Introducción
En esta guía para principiantes se presenta AutoML. Para conocer las principales diferencias entre AutoML y el entrenamiento personalizado, consulta Elegir un método de entrenamiento.
Imagina que pudieras disfrutar de lo siguiente:
- Trabajas en el departamento de marketing de una tienda digital.
- Estás trabajando en un proyecto arquitectónico que identifica tipos de edificios.
- Tu empresa tiene un formulario de contacto en su sitio web.
Seleccionar manualmente imágenes y tablas es un proceso tedioso y lento. Enseñar a un ordenador a identificar y marcar automáticamente el contenido.
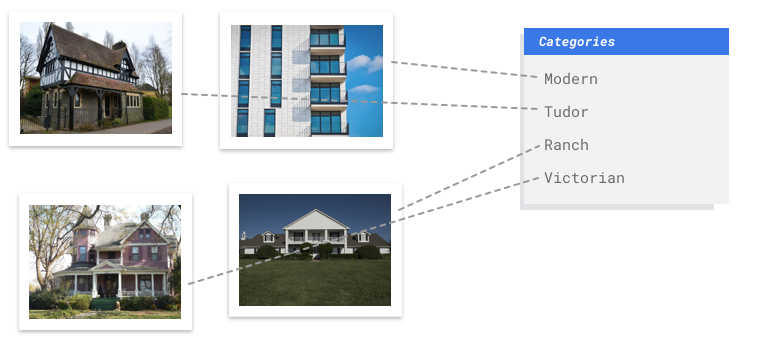
Imagen
Trabajas con una junta de conservación arquitectónica que intenta identificar barrios con un estilo arquitectónico coherente en tu ciudad. Tienes cientos de miles de fotos de casas entre las que elegir. Sin embargo, es un proceso tedioso y propenso a errores si intentas categorizar todas estas imágenes manualmente. Hace unos meses, un becario etiquetó unos cientos de ellos, pero nadie más ha consultado los datos. Sería muy útil si pudieras enseñar a tu ordenador a hacer esta revisión por ti.
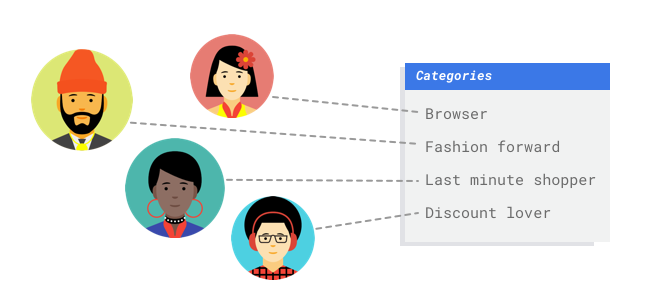
Tabular
Trabajas en el departamento de marketing de un comercio digital. Tú y tu equipo estáis creando un programa de correo personalizado basado en los buyer personas. Has creado las buyer personas y los correos de marketing están listos. Ahora debes crear un sistema que clasifique a los clientes en cada buyer persona en función de sus preferencias de compra y su comportamiento de gasto, incluso cuando sean clientes nuevos. Para maximizar la interacción con los clientes, también quieres predecir sus hábitos de gasto para optimizar el momento en el que les envías los correos.
Como eres un comercio digital, tienes datos sobre tus clientes y las compras que han hecho. ¿Y los clientes nuevos? Con los métodos tradicionales, se pueden calcular estos valores para los clientes actuales con historiales de compra largos, pero no se obtienen buenos resultados con los clientes que tienen pocos datos históricos. ¿Y si pudieras crear un sistema para predecir estos valores y aumentar la velocidad a la que ofreces programas de marketing personalizados a todos tus clientes?
Afortunadamente, el aprendizaje automático y Vertex AI están en una posición idónea para resolver estos problemas.
En esta guía se explica cómo funciona Vertex AI con los conjuntos de datos y los modelos de AutoML, y se ilustran los tipos de problemas que resuelve Vertex AI.
Nota sobre la imparcialidad
Google se compromete a seguir prácticas responsables de la IA. Para ello, nuestros productos de AA, incluido AutoML, se han diseñado en torno a principios fundamentales como la equidad y el aprendizaje automático centrado en las personas. Para obtener más información sobre las prácticas recomendadas para reducir el sesgo al crear tu propio sistema de aprendizaje automático, consulta la guía sobre la implementación de un aprendizaje automático inclusivo: AutoML.
