En esta página, se describen las métricas y los paneles disponibles para supervisar la latencia de inicio de las cargas de trabajo de Google Kubernetes Engine (GKE) y los nodos del clúster subyacente. Puedes usar las métricas para hacer un seguimiento de la latencia del inicio, solucionar problemas relacionados con ella y reducirla.
Esta página está destinada a los administradores y operadores de la plataforma que necesitan supervisar y optimizar la latencia de inicio de sus cargas de trabajo. Para obtener más información sobre los roles comunes a los que hacemos referencia en el contenido de Google Cloud , consulta Roles de usuario y tareas comunes de GKE Enterprise.
Descripción general
La latencia de inicio afecta significativamente la forma en que tu aplicación responde a los picos de tráfico, la rapidez con la que sus réplicas se recuperan de las interrupciones y la eficiencia de los costos operativos de tus clústeres y cargas de trabajo. Supervisar la latencia de inicio de tus cargas de trabajo puede ayudarte a detectar degradaciones de la latencia y hacer un seguimiento del impacto de las actualizaciones de la carga de trabajo y la infraestructura en la latencia de inicio.
Optimizar la latencia de inicio de la carga de trabajo tiene los siguientes beneficios:
- Reduce la latencia de respuesta de tu servicio a los usuarios durante los aumentos repentinos de tráfico.
- Reduce el exceso de capacidad de entrega que se necesita para absorber los picos de demanda mientras se crean réplicas nuevas.
- Reduce el tiempo de inactividad de los recursos que ya se implementaron y esperan a que se inicien los recursos restantes durante los cálculos por lotes.
Antes de comenzar
Antes de comenzar, asegúrate de haber realizado las siguientes tareas:
- Habilita la API de Google Kubernetes Engine. Habilitar la API de Google Kubernetes Engine
- Si deseas usar Google Cloud CLI para esta tarea, instala y, luego, inicializa gcloud CLI. Si ya instalaste gcloud CLI, ejecuta el comando
gcloud components updatepara obtener la versión más reciente. Es posible que las versiones anteriores de gcloud CLI no admitan la ejecución de los comandos que se describen en este documento.
Habilita las APIs de Cloud Logging y Cloud Monitoring.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Requisitos
Para ver las métricas y los paneles de la latencia de inicio de las cargas de trabajo, tu clúster de GKE debe cumplir con los siguientes requisitos:
- Debes tener la versión 1.31.1-gke.1678000 de GKE o una posterior.
- Debes configurar la recopilación de métricas del sistema.
- Debes configurar la recopilación de registros del sistema.
- Habilita las métricas de estado de kube con el componente
PODen tus clústeres para ver las métricas de Pod y de contenedor.
Roles y permisos requeridos
Para obtener los permisos que necesitas para habilitar la generación de registros y acceder a ellos y procesarlos, pídele a tu administrador que te otorgue los siguientes roles de IAM:
-
Consulta los clústeres, los nodos y las cargas de trabajo de GKE:
Visualizador de Kubernetes Engine (
roles/container.viewer) en tu proyecto -
Accede a las métricas de latencia de inicio y visualiza los paneles:
Visualizador de Monitoring (
roles/monitoring.viewer) en tu proyecto -
Accede a los registros con información de latencia, como los eventos de extracción de imágenes de Kubelet, y visualízalos en el Explorador de registros y en Estadísticas de registros:
Visualizador de registros (
roles/logging.viewer) en tu proyecto
Para obtener más información sobre cómo otorgar roles, consulta Administra el acceso a proyectos, carpetas y organizaciones.
También puedes obtener los permisos necesarios a través de roles personalizados o cualquier otro rol predefinido.
Métricas de latencia de inicio
Las métricas de latencia de inicio se incluyen en las métricas del sistema de GKE y se exportan a Cloud Monitoring en el mismo proyecto que el clúster de GKE.
