如需使用基于样本的说明,您必须在将 Model 资源导入或上传到 Model Registry 时通过指定 explanationSpec 来配置说明。
然后,在请求在线说明时,您可以通过在请求中指定 ExplanationSpecOverride 来替换其中的一些配置值。您不能请求批量说明;这不受支持。
本页介绍了如何配置和更新这些选项。
在导入或上传模型时配置说明
在开始之前,请确保您具备以下各项:
一个包含模型工件的 Cloud Storage 位置。您的模型需要是在其中提供层名称的深度神经网络 (DNN) 模型,或是其输出可以用作潜在空间的签名,或者您可以提供直接输出嵌入的模型(潜在空间表示法)。此潜在空间会捕获用于生成说明的样本表示法。
一个包含要为近似最邻近对象搜索建立索引的实例的 Cloud Storage 位置。如需了解详情,请参阅输入数据要求。
控制台
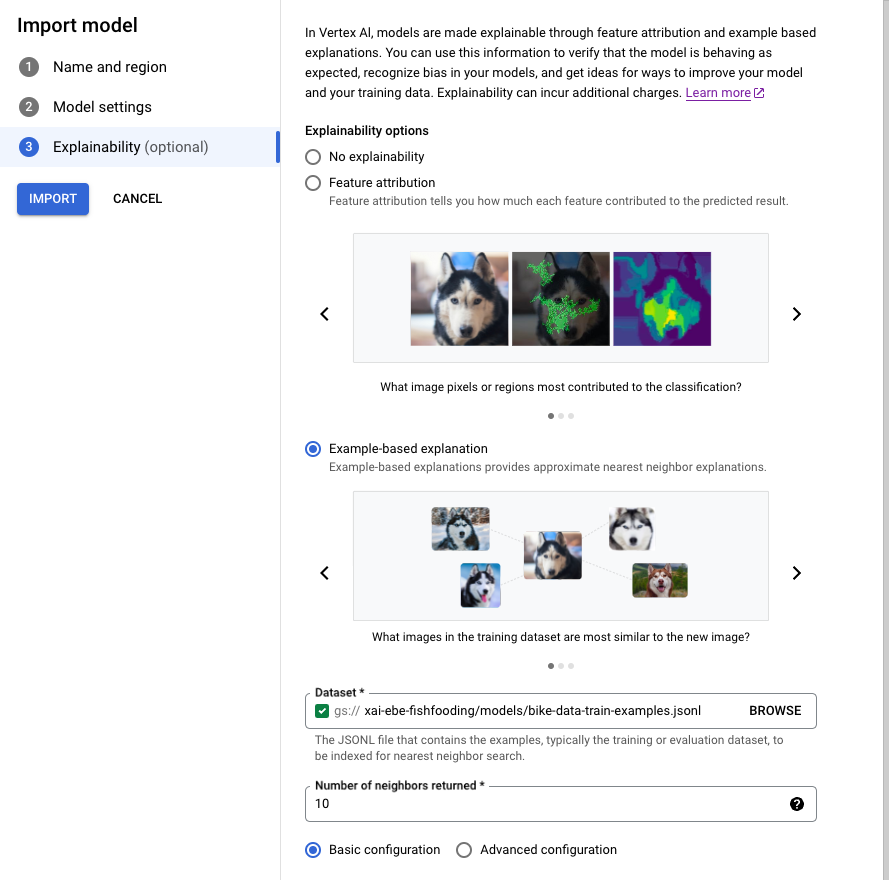
请按照指南使用 Google Cloud 控制台导入模型。
在可解释性标签页中,选择基于样本的说明并填写字段。
如需了解每个字段,请参阅 Google Cloud 控制台中的提示(如下所示)以及 Example 和 ExplanationMetadata 的参考文档。
gcloud CLI
- 将以下
ExplanationMetadata写入本地环境中的 JSON 文件。文件名无关紧要,但在本示例中,请将文件命名为explanation-metadata.json:
{
"inputs": {
"my_input": {
"inputTensorName": "INPUT_TENSOR_NAME",
"encoding": "IDENTITY",
},
"id": {
"inputTensorName": "id",
"encoding": "IDENTITY"
}
},
"outputs": {
"embedding": {
"outputTensorName": "OUTPUT_TENSOR_NAME"
}
}
}
- (可选)如果要指定完整的
NearestNeighborSearchConfig,请将以下内容写入本地环境中的 JSON 文件。文件名无关紧要,但在本示例中,请将文件命名为search_config.json:
{
"contentsDeltaUri": "",
"config": {
"dimensions": 50,
"approximateNeighborsCount": 10,
"distanceMeasureType": "SQUARED_L2_DISTANCE",
"featureNormType": "NONE",
"algorithmConfig": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 1000,
"fractionLeafNodesToSearch": 1.0
}
}
}
}
- 运行以下命令以上传您的
Model。
如果您使用的是 Preset 搜索配置,请移除 --explanation-nearest-neighbor-search-config-file 标志。如果您指定了 NearestNeighborSearchConfig,请移除 --explanation-modality 和 --explanation-query 标志。
与基于样本的说明最相关的标志以粗体显示。
gcloud ai models upload \
--region=LOCATION \
--display-name=MODEL_NAME \
--container-image-uri=IMAGE_URI \
--artifact-uri=MODEL_ARTIFACT_URI \
--explanation-method=examples \
--uris=[URI, ...] \
--explanation-neighbor-count=NEIGHBOR_COUNT \
--explanation-metadata-file=explanation-metadata.json \
--explanation-modality=IMAGE|TEXT|TABULAR \
--explanation-query=PRECISE|FAST \
--explanation-nearest-neighbor-search-config-file=search_config.json
如需了解详情,请参阅 gcloud ai models upload。
-
上传操作会返回一个
