Nesta página, descrevemos como o Cloud TPU funciona com o Google Kubernetes Engine (GKE), incluindo terminologia, os benefícios das Unidades de Processamento de Tensor (TPUs) e considerações sobre programação de carga de trabalho. As TPUs são circuitos integrados de aplicação específica (ASICs, na sigla em inglês) desenvolvidos especialmente pelo Google para acelerar cargas de trabalho de ML que usam frameworks como TensorFlow, PyTorch e JAX.
Esta página é destinada a administradores e operadores de plataforma e especialistas em dados e IA que executam modelos de machine learning (ML) com características como grande escala, longa duração ou dominados por cálculos de matriz. Para saber mais sobre papéis comuns e tarefas de exemplo referenciados no conteúdo do Google Cloud, consulte Tarefas e papéis de usuário comuns do GKE.
Antes de ler esta página, confira se você sabe como os aceleradores de ML funcionam. Para mais detalhes, consulte Introdução ao Cloud TPU.
Benefícios do uso de TPUs no GKE
O GKE oferece suporte completo para o gerenciamento do ciclo de vida de nós da TPU e do pool de nós, incluindo criação, configuração e exclusão de VMs de TPU. O GKE também oferece suporte a VMs do Spot e usa a Cloud TPU reservada. Para mais informações, consulte Opções de consumo do Cloud TPU.
Os benefícios do uso de TPUs no GKE incluem:
- Ambiente operacional consistente:é possível usar uma única plataforma para todo o machine learning e outras cargas de trabalho.
- Upgrades automáticos:o GKE automatiza as atualizações de versão, o que reduz a sobrecarga operacional.
- Balanceamento de carga:o GKE distribui a carga, reduzindo a latência e melhorando a confiabilidade.
- Escalonamento responsivo:o GKE escalona automaticamente os recursos da TPU para atender às necessidades das cargas de trabalho.
- Gerenciamento de recursos:com o Kueue, um sistema de enfileiramento de jobs nativo do Kubernetes, é possível gerenciar recursos em vários locatários na sua organização usando enfileiramento, preempção, priorização e compartilhamento justo.
- Opções de isolamento em sandbox:o GKE Sandbox ajuda a proteger suas cargas de trabalho com o gVisor. Para mais informações, consulte GKE Sandbox.
Benefícios de usar a TPU Trillium
O Trillium é a TPU de sexta geração do Google. O Trillium tem os seguintes benefícios:
- O Trillium aumenta a performance de computação por chip em comparação com a TPU v5e.
- O Trillium aumenta a capacidade e a largura de banda da memória de alta largura de banda (HBM), além da largura de banda da interconexão entre chips (ICI) em relação à TPU v5e.
- O Trillium está equipado com o SparseCore de terceira geração, um acelerador especializado para processar incorporações ultragrandes comuns em cargas de trabalho avançadas de classificação e recomendação.
- O Trillium é mais de 67% mais eficiente em termos de energia do que a TPU v5e.
- O Trillium pode escalonar até 256 TPUs em uma única fração de TPU de alta largura de banda e baixa latência.
- O Trillium é compatível com o agendamento de coleta. Com o agendamento de coleta, é possível declarar um grupo de TPUs (pools de nós de fração de TPU de host único e de vários hosts) para garantir alta disponibilidade para as demandas das cargas de trabalho de inferência.
Em todas as plataformas técnicas, como APIs e registros, e em partes específicas da
documentação do GKE, usamos v6e ou TPU Trillium (v6e) para nos referirmos
às TPUs Trillium. Para saber mais sobre os benefícios do Trillium, leia a
postagem do blog sobre o anúncio do Trillium. Para
começar a configuração da TPU, consulte Planejar TPUs no GKE.
Terminologia relacionada a TPUs no GKE
Nesta página, usamos a seguinte terminologia relacionada às TPUs:
- Tipo de TPU:o tipo de Cloud TPU, como v5e.