Los nombres de las métricas de Cloud Monitoring que figuran en esta tabla deben tener el prefijo
kubernetes.io/. Sin embargo, el prefijo se omitió en las
entradas de la tabla.
| Tipo de métrica (Niveles de jerarquía de recursos) Nombre visible |
|
|---|---|
|
Clase, tipo, unidad
Recursos supervisados |
Descripción Etiquetas |
pod/latencies/pod_first_ready
(proyecto)
Latencia de "listo" inicial de Pod |
|
GAUGE, Double, s
k8s_pod |
Latencia de inicio de extremo a extremo del Pod (desde el Pod Created hasta el Ready), incluidas las extracciones de imágenes. Se tomaron muestras cada 60 segundos. |
node/latencies/startup
(proyecto)
Latencia de inicio del nodo |
|
GAUGE, INT64, s
k8s_node |
Es la latencia total de inicio del nodo, desde la instancia de CreationTimestamp de GCE hasta Kubernetes node ready por primera vez. Se tomaron muestras cada 60 segundos.accelerator_family: Es una clasificación de los nodos según los aceleradores de hardware: gpu, tpu, cpu.
kube_control_plane_available: Indica si se recibió la solicitud de creación del nodo cuando KCP (plano de control de kube) estaba disponible.
|
autoscaler/latencies/per_hpa_recommendation_scale_latency_seconds
(proyecto)
Latencia de escala por recomendación de HPA |
|
GAUGE, DOUBLE, s
k8s_scale |
Latencia de la recomendación de ajuste de escala del escalador automático horizontal de Pods (HPA) para el destino del HPA (tiempo transcurrido entre la creación de las métricas y la aplicación de la recomendación de ajuste de escala correspondiente al servidor de la API) Se hace un muestreo cada 60 segundos. Luego del muestreo, los datos no son visibles durante un máximo de 20 segundos.metric_type: Es el tipo de fuente de la métrica. Debe ser uno de los siguientes: "ContainerResource", "External", "Object", "Pods" o "Resource".
|
Consulta el panel de latencia de inicio para las cargas de trabajo
El panel Latencia de inicio para cargas de trabajo solo está disponible para implementaciones. Para ver las métricas de latencia de inicio de las implementaciones, realiza los siguientes pasos en la consola de Google Cloud :
Ir a la página Cargas de trabajo.
Para abrir la vista Detalles de la implementación, haz clic en el nombre de la carga de trabajo que deseas inspeccionar.
Haz clic en la pestaña Observabilidad.
Selecciona Latencia de inicio en el menú de la izquierda.
Visualiza la distribución de la latencia de inicio de los Pods
La latencia de inicio de los Pods hace referencia a la latencia de inicio total, incluidas las extracciones de imágenes, que mide el tiempo desde el estado Created del Pod hasta el estado Ready. Puedes evaluar la latencia de inicio de los Pods con los siguientes dos gráficos:
Gráfico de Distribución de la latencia de inicio del Pod: Este gráfico muestra los percentiles de latencia de inicio de los Pods (percentil cincuenta, percentil noventa y cinco y percentil noventa y nueve) que se calculan en función de las observaciones de los eventos de inicio del Pod en intervalos fijos de 3 horas, por ejemplo, de 12:00 a.m. a 3:00 a.m. y de 3:00 a.m. a 6:00 a.m. Puedes usar este gráfico para los siguientes fines:
- Comprende la latencia de inicio de Pods de referencia.
- Identificar los cambios en la latencia de inicio de los Pods a lo largo del tiempo
- Correlaciona los cambios en la latencia de inicio de Pods con eventos recientes, como implementaciones de cargas de trabajo o eventos del escalador automático de clústeres. Puedes seleccionar los eventos en la lista Anotaciones en la parte superior del panel.
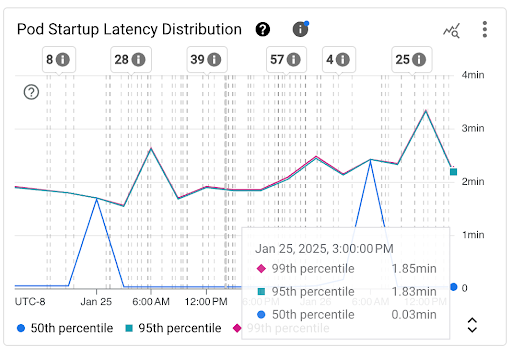
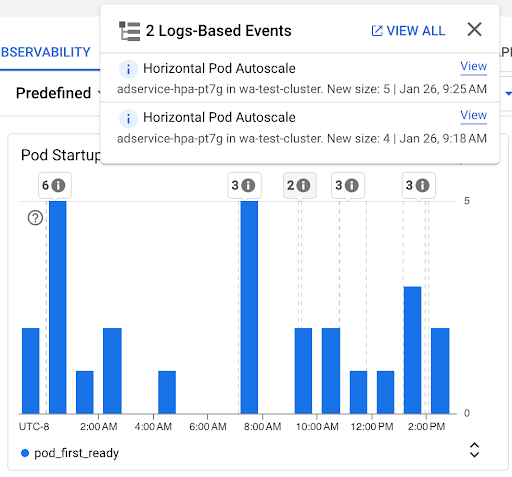
Gráfico de Recuento de inicios de Pods: En este gráfico, se muestra el recuento de Pods que se iniciaron durante los intervalos de tiempo seleccionados. Puedes usar este gráfico para los siguientes propósitos:
- Comprender los tamaños de muestra de Pods que se usan para calcular los percentiles de la distribución de latencia de inicio de Pods para un intervalo de tiempo determinado
- Comprender las causas de los inicios de Pods, como las implementaciones de cargas de trabajo o los eventos de Horizontal Pod Autoscaler Puedes seleccionar los eventos en la lista Anotaciones en la parte superior del panel.
