Introducción
Esta guía para principiantes es una introducción a AutoML. Para comprender las diferencias clave entre AutoML y el entrenamiento personalizado, consulta Elige un método de entrenamiento.
Imagina lo siguiente:
- Eres entrenador de un equipo de fútbol.
- Trabajas en el departamento de marketing de un minorista digital.
- Estás trabajando en un proyecto de arquitectura que identifica tipos de edificios.
- Imagina que tu negocio tiene un formulario de contacto en su sitio web.
El trabajo de seleccionar videos, imágenes, textos y tablas de forma manual es tedioso y demanda mucho tiempo. ¿No sería más fácil enseñarle a una computadora a identificar y marcar automáticamente el contenido?
Imagen
Trabajas con una junta de conservación arquitectónica que intenta identificar los vecindarios de tu ciudad que tienen un estilo arquitectónico coherente. Tienes cientos de miles de instantáneas de hogares para categorizar. Sin embargo, es tedioso y propenso a errores cuando se intentan clasificar todas estas imágenes a mano. Un pasante etiquetó algunos centenares de ellas hace unos meses, pero nadie más ha visto los datos. Sería muy útil si pudieras enseñarle a tu computadora a hacer esto por ti.
Tabular
Imagina que trabajas en el departamento de marketing de un minorista digital. Tú y tu equipo están creando un programa de correos electrónicos personalizados basados en los perfiles de los clientes. Has creado los perfiles, y los correos electrónicos de marketing están listos para usar. Ahora debes crear un sistema que agrupe a los clientes en cada perfil según las preferencias de venta minorista y el comportamiento de consumo, incluso cuando sean clientes nuevos. Para maximizar la participación de los clientes, también es recomendable predecir sus hábitos de consumo a fin de que pueda optimizar el momento de enviarles los correos electrónicos.
Como eres un minorista digital, tienes datos sobre tus clientes y las compras que hicieron. Pero ¿qué sucede con los clientes nuevos? Los enfoques tradicionales pueden calcular estos valores con los clientes existentes con extensos historiales de compra, pero no funcionan muy bien con los clientes con pocos datos históricos. ¿Qué tal si pudieras crear un sistema para predecir estos valores y aumentar la velocidad con la que ofreces programas de marketing personalizados a los clientes?
Por suerte, el aprendizaje automático y Vertex AI están bien preparados para resolver estos problemas.
Texto
Imagina que tu negocio tiene un formulario de contacto en su sitio web. Todos los días recibes muchos mensajes del formulario, muchos de los cuales son prácticos de alguna manera. Debido a que todos vienen juntos, es fácil no poder lidiar con todos ellos. Los distintos empleados controlan diferentes tipos de mensajes.
Sería genial contar con un sistema automatizado que los clasifique para que la persona idónea vea los comentarios correctos.
Necesitarás un sistema para ver los comentarios y decidir si representan reclamos, elogios por servicios pasados, intentos de obtener más información sobre tu negocio, una solicitud para programar una cita o si buscan establecer una relación.
Video
Tienes una gran biblioteca de videos de juegos que te gustaría usar para analizar. Sin embargo, hay cientos de horas de video por revisar. Mirar cada video y marcar los segmentos de forma manual para destacar cada acción es una tarea tediosa que lleva mucho tiempo. Y debes repetir este trabajo cada temporada. Ahora imagina un modelo de computadora que pueda identificar y marcar automáticamente estas acciones cada vez que aparezcan en un video.
A continuación, se describen algunas situaciones específicas de objetivos.
- Reconocimiento de acciones: Busca acciones como anotar un gol, provocar una falta y patear un penal. Es útil para analizar las fortalezas y debilidades de su equipo.
- Clasificación: Clasifique cada toma de video como medio tiempo, vista del juego, vista del público o vista del entrenador. Es útil para que los entrenadores busquen solo las tomas de video interesantes.
- Seguimiento de objetos: realiza un seguimiento de la pelota de fútbol o de los jugadores. Es útil para los instructores a fin de obtener estadísticas de los jugadores, como el mapa de calor en el campo y la tasa de pases exitosos.
En esta guía, se explica cómo funciona Vertex AI para los modelos y los conjuntos de datos de AutoML, y se ilustran los tipos de problemas que Vertex AI está diseñado para resolver.
Una aclaración sobre la equidad
Google está comprometido con avanzar en el seguimiento de las prácticas de IA responsables. Para ello, nuestros productos de AA, incluido AutoML, están diseñados en torno a principios básicos como la equidad y el aprendizaje automático centrado en las personas. Si deseas obtener más información sobre las prácticas recomendadas para mitigar el sesgo cuando compilas tu propio sistema de AA, consulta la Guía para el AA inclusivo: AutoML.
¿Por qué Vertex AI es la herramienta adecuada para este problema?
La programación clásica requiere que el programador especifique las instrucciones paso a paso para que una computadora las siga. Pero considera el caso de uso de identificar acciones específicas en los partidos de fútbol. Hay tanta variación en el color, el ángulo, la resolución y la iluminación que requeriría codificar demasiadas reglas para indicarle a una máquina cómo tomar la decisión correcta. Es difícil imaginar dónde deberías comenzar. O bien, cuando los comentarios de los clientes, que usan un vocabulario y una estructura amplios y variados, son demasiado diversos para que los capture un conjunto simple de reglas. Si intentaste compilar filtros manuales, notarás con rapidez que no pudiste clasificar la mayoría de los comentarios de tus clientes. Necesitas un sistema capaz de generalizar a una amplia variedad de comentarios. En una situación en la que una secuencia de reglas específicas está destinada a expandirse de manera exponencial, necesitas un sistema que pueda aprender de los ejemplos.
Por suerte, el aprendizaje automático puede resolver estos problemas.
¿Cómo funciona Vertex AI?
 Vertex AI implica tareas de aprendizaje supervisado para lograr un resultado deseado.
Los detalles del algoritmo y los métodos de entrenamiento cambian según el tipo de datos y el caso de uso. Existen muchas subcategorías diferentes de aprendizaje automático; todas ellas resuelven distintos problemas y funcionan con diferentes restricciones.
Vertex AI implica tareas de aprendizaje supervisado para lograr un resultado deseado.
Los detalles del algoritmo y los métodos de entrenamiento cambian según el tipo de datos y el caso de uso. Existen muchas subcategorías diferentes de aprendizaje automático; todas ellas resuelven distintos problemas y funcionan con diferentes restricciones.
Imagen
Entrenas, pruebas y validas el modelo de aprendizaje automático con imágenes de ejemplo que se anotan con etiquetas para la clasificación, o que se anotan con etiquetas y cuadros de límite para la detección de objetos. Mediante el aprendizaje supervisado, puedes entrenar un modelo para reconocer en las imágenes los patrones y el contenido que te interesa.
Tabular
Entrenas un modelo de aprendizaje automático con datos de ejemplo. Vertex AI usa datos tabulares (estructurados) para entrenar un modelo de aprendizaje automático a fin de realizar predicciones sobre datos nuevos. Tu modelo aprenderá a predecir una columna de tu conjunto de datos llamada el objetivo. Algunas de las otras columnas de datos son entradas (llamadas atributos) de las que el modelo aprenderá patrones. Puedes usar los mismos atributos de entrada para crear varios tipos de modelos con solo cambiar la columna de destino y las opciones de entrenamiento. A partir del ejemplo del marketing por correo electrónico, esto significa que podrías compilar modelos con los mismos atributos de entrada, pero con diferentes predicciones de destino. Un modelo puede predecir el perfil de un cliente (un objetivo categórico), otro puede predecir su gasto mensual (un objetivo numérico) y otro puede predecir la demanda diaria de tus productos para los próximos tres meses (serie de objetivos numéricos).
Texto
Vertex AI te permite realizar un aprendizaje supervisado. Esto implica entrenar una computadora para reconocer patrones a partir de datos etiquetados. Con el aprendizaje supervisado, puedes entrenar un modelo de AutoML para reconocer el contenido que te interesa en el texto.
Video
Entrenas, pruebas y validas el modelo de aprendizaje automático con videos que ya etiquetaste. Con un modelo entrenado, puedes ingresar videos nuevos en el modelo, que luego producen segmentos de video con etiquetas. Un segmento de video define la compensación de hora de inicio y de finalización en un video. El segmento puede ser la totalidad del video, el segmento de tiempo definido por el usuario, la captura de video detectada automáticamente o una marca de tiempo para indicar cuando la hora de inicio es la misma que la hora de finalización. Una etiqueta es una "respuesta" prevista del modelo. Por ejemplo, en los casos prácticos de fútbol antes mencionados, para cada video de fútbol nuevo, según el tipo de modelo, sucede lo siguiente:
- un modelo de reconocimiento de acción entrenado da como resultado compensaciones para el tiempo del video con etiquetas que describen tomas de acciones como "gol", "falta personal", etcétera;
- un modelo de clasificación entrenado detecta de forma automática segmentos de tomas con etiquetas definidas por el usuario, como "vista del juego", "vista del público".
- Un modelo de seguimiento de objetos entrenado genera un seguimiento de la pelota de fútbol o de los jugadores mediante los cuadros de límite en los marcos en los que aparecen los objetos.
Flujo de trabajo de Vertex AI
Vertex AI usa un flujo de trabajo de aprendizaje automático estándar:
- Reúne tus datos: Determina los datos que necesitas para entrenar y probar tu modelo en función del resultado que quieres lograr.
- Prepara tus datos: Asegúrate de que los datos tengan el formato y las etiquetas adecuados.
- Entrena: Configura los parámetros y crea tu modelo.
- Evalúa: Revisa las métricas del modelo.
- Implementa y predice: Haz que tu modelo esté disponible para su uso.
Sin embargo, antes de comenzar a recopilar datos, debes pensar en el problema que está tratando de resolver. Esto informará los requisitos de datos.
Preparación de datos
Evalúa tu caso práctico
Comienza con tu problema: ¿cuál es el resultado que quieres obtener?
Imagen
Para crear el conjunto de datos, comienza siempre con el caso práctico. Puedes empezar con las siguientes preguntas:
- ¿Cuál es el resultado que buscas?
- ¿Qué tipos de categorías u objetos necesitarías reconocer para lograr este resultado?
- ¿Es posible que las personas reconozcan esas categorías? Si bien la Vertex AI puede manejar una mayor cantidad de categorías que las que las personas pueden recordar y asignar a la vez, si una persona no puede reconocer una categoría específica, Vertex AI también tendrá dificultades.
- ¿Qué tipos de ejemplos reflejarían mejor el tipo y rango de datos que tu sistema verá e intentará clasificar?
Tabular
¿Qué tipo de datos lleva la columna objetivo? ¿A qué cantidad de datos tienes acceso? Según tus respuestas, Vertex AI crea el modelo necesario para resolver tu caso práctico:
- Los modelos de clasificación binaria predicen un resultado binario (una de dos clases). Úsalos para preguntas de sí o no, por ejemplo, a fin de predecir si un cliente pagaría una suscripción (o no). Si todo lo demás permanece constante, un problema de clasificación binaria requiere menos datos que otros tipos de modelos.
- Los modelos de clasificación de varias clases predicen una clase de tres o más clases discretas. Úsalos para categorizar. Para el ejemplo de la venta minorista, deberías crear un modelo de clasificación de clases múltiples con el fin de segmentar a los clientes en diferentes perfiles.
- Un modelo de previsión predice una secuencia de valores. Por ejemplo, como minorista, te recomendamos prever la demanda diaria de tus productos durante los próximos 3 meses para que puedas almacenar los inventarios de productos de forma adecuada con anticipación.
- Un modelo de regresión predice un valor continuo. Para el ejemplo de venta minorista, deberías crear un modelo de regresión a fin de predecir cuánto invertirá un cliente el mes siguiente.
Texto
Para crear el conjunto de datos, comienza siempre con el caso práctico. Puedes empezar con las siguientes preguntas:
- ¿Qué resultado quieres lograr?
- ¿Qué tipos de categorías necesitas reconocer para lograr este resultado?
- ¿Es posible que las personas reconozcan esas categorías? Si bien Vertex AI puede manejar más categorías de lo que las personas pueden recordar y asignar a la vez, si una persona no puede reconocer una categoría específica, Vertex AI también tendrá dificultades.
- ¿Qué clases de ejemplos reflejarán mejor el tipo y el rango de datos que clasificará tu sistema?
Video
Según el resultado que intentes lograr, selecciona el objetivo de modelo adecuado:
- Para detectar los momentos de acción en un video, como identificar la anotación de un gol, la provocación de una falta o el tiro de un penal, usa el objetivo de reconocimiento de acciones.
- Para clasificar las tomas de TV en las siguientes categorías, comerciales, noticias, programas de TV, etc., usa el objetivo de clasificación.
- Para ubicar objetos y hacer un seguimiento de ellos, usa el objetivo de seguimiento de objetos.
Consulta Prepara datos de video a fin de obtener más información sobre las prácticas recomendadas para preparar conjuntos de datos con objetivos de reconocimiento de acciones, clasificación y seguimiento de objetos.
Recopila tus datos
Después de establecer tu caso de uso, debes recopilar los datos que te permitirán crear el modelo que deseas.
Imagen
 Luego de establecer los datos que necesitas, debes encontrar una manera de obtenerlos. Para comenzar, puedes considerar todos los datos que recopila tu organización. Es posible que notes que ya recopilas los datos relevantes que necesitas para entrenar un modelo. En caso de que no tengas esos datos, puedes obtenerlos de forma manual o subcontratar a un proveedor externo.
Luego de establecer los datos que necesitas, debes encontrar una manera de obtenerlos. Para comenzar, puedes considerar todos los datos que recopila tu organización. Es posible que notes que ya recopilas los datos relevantes que necesitas para entrenar un modelo. En caso de que no tengas esos datos, puedes obtenerlos de forma manual o subcontratar a un proveedor externo.
Incluye suficientes ejemplos etiquetados en cada categoría
 El mínimo requerido por Vertex AI Training es de 100 ejemplos de imágenes por categoría o etiqueta para la clasificación.
La probabilidad de reconocer con éxito una etiqueta aumenta con la cantidad de ejemplos de alta calidad para cada una. En general, cuantos más datos etiquetados puedas aportar al proceso de entrenamiento, mejor será tu modelo. Selecciona al menos 1,000 ejemplos por etiqueta.
El mínimo requerido por Vertex AI Training es de 100 ejemplos de imágenes por categoría o etiqueta para la clasificación.
La probabilidad de reconocer con éxito una etiqueta aumenta con la cantidad de ejemplos de alta calidad para cada una. En general, cuantos más datos etiquetados puedas aportar al proceso de entrenamiento, mejor será tu modelo. Selecciona al menos 1,000 ejemplos por etiqueta.
Distribuye ejemplos por igual en todas las categorías
Es importante recopilar cantidades similares de ejemplos de entrenamiento para cada categoría. Incluso si tienes una gran cantidad de datos que corresponden a una etiqueta, es mejor tener una distribución equitativa para cada una. Para entender por qué, imagina que el 80% de las imágenes que usas cuando compilas tu modelo son imágenes de casas unifamiliares de estilo moderno. Con una distribución de etiquetas tan desequilibrada, es muy probable que tu modelo suponga que es seguro indicar siempre que una foto es de una casa unifamiliar moderna, en lugar de arriesgarse a intentar predecir una etiqueta mucho menos común.
Es como escribir una prueba de opción múltiple en la que casi todas las respuestas correctas son “C”. Pronto, una persona inteligente sabrá que puede responder “C” siempre, sin siquiera mirar la pregunta.
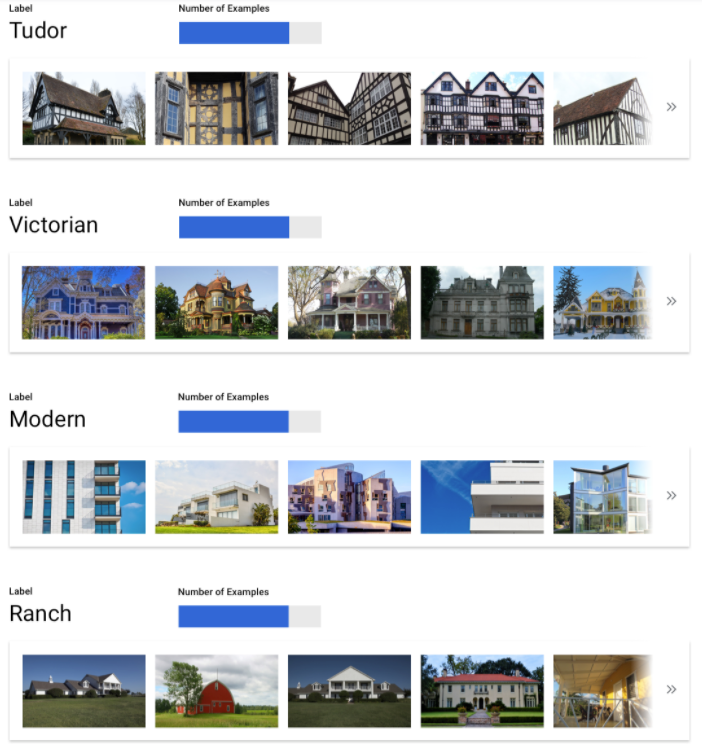
Entendemos que no siempre es posible obtener una cantidad parecida de ejemplos para cada etiqueta. Los ejemplos imparciales y de alta calidad para algunas categorías pueden ser más difíciles de obtener. En esas circunstancias, puedes seguir esta regla general: la etiqueta con el número más bajo de ejemplos debe tener al menos el 10% de los que tiene la etiqueta con el número más alto. Entonces, si la etiqueta más grande tiene 10,000 ejemplos, la etiqueta más pequeña debe tener al menos 1,000 ejemplos.
Captura la variación en tu espacio problemático
Por razones similares, intenta asegurarte de que tus datos capturen la variedad y diversidad del espacio del problema. Cuanto más amplia sea la selección para el proceso de entrenamiento del modelo, más fácil será establecer generalizaciones que contemplen ejemplos nuevos. Por ejemplo, si intentas clasificar fotos de artículos electrónicos de consumo en categorías, cuanto más amplia sea la variedad de artículos a la que se expone el modelo en el entrenamiento, más probable será que pueda distinguir entre un modelo nuevo de tablet, teléfono o laptop, incluso si nunca antes vio ese modelo específico.
Haz coincidir los datos con el resultado previsto para tu modelo