- Nó de fração da TPU:um nó do Kubernetes representado por uma única VM que tem um ou mais chips da TPU interconectados.
- Pool de nós de fração de TPU: um grupo de nós do Kubernetes em um cluster que todos têm a mesma configuração de TPU.
- Topologia de TPU:o número e a disposição física dos chips de TPU em uma fração de TPU.
- Atômico:o GKE trata todos os nós interconectados como uma única unidade. Durante as operações de escalonamento, o GKE escalona todo o conjunto de nós para 0 e cria novos nós. Se uma máquina no grupo falhar ou for encerrada, o GKE recria todo o conjunto de nós como uma nova unidade.
- Imutável:não é possível adicionar manualmente novos nós ao conjunto de nós interconectados. No entanto, é possível criar um novo pool de nós com a topologia de TPU desejada e programar cargas de trabalho nele.
Tipos de pools de nós de fração de TPU
O GKE é compatível com dois tipos de pools de nós da TPU:
O tipo e a topologia da TPU determinam se o nó de fração de TPU pode ser de vários ou de um único host. Recomendamos o seguinte:
- Para modelos em grande escala, use nós de fração de TPU de vários hosts.
- Para modelos de pequena escala, use nós de fração de TPU de host único.
- Para treinamento ou inferência em grande escala, use os Pathways. O Pathways simplifica computações de machine learning em grande escala ao permitir que um único cliente JAX orquestre cargas de trabalho em várias frações grandes de TPU. Para mais informações, consulte Pathways.
Pools de nós de fração de TPU de vários hosts
Um pool de nós de fração de TPU de vários hosts é um pool de nós que contém duas ou mais VMs de TPU interconectadas. Cada VM tem um dispositivo de TPU conectado a ela. As TPUs em
uma fração de TPU de vários hosts são conectadas por uma interconexão de alta velocidade (ICI). Depois que um pool de nós de fração de TPU de vários hosts é criado, não é possível adicionar nós a ele. Por
exemplo, não é possível criar um pool de nós v4-32
e depois adicionar um nó do Kubernetes (VM de TPU) a ele. Para adicionar
uma fração de TPU a um cluster do GKE, crie um pool de nós.
As VMs em um pool de nós de fração de TPU de vários hosts são tratadas como uma única unidade atômica. Se o GKE não conseguir implantar um nó na fração, nenhum nó no nó da fração de TPU será implantado.
