Per utilizzare le spiegazioni basate su esempi, devi configurarle specificando un
explanationSpec
quando importi o carichi la risorsa Model nel registro dei modelli.
Poi, quando richiedi spiegazioni online, puoi sostituire alcuni di questi
valori di configurazione specificando un
ExplanationSpecOverride
nella richiesta. Non puoi richiedere spiegazioni batch, in quanto non sono supportate.
Questa pagina descrive come configurare e aggiornare queste opzioni.
Configurare le spiegazioni durante l'importazione o il caricamento del modello
Prima di iniziare, assicurati di disporre di quanto segue:
Una posizione Cloud Storage che contiene gli artefatti del modello. Il modello deve essere un modello basato su rete neurale profonda (DNN) in cui fornisci il nome di un livello o di una firma il cui output può essere utilizzato come spazio latente oppure puoi fornire un modello che restituisce direttamente gli incorporamenti (rappresentazione dello spazio latente). Questo spazio latente acquisisce le rappresentazioni degli esempi utilizzati per generare spiegazioni.
Un percorso Cloud Storage che contiene le istanze da indicizzare per la ricerca approssimativa del vicino più prossimo. Per ulteriori informazioni, consulta i requisiti dei dati di input.
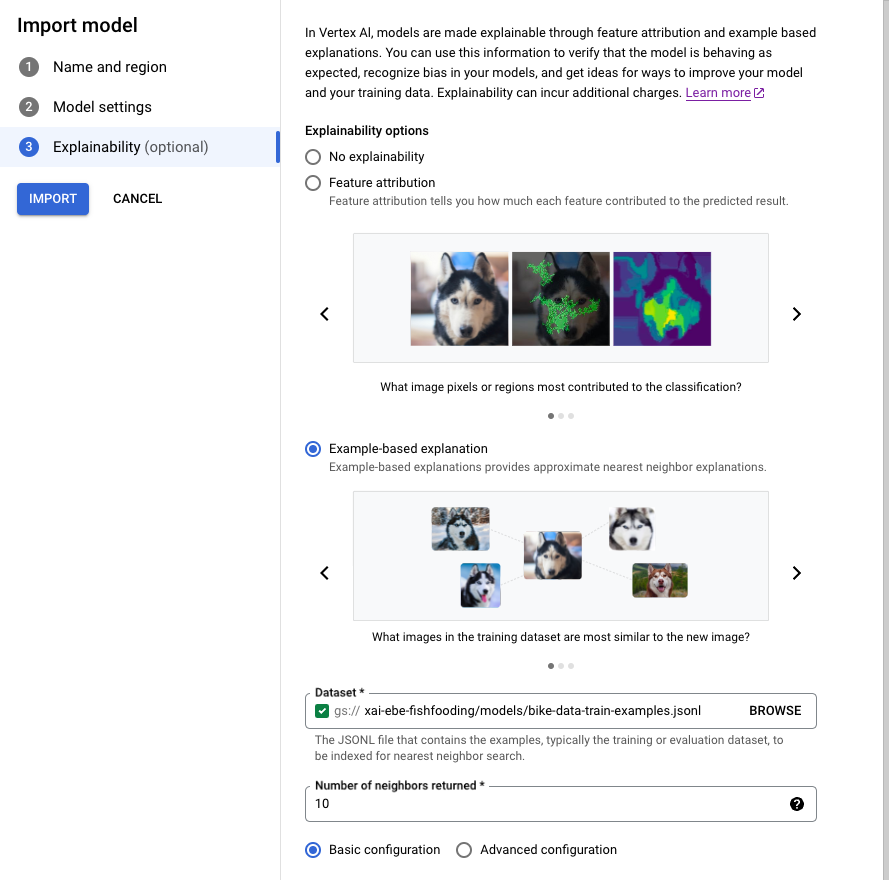
Console
Segui la guida per importare un modello utilizzando la console Google Cloud .
Nella scheda Spiegabilità, seleziona Spiegazione basata su esempi e compila i campi.
Per informazioni su ogni campo, consulta i suggerimenti nella console Google Cloud
(mostrati di seguito) e la documentazione di riferimento per Example e ExplanationMetadata.