¿Por qué Vertex AI es la herramienta adecuada para este problema?
La programación clásica requiere que el programador especifique paso a paso las instrucciones que debe seguir un ordenador. Hay tanta variación en el color, el ángulo, la resolución y la iluminación que se necesitan demasiadas reglas de programación para indicar a una máquina cómo tomar la decisión correcta. Es difícil imaginar por dónde empezar. O bien, los comentarios de los clientes usan un vocabulario y una estructura amplios y variados, y son demasiado diversos para que se puedan recoger con un conjunto de reglas sencillo. Si intentas crear filtros manuales, te darás cuenta de que no puedes clasificar la mayoría de los comentarios de tus clientes. Necesitas un sistema que pueda generalizar una gran variedad de comentarios. En un caso en el que una secuencia de reglas específicas se amplía exponencialmente, necesitas un sistema que pueda aprender de ejemplos.
Afortunadamente, el aprendizaje automático resuelve estos problemas.
¿Cómo funciona Vertex AI?
Vertex AI implica tareas de aprendizaje supervisado para conseguir un resultado concreto. Los detalles del algoritmo y los métodos de entrenamiento cambian en función del tipo de datos y del caso práctico. Existen muchas subcategorías diferentes de aprendizaje automático, y todas ellas resuelven problemas distintos y funcionan con diferentes restricciones.
Imagen
Entrenas, pruebas y validas el modelo de aprendizaje automático con imágenes de ejemplo que están anotadas con etiquetas para la clasificación o con etiquetas y cuadros delimitadores para la detección de objetos. Con el aprendizaje supervisado, puedes entrenar un modelo para que reconozca los patrones y el contenido que te interesan en las imágenes.
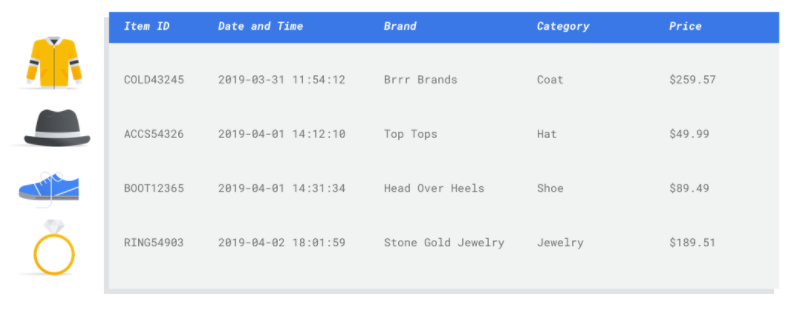
Tabular
Entrenas un modelo de aprendizaje automático con datos de ejemplo. Vertex AI usa datos tabulares (estructurados) para entrenar un modelo de aprendizaje automático que haga inferencias sobre datos nuevos. Una columna de tu conjunto de datos, llamada objetivo, es lo que tu modelo aprenderá a predecir. Algunas de las otras columnas de datos son entradas (denominadas "características") de las que el modelo aprenderá patrones. Puedes usar las mismas características de entrada para crear varios tipos de modelos con solo cambiar la columna de destino y las opciones de entrenamiento. En el ejemplo de marketing por correo electrónico, esto significa que puedes crear modelos con las mismas funciones de entrada, pero con diferentes inferencias de destino. Un modelo podría predecir el perfil de un cliente (un objetivo categórico), otro podría predecir su gasto mensual (un objetivo numérico) y otro podría pronosticar la demanda diaria de tus productos durante los próximos tres meses (una serie de objetivos numéricos).
Flujo de trabajo de Vertex AI
Vertex AI usa un flujo de trabajo de aprendizaje automático estándar:
- Recopila tus datos: determina los datos que necesitas para entrenar y probar tu modelo en función del resultado que quieras conseguir.
- Prepara tus datos: asegúrate de que tengan el formato y las etiquetas adecuados.
- Entrenamiento: define los parámetros y crea tu modelo.
- Evaluar: revisa las métricas del modelo.
- Despliega y predice: haz que tu modelo esté disponible para usarlo.