Se um nó em uma fração de TPU de vários hosts precisar de reparo, o GKE desligará todas as VMs na fração de TPU, forçando a remoção de todos os pods do Kubernetes na carga de trabalho. Depois que todas as VMs na fração de TPU estiverem funcionando, os pods do Kubernetes poderão ser programados nas VMs na nova fração de TPU.
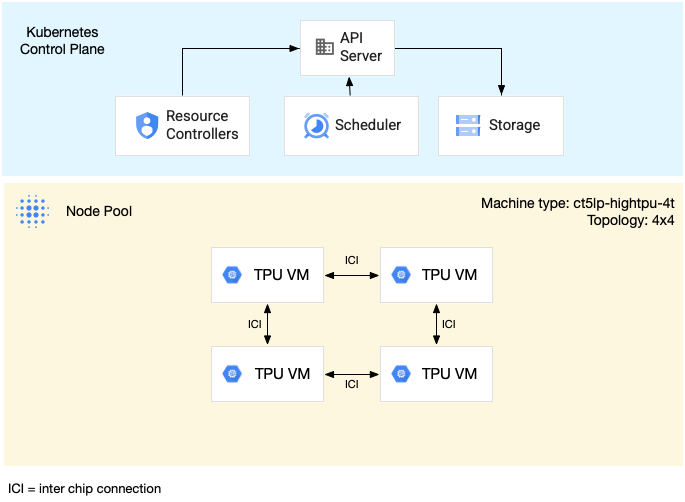
O diagrama a seguir mostra uma fração de TPU v5litepod-16 (v5e) de vários hosts. Essa
fatia da TPU tem quatro VMs. Cada VM na fração de TPU tem quatro chips TPU v5e conectados com interconexões de alta velocidade (ICI), e cada chip TPU v5e tem um TensorCore:
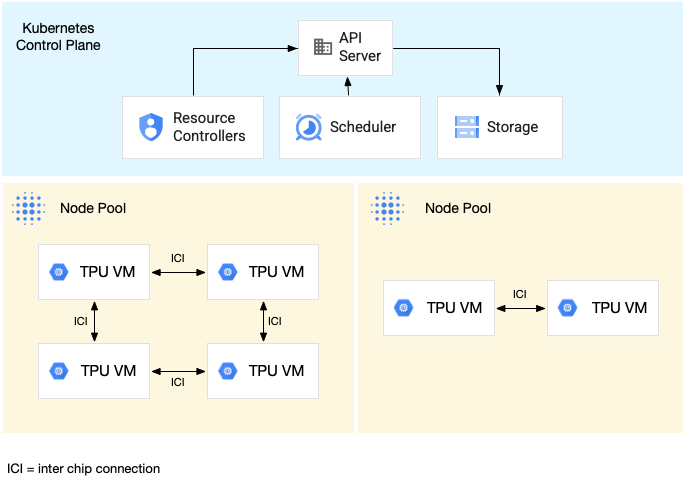
O diagrama a seguir mostra um cluster do GKE que contém uma fração de TPU v5litepod-16 (v5e) (topologia: 4x4) e uma fração de TPU v5litepod-8 (v5e) (topologia: 2x4):
Pools de nós de fração de TPU de host único
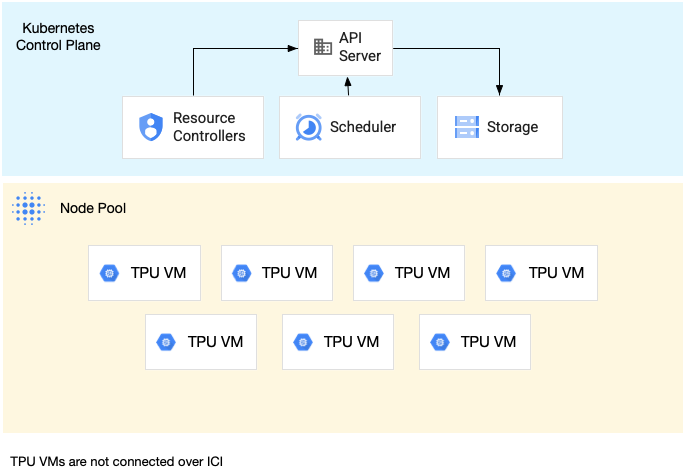
Um pool de nós de fração de host único é um pool de nós que contém uma ou mais VMs de TPU independentes. Cada VM tem um dispositivo de TPU conectado a ela. Embora as VMs em um pool de nós de fração de host único possam se comunicar pela rede de data center (DCN), as TPUs anexadas às VMs não são interconectadas.
O diagrama a seguir mostra um exemplo de fração de TPU de host único que contém
sete máquinas v4-8:
Características das TPUs no GKE
As TPUs têm características únicas que exigem planejamento e configuração especiais.
Consumo de TPU
Para otimizar a utilização de recursos e o custo, mantendo o equilíbrio do desempenho da carga de trabalho, o GKE oferece suporte às seguintes opções de consumo de TPU:
- Início flexível:para provisionar VMs de início flexível por até sete dias, com o GKE alocando automaticamente o hardware da melhor maneira possível com base na disponibilidade. Para mais informações, consulte Sobre o provisionamento de GPU e TPU com o modo de provisionamento de início flexível.
- VMs spot:para provisionar VMs spot, você pode receber descontos significativos, mas elas podem ser interrompidas a qualquer momento, com um aviso de 30 segundos. Para mais informações, consulte VMs spot.
