Ingress de varios clústeres es un controlador alojado en la nube para clústeres de Google Kubernetes Engine (GKE). Es un servicio alojado por Google que admite la implementación de recursos de balanceo de cargas compartidos en clústeres y regiones. Para implementar Ingress de varios clústeres en varios clústeres, completa la configuración de Ingress para varios clústeres y, luego, consulta Cómo implementar Ingress en varios clústeres.
Para obtener una comparación detallada entre Ingress de varios clústeres (MCI), la puerta de enlace de varios clústeres (MCG) y el balanceador de cargas con grupos de extremos de red independientes (LB y NEG independientes), consulta Elige tu clúster múltiple API de balanceo de cargas para GKE.
Herramientas de redes de varios clústeres
Existen muchos factores que impulsan las topologías de varios clústeres, incluida la proximidad del usuario a las apps, la alta disponibilidad regional y de clúster, la separación de organización y seguridad, y la localidad de datos. Estos casos prácticos rara vez son aislados. A medida que aumentan los motivos de tener varios clústeres, se vuelve más urgente la necesidad de una plataforma de varios clústeres formal y desarrollada.
Ingress de varios clústeres está diseñado para satisfacer las necesidades de balanceo de cargas de entornos de varios clústeres y regiones. Es un controlador para el balanceador de cargas de HTTP(S) externo que proporciona entrada de tráfico que proviene de Internet en uno o más clústeres.
La compatibilidad de Ingress de varios clústeres satisface muchos casos de uso, incluidos los siguientes:
- Una sola IP virtual (VIP) coherente de una app, sin importar dónde se implemente de manera global
- La disponibilidad de varios clústeres y regiones a través de la conmutación por error del tráfico y la verificación de estado
- Enrutamiento basado en la proximidad mediante VIP Anycast públicas para una latencia del cliente baja
- Migración transparente de clústeres para actualizaciones o para volver a compilar clústeres
Cuotas predeterminadas
Ingress de clústeres múltiples tiene las siguientes cuotas predeterminadas:
- Para obtener detalles sobre los límites de miembros de las flotas, consulta las cuotas de administración de flotas para saber cuántos miembros se admiten en una flota.
- 100 recursos
MultiClusterIngressy 100 recursosMultiClusterServicepor proyecto. Puedes crear hasta 100 recursosMultiClusterIngressy 100 recursosMultiClusterServiceen un clúster de configuración para cualquier cantidad de clústeres de backend hasta el máximo de clústeres por proyecto.
Precios y pruebas
Para obtener información sobre los precios de Ingress de varios clústeres, consulta Precios de Ingress de varios clústeres.
Cómo funciona Ingress de varios clústeres
Ingress de varios clústeres se basa en la arquitectura del balanceador de cargas de aplicaciones externo global. El balanceador de cargas de aplicaciones externo global es un balanceador de cargas distribuido de forma global con proxies implementados en más de 100 puntos de presencia (PoP) de Google en todo el mundo. Estos proxies, llamados Google Front End (GFE), se encuentran en el perímetro de la red de Google, cerca de los clientes. Ingress de varios clústeres crea balanceadores de cargas de aplicaciones externos en el nivel Premium. Estos balanceadores de cargas usan direcciones IP externas globales que se anuncian mediante anycast. Los GFE entregan y el clúster más cercano al cliente entregan las solicitudes. El tráfico de Internet se dirige al PoP de Google más cercano y usa la red troncal de Google para llegar a un clúster de GKE. Esta configuración de balanceo de cargas da como resultado una latencia más baja desde el cliente hasta el GFE. También puedes reducir la latencia entre la entrega de clústeres de GKE y los GFE; para ello, ejecuta los clústeres de GKE en las regiones más cercanas a los clientes.