Interfaccia a riga di comando gcloud
- Scrivi il seguente
ExplanationMetadatain un file JSON nel tuo ambiente locale. Il nome file non è importante, ma per questo esempio chiamaloexplanation-metadata.json:
{
"inputs": {
"my_input": {
"inputTensorName": "INPUT_TENSOR_NAME",
"encoding": "IDENTITY",
},
"id": {
"inputTensorName": "id",
"encoding": "IDENTITY"
}
},
"outputs": {
"embedding": {
"outputTensorName": "OUTPUT_TENSOR_NAME"
}
}
}
- (Facoltativo) Se specifichi l'
NearestNeighborSearchConfigcompleto, scrivi quanto segue in un file JSON nel tuo ambiente locale. Il nome file non è importante, ma per questo esempio chiamalosearch_config.json:
{
"contentsDeltaUri": "",
"config": {
"dimensions": 50,
"approximateNeighborsCount": 10,
"distanceMeasureType": "SQUARED_L2_DISTANCE",
"featureNormType": "NONE",
"algorithmConfig": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 1000,
"fractionLeafNodesToSearch": 1.0
}
}
}
}
- Esegui questo comando per caricare il tuo
Model.
Se utilizzi una configurazione di ricerca Preset, rimuovi il flag
--explanation-nearest-neighbor-search-config-file. Se stai specificando NearestNeighborSearchConfig, rimuovi i flag --explanation-modality e --explanation-query.
I flag più pertinenti per le spiegazioni basate su esempi sono in grassetto.
gcloud ai models upload \
--region=LOCATION \
--display-name=MODEL_NAME \
--container-image-uri=IMAGE_URI \
--artifact-uri=MODEL_ARTIFACT_URI \
--explanation-method=examples \
--uris=[URI, ...] \
--explanation-neighbor-count=NEIGHBOR_COUNT \
--explanation-metadata-file=explanation-metadata.json \
--explanation-modality=IMAGE|TEXT|TABULAR \
--explanation-query=PRECISE|FAST \
--explanation-nearest-neighbor-search-config-file=search_config.json
Per ulteriori informazioni, consulta gcloud ai models upload.
-
L'azione di caricamento restituisce un
OPERATION_IDche può essere utilizzato per verificare quando l'operazione è terminata. Puoi eseguire il polling dello stato dell'operazione finché la risposta non include"done": true. Utilizza il comando gcloud ai operations describe per eseguire il polling dello stato, ad esempio:gcloud ai operations describe <operation-id>Non potrai richiedere spiegazioni finché l'operazione non sarà completata. A seconda delle dimensioni del set di dati e dell'architettura del modello, questo passaggio può richiedere diverse ore per creare l'indice utilizzato per eseguire query sugli esempi.
REST
Prima di utilizzare i dati della richiesta, apporta le seguenti sostituzioni:
- PROJECT
- LOCATION
Per scoprire di più sugli altri segnaposto, consulta Model, explanationSpec e Examples.
Per scoprire di più sul caricamento dei modelli, consulta il metodo upload e l'articolo Importazione di modelli.
Il corpo della richiesta JSON riportato di seguito specifica una configurazione di ricerca Preset. In alternativa, puoi specificare ilNearestNeighborSearchConfig completo.
Metodo HTTP e URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models:upload
Corpo JSON della richiesta:
{
"model": {
"displayName": "my-model",
"artifactUri": "gs://your-model-artifact-folder",
"containerSpec": {
"imageUri": "us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-11:latest",
},
"explanationSpec": {
"parameters": {
"examples": {
"gcsSource": {
"uris": ["gs://your-examples-folder"]
},
"neighborCount": 10,
"presets": {
"modality": "image"
}
}
},
"metadata": {
"outputs": {
"embedding": {
"output_tensor_name": "embedding"
}
},
"inputs": {
"my_fancy_input": {
"input_tensor_name": "input_tensor_name",
"encoding": "identity",
"modality": "image"
},
"id": {
"input_tensor_name": "id",
"encoding": "identity"
}
}
}
}
}
}
Per inviare la richiesta, espandi una di queste opzioni:
Dovresti ricevere una risposta JSON simile alla seguente:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/models/MODEL_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.UploadModelOperationMetadata",
"genericMetadata": {
"createTime": "2022-01-08T01:21:10.147035Z",
"updateTime": "2022-01-08T01:21:10.147035Z"
}
}
}
L'azione di caricamento restituisce un OPERATION_ID che può essere utilizzato per verificare quando l'operazione è terminata. Puoi eseguire il polling dello stato dell'operazione finché
la risposta non include "done": true. Utilizza il comando gcloud ai operations describe per eseguire il polling dello stato, ad esempio:
gcloud ai operations describe <operation-id>
Non potrai richiedere spiegazioni finché l'operazione non sarà completata. A seconda delle dimensioni del set di dati e dell'architettura del modello, questo passaggio può richiedere diverse ore per creare l'indice utilizzato per eseguire query sugli esempi.
