BigQuery unterstützt verschachtelte Datensätze in Tabellen. Verschachtelte Einträge können aus einem einzelnen Eintrag oder aus wiederholten Werten bestehen. Auf dieser Seite finden Sie einen Überblick über die Arbeit mit verschachtelten BigQuery-Daten in Looker.
Vorteile verschachtelter Datensätze
Die Verwendung verschachtelter Einträge beim Scannen eines verteilten Datensatzes bietet einige Vorteile:
- Für verschachtelte Datensätze sind keine Joins erforderlich. Das bedeutet, dass Berechnungen schneller erfolgen und viel weniger Daten gescannt werden müssen, als wenn Sie die zusätzlichen Daten bei jeder Abfrage wieder zusammenführen müssten.
- Verschachtelte Strukturen sind im Grunde vorkonfigurierte Tabellen. Wenn Sie nicht auf die verschachtelte Spalte verweisen, entstehen keine zusätzlichen Kosten für die Abfrage, da BigQuery-Daten in Spalten gespeichert werden. Wenn Sie auf die verschachtelte Spalte verweisen, entspricht die Logik einem zusammenhängenden Join.
- Durch verschachtelte Strukturen werden wiederholte Daten vermieden, die in einer breiten, denormalisierten Tabelle wiederholt werden müssten. Mit anderen Worten: Eine breite, denormalisierte Tabelle würde für eine Person, die in fünf Städten gelebt hat, alle ihre Informationen in fünf Zeilen enthalten (eine für jede der Städte, in denen sie gelebt hat). In einer verschachtelten Struktur nehmen die wiederholten Informationen nur eine Zeile ein, da das Array mit fünf Städten in einer einzigen Zeile enthalten und bei Bedarf entschachtelt werden kann.
Mit verschachtelten Datensätzen in LookML arbeiten
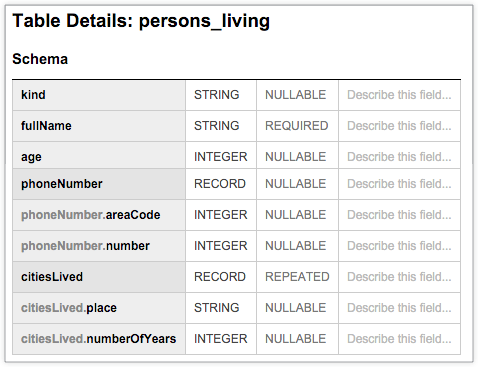
Die folgende BigQuery-Tabelle persons_living zeigt ein typisches Schema mit Beispielnutzerdaten, darunter fullName, age, phoneNumber und citiesLived sowie den Datentyp und den Modus jeder Spalte. Das Schema zeigt, dass sich die Werte in der Spalte citiesLived wiederholen, was darauf hindeutet, dass einige Nutzer in mehreren Städten gelebt haben könnten:
Das folgende Beispiel ist die LookML für die Explores und Ansichten, die Sie anhand des vorherigen Schemas erstellen können. Es gibt drei Ansichten: persons, persons_cities_lived und persons_phone_number. Der Explore sieht identisch aus wie ein Explore, das mit nicht verschachtelten Tabellen geschrieben wird.
Hinweis:Im folgenden Beispiel sind alle Komponenten (Ansichten und Explores) in einem Codeblock geschrieben. Es wird jedoch empfohlen, Ansichten in separaten Ansichtsdateien und Explores und connection:-Spezifikationen in der Modelldatei zu platzieren.
-- model file
connection: "bigquery_publicdata_standard_sql"
explore: persons {
# Repeated nested object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived ;;
relationship: one_to_many
}
# Non repeated nested object
join: persons_phone_number {
view_label: "Persons: Phone:"
sql: LEFT JOIN UNNEST([${persons.phoneNumber}]) as persons_phone_number ;;
relationship: one_to_one
}
}
-- view files
view: persons {
sql_table_name: bigquery-samples.nested.persons_living ;;
dimension: id {
primary_key: yes
sql: ${TABLE}.fullName ;;
}
dimension: fullName {label: "Full Name"}
dimension: kind {}
dimension: age {type:number}
dimension: citiesLived {hidden:yes}
dimension: phoneNumber {hidden:yes}
measure: average_age {
type: average
sql: ${age} ;;
drill_fields: [fullName,age]
}
measure: count {
type: count
drill_fields: [fullName, cities_lived.place_count, age]
}
}
view: persons_phone_number {
dimension: areaCode {label: "Area Code"}
dimension: number {}
}
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${place} AS STRING)) ;;
}
dimension: place {}
dimension: numberOfYears {
label: "Number Of Years"
type: number
}
measure: place_count {
type: count
drill_fields: [place, persons.count]
}
measure: total_years {
type: sum
sql: ${numberOfYears} ;;
drill_fields: [persons.fullName, persons.age, place, numberOfYears]
}
}
Die einzelnen Komponenten für die Arbeit mit verschachtelten Daten in LookML werden in den folgenden Abschnitten ausführlicher beschrieben:
Aufrufe
Jeder verschachtelte Datensatz wird als Ansicht geschrieben. In der phoneNumber-Ansicht werden beispielsweise nur die Dimensionen deklariert, die im Datensatz enthalten sind:
view: persons_phone_number {
dimension: areaCode {label: "Area Code"}
dimension: number {}
}
Die Ansicht persons_cities_lived ist komplexer. Wie im LookML-Beispiel gezeigt, definieren Sie die im Datensatz enthaltenen Dimensionen (numberOfYears und place). Sie können aber auch einige Messwerte definieren. Die Messwerte und drill_fields werden wie gewohnt definiert, als wären diese Daten in einer eigenen Tabelle. Der einzige wirkliche Unterschied besteht darin, dass Sie id als primary_key deklarieren, damit Aggregate richtig berechnet werden.