Cómo ver la latencia de inicio de los Pods individuales
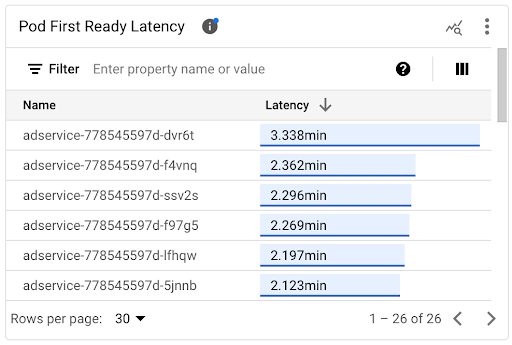
Puedes ver la latencia de inicio de los Pods individuales en el gráfico de la línea de tiempo Latencia de Pod First Ready y en la lista asociada.
- Usa el gráfico de la línea de tiempo de Latencia del primer Pod listo para correlacionar los inicios de Pod individuales con eventos recientes, como los eventos de Horizontal Pod Autoscaler o Cluster Autoscaler. Puedes seleccionar estos eventos en la lista Anotaciones en la parte superior del panel. Este gráfico te ayuda a determinar las posibles causas de cualquier cambio en la latencia de inicio en comparación con otros Pods.
- Usa la lista Pod First Ready Latency para identificar los Pods individuales que tardaron más o menos tiempo en iniciarse. Puedes ordenar la lista por la columna Latencia. Cuando identificas los Pods que tienen la latencia de inicio más alta, puedes solucionar los problemas de degradación de la latencia correlacionando los eventos de inicio de Pods con otros eventos recientes.
Para saber cuándo se creó un Pod individual, consulta el valor del campo timestamp en un evento de creación de Pod correspondiente. Para ver el campo timestamp, ejecuta la siguiente consulta en el Explorador de registros:
log_id("cloudaudit.googleapis.com/activity") AND
protoPayload.methodName="io.k8s.core.v1.pods.create" AND
resource.labels.project_id=PROJECT_ID AND
resource.labels.cluster_name=CLUSTER_NAME AND
resource.labels.location=CLUSTER_LOCATION AND
protoPayload.response.metadata.namespace=NAMESPACE AND
protoPayload.response.metadata.name=POD_NAME
Para enumerar todos los eventos de creación de Pods para tu carga de trabajo, usa el siguiente filtro en la consulta anterior:
protoPayload.response.metadata.name=~"POD_NAME_PREFIX-[a-f0-9]{7,10}-[a-z0-9]{5}"
Cuando comparas las latencias de los Pods individuales, puedes probar el impacto de varias configuraciones en la latencia de inicio del Pod y, luego, identificar una configuración óptima según tus requisitos.
Cómo determinar la latencia de programación de Pods
La latencia de programación de Pods es el tiempo transcurrido entre la creación de un Pod y su programación en un nodo. La latencia de programación de Pods contribuye al tiempo de inicio de extremo a extremo de un Pod y se calcula restando las marcas de tiempo de un evento de programación de Pod y una solicitud de creación de Pod.