OPERATION_ID,可用于检查操作完成时间。您可以轮询操作状态,直到响应包含"done": true。使用 gcloud ai operations describe 命令轮询状态,例如:gcloud ai operations describe <operation-id>操作完成后,您才能请求说明。 根据数据集和模型架构的大小,此步骤可能需要几个小时才能构建用于查询样本的索引。
REST
在使用任何请求数据之前,请先进行以下替换:
- PROJECT
- LOCATION
如需了解其他占位符,请参阅 Model、explanationSpec 和 Examples。
如需详细了解如何上传模型,请参阅 upload 方法和导入模型。
下面的 JSON 请求正文指定了 Preset 搜索配置。或者,您也可以指定完整的 NearestNeighborSearchConfig。
HTTP 方法和网址:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models:upload
请求 JSON 正文:
{
"model": {
"displayName": "my-model",
"artifactUri": "gs://your-model-artifact-folder",
"containerSpec": {
"imageUri": "us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-11:latest",
},
"explanationSpec": {
"parameters": {
"examples": {
"gcsSource": {
"uris": ["gs://your-examples-folder"]
},
"neighborCount": 10,
"presets": {
"modality": "image"
}
}
},
"metadata": {
"outputs": {
"embedding": {
"output_tensor_name": "embedding"
}
},
"inputs": {
"my_fancy_input": {
"input_tensor_name": "input_tensor_name",
"encoding": "identity",
"modality": "image"
},
"id": {
"input_tensor_name": "id",
"encoding": "identity"
}
}
}
}
}
}
如需发送您的请求,请展开以下选项之一:
您应该收到类似以下内容的 JSON 响应:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/models/MODEL_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.UploadModelOperationMetadata",
"genericMetadata": {
"createTime": "2022-01-08T01:21:10.147035Z",
"updateTime": "2022-01-08T01:21:10.147035Z"
}
}
}
上传操作会返回一个 OPERATION_ID,可用于检查操作完成时间。您可以轮询操作状态,直到响应包含 "done": true。使用 gcloud ai operations describe 命令轮询状态,例如:
gcloud ai operations describe <operation-id>
操作完成后,您才能请求说明。 根据数据集和模型架构的大小,此步骤可能需要几个小时才能构建用于查询样本的索引。
Python
请参阅基于图片分类的样本说明笔记本中的上传模型部分。
NearestNeighborSearchConfig
以下 JSON 请求正文演示了如何在 upload 请求中指定完整的 NearestNeighborSearchConfig(而不是预设)。
{
"model": {
"displayName": displayname,
"artifactUri": model_path_to_deploy,
"containerSpec": {
"imageUri": DEPLOY_IMAGE,
},
"explanationSpec": {
"parameters": {
"examples": {
"gcsSource": {
"uris": [DATASET_PATH]
},
"neighborCount": 5,
"nearest_neighbor_search_config": {