Preparación de datos
Pero, antes de empezar a recoger datos, piensa en el problema que quieres resolver. Esto determina los requisitos de datos.
Evaluar tu caso práctico
Empieza por el problema: ¿qué quieres conseguir?
Imagen
Cuando elabores el conjunto de datos, empieza siempre por tu caso práctico. Puedes empezar con las siguientes preguntas:
- ¿Qué resultado quieres conseguir?
- ¿Qué tipos de categorías u objetos tendrías que reconocer para conseguir este resultado?
- ¿Es posible que los humanos reconozcan esas categorías? Aunque Vertex AI puede gestionar una mayor magnitud de categorías de las que los humanos pueden recordar y asignar en un momento dado, si una persona no reconoce una categoría específica, Vertex AI también tendrá dificultades.
- ¿Qué tipo de ejemplos reflejarían mejor el tipo y el intervalo de datos que verá tu sistema y que intentará clasificar?
Tabular
¿Qué tipo de datos tiene la columna de destino? ¿A cuántos datos tienes acceso? En función de tus respuestas, Vertex AI crea el modelo necesario para resolver tu caso práctico:
- Un modelo de clasificación binaria predice un resultado binario (una de las dos clases). Úsalo para preguntas con respuesta afirmativa o negativa, por ejemplo, para predecir si un cliente comprará una suscripción (o no). Si todo lo demás es igual, un problema de clasificación binaria requiere menos datos que otros tipos de modelos.
- Un modelo de clasificación de varias clases predice una clase entre tres o más clases discretas. Úsalo para clasificar elementos. En el ejemplo del comercio, te interesaría crear un modelo de clasificación multiclase para segmentar a los clientes en diferentes buyer personas.
- Un modelo de previsión predice una secuencia de valores. Por ejemplo, como comerciante, puede que quiera predecir la demanda diaria de sus productos durante los próximos tres meses para poder almacenar los inventarios de productos de forma adecuada con antelación.
- Un modelo de regresión predice un valor continuo. En el ejemplo de la tienda, te interesaría crear un modelo de regresión para predecir cuánto gastará un cliente el mes que viene.
Recopila tus datos
Una vez que hayas definido tu caso práctico, recoge los datos que te permitan crear el modelo que quieras.
Imagen
 Una vez que hayas determinado qué datos necesitas, tendrás que encontrar una forma de obtenerlos. Puedes empezar por analizar todos los datos que recoge tu organización. Puede que ya estés recogiendo los datos relevantes que necesitas para entrenar un modelo. Si no tienes esos datos, puedes obtenerlos manualmente o subcontratarlos a un proveedor externo.
Una vez que hayas determinado qué datos necesitas, tendrás que encontrar una forma de obtenerlos. Puedes empezar por analizar todos los datos que recoge tu organización. Puede que ya estés recogiendo los datos relevantes que necesitas para entrenar un modelo. Si no tienes esos datos, puedes obtenerlos manualmente o subcontratarlos a un proveedor externo.
Incluir suficientes ejemplos etiquetados en cada categoría
 El mínimo que requiere Vertex AI Training es de 100 ejemplos de imágenes por categoría o etiqueta para la clasificación.
La probabilidad de reconocer correctamente una etiqueta aumenta con el número de ejemplos de alta calidad de cada una. En general, cuantos más datos etiquetados puedas aportar al proceso de entrenamiento, mejor será tu modelo. Incluya al menos 1000 ejemplos por etiqueta.
El mínimo que requiere Vertex AI Training es de 100 ejemplos de imágenes por categoría o etiqueta para la clasificación.
La probabilidad de reconocer correctamente una etiqueta aumenta con el número de ejemplos de alta calidad de cada una. En general, cuantos más datos etiquetados puedas aportar al proceso de entrenamiento, mejor será tu modelo. Incluya al menos 1000 ejemplos por etiqueta.
Distribuir los ejemplos de forma equitativa entre las categorías
Es importante que haya una cantidad de ejemplos de entrenamiento similar para cada categoría. Aunque tengas muchos datos de una etiqueta, es mejor que la distribución sea equitativa para todas las etiquetas. Para entender por qué, imagina que el 80% de las imágenes que usas para crear tu modelo son fotos de casas unifamiliares de estilo moderno. Con una distribución de etiquetas tan desequilibrada, es muy probable que tu modelo aprenda que es seguro decir que una foto es de una casa unifamiliar moderna, en lugar de arriesgarse a predecir una etiqueta mucho menos común.