Encuentra imágenes que sean visualmente similares a lo que planeas usar para hacer predicciones. Si intentas clasificar fotos de casas tomadas en un clima nevado de invierno, es probable que no obtengas un buen rendimiento de un modelo entrenado solo con fotos tomadas en un clima soleado, incluso si las etiquetaste de forma correcta, ya que la iluminación y el paisaje pueden ser bastante diferentes y afectar el rendimiento. Lo ideal es que tus ejemplos de entrenamiento sean datos del mundo real extraídos del mismo conjunto de datos que deseas clasificar mediante el modelo.
Tabular
Después de establecer tu caso de uso, deberás recopilar datos para entrenar el modelo.
La obtención y la preparación de datos son pasos fundamentales para crear un modelo de aprendizaje automático.
Los datos que tengas disponibles dictaminarán el tipo de problemas que puedes resolver. ¿Cuántos datos tienes disponibles? ¿Tus datos son relevantes para las preguntas que intentas responder? Mientras recopilas tus datos, ten en cuenta las consideraciones claves que se mencionan a continuación.
Selecciona las características relevantes
Una característica es un atributo de entrada que se usa para el entrenamiento del modelo. Las características son la forma en que tu modelo identifica patrones a fin de hacer predicciones, por lo que deben ser relevantes para problema. Por ejemplo, para crear un modelo que prediga si la transacción de una tarjeta de crédito es fraudulenta o no, deberás compilar un conjunto de datos que contenga detalles de la transacción, como el comprador, el vendedor, el importe, la fecha, la hora y los artículos comprados. Otros atributos útiles pueden ser la información histórica sobre el comprador, el vendedor y la frecuencia con la que el artículo en cuestión ha sido objeto de fraude. ¿Qué otras características podrían ser relevantes?
Considera el caso de uso de la introducción sobre el marketing por correo electrónico para la venta minorista. Estas son algunas columnas de atributos que podrías necesitar:
- Lista de artículos comprados (que incluye marcas, categorías, precios, descuentos)
- Cantidad de artículos comprados (último día, semana, mes, año)
- Importe de dinero gastado (último día, semana, mes, año)
- Para cada artículo, la cantidad total que se vende por día
- Para cada artículo, la cantidad total en stock cada día
- Si está ejecutando una promoción de un día específico
- Perfil demográfico conocido del comprador
Incluye suficientes datos
En general, mientras más ejemplos de entrenamiento tengas, mejor será el resultado. La cantidad de datos de ejemplo necesarios también se ajusta a la complejidad del problema que intentas resolver. En comparación con un modelo de varias clases, para obtener un modelo de clasificación binaria preciso, no necesitarás tantos datos, porque es menos complicado predecir una clase entre dos que entre muchas.
No existe la fórmula perfecta, pero sí se recomiendan cantidades mínimas de datos de ejemplo:
- Problema de clasificación: 50 filas x la cantidad de atributos
- Problema de previsión:
- 5,000 filas x la cantidad de atributos
- 10 valores únicos en la columna del identificador de la serie temporal x la cantidad de atributos
- Problema de regresión: 200 veces la cantidad de atributos
Abarca la variedad
Tu conjunto de datos debería abarcar la diversidad de la dimensión del problema. Cuanto más diversos sean los ejemplos que ve un modelo durante el entrenamiento, con mayor facilidad podrá generalizar ejemplos nuevos o no tan comunes. Imagina si tu modelo de venta minorista se entrenara solo con datos de compras durante el invierno. ¿Podría predecir con éxito las preferencias sobre vestimenta o comportamientos de compra durante el verano?
Texto
Una vez establecidos los datos que necesitas, debes buscar una manera de obtenerlos. Para comenzar, puedes tener en cuenta todos los datos que recopila tu organización. Es posible que descubras que ya estás recopilando los datos que necesitas para entrenar un modelo. En caso de que no tengas los datos que necesitas, puedes obtenerlos de forma manual o subcontratar a un tercero.
Incluye suficientes ejemplos etiquetados en cada categoría
La probabilidad de reconocer de forma correcta una etiqueta aumenta con la cantidad de ejemplos de alta calidad para cada uno. Por lo general, cuantos más datos etiquetados puedas aportar al proceso de entrenamiento, mejor será tu modelo. La cantidad de muestras necesarias también varía según el grado de coherencia en los datos que deseas predecir y el nivel objetivo de precisión. Puedes usar menos ejemplos para conjuntos de datos coherentes o a fin de lograr un 80% de precisión en lugar del 97% de precisión.
Entrena un modelo y, luego, evalúa los resultados. Agrega más ejemplos y vuelve a entrenar hasta que alcances tus objetivos de precisión, lo que podría requerir cientos o incluso miles de ejemplos por etiqueta. Para obtener más información sobre requisitos y recomendaciones de datos, consulta Prepara datos de entrenamiento de texto para modelos de AutoML.
Distribuye ejemplos por igual en todas las categorías
Es importante capturar cantidades similares de ejemplos de entrenamiento para cada categoría. Incluso si tienes una gran cantidad de datos que corresponden a una etiqueta, es mejor tener una distribución equitativa para cada una. Para entender por qué, imagina que el 80% de los comentarios de clientes que usas cuando compilas tu modelo son solicitudes de presupuesto. Con una distribución de etiquetas tan desequilibrada, es muy probable que tu modelo suponga que es seguro indicar siempre que un comentario de un cliente es una solicitud de presupuesto, en lugar de intentar predecir una etiqueta mucho menos común. Es como escribir una prueba de opción múltiple en la que casi todas las respuestas correctas son “C”. Pronto, una persona inteligente sabrá que puede responder “C” siempre, sin siquiera mirar la pregunta.