Puedes encontrar la marca de tiempo de un evento de programación de Pod individual en el campo jsonPayload.eventTime de un evento de programación de Pod correspondiente. Para ver el campo jsonPayload.eventTime, ejecuta la siguiente consulta en el Explorador de registros:
log_id("events")
jsonPayload.reason="Scheduled"
resource.type="k8s_pod"
resource.labels.project_id=PROJECT_ID
resource.labels.location=CLUSTER_LOCATION
resource.labels.cluster_name=CLUSTER_NAME
resource.labels.namespace_name=NAMESPACE
resource.labels.pod_name=POD_NAME
Para enumerar todos los eventos de programación de Pods para tu carga de trabajo, usa el siguiente filtro en la consulta anterior:
resource.labels.pod_name=~"POD_NAME_PREFIX-[a-f0-9]{7,10}-[a-z0-9]{5}"
Consulta la latencia de extracción de imágenes
La latencia de extracción de imágenes de contenedor contribuye a la latencia de inicio del Pod en situaciones en las que la imagen aún no está disponible en el nodo o debe actualizarse. Cuando optimizas la latencia de extracción de imágenes, reduces la latencia de inicio de la carga de trabajo durante los eventos de expansión del clúster.
Puedes ver la tabla Kubelet Image Pull Events para saber cuándo se extrajeron las imágenes de contenedor de la carga de trabajo y cuánto duró el proceso.
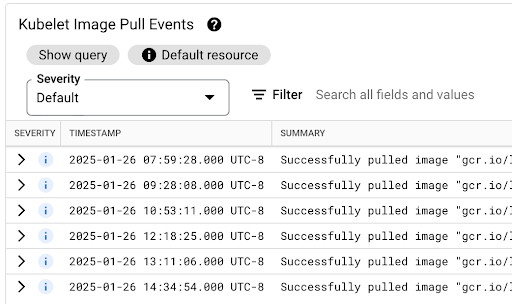
La latencia de extracción de la imagen está disponible en el campo jsonPayload.message, que contiene un mensaje como el siguiente:
"Successfully pulled image "gcr.io/example-project/image-name" in 17.093s (33.051s including waiting). Image size: 206980012 bytes."
Visualiza la distribución de la latencia de las recomendaciones de escalamiento de HPA
La latencia de las recomendaciones de ajuste de escala de Horizontal Pod Autoscaler (HPA) para el destino del HPA es el tiempo transcurrido entre la creación de las métricas y la aplicación de la recomendación de ajuste de escala correspondiente al servidor de la API. Cuando optimizas la latencia de las recomendaciones de escalamiento del HPA, reduces la latencia de inicio de la carga de trabajo durante los eventos de expansión.
El ajuste de escala del HPA se puede ver en los siguientes dos gráficos:
Gráfico Distribución de la latencia de las recomendaciones de escalamiento de HPA: Este gráfico muestra los percentiles de la latencia de las recomendaciones de escalamiento de HPA (percentil cincuenta, percentil noventa y cinco y percentil noventa y nueve) que se calculan en función de las observaciones de las recomendaciones de escalamiento de HPA en intervalos de tiempo de 3 horas. Puedes usar este gráfico para los siguientes fines:
- Comprende la latencia de referencia de las recomendaciones de escalamiento del HPA.
- Identificar cambios en la latencia de las recomendaciones de escalamiento de HPA a lo largo del tiempo
- Correlaciona los cambios en la latencia de las recomendaciones de escalamiento de HPA con eventos recientes. Puedes seleccionar los eventos en la lista Anotaciones en la parte superior del panel.
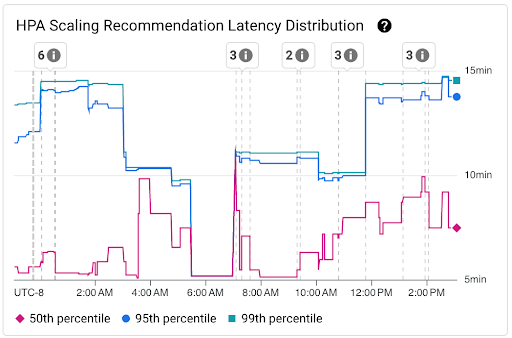
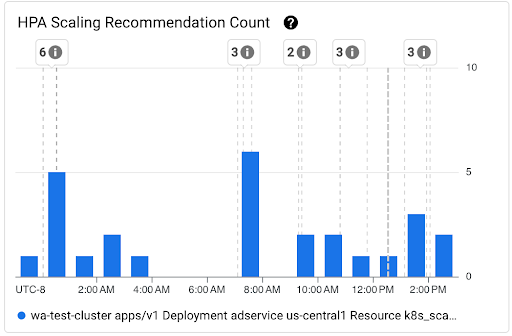
Gráfico de Recuento de recomendaciones de escalamiento de HPA: Este gráfico muestra el recuento de recomendaciones de escalamiento de HPA que se observaron durante el intervalo de tiempo seleccionado. Usa el gráfico para las siguientes tareas:
- Comprende los tamaños de muestra de las recomendaciones de escalamiento de HPA. Las muestras se usan para calcular los percentiles en la distribución de la latencia de las recomendaciones de escalamiento de HPA para un intervalo de tiempo determinado.