"contentsDeltaUri": "",
"config": {
"dimensions": dimensions,
"approximateNeighborsCount": 10,
"distanceMeasureType": "SQUARED_L2_DISTANCE",
"featureNormType": "NONE",
"algorithmConfig": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 1000,
"fractionLeafNodesToSearch": 1.0
}
}
}
}
}
},
"metadata": { ... }
}
}
}
下表列出了 NearestNeighborSearchConfig 的字段。
| 字段 | |
|---|---|
dimensions |
必需。输入向量的维度数。 仅用于密集嵌入。 |
approximateNeighborsCount |
如果使用了树 AH 算法,则为必需。 在执行精确重新排序之前通过近似搜索找到的默认邻数量。精确重新排序是一个过程,在该过程中使用费用更高的距离计算记录通过近似搜索算法返回的结果。 |
ShardSize |
ShardSize
每个分片的大小。如果索引较大,系统会根据指定的碎片大小对其进行分片。在传送期间,每个分片都会在单独的节点上传送,并且可以独立扩缩。 |
distanceMeasureType |
在最邻近搜索中使用的距离度量。 |
featureNormType |
要对每个向量执行的归一化类型。 |
algorithmConfig |
oneOf:
Vector Search 用于高效搜索的算法的配置。 仅用于密集嵌入。
|
DistanceMeasureType
| 枚举 | |
|---|---|
SQUARED_L2_DISTANCE |
欧几里得 (L2) 距离 |
L1_DISTANCE |
曼哈顿 (L1) 距离 |
DOT_PRODUCT_DISTANCE |
默认值。定义为点积的负数。 |
COSINE_DISTANCE |
余弦距离我们强烈建议您使用 DOT_PRODUCT_DISTANCE + UNIT_L2_NORM,而不是 COSINE 距离。我们的算法针对 DOT_PRODUCT 距离进行了优化,并且与 UNIT_L2_NORM 结合使用时,可提供与 COSINE 距离相同的排名和数学等效性。 |
FeatureNormType
| 枚举 | |
|---|---|
UNIT_L2_NORM |
单位 L2 归一化类型。 |
NONE |
默认值。未指定归一化类型。 |
TreeAhConfig
这些字段是为树 AH 算法(浅树 + 非对称哈希)选择的字段。
| 字段 | |
|---|---|
fractionLeafNodesToSearch |
double |
| 所有查询均可搜索的叶节点的默认小数。 必须介于 0.0 - 1.0 之间(不含 0.0 和 1.0)。如果未设置,则默认值为 0.05。 | |
leafNodeEmbeddingCount |
int32 |
| 每个叶节点上的嵌入数量。如果未设置,则默认值为 1000。 | |
leafNodesToSearchPercent |
int32 |
已弃用,请使用 fractionLeafNodesToSearch。所有查询均可搜索的叶节点的默认百分比。 必须在 1-100 之间(含 1 和 100)。如果未设置,则默认值为 10(即 10%)。 |
|
BruteForceConfig
此选项用于在数据库中为每个查询实现标准线性搜索。没有要为暴力搜索配置的字段。如需选择此算法,请将 BruteForceConfig 的空对象传递给 algorithmConfig。
输入数据要求
将数据集上传到 Cloud Storage 位置。确保文件采用 JSON 行格式。
这些文件必须采用 JSON 行格式。以下示例摘自基于图片分类的样本说明笔记本:
{"id": "0", "bytes_inputs": {"b64": "..."}}
{"id": "1", "bytes_inputs": {"b64": "..."}}
{"id": "2", "bytes_inputs": {"b64": "..."}}
更新索引或配置
通过 Vertex AI,您可以更新模型的最邻近对象索引或 Example 配置。如果您想更新模型而不将其数据集重新编入索引,这将非常有用。例如,如果模型的索引包含 1,000 个实例,并且您希望再添加 500 个实例,则可以调用 UpdateExplanationDataset 来添加到索引,而无需重新处理原始 1,000 个实例。