Finalizar las conexiones HTTP y HTTPS en el extremo permite que el balanceador de cargas de Google decida dónde enrutar el tráfico mediante la determinación de la disponibilidad del backend antes de que el tráfico entre en un centro de datos o una región. Esto le da al tráfico la ruta más eficiente desde el cliente hasta el backend mientras considera el estado y la capacidad de los backends.
Ingress de varios clústeres es un controlador de Ingress que programa el balanceador de cargas HTTP(S) externo mediante grupos de extremo de red (NEG).
Cuando creas un recurso MultiClusterIngress, GKE implementa los recursos del balanceador de cargas de Compute Engine y configura los Pods adecuados en los clústeres como backends. Los NEG se usan para hacer un seguimiento dinámico de los extremos del pod, de modo que el balanceador de cargas de Google tenga el conjunto correcto de backends en buen estado.

A medida que implementas aplicaciones en los clústeres en GKE, Ingress de varios clústeres garantiza que el balanceador de cargas esté sincronizado con los eventos que ocurren en el clúster:
- Se crea un Deployment con las etiquetas coincidentes adecuadas.
- El proceso de un Pod se detiene y falla su verificación de estado.
- Se quita un clúster del grupo de backends.
Ingress de varios clústeres actualiza el balanceador de cargas para que sea coherente con el entorno y el estado deseado de los recursos de Kubernetes.
Arquitectura de Ingress de varios clústeres
Ingress de varios clústeres usa un servidor de API centralizado de Kubernetes para implementar Ingress en varios clústeres. Este servidor de la API centralizado se denomina clúster de configuración. Cualquier clúster de GKE puede actuar como clúster de configuración. El clúster de configuración usa dos tipos de recursos personalizados: MultiClusterIngress y MultiClusterService.
Mediante la implementación de estos recursos en el clúster de configuración, el controlador de Ingress de varios clústeres implementa balanceadores de cargas en varios clústeres.
Los siguientes conceptos y componentes conforman Ingress de varios clústeres:
Controlador de Ingress de varios clústeres: Es un plano de control distribuido de forma global que se ejecuta como un servicio fuera de los clústeres. Esto permite que el ciclo de vida y las operaciones del controlador sean independientes de los clústeres de GKE.
Clúster de configuración: Es un clúster de GKE elegido que se ejecuta en Google Cloud en el que se implementan los recursos
MultiClusterIngressyMultiClusterService. Este es un punto de control centralizado para estos recursos de varios clústeres. Estos recursos de varios clústeres existen en una sola API lógica y se pueden acceder desde ella a fin de mantener la coherencia en todos los clústeres. El controlador de Ingress detecta el clúster del archivo de configuración y concilia la infraestructura del balanceo de cargas.Una flota te permite agrupar y normalizar de forma lógica los clústeres de GKE, lo que facilita la administración de la infraestructura y habilita el uso de funciones de varios clústeres, como Ingress de varios clústeres. Puedes obtener más información sobre los beneficios de las flotas y cómo crearlas en la documentación de administración de flotas. Un clúster solo puede ser miembro de una única flota.
Clústeres miembros: Clústeres registrados en una flota se denominan clústeres miembros. Los clústeres miembros en la flota conforman el alcance completo de los backends que Ingress de varios clústeres conoce. La vista de administración de clústeres de Google Kubernetes Engine proporciona una consola segura para ver el estado de todos tus clústeres registrados.

Flujo de trabajo de Deployment
En los siguientes pasos, se ilustra un flujo de trabajo de alto nivel para usar Ingress de varios clústeres en varios clústeres.
Registra los clústeres de GKE en una flota en el proyecto que elegiste.
Configura un clúster de GKE como el clúster de configuración central. Este clúster puede ser un plano de control dedicado o puede ejecutar otras cargas de trabajo.
Implementa aplicaciones en los clústeres de GKE en los que deben ejecutarse.