- Correlaciona las recomendaciones de escalamiento del HPA con los eventos de inicio de Pod nuevos y con los eventos del Horizontal Pod Autoscaler. Puedes seleccionar los eventos en la lista Anotaciones en la parte superior del panel.
Visualiza problemas de programación de Pods
Los problemas de programación de pods pueden afectar la latencia de inicio de extremo a extremo de tu carga de trabajo. Para reducir la latencia de inicio de extremo a extremo de tu carga de trabajo, soluciona los problemas y reduce la cantidad de estos.
Los siguientes son los dos gráficos disponibles para hacer un seguimiento de estos problemas:
- El gráfico Pods no programables/pendientes/con errores muestra la cantidad de Pods no programables, pendientes y con errores a lo largo del tiempo.
- El gráfico Contenedores con errores de retirada/espera/preparación muestra la cantidad de contenedores en estos estados a lo largo del tiempo.
Visualiza el panel de latencia de inicio para los nodos
Para ver las métricas de latencia de inicio de los nodos, realiza los siguientes pasos en la consola deGoogle Cloud :
Ve a la página Clústeres de Kubernetes.
Para abrir la vista Detalles del clúster, haz clic en el nombre del clúster que deseas inspeccionar.
Haz clic en la pestaña Observabilidad.
En el menú de la izquierda, selecciona Latencia de inicio.
Visualiza la distribución de la latencia de inicio de los nodos
La latencia de inicio de un nodo hace referencia a la latencia de inicio total, que mide el tiempo desde el CreationTimestamp del nodo hasta el estado Kubernetes node ready. La latencia de inicio del nodo se puede ver en los siguientes dos gráficos:
Gráfico de Distribución de la latencia de inicio de nodos: Este gráfico muestra los percentiles de la latencia de inicio de nodos (percentil cincuenta, percentil noventa y cinco y percentil noventa y nueve) que se calculan en función de las observaciones de los eventos de inicio de nodos en intervalos fijos de 3 horas, por ejemplo, de 12:00 a.m. a 3:00 a.m. y de 3:00 a.m. a 6:00 a.m. Puedes usar este gráfico para los siguientes fines:
- Comprende la latencia de inicio del nodo de referencia.
- Identificar los cambios en la latencia de inicio de los nodos a lo largo del tiempo
- Correlaciona los cambios en la latencia de inicio del nodo con eventos recientes, como actualizaciones del clúster o actualizaciones del grupo de nodos. Puedes seleccionar los eventos en la lista Anotaciones en la parte superior del panel.
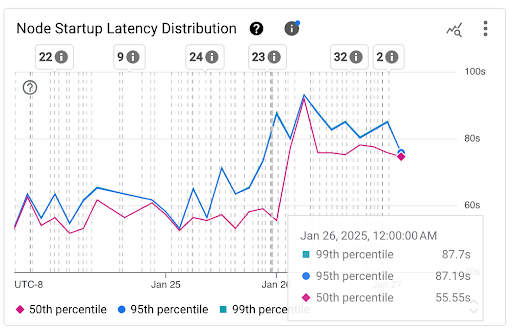
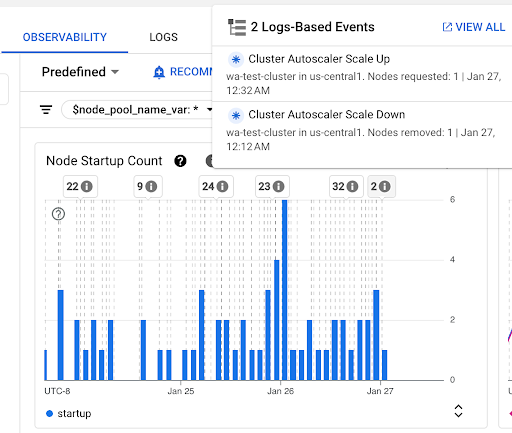
Gráfico de Recuento de inicios de nodos: Este gráfico muestra el recuento de nodos que se iniciaron durante los intervalos de tiempo seleccionados. Puedes usar el gráfico para los siguientes propósitos:
- Comprende los tamaños de muestra de los nodos que se usan para calcular los percentiles de distribución de latencia de inicio de nodos para un intervalo de tiempo determinado.