Python
Consulta la sezione Carica il modello nel notebook di spiegazioni basate su esempi di classificazione delle immagini.
NearestNeighborSearchConfig
Il seguente corpo della richiesta JSON mostra come specificare l'intero
NearestNeighborSearchConfig (anziché
i preset) in una
richiesta upload.
{
"model": {
"displayName": displayname,
"artifactUri": model_path_to_deploy,
"containerSpec": {
"imageUri": DEPLOY_IMAGE,
},
"explanationSpec": {
"parameters": {
"examples": {
"gcsSource": {
"uris": [DATASET_PATH]
},
"neighborCount": 5,
"nearest_neighbor_search_config": {
"contentsDeltaUri": "",
"config": {
"dimensions": dimensions,
"approximateNeighborsCount": 10,
"distanceMeasureType": "SQUARED_L2_DISTANCE",
"featureNormType": "NONE",
"algorithmConfig": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 1000,
"fractionLeafNodesToSearch": 1.0
}
}
}
}
}
},
"metadata": { ... }
}
}
}
Queste tabelle elencano i campi per NearestNeighborSearchConfig.
| Campi | |
|---|---|
dimensions |
Obbligatorio. Il numero di dimensioni dei vettori di input. Utilizzata solo per gli incorporamenti densi. |
approximateNeighborsCount |
Obbligatorio se viene utilizzato l'algoritmo tree-AH. Il numero predefinito di vicini da trovare tramite una ricerca approssimativa prima che venga eseguito il riordinamento esatto. Il riordino esatto è una procedura in cui i risultati restituiti da un algoritmo di ricerca approssimativa vengono riordinati utilizzando un calcolo della distanza più costoso. |
ShardSize |
ShardSize
Le dimensioni di ogni shard. Quando un indice è grande, viene suddiviso in shard in base alle dimensioni dello shard specificate. Durante la pubblicazione, ogni shard viene pubblicato su un nodo separato e viene scalato in modo indipendente. |
distanceMeasureType |
La misurazione della distanza utilizzata nella ricerca del vicino più prossimo. |
featureNormType |
Tipo di normalizzazione da eseguire su ciascun vettore. |
algorithmConfig |
oneOf:
La configurazione degli algoritmi utilizzati da Vector Search per una ricerca efficiente. Utilizzato solo per gli incorporamenti densi.
|
DistanceMeasureType
| Enum | |
|---|---|
SQUARED_L2_DISTANCE |
Distanza euclidea (L2) |
L1_DISTANCE |
Distanza di Manhattan (L1) |
DOT_PRODUCT_DISTANCE |
Valore predefinito. Definito come il negativo del prodotto scalare. |
COSINE_DISTANCE |
Distanza coseno. Consigliamo vivamente di utilizzare DOT_PRODUCT_DISTANCE + UNIT_L2_NORM anziché la distanza COSINE. I nostri algoritmi sono stati ottimizzati maggiormente per la distanza DOT_PRODUCT e, se combinata con UNIT_L2_NORM, offre lo stesso ranking ed equivalenza matematica della distanza COSINE. |
FeatureNormType
| Enum | |
|---|---|
UNIT_L2_NORM |
Tipo di normalizzazione dell'unità L2. |
NONE |
Valore predefinito. Non è specificato alcun tipo di normalizzazione. |
TreeAhConfig
Questi sono i campi da selezionare per l'algoritmo tree-AH (albero superficiale + hashing asimmetrico).
| Campi | |
|---|---|
fractionLeafNodesToSearch |
double |
| La frazione predefinita di nodi foglia in cui è possibile cercare qualsiasi query. Deve essere compresa tra 0,0 e 1,0, esclusi. Se non è impostata, il valore predefinito è 0,05. | |
leafNodeEmbeddingCount |
int32 |
| Numero di incorporamenti su ciascun nodo foglia. Se non è impostato, il valore predefinito è 1000. | |
leafNodesToSearchPercent |
int32 |
Obsoleto, utilizza fractionLeafNodesToSearch.La percentuale predefinita di nodi foglia in cui è possibile cercare qualsiasi query. Deve essere compreso tra 1 e 100 inclusi. Se non è impostato, il valore predefinito è 10 (ovvero 10%). |
|
BruteForceConfig
Questa opzione implementa la ricerca lineare standard nel database per ogni
query. Non ci sono campi da configurare per una ricerca di forza bruta. Per selezionare questo
algoritmo, passa un oggetto vuoto per BruteForceConfig a algorithmConfig.
Requisiti dei dati di input
Carica il set di dati in una posizione Cloud Storage. Assicurati che i file siano in formato JSON Lines.