Implementa uno o más recursos
MultiClusterServiceen el clúster de configuración con coincidencias de clústeres y etiquetas a fin de seleccionar clústeres, espacios de nombres y Pods que se consideren backends para un Service determinado. Esto crea NEG en Compute Engine, que comienza a registrar y administrar extremos de servicio.Implementa un recurso
MultiClusterIngressen el clúster de configuración que haga referencia a uno o más recursosMultiClusterServicecomo backends del balanceador de cargas. Esto implementa los recursos del balanceador de cargas externo de Compute Engine y expone los extremos en los clústeres a través de una sola VIP de balanceador de cargas.
Conceptos de Ingress
Ingress de varios clústeres usa un servidor de API centralizado de Kubernetes para implementar Ingress en varios clústeres. En las siguientes secciones, se describe el modelo de recursos de Ingress de varios clústeres, cómo implementar Ingress y los conceptos importantes para administrar este plano de control de red con alta disponibilidad.
Recursos MultiClusterService
Un MultiClusterService es un recurso personalizado que Ingress de varios clústeres usa para representar servicios de uso compartido entre clústeres. Un recurso MultiClusterService selecciona Pods, similar al recurso Service, pero un MultiClusterService también puede seleccionar etiquetas y clústeres. El grupo de clústeres entre los que un MultiClusterService selecciona se denominan clústeres miembros. Todos los clústeres registrados en la flota son clústeres miembros.
Un MultiClusterService solo existe en el clúster de configuración y no enruta nada similar a lo que un Service NodePort, ClusterIP o LoadBalancer enruta. En su lugar, permite que el controlador de Ingress de clústeres múltiples haga referencia a un recurso distribuido único.
En el siguiente manifiesto de muestra, se describe un MultiClusterService para una aplicación llamada foo:
apiVersion: networking.gke.io/v1
kind: MultiClusterService
metadata:
name: foo
namespace: blue
spec:
template:
spec:
selector:
app: foo
ports:
- name: web
protocol: TCP
port: 80
targetPort: 80
En este manifiesto, se implementa un servicio en todos los clústeres miembros con el selector app:
foo. Si existen Pods app: foo en ese clúster, esas direcciones IP del Pod se agregan como backends para MultiClusterIngress.
El siguiente mci-zone1-svc-j726y6p1lilewtu7 es un Service derivado generado en uno de los clústeres de destino. Este Service crea un NEG que realiza un seguimiento de los extremos del Pod para todos los pods que coinciden con el selector de etiquetas especificado en este clúster. Un Service derivado y un NEG existirán en cada clúster de destino para cada MultiClusterService (a menos que se usen selectores de clústeres). Si no hay Pods coincidentes en un clúster de destino, el Service y el NEG estarán vacíos. Los Services derivados son administrados en su totalidad por MultiClusterService, y los usuarios no los administran directamente.
apiVersion: v1
kind: Service
metadata:
annotations:
cloud.google.com/neg: '{"exposed_ports":{"8080":{}}}'
cloud.google.com/neg-status: '{"network_endpoint_groups":{"8080":"k8s1-a6b112b6-default-mci-zone1-svc-j726y6p1lilewt-808-e86163b5"},"zones":["us-central1-a"]}'
networking.gke.io/multiclusterservice-parent: '{"Namespace":"default","Name":"zone1"}'
name: mci-zone1-svc-j726y6p1lilewtu7
namespace: blue
spec:
selector:
app: foo
ports:
- name: web
protocol: TCP
port: 80
targetPort: 80
Notas el Service derivado:
- Su función es una agrupación lógica de extremos como backends de Ingress de varios clústeres.
- Administra el ciclo de vida del NEG para un clúster y una aplicación determinados.
- También se crea como un Service sin interfaz gráfica. Ten en cuenta que solo los campos
SelectoryPortsse transfieren deMultiClusterServiceal servicio derivado. - El controlador de Ingress administra su ciclo de vida.