No siempre será posible obtener una cantidad parecida de ejemplos para cada etiqueta. Los ejemplos imparciales y de alta calidad para algunas categorías pueden ser más difíciles de obtener. En esas circunstancias, la etiqueta con el número más bajo de ejemplos debe tener al menos el 10% de los que tiene la etiqueta con el número más alto. Entonces, si la etiqueta más grande tiene 10,000 ejemplos, la etiqueta más pequeña debe tener al menos 1,000 ejemplos.
Captura la variación en tu espacio problemático
Por razones similares, intenta que tus datos capturen la variedad y diversidad de tu espacio problemático. Cuando proporcionas un conjunto más amplio de ejemplos, el modelo puede generalizar mejor los datos nuevos. Digamos que estás tratando de clasificar artículos sobre electrodomésticos en temas. Cuanto más marcas y especificaciones técnicas proporciones, más fácil será para el modelo descubrir el tema de un artículo, incluso si trata sobre una marca que no formó parte del conjunto de entrenamiento. Considera incluir una etiqueta “none_of_the_above” para los documentos que no coincidan con ninguna de tus etiquetas definidas, y así mejorar aún más el rendimiento del modelo.
Haz coincidir los datos con el resultado previsto para tu modelo

Encuentra ejemplos de texto que sean similares a los que planeas utilizar para hacer predicciones. Si estás tratando de clasificar las publicaciones de las redes sociales sobre vidrio soplado, probablemente no obtendrás un gran rendimiento de un modelo entrenado en sitios web de información sobre vidrio soplado, ya que el vocabulario y el estilo pueden ser diferentes. Lo ideal es que tus ejemplos de entrenamiento sean datos del mundo real extraídos del mismo conjunto de datos que deseas clasificar mediante el modelo.
Video
Después de establecer tu caso de uso, deberás recopilar los datos de video que te permitirán crear el modelo que deseas. Los datos que recopilas para el entrenamiento informan los tipos de problemas que puedes resolver. ¿Cuántos videos puedes usar? ¿Los videos contienen suficientes ejemplos para las predicciones que deseas que tu modelo realice? Cuando recopiles tus datos de video, ten en cuenta las siguientes consideraciones.
Incluye suficientes videos
Por lo general, cuantos más videos de entrenamiento incluyas en tu conjunto de datos, mejor serán tus resultados. La cantidad de videos recomendados también se escala en función de la complejidad del problema que intentas resolver. Por ejemplo, para la clasificación, necesitarás menos datos de video para un problema de clasificación binaria (predicción de una de entre dos clases) que un problema de varias etiquetas (predicción de una o más clases de entre muchas).
La complejidad de lo que intentas hacer también determina la cantidad de datos de video que necesitas. Considera el caso de uso sobre fútbol para la clasificación, que compila un modelo para distinguir tomas de acciones, en comparación con entrenar un modelo para clasificar diferentes estilos de natación. Por ejemplo, para distinguir entre pecho, mariposa, espalda, etc., necesitarás más datos de entrenamiento a fin de identificar los distintos estilos de natación para que el modelo aprenda a identificar cada tipo con precisión. Consulta Prepara datos de video a fin de obtener ayuda para comprender tus necesidades de datos de video mínimas para el reconocimiento de acciones, la clasificación y el seguimiento de objetos.
Es posible que la cantidad de datos de video requeridos sea superior a la que tienes actualmente. Considera obtener más videos a través de un proveedor externo. Por ejemplo, podrías comprar u obtener más videos de colibríes si no tienes suficientes para el modelo del identificador de acciones del juego.
Distribuye videos de forma equitativa en todas las clases
Intenta proporcionar una cantidad similar de ejemplos de entrenamiento a cada clase. Esta es la razón: Imagina que el 80% de tu conjunto de datos de entrenamiento consiste en videos de fútbol que incluyen tiros que lograron anotar goles, pero solo en el 20% de ellos se muestran faltas o patadas que provoquen penales. Con una distribución de clases tan poco equitativa, es más probable que tu modelo prediga que una acción determinada es un gol. Es similar a escribir una prueba de opción múltiple en la que el 80% de las respuestas correctas es “C”: el modelo inteligente determinará con rapidez que “C” es una buena estimación.

Es posible que no puedas obtener la misma cantidad de videos para cada clase. Los ejemplos imparciales y de alta calidad también pueden ser difíciles para algunas clases. Intenta seguir una proporción de 1:10: si la clase más grande tiene 10,000 videos, la más pequeña debe tener al menos 1,000 videos.
Abarca la variedad
Los datos de tus videos deben capturar la diversidad del espacio del problema. Cuanto más diversos sean los ejemplos que ve un modelo durante el entrenamiento, con mayor facilidad podrá generalizar ejemplos nuevos o no tan comunes. Piensa en el modelo de clasificación de acciones de fútbol: asegúrate de incluir videos con una variedad de ángulos de cámara, distintas horas del día y la noche, y diversos movimientos de los jugadores. Exponer el modelo a una diversidad de datos mejora su capacidad de distinguir una acción de otra.
Hace coincidir los datos con el resultado deseado