如需更新说明数据集,请执行以下操作:
Python
def update_explanation_dataset(model_id, new_examples):
response = clients["model"].update_explanation_dataset(model=model_id, examples=new_examples)
update_dataset_response = response.result()
return update_dataset_response
PRESET_CONFIG = {
"modality": "TEXT",
"query": "FAST"
}
NEW_DATASET_FILE_PATH = "new_dataset_path"
NUM_NEIGHBORS_TO_RETURN = 10
EXAMPLES = aiplatform.Examples(presets=PRESET_CONFIG,
gcs_source=aiplatform.types.io.GcsSource(uris=[NEW_DATASET_FILE_PATH]),
neighbor_count=NUM_NEIGHBORS_TO_RETURN)
MODEL_ID = 'model_id'
update_dataset_response = update_explanation_dataset(MODEL_ID, EXAMPLES)
使用说明:
执行
UpdateExplanationDataset操作后,model_id保持不变。UpdateExplanationDataset操作仅影响Model资源;它不会更新任何关联的DeployedModel。这意味着deployedModel的索引包含数据集在部署时的数据集。如需更新deployedModel的索引,您必须将更新后的模型重新部署到端点。
获取在线说明时替换配置
请求说明时,您可以通过指定 ExplanationSpecOverride 字段实时即时替换某些参数。
根据应用的不同,可能需要对返回的样本类型实施一些限制条件。例如,为了确保说明的多样性,用户可以指定数量上限参数,用于指明在说明中不会过度表示任何一种类型的样本。具体而言,如果用户正在尝试了解其模型将全局标记为平面的原因,那么他们可能不想看到太多全局样本作为说明,以便更好地调查根本原因。
下表总结了可在基于样本的说明请求中替换的参数:
| 属性名称 | 属性值 | 说明 |
|---|---|---|
| neighborCount | int32 |
要作为说明返回的样本数量 |
| crowdingCount | int32 |
要使用相同的拥挤标记返回的样本数上限 |
| allow | String Array |
允许说明具有的标记 |
| deny | String Array |
不允许说明具有的标记 |
Vector Search 过滤更详细地介绍了这些参数。
以下示例展示了包含替换项的 JSON 请求正文:
{
"instances":[
{
"id": data[0]["id"],
"bytes_inputs": {"b64": bytes},
"restricts": "",
"crowding_tag": ""
}
],
"explanation_spec_override": {
"examples_override": {
"neighbor_count": 5,
"crowding_count": 2,
"restrictions": [
{
"namespace_name": "label",
"allow": ["Papilloma", "Rift_Valley", "TBE", "Influenza", "Ebol"]
}
]
}
}
}
后续步骤
以下是基于样本的 explain 请求的响应示例:
[
{
"neighbors":[
{
"neighborId":"311",
"neighborDistance":383.8
},
{
"neighborId":"286",
"neighborDistance":431.4
}
],
"input":"0"
},
{
"neighbors":[
{
"neighborId":"223",
"neighborDistance":471.6
},
{
"neighborId":"55",
"neighborDistance":392.7
}
],
"input":"1"
}
]
价格
请参阅价格页面中有关基于样本的说明的部分。