Recurso MultiClusterIngress
Un recurso MultiClusterIngress se comporta de manera idéntica al recurso Ingress principal en varios aspectos. Ambos tienen la misma especificación para definir los hosts, las rutas, las finalizaciones de protocolos y los backends.
En el siguiente manifiesto, se describe un MultiClusterIngress que enruta el tráfico a los backends foo y bar según los encabezados del host HTTP:
apiVersion: networking.gke.io/v1
kind: MultiClusterIngress
metadata:
name: foobar-ingress
namespace: blue
spec:
template:
spec:
backend:
serviceName: default-backend
servicePort: 80
rules:
- host: foo.example.com
backend:
serviceName: foo
servicePort: 80
- host: bar.example.com
backend:
serviceName: bar
servicePort: 80
Este recurso MultiClusterIngress hace coincidir el tráfico con la dirección IP virtual en foo.example.com y bar.example.com mediante el envío de este tráfico a los recursos MultiClusterService llamados foo y bar. Este MultiClusterIngress tiene un backend predeterminado que coincide con el resto del tráfico y lo envía al MultiClusterService del backend predeterminado.
En el siguiente diagrama, se muestra cómo fluye el tráfico desde un Ingress hasta un clúster:

En el diagrama, hay dos clústeres, gke-us y gke-eu. El tráfico fluye desde foo.example.com hacia los Pods que tienen la etiqueta app:foo en ambos clústeres. Desde bar.example.com, el tráfico fluye a los Pods que tienen la etiqueta app:bar en ambos clústeres.
Recursos de Ingress en los clústeres
El clúster de configuración es el único que puede tener recursos MultiClusterIngress y MultiClusterService. Cada clúster de destino que tenga Pods que coincidan con los selectores de etiquetas MultiClusterService también tendrá un Service derivado correspondiente programado en ellos. Si un MultiClusterService no selecciona de manera explícita un clúster, no se crea un Service derivado correspondiente en ese clúster.

Similitud de espacio de nombres
La similitud de espacios de nombres es una propiedad de los clústeres de Kubernetes en la que un espacio de nombres se extiende entre los clústeres y se considera el mismo espacio de nombres.
En el siguiente diagrama, el espacio de nombres blue existe en los clústeres de GKE gke-cfg, gke-eu y gke-us. La similitud de espacio de nombres considera que el espacio de nombres blue es el mismo en todos los clústeres. Esto significa que un usuario tiene los mismos privilegios para los recursos en el espacio de nombres blue en cada clúster.
La similitud de espacio de nombres también significa que los recursos Service con el mismo nombre en varios clústeres del espacio de nombres blue se consideran el mismo Service.
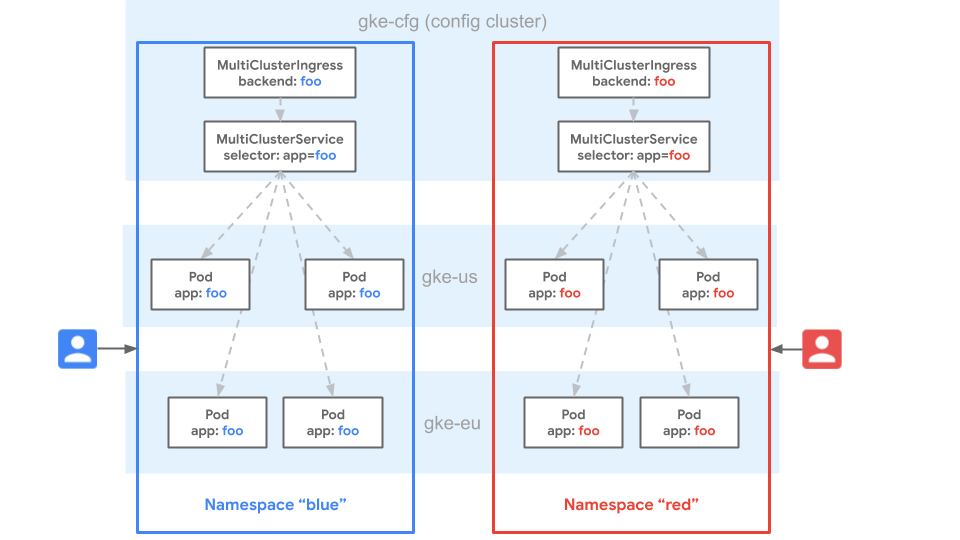
Gateway trata el Service como un solo grupo de extremos en los tres clústeres. Debido a que las rutas y los recursos MultiClusterIngress solo pueden enrutarse a Services dentro del mismo espacio de nombres, esto proporciona coherencia con múltiples usuarios para la configuración en todos los clústeres de la flota. Las flotas proporcionan un alto grado de portabilidad, ya que los recursos se pueden implementar o mover entre clústeres sin ningún cambio en su configuración. La implementación en el mismo espacio de nombres de flota proporciona coherencia entre clústeres.
