以下のセクションでは、Vertex AI Feature Store(レガシー)のデータモデル、および Vertex AI Feature Store(レガシー)のリソースとコンポーネントの記述で使用されている用語について概説します。
Vertex AI Feature Store(レガシー)のデータモデル
Vertex AI Feature Store(レガシー)は、時系列データモデルを使用して一連の特徴の値を格納します。このモデルにより、Vertex AI Feature Store(レガシー)は、特徴の値が時間とともに変化しても値を保持できます。Vertex AI Feature Store(レガシー)は Featurestore -> EntityType -> Feature の順序でリソースを階層的に整理します。Vertex AI Feature Store(レガシー)にデータをインポートする前に、これらのリソースを作成する必要があります。
たとえば、BigQuery テーブルから次のサンプルのソースデータを使用するとします。このソースデータは映画とその特徴に関するものです。
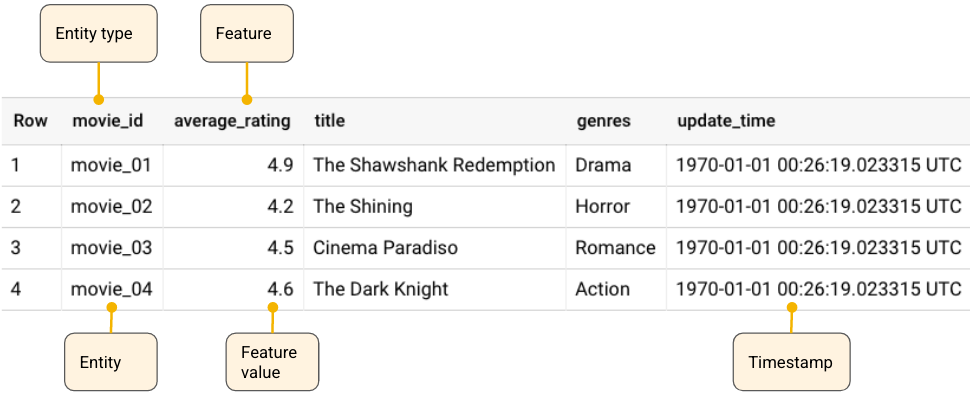
このデータを Vertex AI Feature Store(レガシー)にインポートするには、featurestore を作成する必要があります。これは、他のすべてのリソースの最上位コンテナになります。featurestore では、エンティティ タイプを作成して、関連する特徴をグループ化します。その後、ソースデータの特徴にマッピングする特徴を作成できます。エンティティ タイプと特徴の名前には列見出しの名前をそのまま利用できますが、必ずしもそのようにする必要はありません。
この例では、movie_id 列見出しがエンティティ タイプ movie にマッピングされています。average_rating、title、genre は、movie エンティティ タイプの特徴です。各列の値は、エンティティ タイプまたは特徴の特定のインスタンスにマッピングされます。これは、エンティティまたは特徴値と呼ばれます。
タイムスタンプ列は、特徴値の生成日時を表しています。featurestore では、タイムスタンプは個別のリソースタイプではなく、特徴値の属性になります。すべての特徴が同時に生成された場合は、タイムスタンプ列を使用する必要はありません。タイムスタンプは、インポート リクエストの一部として指定できます。
Featurestore
featurestore は、エンティティ タイプ、特徴、特徴値を格納する最上位のコンテナです。通常、組織で 1 つの共有 featurestore を作成して、組織内のすべてのチームで特徴のインポート、サービス提供、共有を行います。ただし、同じプロジェクト内で複数の featurestore を作成し、環境を分離することも可能です。たとえば、テスト環境、テスト環境、本番環境に別々の featurestore を使用できます。
エンティティ タイプ
エンティティ タイプは、意味的に関連する特徴のコレクションです。ユースケースに関連するコンセプトに基づいて、独自のエンティティ タイプを定義します。たとえば、映画サービスではエンティティ タイプ movie と user を設定し、映画または顧客に対応する特徴をグループ化します。
エンティティ
エンティティは、エンティティ タイプのインスタンスです。たとえば、movie_01 と movie_02 は movie エンティティ タイプのエンティティです。featurestore では、各エンティティは一意の ID を持ち、STRING 型にする必要があります。
特徴
特徴とは、エンティティ タイプの測定可能なプロパティまたは属性です。たとえば、movie エンティティ タイプには、映画のさまざまなプロパティを追跡する average_rating や title などの特徴が含まれています。特徴はエンティティ タイプに関連付けられます。特徴は特定のエンティティ タイプ内で一意でなければなりませんが、グローバルに一意である必要はありません。たとえば、2 つの異なるエンティティ タイプで title を使用している場合、Vertex AI Feature Store(レガシー)は title を 2 つの異なる特徴として解釈します。特徴値を読み取る場合は、リクエストの一部として特徴とそのエンティティ タイプを指定します。
特徴を作成するとき、BOOL_ARRAY、DOUBLE、DOUBLE_ARRAY、STRING などの値の型を指定します。これにより、特定の特徴でインポートできる値の型が決まります。サポートされている値の型については、API リファレンスの valueType をご覧ください。