Busca videos de entrenamiento que sean visualmente similares a los videos que planeas ingresar en el modelo para la predicción. Por ejemplo, si todos tus videos de entrenamiento se filmaron durante el invierno o en la noche, los patrones de iluminación y color de esos entornos afectarán tu modelo. Si luego usas ese modelo para probar los videos tomados durante el verano o a la luz solar, es posible que no recibas predicciones precisas.
Considera estos factores adicionales: resolución del video, fotogramas por video, ángulo de la cámara y fondo.
Prepara los datos
Imagen
 Después de decidir cuál es la opción adecuada para ti (una división manual o predeterminada), puedes agregar datos en Vertex AI con uno de los siguientes métodos:
Después de decidir cuál es la opción adecuada para ti (una división manual o predeterminada), puedes agregar datos en Vertex AI con uno de los siguientes métodos:
- Puedes importar datos desde tu computadora o desde Cloud Storage en un formato disponible (CSV o JSON Lines) que tenga las etiquetas intercaladas (y los cuadros de límite, si es necesario). Para obtener más información sobre el formato del archivo de importación, consulta Prepara tus datos de entrenamiento. Si deseas dividir tu conjunto de datos de forma manual, puedes especificar las divisiones en tu archivo de importación de líneas CSV o JSONL.
- Si no se anotaron tus datos, puedes subir imágenes sin etiquetar y usar la consola de Google Cloud para aplicar anotaciones. Puedes administrar estas anotaciones en varios conjuntos de anotaciones para el mismo conjunto de imágenes. Por ejemplo, para un conjunto único de imágenes, puedes tener un conjunto de anotaciones con información de cuadros de límite y etiquetas a fin de realizar la detección de objetos, y también puedes tener otro conjunto de anotaciones con solo anotaciones de etiquetas para la clasificación.
Tabular
Una vez que hayas identificado los datos disponibles, debes asegurarte de que estén listos para el entrenamiento.
Si tus datos tienen sesgos o valores erróneos o faltantes, esto afecta la calidad del modelo. Antes de comenzar a entrenar tu modelo, ten en cuenta lo siguiente.
Obtén más información.
Evita la filtración de datos y desviaciones entre el entrenamiento y la entrega
La filtración de datos ocurre cuando usas atributos de entrada durante el entrenamiento que “filtran” información acerca del objetivo que intentas predecir y que no está disponible cuando el modelo se entrega. Esto se puede detectar cuando un atributo que tiene una alta correlación con la columna objetivo se incluye como uno de los atributos de entrada. Por ejemplo, si estás creando un modelo con el fin de predecir si un cliente se registrará para obtener una suscripción el próximo mes, y uno de los atributos de entrada es un pago por una futura suscripción de ese cliente. Esto puede generar un gran rendimiento del modelo durante la prueba, pero no cuando se implementa en producción, ya que la información de pago de la futura suscripción no estará disponible al momento de la entrega.
Las desviaciones entre el entrenamiento y la entrega ocurren cuando los atributos de entrada usados durante el entrenamiento son diferentes de los que se proporcionan al modelo al momento de la entrega, lo que reduce la calidad de modelo en la producción. Por ejemplo, si creas un modelo para predecir las temperaturas por hora, pero entrenas con datos que solo contienen temperaturas semanales. Otro ejemplo: supongamos que quieres predecir la deserción escolar y siempre proporcionas las calificaciones de un alumno en los datos de entrenamiento, pero no lo haces al momento de la entrega.
Es importante que comprendas los datos de entrenamiento para evitar la filtración de datos y desviaciones entre el entrenamiento y la entrega:
- Antes de usar cualquier tipo de dato, asegúrate de saber qué significa y si debes usarlo como un atributo.
- Verifica la correlación en la pestaña de entrenamiento. Las altas correlaciones se deben marcar para revisarlas luego.
- Desviaciones entre el entrenamiento y la entrega: Asegúrate de proporcionar al modelo solo los atributos de entrada que, al momento de la entrega, no hayan cambiado de ninguna forma.
Borra los datos incompletos, incoherentes y faltantes
Es común que tengas valores faltantes o imprecisos en los datos de ejemplo. Tómate el tiempo para revisar y, cuando sea posible, mejorar la calidad de los datos antes de usarlos en el entrenamiento. Cuantos más valores faltantes haya, menos útil serán tus datos a la hora de entrenar un modelo de aprendizaje automático.
- Busca valores faltantes entre tus datos. Corrígelos cuando sea posible o deja el valor en blanco si la columna es anulable. Vertex AI puede trabajar con valores faltantes, pero es más probable que obtengas resultados óptimos si todos los valores están disponibles.
- Para la previsión, verifica que el intervalo entre filas de entrenamiento sea coherente. Vertex AI puede trabajar con valores faltantes, pero es más probable que obtengas resultados óptimos si todas las filas están disponibles.
- Realiza una limpieza de tus datos: corrige o borra los errores de datos o información irrelevante. Haz que tus datos sean coherentes: revisa la ortografía, las abreviaturas y el formato.
Analiza tus datos después de importarlos
Vertex AI proporciona una descripción general de tu conjunto de datos después de que se importa. Revisa el conjunto de datos importado para asegurarte de que cada columna tenga el tipo de variable correcto. Vertex AI detectará automáticamente el tipo de variable según los valores de las columnas, pero es mejor revisar cada una. También debes revisar la nulabilidad de cada columna, que determina si una columna puede contener valores faltantes o NULL.
Texto
Después de decidir cuál es la opción adecuada para ti (una división manual o predeterminada), puedes agregar datos en Vertex AI mediante uno de los siguientes métodos:
- Puedes importar datos desde tu computadora o Cloud Storage en formato CSV o JSON Lines con las etiquetas intercaladas, como se especifica en Prepara los datos de entrenamiento. Si deseas dividir tu conjunto de datos de forma manual, puedes especificar las divisiones en tu archivo CSV o JSON Lines.
- Si tus datos no están etiquetados, puedes subir ejemplos de texto sin etiqueta y usar la consola de Vertex AI para aplicar etiquetas.
Video
Después de recopilar los videos que quieres incluir en tu conjunto de datos, debes asegurarte de que contengan etiquetas asociadas con segmentos de video o cuadros de límite. Para el reconocimiento de acciones, el segmento de video es una marca de tiempo. Para la clasificación, el segmento puede ser una foto, un segmento o el video completo. Para el seguimiento de objetos, las etiquetas se asocian con cuadros de límite.
¿Por qué mis videos necesitan cuadros de límite y etiquetas?
En el caso del seguimiento de objetos, ¿cómo aprende un modelo de Vertex AI a identificar patrones? Para esto son los cuadros de límite y etiquetas durante el entrenamiento. Toma el ejemplo del fútbol: cada video de ejemplo deberá contener cuadros de límite alrededor de los objetos que te interesa detectar. Esos cuadros también necesitan tener etiquetas asignadas, como “persona” y “bola”. De lo contrario, el modelo no sabrá qué debe buscar. Dibujar cuadros y asignar etiquetas a tus videos de ejemplo puede demandar tiempo.
Si tus datos aún no están etiquetados, también puedes subir los videos sin etiqueta y usar la consola de Google Cloud para aplicar cuadros de límite y etiquetas. Para obtener más información, consulta Etiqueta datos con la consola de Google Cloud.
Entrenar modelo
Imagen
Considera cómo Vertex AI usa tu conjunto de datos para crear un modelo personalizado
Tu conjunto de datos contiene conjuntos de entrenamiento, validación y prueba. Si no especificas las divisiones (consulta Prepara tus datos), Vertex AI usa de forma automática el 80% de tus imágenes para entrenamiento, el 10% para validación y el 10% para pruebas.
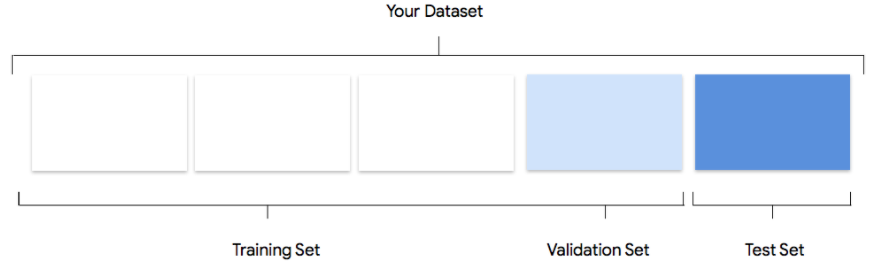
Conjunto de entrenamiento
 La gran mayoría de tus datos deben estar en el conjunto de entrenamiento. Estos son los datos que tu modelo “ve” durante el entrenamiento; se usan para aprender los parámetros del modelo, es decir, el peso de las conexiones entre los nodos de la red neuronal.
La gran mayoría de tus datos deben estar en el conjunto de entrenamiento. Estos son los datos que tu modelo “ve” durante el entrenamiento; se usan para aprender los parámetros del modelo, es decir, el peso de las conexiones entre los nodos de la red neuronal.
Conjunto de validación
 El conjunto de validación, a veces llamado conjunto “dev”, también se usa durante el proceso de entrenamiento.
Después de que el marco de trabajo del modelo de aprendizaje incorpora datos de entrenamiento durante cada iteración del proceso de entrenamiento, usa el rendimiento del modelo en el conjunto de validación para ajustar sus hiperparámetros, que son variables que especifican la estructura del modelo. Si intentaste usar el conjunto de entrenamiento para ajustar los hiperparámetros, es muy probable que el modelo se centre demasiado en tus datos de entrenamiento y le cueste generalizar ejemplos que no coincidan con exactitud.
Si usas un conjunto de datos un tanto nuevo para configurar la estructura del modelo, este realizará mejores generalizaciones.
El conjunto de validación, a veces llamado conjunto “dev”, también se usa durante el proceso de entrenamiento.
Después de que el marco de trabajo del modelo de aprendizaje incorpora datos de entrenamiento durante cada iteración del proceso de entrenamiento, usa el rendimiento del modelo en el conjunto de validación para ajustar sus hiperparámetros, que son variables que especifican la estructura del modelo. Si intentaste usar el conjunto de entrenamiento para ajustar los hiperparámetros, es muy probable que el modelo se centre demasiado en tus datos de entrenamiento y le cueste generalizar ejemplos que no coincidan con exactitud.
Si usas un conjunto de datos un tanto nuevo para configurar la estructura del modelo, este realizará mejores generalizaciones.
Conjunto de prueba
 El conjunto de prueba no interviene para nada en el proceso de entrenamiento. Una vez que el modelo completa todo su entrenamiento, usamos el conjunto de prueba como un desafío nuevo para tu modelo. El rendimiento de tu modelo en el conjunto de prueba sirve para darte una idea bastante clara de cómo será su rendimiento en datos del mundo real.
El conjunto de prueba no interviene para nada en el proceso de entrenamiento. Una vez que el modelo completa todo su entrenamiento, usamos el conjunto de prueba como un desafío nuevo para tu modelo. El rendimiento de tu modelo en el conjunto de prueba sirve para darte una idea bastante clara de cómo será su rendimiento en datos del mundo real.
División manual
 También puedes dividir tu conjunto de datos. La división manual de datos es una buena opción cuando deseas ejercer más control sobre el proceso o si hay ejemplos específicos que deseas incluir en una parte determinada del ciclo de vida del entrenamiento del modelo.
También puedes dividir tu conjunto de datos. La división manual de datos es una buena opción cuando deseas ejercer más control sobre el proceso o si hay ejemplos específicos que deseas incluir en una parte determinada del ciclo de vida del entrenamiento del modelo.
Tabular
Después de importar tu conjunto de datos, el siguiente paso es entrenar un modelo. Vertex AI generará un modelo de aprendizaje automático confiable con los valores predeterminados de entrenamiento, pero te recomendamos cambiar algunos de los parámetros según tu caso de uso.
Para el entrenamiento, intenta seleccionar tantas columnas de atributos como sea posible, pero revisa cada una con el fin de asegurarte de que sean adecuadas para el entrenamiento. Ten en cuenta las siguientes consideraciones para la selección de atributos:
- No selecciones columnas de atributos que generen información irrelevante, como columnas de identificadores asignados de forma aleatoria con un valor único para cada fila.
- Asegúrate de comprender cada columna de atributos y sus valores.
- Si creas varios modelos a partir de un conjunto de datos, quita las columnas objetivo que no formen parte del problema de predicción actual.
- Recuerda los principios de equidad: ¿Entrenaste tu modelo con un atributo que podría llevar a una toma de decisiones sesgada o injusta hacia los grupos marginados?
Cómo Vertex AI usa tu conjunto de datos
Tu conjunto de datos se dividirá en grupos de entrenamiento, validación y prueba. La división predeterminada que Vertex AI aplica depende del tipo de modelo que entrenes. También puedes especificar las divisiones (divisiones manuales) si es necesario. Para obtener más información, consulta Acerca de las divisiones de datos para los modelos de AutoML.
Conjunto de entrenamiento
La gran mayoría de tus datos deben estar en el conjunto de entrenamiento. Estos son los datos que tu modelo “ve” durante el entrenamiento; se usan para aprender los parámetros del modelo, es decir, el peso de las conexiones entre los nodos de la red neuronal.
Conjunto de validación
El conjunto de validación, a veces llamado conjunto “dev”, también se usa durante el proceso de entrenamiento.
Después de que el marco de trabajo del modelo de aprendizaje incorpora datos de entrenamiento durante cada iteración del proceso de entrenamiento, usa el rendimiento del modelo en el conjunto de validación para ajustar sus hiperparámetros, que son variables que especifican la estructura del modelo. Si intentaste usar el conjunto de entrenamiento para ajustar los hiperparámetros, es muy probable que el modelo se centre demasiado en tus datos de entrenamiento y le cueste generalizar ejemplos que no coincidan con exactitud.
Si usas un conjunto de datos un tanto nuevo para configurar la estructura del modelo, este realizará mejores generalizaciones.
Conjunto de prueba
El conjunto de prueba no interviene para nada en el proceso de entrenamiento. Luego de que el modelo completó su entrenamiento por completo, Vertex AI usa el conjunto de prueba como un nuevo desafío para tu modelo.
El rendimiento de tu modelo en el conjunto de prueba sirve para darte una idea bastante clara de cómo será su rendimiento en datos del mundo real.
Texto
Considera cómo Vertex AI usa tu conjunto de datos para crear un modelo personalizado.
Tu conjunto de datos contiene conjuntos de entrenamiento, validación y prueba. Si no especificas las divisiones como se explica en la sección Prepara los datos, Vertex AI usa de forma automática el 80% de tus documentos de contenido para el entrenamiento, el 10% para la validación y el 10% para pruebas.
Conjunto de entrenamiento
La gran mayoría de tus datos deben estar en el conjunto de entrenamiento. Estos son los datos que tu modelo “ve” durante el entrenamiento; se usan para aprender los parámetros del modelo, es decir, el peso de las conexiones entre los nodos de la red neuronal.
Conjunto de validación
El conjunto de validación, a veces llamado conjunto “dev”, también se usa durante el proceso de entrenamiento.
Después de que el marco de trabajo del modelo de aprendizaje incorpora datos de entrenamiento durante cada iteración del proceso de entrenamiento, usa el rendimiento del modelo en el conjunto de validación para ajustar sus hiperparámetros, que son variables que especifican la estructura del modelo. Si intentaste usar el conjunto de entrenamiento para ajustar los hiperparámetros, es muy probable que el modelo se centre demasiado en tus datos de entrenamiento y le cueste generalizar ejemplos que no coincidan con exactitud.
Si usas un conjunto de datos un tanto nuevo para configurar la estructura del modelo, este realizará mejores generalizaciones.
Conjunto de prueba
El conjunto de prueba no interviene para nada en el proceso de entrenamiento. Luego de que el modelo completa todo su entrenamiento, usamos el conjunto de prueba como un desafío nuevo para tu modelo. El rendimiento de tu modelo en el conjunto de prueba sirve para darte una idea bastante clara de cómo será su rendimiento en datos del mundo real.
División manual
También puedes dividir tu conjunto de datos. La división manual de datos es una buena opción cuando deseas ejercer más control sobre el proceso o si hay ejemplos específicos que deseas incluir en una parte determinada del ciclo de vida del entrenamiento del modelo.
Video
Una vez preparados los datos de video de entrenamiento, estarás listo para crear un modelo de aprendizaje automático. Ten en cuenta que puedes crear conjuntos de anotaciones para diferentes objetivos del modelo en el mismo conjunto de datos. Consulta Crea un conjunto de anotaciones.
Uno de los beneficios de Vertex AI es que los parámetros predeterminados te guiarán para obtener un modelo de aprendizaje automático confiable. Sin embargo, es posible que debas ajustar los parámetros según la calidad de los datos y el resultado que deseas obtener. Por ejemplo:
- El Tipo de predicción es el nivel de detalle con el que se procesan tus videos.
- La velocidad de fotogramas es importante si las etiquetas que intentas clasificar son sensibles a los cambios de movimiento, como en el reconocimiento de acciones. Por ejemplo, considera correr o caminar. Un clip de una persona caminando con una velocidad de fotogramas por segundo (FPS) baja puede parecer una persona corriendo. En cuanto al seguimiento de objetos, también es sensible a la velocidad de fotogramas. En esencia, el objeto al que se le realiza un seguimiento debe tener suficiente superposición entre los fotogramas adyacentes.
- La resolución para el seguimiento de objetos es más importante de lo que es para el reconocimiento de acciones o la clasificación de videos. Cuando los objetos sean pequeños, asegúrate de subir videos con una resolución más alta. La canalización actual usa 256x256 para el entrenamiento normal o 512x512 si hay demasiados objetos pequeños (cuya área es menor al 1% del área de la imagen) en los datos del usuario. Se recomienda usar videos de al menos 256p. El uso de videos con una resolución más alta puede no ayudar a mejorar el rendimiento del modelo porque, internamente, a los fotogramas del video se les realiza una reducción de muestreo para aumentar la velocidad de inferencia y el entrenamiento.
Evalúa, implementa y prueba tu modelo
Evaluar el modelo
Imagen
Luego de que tu modelo esté entrenado, recibirás un resumen de su rendimiento. Haz clic en evaluar o ver evaluación completa a fin de ver un análisis detallado.
 La depuración de un modelo es más bien una depuración de los datos que del modelo en sí. Si en algún momento tu modelo comienza a actuar de manera inesperada mientras evalúas su rendimiento antes y después de pasar a producción, debes regresar y verificar los datos para ver dónde podrían realizarse mejoras.
La depuración de un modelo es más bien una depuración de los datos que del modelo en sí. Si en algún momento tu modelo comienza a actuar de manera inesperada mientras evalúas su rendimiento antes y después de pasar a producción, debes regresar y verificar los datos para ver dónde podrían realizarse mejoras.
¿Qué tipos de análisis puedo realizar en Vertex AI?
En la sección de evaluación de Vertex Ai, puedes evaluar el rendimiento de tu modelo personalizado con el resultado del modelo en los ejemplos de prueba y las métricas comunes del aprendizaje automático. En esta sección, abordaremos el significado de cada uno de estos conceptos.
- La salida del modelo
- El límite de puntuación
- Positivos verdaderos, negativos verdaderos, falsos positivos y falsos negativos
- Precisión y recuperación
- Curvas de precisión y recuperación
- Precisión promedio
¿Cómo interpreto el resultado del modelo?
Vertex AI extrae ejemplos de tus datos de prueba a fin de presentar desafíos completamente nuevos para tu modelo. Para cada ejemplo, el modelo genera una serie de números que reflejan el grado de confianza con el que asocia cada etiqueta con ese ejemplo. Si el número es alto, el modelo tiene una confianza alta en que la etiqueta se debe aplicar a ese documento.