Considera los siguientes principios de diseño para la similitud de espacios de nombres:
- Los espacios de nombres para diferentes propósitos no deben tener el mismo nombre en varios clústeres.
- Los espacios de nombres deben reservarse de forma explícita, mediante la asignación de un espacio de nombres, o de manera implícita, mediante políticas fuera de banda, para equipos y clústeres dentro de una flota.
- Los espacios de nombres para el mismo propósito en todos los clústeres deben compartir el mismo nombre.
- El permiso del usuario para los espacios de nombres en varios clústeres debe controlarse de forma estricta a fin de evitar el acceso no autorizado.
- No debes usar el espacio de nombres predeterminado ni los espacios de nombres genéricos, como “prod” o “dev”, para la implementación normal de la aplicación. Es frecuente que los usuarios implementen recursos en el espacio de nombres predeterminado de forma accidental y violen los principios de segmentación de los espacios de nombres.
- Se debe crear el mismo espacio de nombres en los clústeres cada vez que un equipo o grupo de usuarios determinado tenga que implementar recursos.
Diseño del clúster de configuración
El clúster de configuración de Ingress for Anthos es un clúster de GKE único que aloja los recursos MultiClusterIngress y MultiClusterService, y actúa como el único punto de control para Ingress en la flota de clústeres de GKE de destino. Elige el clúster de configuración cuando habilites Ingress de varios clústeres. Puedes elegir cualquier clúster de GKE como el clúster de configuración y cambiarlo en cualquier momento.
Disponibilidad del clúster de configuración
Debido a que el clúster de configuración es un único punto de control, los recursos de Ingress de varios clústeres no se pueden crear ni actualizar si la API del clúster de configuración no está disponible. Una interrupción del clúster de configuración no afectará a los balanceadores de cargas ni al tráfico que entregan, pero el controlador no conciliará los cambios en los recursos MultiClusterIngress y MultiClusterService hasta que estén disponibles nuevamente.
Considera los siguientes principios de diseño para los clústeres de configuración:
- El clúster de configuración debe elegirse de modo que tenga alta disponibilidad. Se prefieren los clústeres regionales en lugar de los clústeres zonales.
- Para habilitar Ingress de varios clústeres, no es necesario que el clúster de configuración sea un clúster dedicado. El clúster de configuración puede alojar cargas de trabajo administrativas o incluso de aplicaciones, aunque debes asegurarte de que las aplicaciones alojadas no afecten la disponibilidad del servidor de la API del clúster de configuración. El clúster de configuración puede ser un clúster de destino que aloja backends para recursos
MultiClusterService, pero si se necesitan precauciones adicionales, el clúster de configuración también se puede excluir como un backend a través de la selección de clústeres. - Los clústeres de configuración deben tener todos los espacios de nombres que usan los backends del clúster de destino. Un
MultiClusterServicesolo puede hacer referencia a Pods en el mismo espacio de nombres en los clústeres, por lo que el espacio de nombres debe estar presente en el clúster de configuración. - Los usuarios que implementan Ingress en varios clústeres deben tener acceso al clúster de configuración para implementar recursos
MultiClusterIngressyMultiClusterService. Sin embargo, los usuarios solo deben tener acceso a los espacios de nombres que tengan permiso para usar.