特徴値
Vertex AI Feature Store(レガシー)は、特定時点での特徴値をキャプチャします。つまり、1 つのエンティティと特徴に複数の値が存在する可能性があります。たとえば、movie_01 エンティティには average_rating 特徴の複数の特徴値が存在する場合があります。値は、ある時点で 4.4 になり、別の時点で 4.8 になっている場合があります。Vertex AI Feature Store(レガシー)は、タプル識別子をそれぞれの特徴値(entity_id、feature_id、timestamp)に関連付けます。これは、Vertex AI Feature Store(レガシー)がサービング時に値を検索するときに使用されます。
時間が連続していても、Vertex AI Feature Store(レガシー)には離散的な値が格納されます。時間 t の特徴値をリクエストすると、Vertex AI Feature Store(レガシー)は、時間 t またはそれ以前で最後に格納された値を返します。たとえば、Vertex AI Feature Store(レガシー)が時刻 100 と 110 で車の位置情報を格納している場合、時刻 100(この値を含む)から 110(この値を含まない)までの間のリクエストに対して時刻 100 の位置情報が常に使用されます。より高い精度が必要な場合は、値の間の位置情報を推定するか、データのサンプリング レートを引き上げます。
特徴のインポート
特徴のインポートは、特徴量エンジニアリング ジョブによって計算された特徴値を featurestore にインポートするプロセスです。データをインポートする前に、対応するエンティティ タイプと特徴を featurestore で定義する必要があります。Vertex AI Feature Store(レガシー)にはバッチ インポートとストリーミング インポートがあり、特徴値を一括またはリアルタイムで追加できます。
たとえば、計算したソースデータが BigQuery や Cloud Storage などに存在する場合があります。これらのソースからデータを中央の featurestore にバッチ インポートして、特徴値を一貫した形式で提供できます。ソースデータが変更されると、ストリーミング インポートでそれらの変更を featurestore にすばやく取り込むことができます。これにより、オンライン サービスの状況で利用可能な最新のデータが得られます。
詳細については、特徴値のバッチ インポートまたはストリーミング インポートをご覧ください。
特徴のサービング
特徴のサービングは、トレーニングまたは推論のために保存されている特徴値をエクスポートするプロセスです。Vertex AI Feature Store(レガシー)には、特徴をサービングする方法としてバッチとオンラインの 2 つがあります。バッチ サービングはスループットが高く、オフライン処理(モデルのトレーニングやバッチ予測など)用に大量のデータを提供します。オンライン サービングでは、リアルタイム データ処理(オンライン予測など)で小規模なデータを低レイテンシで取得します。
詳細については、オンラインまたはバッチ サービングをご覧ください。
エンティティ ビュー
featurestore から値を取得すると、リクエストされた特徴値を含むエンティティ ビューが返されます。エンティティ ビューは、以下のように Vertex AI Feature Store(レガシー)がオンラインまたはバッチのサービング リクエストから返す特徴と値のプロジェクションと考えることができます。
- オンライン サービング リクエストでは、特定のエンティティ タイプに対応する特徴のすべてまたはサブセットを取得できます。
- バッチ サービング リクエストの場合は、1 つ以上のエンティティ タイプの特徴のすべてまたはサブセットを取得できます。たとえば、特徴が複数のエンティティ タイプに分散されている場合、それらの特徴を 1 つのリクエストで取得し、結合できます。この結果は、機械学習やバッチ予測リクエストにフィードできます。
データのエクスポート
Vertex AI Feature Store(レガシー)を使用すると、featurestore からデータをエクスポートし、特徴値のバックアップとアーカイブを行うことができます。最新の特徴値(スナップショット)または値の範囲(完全なエクスポート)をエクスポートできます。詳細については、特徴値のエクスポートをご覧ください。