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${place} AS STRING)) ;;
}
dimension: place {}
dimension: numberOfYears {
label: "Number Of Years"
type: number
}
measure: place_count {
type: count
drill_fields: [place, persons.count]
}
measure: total_years {
type: sum
sql: ${numberOfYears} ;;
drill_fields: [persons.fullName, persons.age, place, numberOfYears]
}
}
Erklärungen erfassen
In der Ansicht, die die untergeordneten Datensätze enthält (in diesem Fall persons), müssen Sie die Datensätze deklarieren. Sie werden beim Erstellen der Joins verwendet. Sie können diese LookML-Felder mit dem Parameter hidden ausblenden, da Sie sie beim Untersuchen der Daten nicht benötigen.
view: persons {
...
dimension: citiesLived {
hidden:yes
}
dimension: phoneNumber {
hidden:yes
}
...
}
Joins
Verschachtelte Einträge in BigQuery sind Arrays von STRUCT-Elementen. Anstatt eine Verbindung mit einem sql_on-Parameter herzustellen, ist die Join-Beziehung in die Tabelle eingebunden. In diesem Fall können Sie den sql:-Join-Parameter verwenden, um den UNNEST-Operator zu verwenden. Abgesehen von dieser Abweichung entspricht das Aufheben des Verschachtelungsstatus eines Arrays von STRUCT-Elementen genau dem Zusammenführen einer Tabelle.
Bei nicht wiederholten Einträgen können Sie einfach STRUCT verwenden. Wenn Sie daraus ein Array von STRUCT-Elementen erstellen möchten, setzen Sie es in eckige Klammern. Das mag zwar seltsam erscheinen, aber es scheint keine Leistungseinbußen zu geben. So bleiben die Dinge übersichtlich und einfach.
explore: persons {
# Repeated nested object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived ;;
relationship: one_to_many
}
# Non repeated nested object
join: persons_phone_number {
view_label: "Persons: Phone:"
sql: LEFT JOIN UNNEST([${persons.phoneNumber}]) as persons_phone_number ;;
relationship: one_to_one
}
}
Zusammenführen von Arrays ohne eindeutige Schlüssel für jede Zeile
Es ist zwar am besten, eindeutige natürliche Schlüssel in den Daten oder im ETL-Prozess erstellte Ersatzschlüssel zu haben, dies ist jedoch nicht immer möglich. Es kann beispielsweise vorkommen, dass einige Arrays keinen relativ eindeutigen Schlüssel für die Zeile haben. Hier kann WITH OFFSET in der Join-Syntax nützlich sein.
Eine Spalte, die eine Person darstellt, wird beispielsweise möglicherweise mehrmals geladen, wenn die Person in mehreren Städten gelebt hat, z. B. in Chicago, Denver und San Francisco. Es kann schwierig sein, einen Primärschlüssel für die nicht verschachtelte Zeile zu erstellen, wenn kein Datum oder ein anderer eindeutiger natürlicher Schlüssel angegeben ist, um den Aufenthalt der Person in jeder Stadt zu unterscheiden. Hier kann WITH OFFSET für jede nicht verschachtelte Zeile eine relative Zeilennummer (0,1,2,3) angeben. Mit diesem Ansatz wird ein eindeutiger Schlüssel für die nicht verschachtelte Zeile garantiert:
explore: persons {
# Repeated nested Object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived WITH OFFSET as person_cities_lived_offset;;
relationship: one_to_many
}
}
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${offset} AS STRING)) ;;
}
dimension: offset {
type: number
sql: person_cities_lived_offset;;
}
}
Einfache wiederholte Werte
Verschachtelte Daten in BigQuery können auch einfache Werte wie Ganzzahlen oder Strings sein. Wenn Sie Arrays mit einfachen wiederholten Werten entschachteln möchten, können Sie einen ähnlichen Ansatz wie oben beschrieben verwenden und den Operator UNNEST in einem Join verwenden.
Im folgenden Beispiel wird ein bestimmtes Array von Ganzzahlen (unresolved_skus) entschachtelt:
explore: impressions {
join: impressions_unresolved_sku {
sql: LEFT JOIN UNNEST(unresolved_skus) AS impressions_unresolved_sku ;;
relationship: one_to_many
}
}
view: impressions_unresolved_sku {
dimension: sku {
type: string
sql: ${TABLE} ;;
}
}
Der Parameter sql für das Array von Ganzzahlen unresolved_skus wird als ${TABLE} dargestellt. Damit wird direkt auf die Wertetabelle verwiesen, die dann in explore entschachtelt wird.