- Reserva adiantada por até 90 dias (no modo de calendário): para provisionar recursos de TPU por até 90 dias, durante um período especificado. Para mais informações, consulte Solicitar TPUs com reserva adiantada no modo de calendário.
- Reservas de TPU:para solicitar uma reserva adiantada por um ano ou mais.
Para escolher a opção de consumo que atende aos requisitos da sua carga de trabalho, consulte Sobre as opções de consumo de aceleradores para cargas de trabalho de IA/ML no GKE.
Antes de usar TPUs no GKE, escolha a opção de consumo que melhor se adapta aos requisitos da sua carga de trabalho.
Topologia
A topologia define a disposição física das TPUs dentro de uma fração da TPU. O GKE provisiona uma fração da TPU em topologias bidimensionais ou tridimensionais, dependendo da versão da TPU. Especifique uma topologia como o número de chips de TPU em cada dimensão da seguinte maneira:
Para a TPU v4 e v5p programada em pools de nós de fração da TPU de vários hosts, defina a topologia em três tuplas ({A}x{B}x{C}), por exemplo, 4x4x4. O produto de {A}x{B}x{C} define o número de chips de TPU no pool de nós. Por exemplo, é possível
definir topologias pequenas com menos de 64 chips de TPU com formulários de topologia
como 2x2x2, 2x2x4 ou 2x4x4. Se você usar topologias maiores que
64 chips de TPU, os valores atribuídos a {A}, {B} e {C} precisarão
atender às seguintes condições:
- {A}, {B} e {C} precisam ser múltiplos de quatro.
- A maior topologia compatível com v4 é
12x16x16e v5p é16x16x24. - Os valores atribuídos precisam manter o padrão A ≤ B ≤ C. Por exemplo,
4x4x8ou8x8x8.
Tipo de máquina
Os tipos de máquinas que oferecem suporte aos recursos de TPU seguem uma convenção de nomenclatura que inclui a versão da TPU e o número de chips de TPU por fração de nó, como ct<version>-hightpu-<node-chip-count>t. Por exemplo, o tipo de máquina
ct5lp-hightpu-1t é compatível com TPU v5e e contém apenas um chip de TPU.
Modo privilegiado
Se você usar versões do GKE anteriores à 1.28, configure
seus contêineres com recursos especiais para acessar TPUs. Em clusters no modo
padrão, é possível usar o modo privilegiado para conceder esse acesso. O modo privilegiado
substitui muitas das outras configurações de segurança no securityContext. Para mais detalhes, consulte Executar contêineres sem modo privilegiado.
As versões 1.28 e mais recentes não exigem modo privilegiado nem recursos especiais.
Como funcionam as TPUs no GKE
O gerenciamento de recursos e a priorização do Kubernetes tratam as VMs nas TPUs da mesma forma que outros tipos de VM. Para solicitar chips de TPU, use o nome do recurso google.com/tpu:
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
Ao usar TPUs no GKE, considere as seguintes características:
- Uma VM pode acessar até oito chips de TPU.
- Uma fração de TPU contém um número fixo de chips de TPU, que depende do tipo de máquina de TPU escolhido.
- O número solicitado de
google.com/tpuprecisa ser igual ao número total de chips TPU disponíveis no nó de fração da TPU. Qualquer contêiner em um pod do GKE que solicite TPUs precisa consumir todos os chips TPU no nó. Caso contrário, a implantação vai falhar porque o GKE não pode consumir parcialmente os recursos de TPU. Considere os seguintes cenários:- O tipo de máquina
ct5lp-hightpu-4tcom uma topologia2x4contém dois nós de fração de TPU com quatro chips de TPU cada, um total de oito chips de TPU. Com esse tipo de máquina, você pode: - Não é possível implantar um pod do GKE que requer oito chips de TPU nos nós deste pool.
- Você pode implantar dois pods que exigem quatro chips de TPU cada, cada pod em um dos dois nós neste pool de nós.