I file devono essere in formato JSON Lines. Il seguente esempio è tratto dal notebook delle spiegazioni basate su esempi di classificazione delle immagini:
{"id": "0", "bytes_inputs": {"b64": "..."}}
{"id": "1", "bytes_inputs": {"b64": "..."}}
{"id": "2", "bytes_inputs": {"b64": "..."}}
Aggiorna l'indice o la configurazione
Vertex AI ti consente di aggiornare l'indice dei vicini più prossimi di un modello o la configurazione di Example. Questa operazione è
utile se vuoi aggiornare il modello senza reindicizzare il set di dati. Ad esempio, se l'indice del modello contiene 1000 istanze e vuoi aggiungerne altre 500, puoi chiamare UpdateExplanationDataset per aggiungerle all'indice senza rielaborare le 1000 istanze originali.
Per aggiornare il set di dati delle spiegazioni:
Python
def update_explanation_dataset(model_id, new_examples):
response = clients["model"].update_explanation_dataset(model=model_id, examples=new_examples)
update_dataset_response = response.result()
return update_dataset_response
PRESET_CONFIG = {
"modality": "TEXT",
"query": "FAST"
}
NEW_DATASET_FILE_PATH = "new_dataset_path"
NUM_NEIGHBORS_TO_RETURN = 10
EXAMPLES = aiplatform.Examples(presets=PRESET_CONFIG,
gcs_source=aiplatform.types.io.GcsSource(uris=[NEW_DATASET_FILE_PATH]),
neighbor_count=NUM_NEIGHBORS_TO_RETURN)
MODEL_ID = 'model_id'
update_dataset_response = update_explanation_dataset(MODEL_ID, EXAMPLES)
Note sull'utilizzo:
Il valore
model_idrimane invariato dopo l'operazioneUpdateExplanationDataset.L'operazione
UpdateExplanationDatasetinteressa solo la risorsaModele non aggiorna alcunDeployedModelassociato. Ciò significa che l'indice di undeployedModelcontiene il set di dati al momento del deployment. Per aggiornare l'indice di undeployedModel, devi eseguire nuovamente il deployment del modello aggiornato in un endpoint.
Ignorare la configurazione quando si ottengono spiegazioni online
Quando richiedi una spiegazione, puoi sostituire alcuni parametri al volo specificando il campo ExplanationSpecOverride.
A seconda dell'applicazione, alcune limitazioni potrebbero essere auspicabili per il tipo di spiegazioni restituite. Ad esempio, per garantire la diversità delle spiegazioni, un utente può specificare un parametro di affollamento che stabilisce che nessun tipo di esempi sia sovra rappresentato nelle spiegazioni. In concreto, se un utente sta cercando di capire perché un uccello è stato etichettato come aereo dal suo modello, potrebbe non essere interessato a vedere troppi esempi di uccelli come spiegazioni per indagare meglio sulla causa principale.
La seguente tabella riepiloga i parametri che possono essere sostituiti per una richiesta di spiegazione basata su esempi:
| Nome proprietà | Valore della proprietà | Descrizione |
|---|---|---|
| neighborCount | int32 |
Il numero di esempi da restituire come spiegazione |
| crowdingCount | int32 |
Numero massimo di esempi da restituire con lo stesso tag di affollamento |
| allow | String Array |
I tag consentiti per le spiegazioni |
| deny | String Array |
I tag che non sono consentiti per le spiegazioni |
La sezione Filtro di Vector Search descrive questi parametri in modo più dettagliato.
Ecco un esempio di corpo della richiesta JSON con override:
{
"instances":[
{
"id": data[0]["id"],
"bytes_inputs": {"b64": bytes},
"restricts": "",
"crowding_tag": ""
}
],
"explanation_spec_override": {
"examples_override": {
"neighbor_count": 5,
"crowding_count": 2,
"restrictions": [
{
"namespace_name": "label",
"allow": ["Papilloma", "Rift_Valley", "TBE", "Influenza", "Ebol"]
}
]
}
}
}
Passaggi successivi
Ecco un esempio di risposta a una richiesta explain basata su esempi:
[
{
"neighbors":[
{
"neighborId":"311",
"neighborDistance":383.8
},
{
"neighborId":"286",
"neighborDistance":431.4
}
],
"input":"0"
},
{
"neighbors":[
{
"neighborId":"223",
"neighborDistance":471.6
},
{
"neighborId":"55",
"neighborDistance":392.7
}
],
"input":"1"
}
]
Prezzi
Consulta la sezione sulle spiegazioni basate su esempi nella pagina dei prezzi.