra delle azioni, fai clic su Visualizza recupero dati in batch batch per elencare i job di pubblicazione batch per tutti gli store di funzionalità.
- Fai clic sull'ID di un job di recupero dati in batch per visualizzarne i dettagli, ad esempio l'origine dell'istanza di lettura utilizzata e la destinazione di output.
Passaggi successivi
- Scopri come importare in batch i valori delle caratteristiche.
- Scopri come pubblicare funzionalità tramite la pubblicazione online.
- Visualizza la quota di job batch simultanei di Vertex AI Feature Store (legacy).
- Risolvi i problemi comuni di Vertex AI Feature Store (legacy).