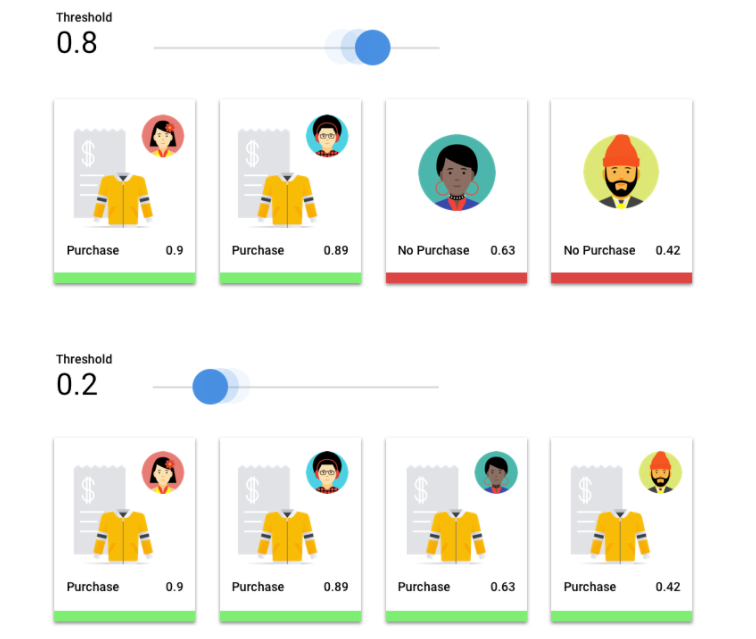
¿Cuál es el umbral de puntuación?
Podemos convertir estas probabilidades en valores binarios de “encendido” y “apagado” si establecemos un umbral de puntuación.
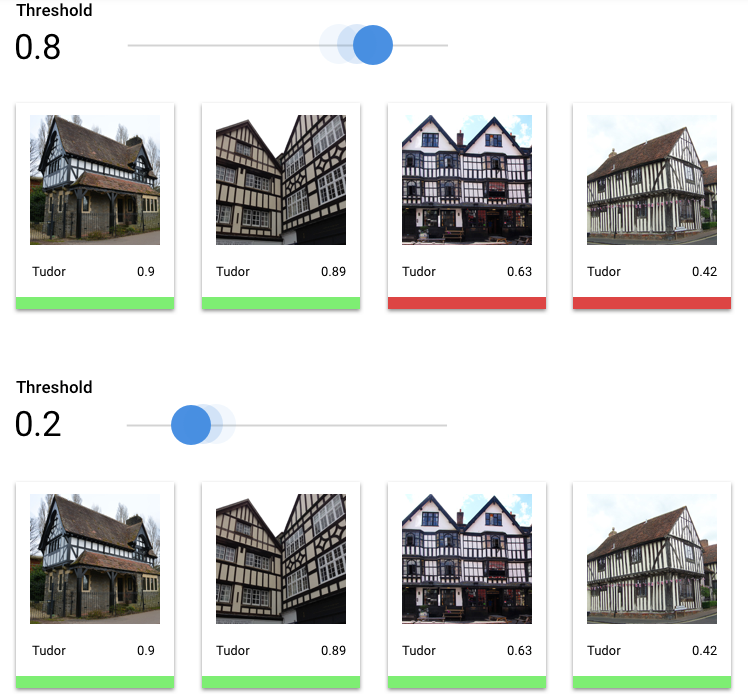
El umbral de puntuación se refiere al nivel de confianza que debe tener el modelo para asignar una categoría a un elemento de prueba. El control deslizante del umbral de puntuación en la consola de Google Cloud es una herramienta visual que prueba el efecto de diferentes umbrales para todas las categorías y categorías individuales en el conjunto de datos.
Si el umbral de puntuación es bajo, tu modelo clasificará más imágenes, pero corres el riesgo de clasificar de forma errónea algunas imágenes en el proceso. Si tu límite de puntuación es alto, tu modelo clasifica menos imágenes, pero tiene un riesgo menor de clasificar de manera incorrecta las imágenes. Puedes modificar los límites por categoría en la consola de Google Cloud para experimentar. Sin embargo, cuando uses tu modelo en producción, debes aplicar los umbrales que consideras óptimos.
¿Qué son los verdaderos positivos, los verdaderos negativos, los falsos positivos y los falsos negativos?
Después de aplicar el umbral de puntuación, las predicciones que haga tu modelo entrarán en una de las cuatro categorías siguientes:
Los umbrales que consideraste óptimos de tu lado.
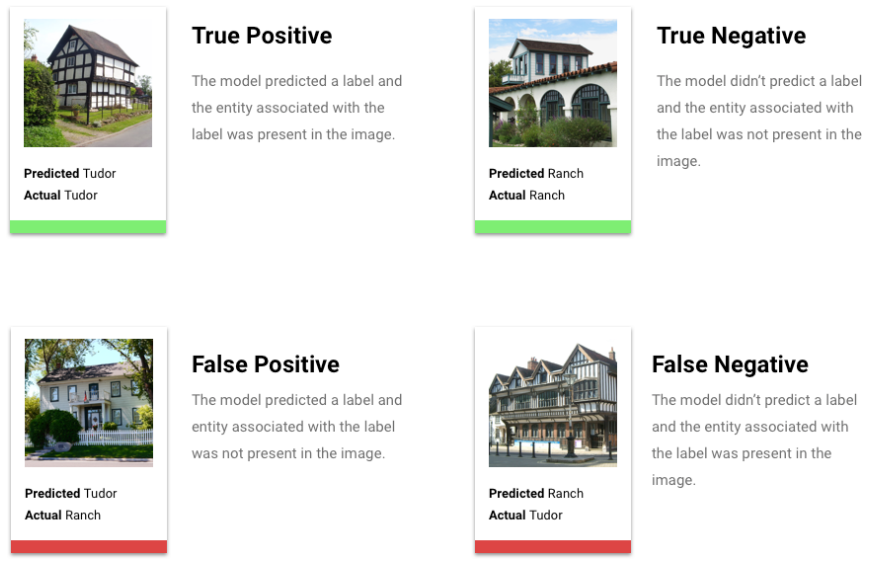
Podemos usar estas categorías para calcular la precisión y la recuperación, métricas que nos ayudan a medir la eficacia de nuestro modelo.
¿Qué son la precisión y la recuperación?
La precisión y la recuperación nos ayudan a comprender qué tan bien nuestro modelo captura información y cuánta omite. La precisión nos dice cuántos de todos los ejemplos de prueba a los que se asignó una etiqueta se categorizaron de forma correcta. La recuperación nos dice cuántos de todos los ejemplos de prueba a los que debía asignarse una etiqueta determinada se etiquetaron de forma correcta.
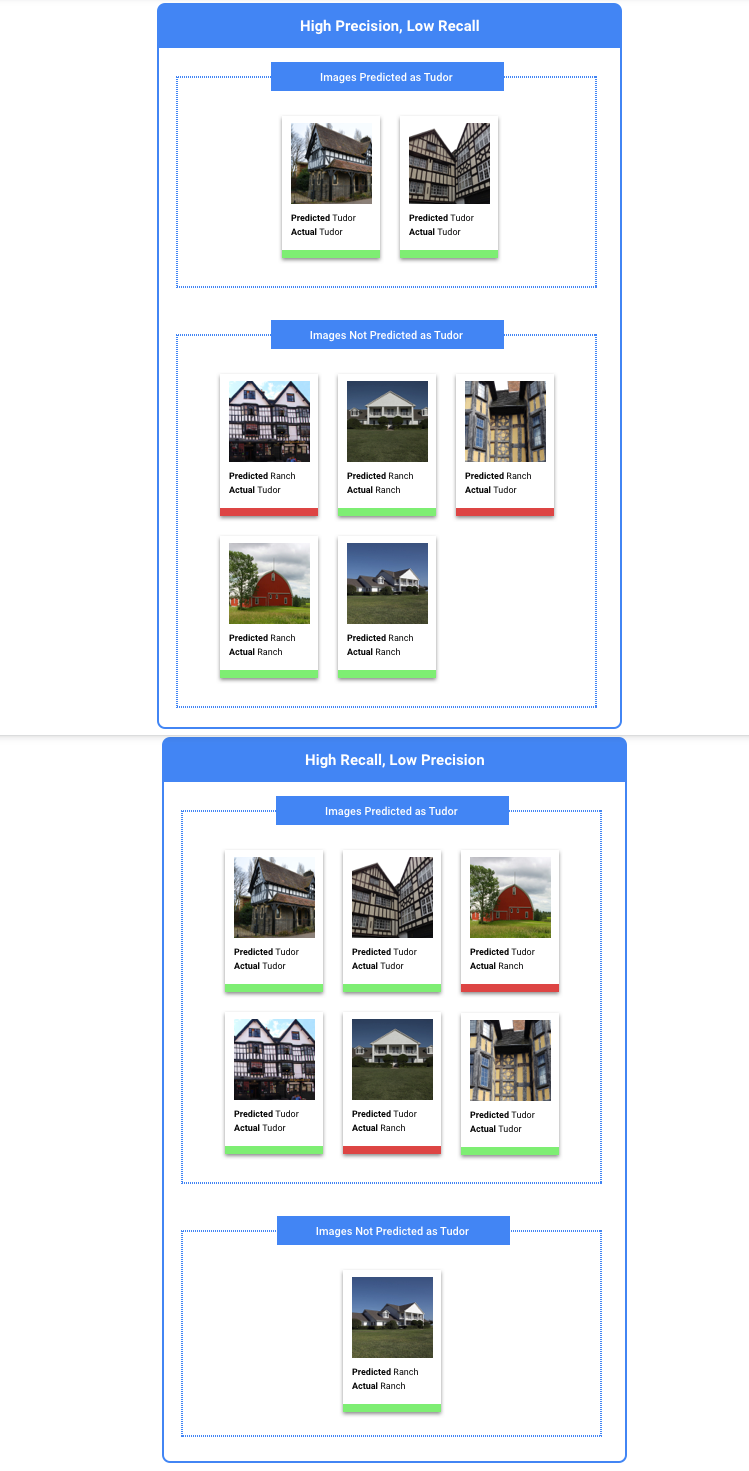
¿Debo optimizar la precisión o la recuperación?
Según tu caso de uso, puedes optimizar la precisión o la recuperación. Considera los siguientes dos casos de uso cuando decidas qué enfoque funciona mejor.
Caso de uso: Privacidad en las imágenes
Supongamos que deseas crear un sistema que detecte de forma automática la información sensible y la difumine.

Los falsos positivos en este caso serían objetos que se difuminan por error, lo que puede ser molesto, pero no perjudicial.

Los falsos negativos en este caso serían objetos que se dejaron sin difuminar por error, como una tarjeta de crédito, lo que puede llevar a un robo de identidad.
En este caso, debes optimizar la recuperación. Esta métrica determina cuánto se omite en todas las predicciones realizadas. Es probable que un modelo de recuperación alta etiquete ejemplos apenas relevantes. Esto es útil para los casos en los que tu categoría tiene pocos datos de entrenamiento.
Caso práctico: búsqueda de fotografías de archivo
Supongamos que deseas crear un sistema que encuentre la mejor fotografía de archivo para una palabra clave determinada.

Un falso positivo en este caso mostraría una imagen irrelevante. Como se supone que tu producto muestra solo las imágenes que mejor coinciden, el resultado obtenido sería un gran fracaso.