- A TPU v5e com topologia 4x4 tem 16 chips de TPU em quatro nós. A carga de trabalho do GKE Autopilot que seleciona essa configuração precisa solicitar quatro chips de TPU em cada réplica, para de uma a quatro réplicas.
- O tipo de máquina
- Em clusters padrão, vários pods do Kubernetes podem ser programados em uma VM, mas apenas um contêiner em cada pod pode acessar os chips de TPU.
- Para criar pods do kube-system, como o kube-dns, cada cluster padrão precisa ter pelo menos um pool de nós de fração não TPU.
- Por padrão, os nós de fração de TPU têm o
google.com/tputaint que impede que cargas de trabalho não TPU sejam programadas nos nós de fração de TPU. Cargas de trabalho que não usam TPUs são executadas em nós não TPU, liberando computação em nós de fatias TPU para código que usa TPUs. O taint não garante que os recursos da TPU sejam totalmente utilizados. - O GKE coleta os registros emitidos por contêineres em execução em nós de fração da TPU. Para saber mais, consulte Logging.
- As métricas de inicialização da TPU, como o desempenho do ambiente de execução, estão disponíveis no Cloud Monitoring. Para saber mais, consulte Observabilidade e métricas.
- É possível colocar as cargas de trabalho de TPU em sandbox com o GKE Sandbox. O GKE Sandbox funciona com modelos de TPU v4 e mais recentes. Para saber mais, consulte GKE Sandbox.
Como funciona o agendamento de coleta
No TPU Trillium, é possível usar o agendamento de coleta para agrupar nós de fração de TPU. Agrupar esses nós de fração de TPU facilita o ajuste do número de réplicas para atender à demanda da carga de trabalho.O Google Cloud controla as atualizações de software para garantir que sempre haja frações suficientes disponíveis na coleção para atender ao tráfego.
A TPU Trillium oferece suporte ao agendamento de coleta para pools de nós de host único e vários hosts que executam cargas de trabalho de inferência. A seguir, descrevemos como o comportamento do agendamento de coleta depende do tipo de fração de TPU usada:
- Fração de TPU de vários hosts:o GKE agrupa frações de TPU de vários hosts para formar uma coleção. Cada pool de nós do GKE é uma réplica nessa coleção. Para definir uma coleção, crie uma fração de TPU de vários hosts e atribua um nome exclusivo a ela. Para adicionar mais frações de TPU à coleção, crie outro pool de nós de fração de TPU de vários hosts com o mesmo nome de coleção e tipo de carga de trabalho.
- Fração de TPU de host único:o GKE considera todo o pool de nós de fração de TPU de host único como uma coleção. Para adicionar mais frações de TPU à coleção, redimensione o pool de nós de fração de TPU de host único.
O agendamento de coleta tem as seguintes limitações:
- Só é possível programar coletas para o TPU Trillium.
- É possível definir coleções apenas durante a criação do pool de nós.
- As VMs spot não são compatíveis.
- As coleções que contêm pools de nós de fração de TPU de vários hosts precisam usar o mesmo tipo de máquina, topologia e versão para todos os pools de nós na coleção.
É possível configurar o agendamento da coleta nos seguintes cenários:
- Ao criar um pool de nós de fração de TPU no GKE Standard
- Ao implantar cargas de trabalho no Autopilot do GKE
- Ao criar um cluster que ativa o provisionamento automático de nós
A seguir
Para saber como configurar a Cloud TPU no GKE, consulte as páginas a seguir:
- Planejar TPUs no GKE para iniciar a configuração da TPU
- Implante cargas de trabalho de TPU no Autopilot do GKE
- Implantar cargas de trabalho de TPU no GKE Standard
- Conheça as práticas recomendadas para usar o Cloud TPU em tarefas de ML.
- Vídeo: criar machine learning em larga escala em Cloud TPU com o GKE
- Exibir modelos de linguagem grandes com o KubeRay em TPUs
- Saiba mais sobre o sandbox de cargas de trabalho de GPU com o GKE Sandbox