Selecciona y migra el clúster de configuración
Debes elegir el clúster de configuración cuando habilites Ingress de varios clústeres. Cualquier clúster miembro de una flota se puede seleccionar como el clúster de configuración. Puedes actualizar el clúster de configuración en cualquier momento, pero debes asegurarte de que no provoque interrupciones. El controlador de Ingress conciliará los recursos que existan en el clúster de configuración. Cuando se migra el clúster de configuración del actual al siguiente, los recursos MultiClusterIngress y MultiClusterService deben ser idénticos.
Si los recursos no son idénticos, los balanceadores de cargas de Compute Engine pueden actualizarse o destruirse después de la actualización del clúster de configuración.
En el siguiente diagrama, se muestra cómo un sistema de CI/CD centralizado aplica los recursos MultiClusterIngress y MultiClusterService al servidor de la API de GKE para el clúster de configuración (gke-us) y un clúster de copia de seguridad (gke-eu) en todo momento, a fin de que los recursos sean idénticos en los dos clústeres. Puedes cambiar el clúster de configuración para emergencias o tiempo de inactividad planificado en cualquier momento sin ningún impacto porque los recursos MultiClusterIngress y MultiClusterServiceson idénticos.
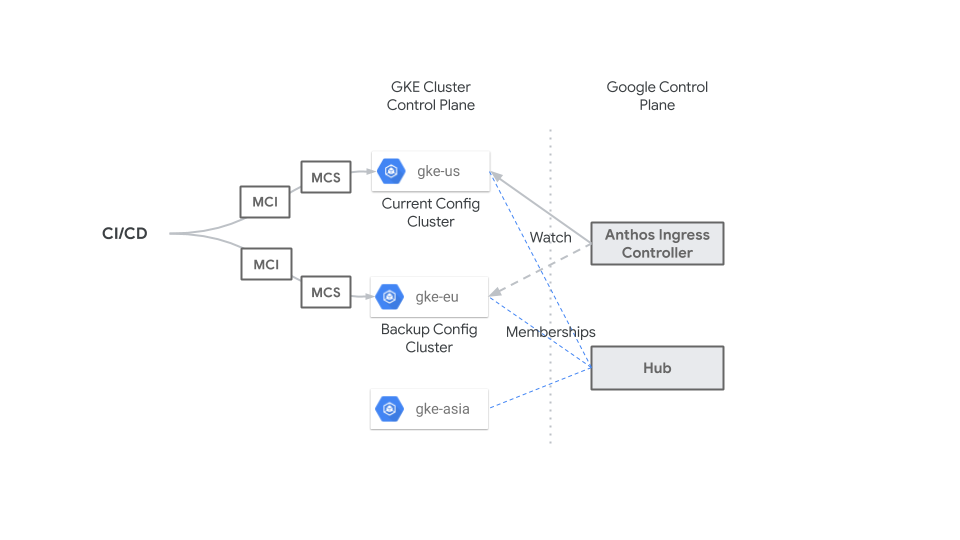
Selección de clústeres
Los recursos MultiClusterService pueden seleccionarse en todos los clústeres. De forma predeterminada, el
controlador programa un Service derivado en cada clúster de destino. Si no quieres
un Service derivado en cada clúster de destino, puedes definir una lista de
clústeres con el campo spec.clusters en el manifiesto MultiClusterService.
Se recomienda definir una lista de clústeres si necesitas realizar las siguientes acciones:
- Aislar el clúster de configuración para evitar que los recursos
MultiClusterServicese seleccionen en todo el clúster de configuración. - Controlar el tráfico entre clústeres para la migración de aplicaciones.