Un falso negativo en este caso sería no mostrar una imagen relevante en una búsqueda por palabra clave.
Ya que muchos términos de búsqueda tienen miles de fotos con una sólida coincidencia posible, esto no es un problema.
En este caso, debes optimizar la precisión. Esta métrica determina qué tan correctas son todas las predicciones hechas. Es probable que un modelo de alta precisión etiquete solo los ejemplos más relevantes, lo cual es útil para los casos en los que tu clase es común en los datos de entrenamiento.
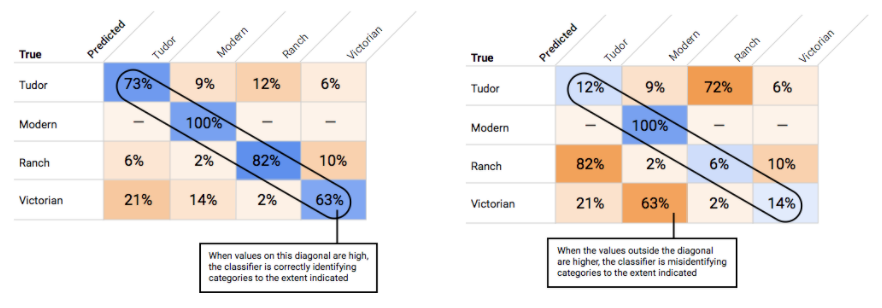
¿Cómo uso la matriz de confusión?
¿Cómo interpreto las curvas de precisión-recuperación?
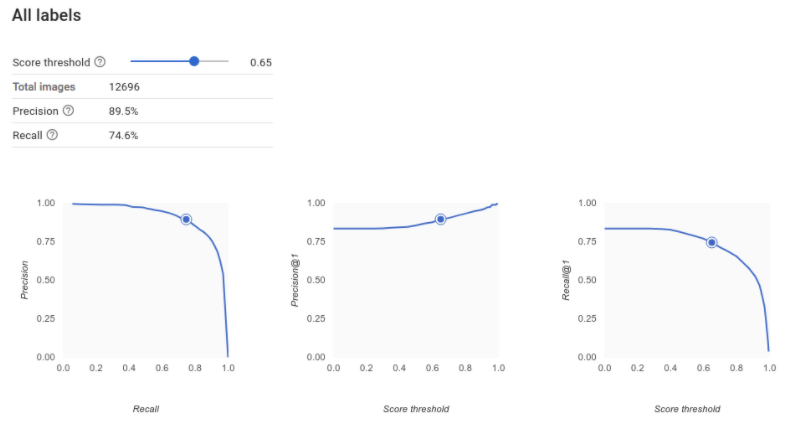
La herramienta de umbral de puntuación te permite explorar cómo el umbral de puntuación elegido afecta la precisión y la recuperación. A medida que arrastras el control deslizante en la barra del umbral de puntuación, puedes ver dónde te sitúa ese umbral en la curva de balance de precisión-recuperación y cómo afecta a tu precisión y recuperación individualmente (para modelos multiclase, la única etiqueta que se usa en estos grafos a fin de calcular las métricas de precisión y recuperación es la que tiene la puntuación más alta en el conjunto que mostramos). Esto puede ayudarte a encontrar un buen balance entre falsos positivos y falsos negativos.
Una vez que eliges un umbral aceptable para tu modelo en general, puedes hacer clic en etiquetas individuales y ver dónde se ubica ese umbral en la curva de precisión-recuperación correspondiente. En algunos casos, del resultado podría inferirse que obtienes muchas predicciones incorrectas para pocas etiquetas, lo que tal vez te ayude a elegir un umbral por clase personalizado para esas etiquetas. Por ejemplo, supongamos que revisas tu conjunto de datos de casas y observas que un umbral de 0.5 tiene una precisión y recuperación razonables para todos los tipos de imagen, excepto “Tudor”, tal vez porque es una categoría muy general. En esa categoría, encuentras muchos falsos positivos. En ese caso, puedes decidir usar un umbral de 0.8 solo para “Tudor” cuando llames al clasificador a fin de hacer predicciones.
¿Qué es la precisión promedio?
Una métrica útil para la exactitud del modelo es el área bajo la curva de precisión-recuperación. Mide el rendimiento de tu modelo en todos los umbrales de puntuación. En Vertex AI, esta métrica se conoce como Precisión promedio. Cuanto más cerca de 1.0 esté esta puntuación, mejor será el rendimiento de tu modelo en el conjunto de prueba; un modelo que adivine al azar para cada etiqueta obtendría una precisión promedio de alrededor de 0.5.
Tabular
Después del entrenamiento del modelo, recibirás un resumen sobre el rendimiento. Las métricas de evaluación del modelo se basan en cómo se desempeñó ante una porción de tu conjunto de datos (el conjunto de datos de prueba). Hay algunas métricas y conceptos clave que debes tener en cuenta a fin de determinar si tu modelo está listo para usarse con datos reales.
Métricas de clasificación
Umbral de puntuación
Considera un modelo de aprendizaje automático que prediga si el próximo año un cliente comprará una chaqueta o no. ¿Qué tan seguro debe estar el modelo antes de predecir que un cliente determinado comprará una chaqueta? En los modelos de clasificación, a cada predicción se le asigna una puntuación de confianza, una evaluación numérica acerca de la certeza del modelo de que la clase predicha sea correcta. El umbral de puntuación es el número que determina cuándo una puntuación determinada se convierte en una decisión de sí o no; es decir, el valor en el que el modelo dice “sí, esta puntuación de confianza es lo suficientemente alta como para concluir que este cliente comprará un abrigo el próximo año.
Si tu umbral de puntuación es bajo, tu modelo correrá el riesgo de realizar una clasificación errónea. Por ese motivo, el umbral de puntuación debe basarse en un caso práctico determinado.
Resultados de la predicción
Después de aplicar el umbral de puntuación, las predicciones que realice tu modelo se clasificarán en una de cuatro categorías. Para comprender estas categorías, imagina otra vez un modelo de clasificación binaria de chaquetas. En este ejemplo, la clase positiva (lo que el modelo intenta predecir) es si cliente sí comprará una chaqueta el próximo año.
- Verdadero positivo: El modelo predice la clase positiva de forma correcta. El modelo predijo de forma correcta que un cliente compraría una chaqueta.
- Falso positivo: El modelo predice la clase positiva de forma incorrecta. El modelo predijo que un cliente compró una chaqueta, pero este no lo hizo.
- Verdadero negativo: El modelo predice la clase negativa de forma correcta. El modelo predijo de forma correcta que un cliente no compraría una chaqueta.
- Falso negativo: El modelo predice una clase negativa de forma incorrecta. El modelo predijo que un cliente no compraría una chaqueta, pero sí lo hizo.

