使用预构建的数据预处理代码进行模型训练:笔记本
作为数据科学家,这是一个常见的工作流:在本地训练模型(在我的笔记本中)、记录参数、将训练时序指标记录到 Vertex AI TensorBoard,并记录评估指标。
作为数据科学家,我想能够重复使用公司内其他人编写的数据预处理代码,以简化和标准化我们所做的所有复杂数据整理。我希望能够:
- 在笔记本中使用 Python 数据预处理库清理内存中的数据集 (Pandas Dataframe)。
- 使用 Keras 训练模型(还在笔记本中)。
笔记本:使用预处理后的数据进行模型实验
在“为自定义训练构建 Vertex AI Experiment 沿袭”笔记本中,您将学习如何在 Vertex AI Experiments 中集成预处理代码。此外,您将构建实验沿袭,以便记录、分析、调试和审核在整个机器学习过程中生成的元数据和工件。
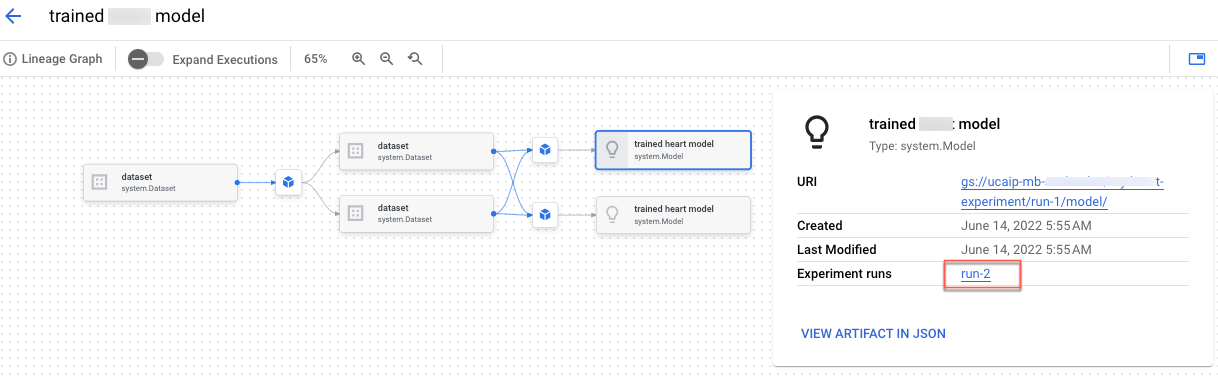
您可以在 Google Cloud 控制台中查看制品沿袭。
相关内容
如未另行说明,那么本页面中的内容已根据知识共享署名 4.0 许可获得了许可,并且代码示例已根据 Apache 2.0 许可获得了许可。有关详情,请参阅 Google 开发者网站政策。Java 是 Oracle 和/或其关联公司的注册商标。
最后更新时间 (UTC):2025-10-19。
[[["易于理解","easyToUnderstand","thumb-up"],["解决了我的问题","solvedMyProblem","thumb-up"],["其他","otherUp","thumb-up"]],[["很难理解","hardToUnderstand","thumb-down"],["信息或示例代码不正确","incorrectInformationOrSampleCode","thumb-down"],["没有我需要的信息/示例","missingTheInformationSamplesINeed","thumb-down"],["翻译问题","translationIssue","thumb-down"],["其他","otherDown","thumb-down"]],["最后更新时间 (UTC):2025-10-19。"],[],[]]