- Enrutar a los backends de aplicaciones que solo existen en un subconjunto de clústeres.
- Usar una sola dirección IP virtual HTTP(S) para enrutar a backends que se alojan en clústeres diferentes.
Debes asegurarte de que los clústeres miembros dentro de la misma flota y región tengan nombres únicos para evitar colisiones de nombres.
Para obtener información sobre cómo configurar la selección de clústeres, consulta Configura Ingress de varios clústeres.
En el siguiente manifiesto, se describe un MultiClusterService que tiene un campo clusters que hace referencia a europe-west1-c/gke-eu y asia-northeast1-a/gke-asia:
apiVersion: networking.gke.io/v1
kind: MultiClusterService
metadata:
name: foo
namespace: blue
spec:
template:
spec:
selector:
app: foo
ports:
- name: web
protocol: TCP
port: 80
targetPort: 80
clusters:
- link: "europe-west1-c/gke-eu"
- link: "asia-northeast1-a/gke-asia-1"
En este manifiesto, se especifica que los Pods con las etiquetas coincidentes en los clústeres gke-asia y gke-eu se pueden incluir como backends para MultiClusterIngress.
Cualquier otro clúster se excluye, incluso si tiene Pods con la etiqueta app: foo.
En el siguiente diagrama, se muestra un ejemplo de configuración de MultiClusterService con el manifiesto anterior:
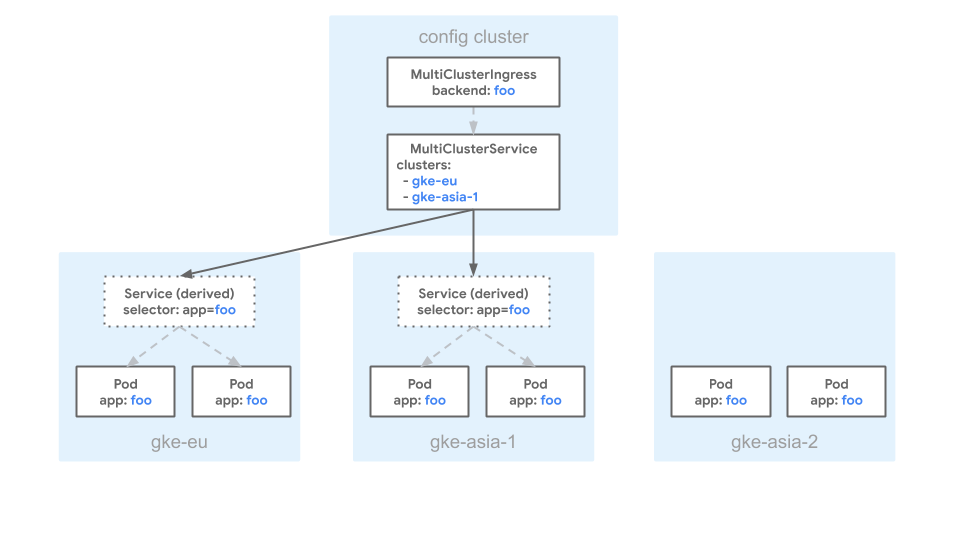
En el diagrama, hay tres clústeres: gke-eu, gke-asia-1 y gke-asia-2. El clúster gke-asia-2 no se incluye como backend, aunque haya Pods con etiquetas coincidentes, ya que el clúster no se incluye en la lista spec.clusters del manifiesto. El clúster no recibe tráfico por mantenimiento o por otras operaciones.
¿Qué sigue?
- Obtén información sobre cómo configurar Ingress de varios clústeres.
- Obtén más información sobre cómo implementar puertas de enlace de varios clústeres.
- Obtén más información sobre cómo implementar Ingress de varios clústeres.
- Implementa Ingress de varios clústeres para el balanceo de cargas externo.