Precisión y recuperación
Las métricas de precisión y recuperación te ayudan a comprender qué tan bien tu modelo capta información y qué omite. Obtén más información sobre precisión y recuperación.
- La precisión es la fracción correcta de las predicciones positivas. De todas las predicciones de compra de un cliente, ¿qué fracción corresponde a compras reales?
- La recuperación es la fracción de filas con esta etiqueta que el modelo predijo de forma correcta. De todas las compras de los consumidores que se pudieron haber identificado, ¿qué fracción efectivamente se identificó?
Según el caso práctico, es posible que debas optimizar la precisión o la recuperación.
Otras métricas de clasificación
- AUC PR: El área bajo la curva de precisión y recuperación (PR). Esta medida puede variar de cero a uno, y cuanto más alto sea su valor, mejor será la calidad del modelo.
- AUC ROC: El área bajo la curva de característica operativa del receptor (ROC). Esta puede variar de cero a uno y cuanto más alto sea su valor, mejor será la calidad del modelo.
- Exactitud: La fracción de predicciones de clasificación correctas que produjo el modelo.
- Pérdida logística: La entropía cruzada entre las predicciones del modelo y los valores objetivo. Esta medida puede variar de cero a infinito y, cuanto más bajo sea su valor, mejor será la calidad del modelo.
- Puntuación F1: La media armónica de precisión y recuperación. F1 es una métrica útil si lo que buscas es un equilibrio entre la precisión y la recuperación, y tienes una distribución de clases despareja.
Métricas de regresión y previsión
Una vez que se compila el modelo, Vertex AI proporciona una variedad de métricas estándar para que revises. No hay una respuesta perfecta sobre cómo evaluar tu modelo. Considera las métricas de evaluación en el contexto del tipo de problema y lo que quieras lograr con el modelo. En la siguiente lista, se muestra una descripción general de algunas métricas que puede proporcionar Vertex AI.
Error absoluto medio (MAE)
MAE es la diferencia absoluta promedio entre los valores objetivo y valores predichos. Determina la magnitud promedio de los errores (la diferencia entre un valor objetivo y uno predicho) en un conjunto de predicciones. Además, como usa valores absolutos, MAE no tiene en cuenta la dirección de la relación, ni tampoco indica cuándo el rendimiento está por debajo o por encima del esperado. Cuando se evalúa MAE, cuanto más bajo el valor, mayor será la calidad del modelo (0 representa un predictor perfecto).
Raíz cuadrada del error cuadrático medio (RMSE)
RMSE es la raíz cuadrada de la diferencia cuadrática promedio entre los valores objetivo y valores predichos. La RMSE es más sensible a los valores atípicos que MAE, por lo que, si te preocupan los grandes errores, RMSE puede ser una métrica más útil para evaluar. Al igual que MAE, cuanto más bajo el valor, mayor será la calidad del modelo (0 representa un predictor perfecto).
Raíz cuadrada del error logarítmico cuadrático medio (RMSLE)
RMSLE es RMSE en escala logarítmica. RMSLE es más sensible a los errores relativos que a los absolutos y tiene más en cuenta a los rendimientos por debajo que por encima de lo esperado.
Cuantil observado (solo previsión)
Para un cuantil objetivo determinado, el cuantil observado muestra la fracción real de valores observados por debajo de los valores de predicción del cuantil especificado. El cuantil observado indica cuán cerca el modelo se aproxima al cuantil objetivo. Una diferencia menor entre ambos valores indica un modelo de mayor calidad.
Pérdida escalada de bola de pinball (solo previsión)
Mide la calidad de un modelo en un cuantil objetivo determinado. Un número más bajo indica un modelo de mayor calidad. Puedes comparar la métrica de pérdida escalada de bola de pinball en diferentes cuantiles para determinar la exactitud relativa de tu modelo entre esos diferentes cuantiles.
Texto
Una vez que tu modelo esté entrenado, recibirás un resumen de su rendimiento. Para ver un análisis detallado, haz clic en evaluar o ver la evaluación completa.
¿Qué debo tener en cuenta antes de evaluar mi modelo?
La depuración de un modelo consiste más en depurar los datos que el modelo en sí. Si tu modelo comienza a actuar de manera inesperada mientras evalúas su rendimiento antes y después de pasar a producción, debes regresar y verificar tus datos para ver dónde podrían realizarse mejoras.
¿Qué tipos de análisis puedo realizar en Vertex AI?
En la sección de evaluación de Vertex AI, puedes evaluar el rendimiento de tu modelo personalizado mediante el uso del resultado del modelo en los ejemplos de prueba y las métricas comunes del aprendizaje automático. En esta sección, se explica qué significa cada uno de los siguientes conceptos:
- La salida del modelo
- El límite de puntuación
- Positivos verdaderos, negativos verdaderos, falsos positivos y falsos negativos
- Precisión y recuperación
- Curvas de precisión y recuperación
- Precisión promedio
¿Cómo interpreto el resultado del modelo?
Vertex AI extrae ejemplos de tus datos de prueba a fin de presentar desafíos nuevos para tu modelo. Para cada ejemplo, el modelo genera una serie de números que reflejan el grado de confianza con el que asocia cada etiqueta con ese ejemplo. Si el número es alto, el modelo tiene una confianza alta en que la etiqueta se debe aplicar a ese documento.
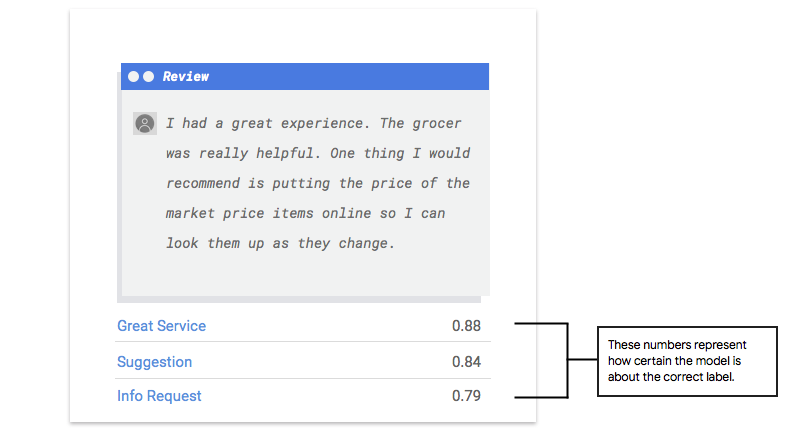
¿Cuál es el umbral de puntuación?
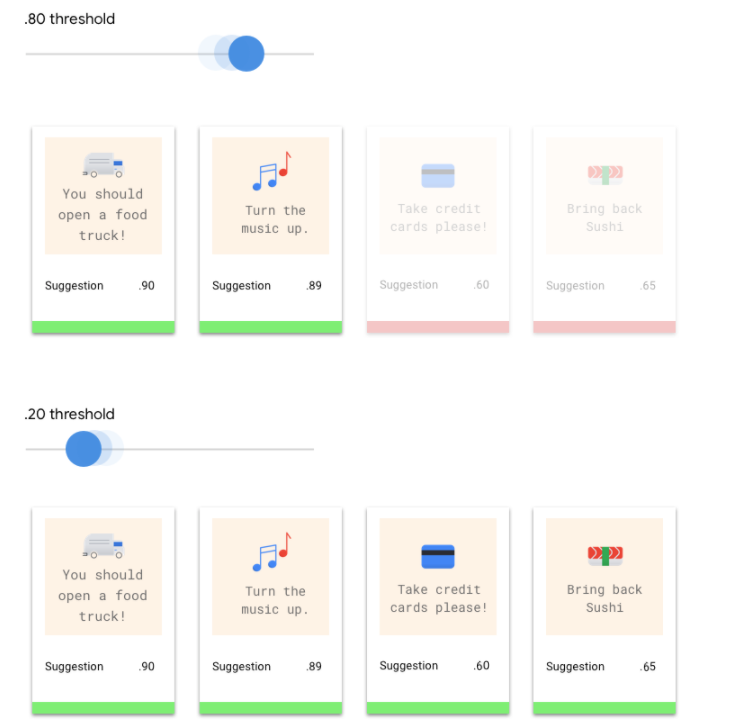
El umbral de puntuación permite que Vertex AI convierta las probabilidades en valores binarios de “encendido” y “apagado”. El umbral de puntuación se refiere al nivel de confianza que debe tener el modelo para asignar una categoría a un elemento de prueba. El control deslizante del límite de puntuación en la consola es una herramienta visual para probar el impacto de diferentes límites en todo el conjunto de datos. En el ejemplo anterior, si establecemos un límite de puntuación de 0.8 para todas las categorías, se asignarán "Gran Servicio" y "Sugerencia", pero no "Solicitud de información". Si tu límite de puntuación es bajo, tu modelo clasificará más elementos de texto, pero corre el riesgo de clasificar erróneamente algunos de ellos en el proceso. Si tu umbral de puntuación es alto, tu modelo clasificará menos elementos de texto, pero tendrá un riesgo menor de clasificarlos de manera errónea. Puedes modificar los límites por categoría en la consola de Google Cloud para experimentar.
Sin embargo, cuando uses tu modelo en producción, debes aplicar los umbrales que consideras óptimos.
¿Qué son los verdaderos positivos, los verdaderos negativos, los falsos positivos y los falsos negativos?
Después de aplicar el umbral de puntuación, las predicciones que haga tu modelo entrarán en una de las siguientes cuatro categorías.
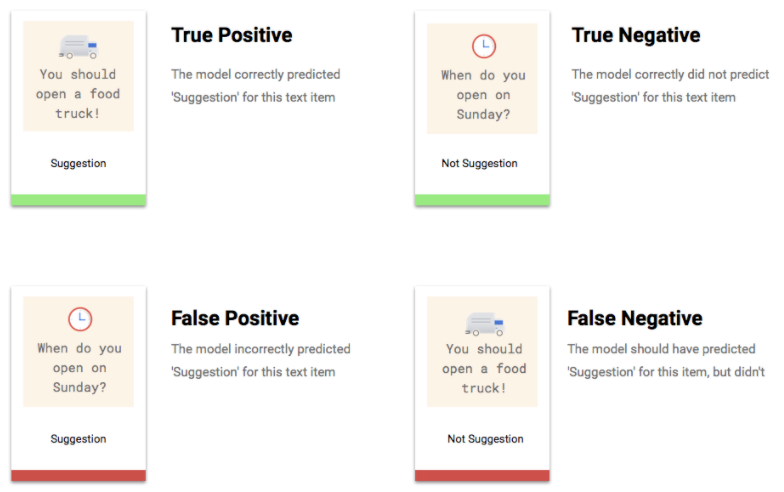
Puedes usar estas categorías para calcular la precisión y la recuperación, métricas que ayudan a medir la eficacia de tu modelo.
¿Qué son la precisión y la recuperación?
La precisión y la recuperación nos ayudan a comprender qué tan bien nuestro modelo captura información y cuánta omite. La precisión nos dice cuántos de todos los ejemplos de prueba a los que se asignó una etiqueta se categorizaron de forma correcta. La recuperación nos dice cuántos de todos los ejemplos de prueba a los que debía asignarse una etiqueta determinada se etiquetaron de forma correcta.
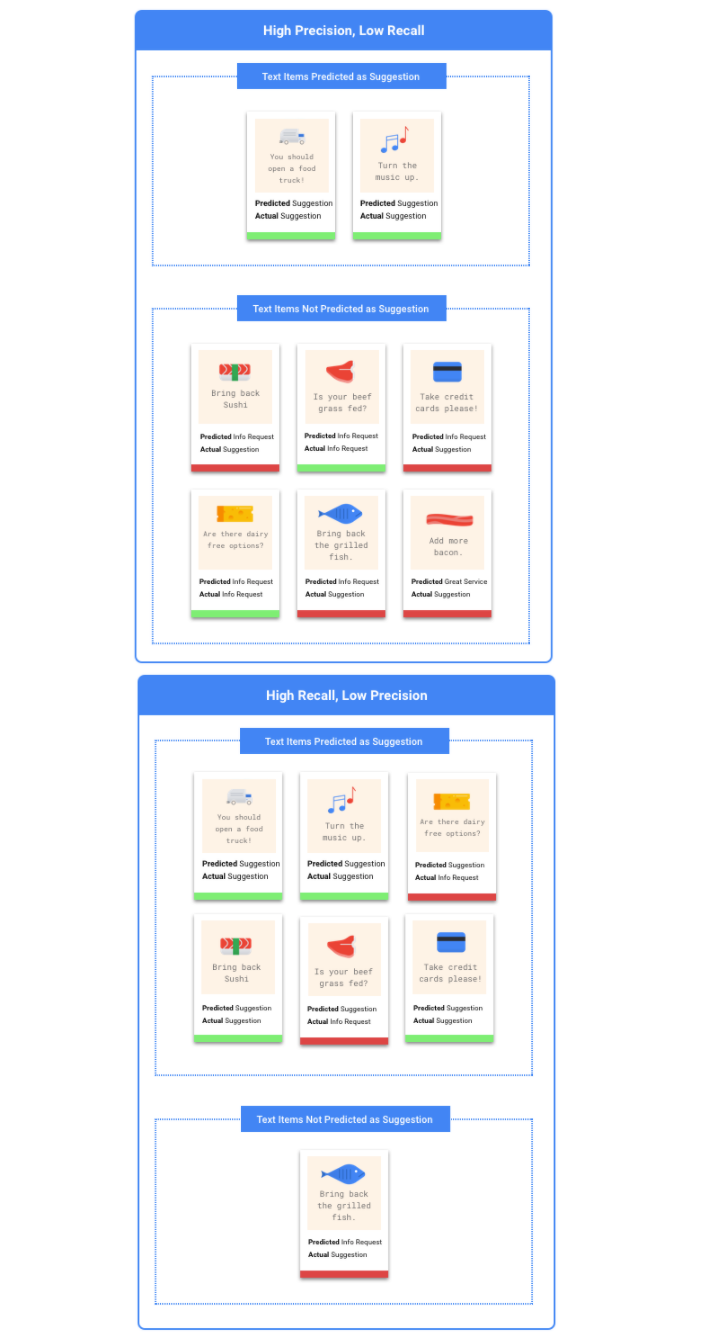
¿Debo optimizar la precisión o la recuperación?
Según tu caso de uso, puedes optimizar la precisión o la recuperación. Considera los siguientes dos casos de uso cuando decidas qué enfoque funciona mejor.
Caso de uso: Documentos urgentes
Supongamos que deseas crear un sistema que conceda prioridad a los documentos urgentes con respecto a los que no lo son.

Un falso positivo en este caso sería un documento que no es urgente, pero que se marca como tal.
El usuario puede descartarlo como no urgente y continuar.

En este caso, se produciría un falso negativo si el sistema no logra etiquetar un documento urgente como tal. ¡Esto podría causar problemas!
En este caso, debes optimizar el modelo para la recuperación. Esta métrica determina cuánto se omite en todas las predicciones realizadas. Es probable que un modelo de recuperación alta etiquete ejemplos apenas relevantes. Esto es útil para los casos en los que tu categoría tiene pocos datos de entrenamiento.
Caso práctico: Filtros de spam
Supongamos que deseas crear un sistema que filtre de manera automática los mensajes de correo electrónico que son spam de los que no lo son.

Un falso negativo en este caso sería un correo electrónico spam que no se detecta y que aparece en tu carpeta Recibidos. Por lo general, es un poco molesto.

Un falso positivo en este caso sería un correo electrónico que se marca erróneamente como spam y se quita de tu carpeta de Recibidos. Si el correo electrónico fuera importante, el usuario podría verse afectado de forma negativa.
En este caso, debes optimizar el modelo para la precisión. Esta métrica determina qué tan correctas son todas las predicciones hechas. Es probable que un modelo de precisión alta etiquete solo los ejemplos más relevantes, lo cual es útil para los casos en los que tu categoría es común en los datos de entrenamiento.
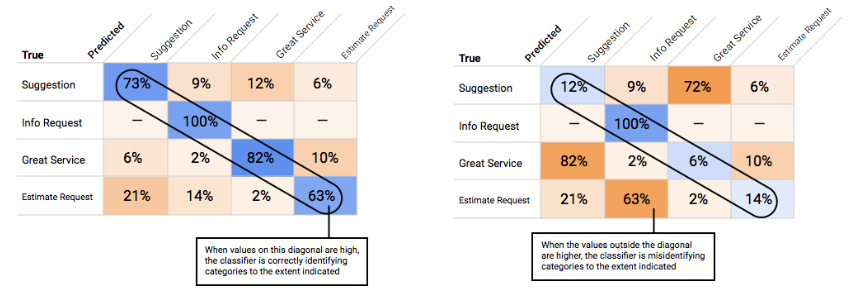
¿Cómo uso la matriz de confusión?
Podemos comparar el rendimiento del modelo en cada etiqueta con una matriz de confusión. En un modelo ideal, todos los valores en la diagonal serán altos y todos los demás valores serán bajos. Esto demuestra que las categorías deseadas se identifican de forma correcta. Si cualquier otro valor es alto, nos da una pista sobre la forma en la que el modelo clasifica los elementos de prueba de manera errónea.
¿Cómo interpreto las curvas de precisión-recuperación?
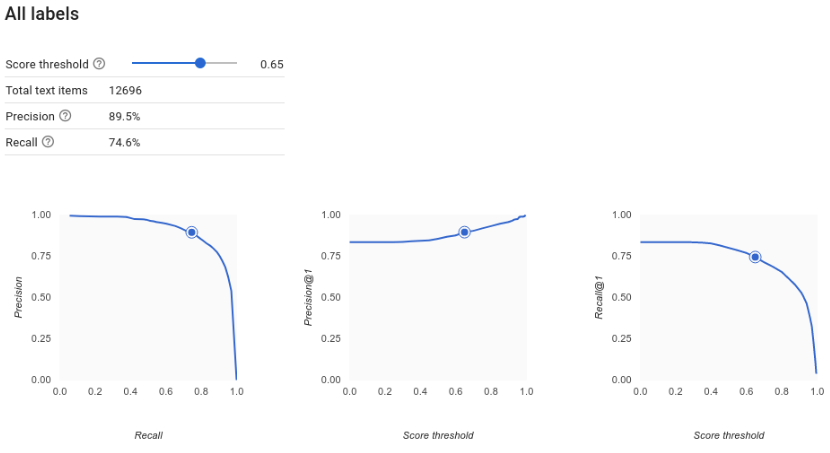
La herramienta de umbral de puntuación te permite explorar cómo el umbral de puntuación elegido afecta la precisión y la recuperación. A medida que arrastras el control deslizante en la barra de umbral de puntuación, puedes ver dónde te sitúa ese umbral en la curva de balance de precisión-recuperación y cómo afecta a tu precisión y recuperación individualmente (para modelos multiclase, la única etiqueta que se usa en estos grafos a fin de calcular las métricas de precisión y recuperación es la que tiene la puntuación más alta en el conjunto que mostramos). Esto puede ayudarte a encontrar un buen balance entre falsos positivos y falsos negativos.
Una vez que eliges un umbral aceptable para el modelo en general, puedes hacer clic en etiquetas individuales y ver dónde se ubica ese umbral en la curva de precisión y recuperación correspondiente. En algunos casos, del resultado podría inferirse que obtienes muchas predicciones incorrectas para pocas etiquetas, lo que tal vez te ayude a elegir un umbral por clase personalizado para esas etiquetas. Por ejemplo, supongamos que revisas tu conjunto de datos de comentarios de clientes y observas que un umbral de 0.5 tiene una precisión y recuperación razonables para todos los tipos de comentarios excepto "Sugerencia", tal vez porque es una categoría muy general. En esa categoría, encuentras muchos falsos positivos. En ese caso, puedes decidir usar un límite de 0.8 solo para "Sugerencia" cuando llames al clasificador para hacer predicciones.
¿Qué es la precisión media?
Una métrica útil para la exactitud del modelo es el área bajo la curva de precisión-recuperación. Mide el rendimiento de tu modelo en todos los umbrales de puntuación. En Vertex AI, esta métrica se conoce como Precisión promedio. Cuanto más cerca de 1.0 esté esta puntuación, mejor será el rendimiento de tu modelo en el conjunto de prueba; un modelo que adivine al azar para cada etiqueta obtendría una precisión promedio de alrededor de 0.5.
Video
Después del entrenamiento del modelo, recibirás un resumen de su rendimiento. Las métricas de evaluación del modelo se basan en cómo se desempeñó ante una porción de tu conjunto de datos (el conjunto de datos de prueba). Hay algunas métricas y conceptos clave que debes tener en cuenta a fin de determinar si tu modelo está listo para usarse con datos nuevos.
Umbral de puntuación
¿Cómo sabe un modelo de aprendizaje automático cuando un gol de fútbol es realmente un gol? A cada predicción se le asigna una puntuación de confianza, que es una evaluación numérica acerca de la certeza del modelo de que un segmento determinado del video contenga una clase. El umbral de puntuación es la cantidad que determina cuándo una puntuación determinada se convierte en una decisión de sí o no. Es decir, es el valor en el que el modelo dice “sí, esta cantidad de confianza es lo suficientemente alta como para concluir que este segmento de video contiene un gol”.

