Als Data Scientist ist dies mein üblicher Workflow: Ein Modell lokal trainieren (in meinem Notebook), die Parameter protokollieren, die Zeitachsenmesswerte für das Training in Vertex AI TensorBoard protokollieren, und die Bewertungsmesswerte protokollieren.
Als Data Scientists möchte ich die Möglichkeit haben, Datenvorverarbeitungscode wiederzuverwenden, den andere in meinem Unternehmen geschrieben haben, um unsere komplexen Data Wrangling-Vorgänge zu vereinfachen und zu standardisieren. Ich möchte Folgendes tun können:
- Verwenden Sie eine Python-Bibliothek zur Datenvorverarbeitung, um ein Speicher-Dataset (ein Pandas-DataFrame) in einem Notebook zu bereinigen.
- Trainieren Sie ein Modell mit Keras (wieder in einem Notebook).
Notebook: Modellexperimente mit vorverarbeiteten Daten
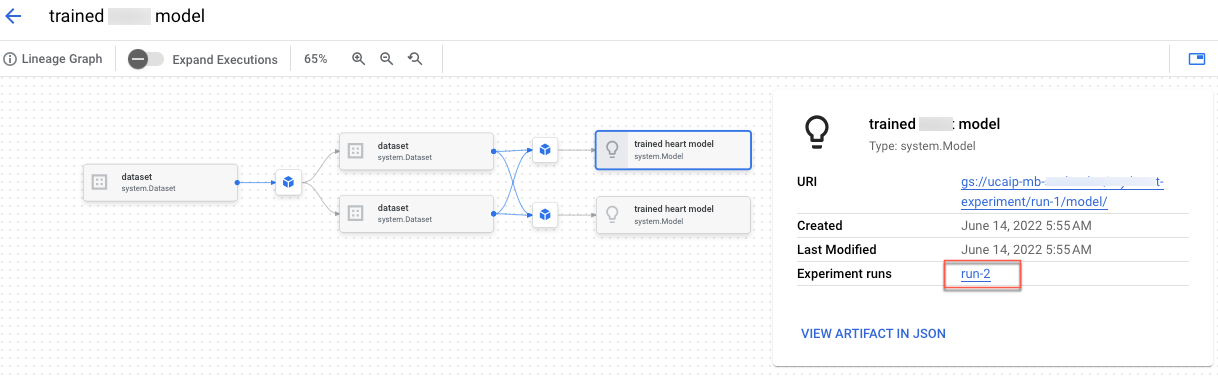
Im Notebook „Build Vertex AI Experiment: Herkunft für benutzerdefiniertes Training“ erfahren Sie, wie Sie Vorverarbeitungscode in Vertex AI Experiments einbinden. Außerdem erstellen Sie die Herkunft des Tests, mit der Sie Metadaten und Artefakte, die während Ihres ML-Prozesses erstellt wurden, aufzeichnen, analysieren, debuggen und prüfen können.
Sie können die Herkunft des Artefakts in der Google Cloud -Konsole ansehen.