- Comprender las causas de los inicios de nodos, como las actualizaciones de grupos de nodos o los eventos del escalador automático del clúster Puedes seleccionar los eventos en la lista Anotaciones en la parte superior del panel.
Cómo ver la latencia de inicio de nodos individuales
Cuando comparas las latencias de los nodos individuales, puedes probar el impacto de varios parámetros de configuración de nodos en la latencia de inicio del nodo y, luego, identificar una configuración óptima según tus requisitos. Puedes ver la latencia de inicio de nodos individuales en el gráfico de cronograma Latencia de inicio de nodos y en la lista asociada.
Usa el gráfico de la línea de tiempo Latencia de inicio del nodo para correlacionar los inicios de nodos individuales con eventos recientes, como las actualizaciones del clúster o las actualizaciones del grupo de nodos. Puedes determinar las posibles causas de los cambios en la latencia de inicio en comparación con otros nodos. Puedes seleccionar los eventos en la lista Anotaciones en la parte superior del panel.
Usa la lista Latencia de inicio del nodo para identificar los nodos individuales que tardaron más o menos tiempo en iniciarse. Puedes ordenar la lista por la columna Latencia. Cuando identificas los nodos con la latencia de inicio más alta, puedes solucionar los problemas de degradación de la latencia correlacionando los eventos de inicio del nodo con otros eventos recientes.
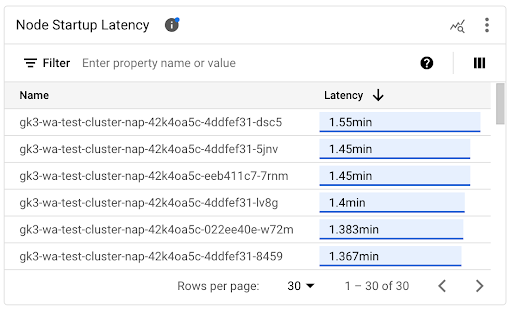
Para saber cuándo se creó un nodo individual, consulta el valor del campo protoPayload.metadata.creationTimestamp en un evento de creación de nodo correspondiente. Para ver el campo protoPayload.metadata.creationTimestamp, ejecuta la siguiente consulta en el Explorador de registros:
log_id("cloudaudit.googleapis.com/activity") AND
protoPayload.methodName="io.k8s.core.v1.nodes.create" AND
resource.labels.project_id=PROJECT_ID AND
resource.labels.cluster_name=CLUSTER_NAME AND
resource.labels.location=CLUSTER_LOCATION AND
protoPayload.response.metadata.name=NODE_NAME
Visualiza la latencia de inicio en un grupo de nodos
Si tus grupos de nodos tienen diferentes configuraciones, por ejemplo, para ejecutar diferentes cargas de trabajo, es posible que debas supervisar la latencia de inicio de los nodos por separado según los grupos de nodos. Cuando comparas las latencias de inicio de los nodos en tus grupos de nodos, puedes obtener estadísticas sobre cómo la configuración de los nodos afecta la latencia de inicio y, en consecuencia, optimizar la latencia.
De forma predeterminada, en el panel Latencia de inicio del nodo, se muestran la distribución agregada de la latencia de inicio y las latencias de inicio de nodos individuales en todos los grupos de nodos de un clúster. Para ver la latencia de inicio de los nodos de un grupo de nodos específico, selecciona el nombre del grupo de nodos con el filtro $node_pool_name_var ubicado en la parte superior del panel.
¿Qué sigue?
- Obtén información para optimizar el ajuste de escala automático de Pods en función de las métricas.
- Obtén más información sobre las formas de reducir la latencia de inicio en frío en GKE.
- Obtén más información para reducir la latencia de extracción de imágenes con la transmisión de imágenes.
- Obtén información sobre la sorprendente economía del ajuste del ajuste de escala automático horizontal de Pods.
- Supervisa tus cargas de trabajo con la supervisión automática de aplicaciones.