Si tu umbral de puntuación es bajo, tu modelo correrá el riesgo de etiquetar de manera incorrecta segmentos de video. Por ese motivo, el umbral de puntuación debe basarse en un caso práctico determinado. Imagina un caso práctico médico como la detección del cáncer, en el que las consecuencias de realizar un etiquetado incorrecto son más altas que en caso de etiquetar de manera incorrecta videos deportivos. En la detección de cáncer, se recomienda un umbral de puntuación más alto.
Resultados de la predicción
Después de aplicar el umbral de puntuación, las predicciones que realice tu modelo se clasificarán en una de cuatro categorías. Para comprender estas categorías, supongamos que creaste un modelo para detectar si un segmento determinado contiene un gol de fútbol (o no). En este ejemplo, un gol es la clase positiva (lo que el modelo intenta predecir).
- Verdadero positivo: El modelo predice la clase positiva de forma correcta. El modelo predijo correctamente un gol en el segmento de video.
- Falso positivo: El modelo predice la clase positiva de forma incorrecta. El modelo predijo que un gol era parte del segmento, pero no había uno.
- Verdadero negativo: El modelo predice la clase negativa de forma correcta. El modelo predijo correctamente que no había un gol en el segmento.
- Falso negativo: El modelo predice una clase negativa de forma incorrecta. El modelo predijo que no había ningún gol en el segmento, pero había uno.

Precisión y recuperación
Las métricas de precisión y recuperación te ayudan a comprender qué tan bien tu modelo capta información y qué omite. Obtén más información sobre precisión y recuperación.
- La precisión es la fracción correcta de las predicciones positivas. De todas las predicciones etiquetadas como "gol", ¿qué fracción contenía un gol?
- La recuperación es la fracción de todas las predicciones positivas que se identificaron. De todos los goles de fútbol que se pudieron identificar, ¿qué fracción correspondía?
Según el caso práctico, es posible que debas optimizar la precisión o la recuperación. Considera los siguientes casos prácticos.
Caso de uso: Información privada en los videos
Imagina que estás compilando software que detecte automáticamente información sensible en un video y la difumine. Las ramificaciones de los resultados falsos pueden incluir lo siguiente:
- Un falso positivo identifica algo que no necesita ser censurado, pero que se censura de todas formas. Esto puede ser molesto, pero no perjudicial.
- Un falso negativo falla en la identificación de la información que se debe censurar, como el número de una tarjeta de crédito. De esta forma, se mostraría información privada, y es el peor de los casos.
En este caso práctico, es fundamental optimizar para la recuperación a fin de garantizar que el modelo encuentre todos los casos relevantes. Es más probable que un modelo optimizado para la recuperación etiquete ejemplos relevantes de forma marginal, pero que, al mismo tiempo, también etiquete ejemplos incorrectos (que difumine más de lo necesario).
Caso de uso: Búsqueda de videos en stock
Supongamos que deseas crear un software que permita a los usuarios buscar una biblioteca de videos en función de una palabra clave. Considera los resultados incorrectos:
- Un falso positivo muestra un video irrelevante. Dado que tu sistema intenta proporcionar solo videos relevantes, tu software no está cumpliendo con lo que se compiló para hacer.
- Un falso negativo falla en mostrar un video relevante. Debido a que muchas palabras clave tienen cientos de videos, este no es un problema tan grave como mostrar un video irrelevante.
En este ejemplo, querrás optimizar la precisión para asegurarte de que tu modelo genere resultados muy relevantes y correctos. Es probable que un modelo de alta precisión etiquete solo los ejemplos más relevantes, pero que omita algunos. Obtén más información sobre las métricas de evaluación de modelos.
Prueba tu modelo
Imagen
Vertex AI usa el 10% de tus datos de manera automática (o el porcentaje que hayas usado si optaste por la división manual) para probar el modelo, y la página "Evaluación” te informa cómo le fue al modelo con esos datos de prueba. Sin embargo, en caso de que quieras verificar la confianza de tu modelo, hay varias formas de hacerlo. La más sencilla es subir algunas imágenes en la página "Implementación y prueba" y ver las etiquetas que el modelo elige para tus ejemplos. Con suerte, el resultado coincidirá con lo esperado. Prueba varios ejemplos de cada tipo de imagen que esperas recibir.
Si deseas usar tu modelo en tus propias pruebas automatizadas, la página “Implementación y prueba” también te indica cómo realizar llamadas al modelo de manera programática.
Tabular
La evaluación de las métricas de tu modelo es, en esencia, la forma de determinar si el modelo está listo para implementarse, pero también puedes probarlo con datos nuevos. Sube datos nuevos para ver si las predicciones del modelo coinciden con tus expectativas. Según las métricas de evaluación o las pruebas con datos nuevos, es posible que debas seguir mejorando el rendimiento de tu modelo.
Texto
Vertex AI usa el 10% de tus datos de manera automática (o el porcentaje que hayas usado si optaste por la división manual) para probar el modelo, y la página Evaluación te informa cómo le fue al modelo con esos datos de prueba. Sin embargo, en caso de que quieras verificar tu modelo, dispones de varias maneras de hacerlo. Después de implementar tu modelo, puedes ingresar ejemplos de texto en el campo de la página Implementación y prueba, y observar las etiquetas que el modelo elige para tus ejemplos. Con suerte, el resultado coincidirá con lo esperado. Prueba varios ejemplos de cada tipo de comentario que esperas recibir.
Si deseas usar tu modelo en tus propias pruebas automatizadas, la página Implementar y probar proporciona una solicitud a la API de muestra que indica cómo realizar llamadas al modelo de manera programática.
Si deseas usar tu modelo en tus propias pruebas automatizadas, la página Implementar y probar proporciona una solicitud a la API de muestra que indica cómo realizar llamadas al modelo de manera programática.
En la página Predicciones por lotes, puedes crear una predicción por lotes que agrupe muchas solicitudes de predicción en una. Una predicción por lotes es asíncrona, lo que significa que el modelo esperará hasta procesar todas las solicitudes de predicción antes de mostrar resultados.
Video
El video de Vertex AI usa el 20% de tus datos de forma automática (o el porcentaje que hayas usado si optaste por la división manual) para probar el modelo. La pestaña Evaluación de la consola te indica cómo le fue al modelo con los datos de prueba. Sin embargo, en caso de que quieras verificar tu modelo, dispones de varias maneras de hacerlo. Una forma es proporcionar un archivo CSV con datos de video para la prueba en la pestaña "Probar y usar", y ver las etiquetas que el modelo predice para los videos. Esperamos que esto coincida con tus expectativas.
Puedes ajustar el umbral de la visualización de predicciones y ver las predicciones en 3 escalas temporales: intervalos de 1 segundo, capturas de cámara de video después de la detección automática del límite de toma y segmentos completos de videos.
Implementa tu modelo
Imagen
Cuando estés satisfecho con el rendimiento de tu modelo, será momento de usarlo. Quizás eso signifique usarlo en escala de producción o tal vez sea una solicitud de predicción de un solo uso. Según el caso de uso, puedes usar tu modelo de diferentes maneras.
Predicción por lotes
La predicción por lotes es útil para realizar muchas solicitudes de predicción a la vez. La predicción por lotes es asíncrona, lo que significa que el modelo esperará hasta procesar todas las solicitudes de predicción antes de mostrar un archivo de líneas de JSON con valores de predicción.
Predicción en línea
Implementa tu modelo a fin de que esté disponible para las solicitudes de predicción mediante una API de REST. La predicción en línea es síncrona (en tiempo real), lo que significa que mostrará una predicción con rapidez, pero solo acepta una solicitud de predicción por cada llamada a la API. La predicción en línea es útil si tu modelo es parte de una aplicación y si algunas partes de tu sistema dependen de una rápida respuesta de predicción.
Tabular
Cuando estés satisfecho con el rendimiento de tu modelo, será momento de usarlo. Quizás eso signifique usarlo en escala de producción o tal vez sea una solicitud de predicción de un solo uso. Según tu caso práctico, puedes usar tu modelo de diferentes maneras.
Predicción por lotes
La predicción por lotes es útil para realizar muchas solicitudes de predicción a la vez. La predicción por lotes es asíncrona, lo que significa que el modelo esperará hasta procesar todas las solicitudes de predicción antes de mostrar un archivo CSV o una tabla de BigQuery con valores de predicción.
Predicción en línea
Implementa tu modelo a fin de que esté disponible para las solicitudes de predicción mediante una API de REST. La predicción en línea es síncrona (en tiempo real), lo que significa que mostrará una predicción con rapidez, pero solo acepta una solicitud de predicción por cada llamada a la API. La predicción en línea es útil si tu modelo es parte de una aplicación y si algunas partes de tu sistema dependen de una rápida respuesta de predicción.
Video
Cuando estés satisfecho con el rendimiento de tu modelo, será momento de usarlo. Vertex AI usa la predicción por lotes, que te permite subir un archivo CSV con rutas de acceso a videos alojados en Cloud Storage. Tu modelo procesará cada video y generará predicciones en otro archivo CSV. La predicción por lotes es asíncrona, lo que significa que el modelo procesará todas las solicitudes de predicción antes de mostrar los resultados.
Limpia
Para evitar cargos no deseados, anula la implementación de tu modelo cuando no esté en uso.
Cuando termines de usar tu modelo, borra los recursos que creaste para evitar que se generen cargos no deseados en tu cuenta.
- Datos de imagen de Hello: Limpia tu proyecto
- Datos de video de Hello: limpia tu proyecto
- Datos de texto: Limpia tu proyecto
- Datos de video de Hello: limpia tu proyecto