Es como escribir un examen de tipo test en el que casi todas las respuestas correctas son la "C". En poco tiempo, el alumno se dará cuenta de que puede responder "C" siempre sin siquiera mirar la pregunta.
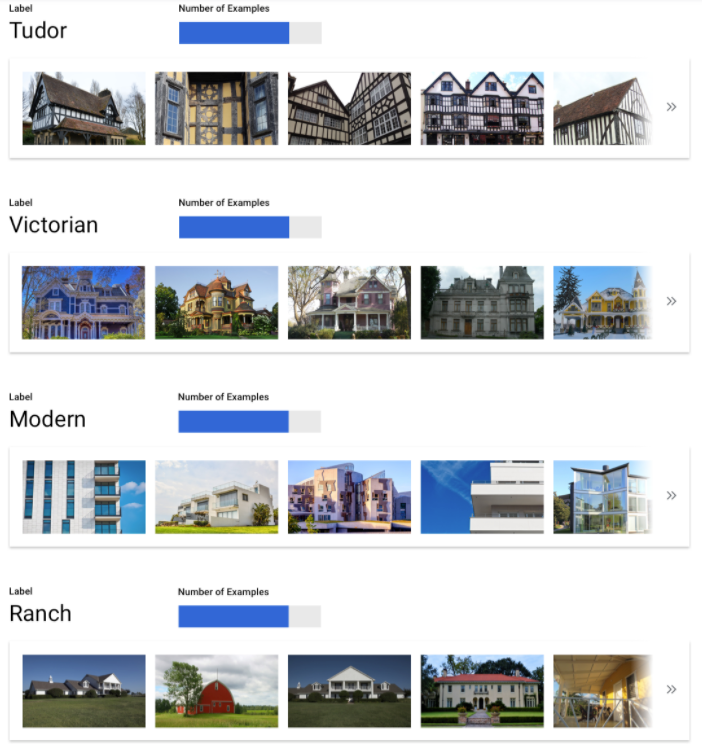
Somos conscientes de que no siempre es posible obtener un número de ejemplos aproximadamente igual para cada etiqueta. Puede que sea más difícil encontrar ejemplos de alta calidad y objetivos para algunas categorías. En esos casos, puedes seguir esta regla general: la etiqueta con el menor número de ejemplos debe tener al menos el 10% de los ejemplos de la etiqueta con el mayor número de ejemplos. Por lo tanto, si la etiqueta más grande tiene 10.000 ejemplos, la más pequeña debe tener al menos 1000.
Captura la variación en tu espacio de problemas
Por motivos similares, intenta que tus datos reflejen la variedad y la diversidad de tu espacio de problemas. Cuanto más amplia sea la selección que vea el proceso de entrenamiento del modelo, más fácilmente se generalizará a nuevos ejemplos. Por ejemplo, si quieres clasificar fotos de productos electrónicos de consumo en categorías, cuanto mayor sea la variedad de productos electrónicos de consumo a los que se exponga el modelo durante el entrenamiento, más probable será que pueda distinguir entre un modelo nuevo de tablet, teléfono u ordenador portátil, aunque nunca haya visto ese modelo específico.
Hacer coincidir los datos con el resultado previsto del modelo

Busca imágenes que sean visualmente similares a las que quieres usar para hacer inferencias. Si intentas clasificar imágenes de casas que se han tomado en invierno con nieve, probablemente no obtendrás un buen rendimiento de un modelo entrenado solo con imágenes de casas tomadas en un día soleado, aunque las hayas etiquetado con las clases que te interesan, ya que la iluminación y el paisaje pueden ser lo suficientemente diferentes como para afectar al rendimiento. Lo ideal es que los ejemplos de entrenamiento sean datos reales
extraídos del mismo conjunto de datos que tienes previsto usar para clasificar con el modelo.
Tabular
Una vez que hayas definido tu caso práctico, tendrás que recoger datos para entrenar tu modelo.
La obtención y la preparación de datos son pasos fundamentales para crear un modelo de aprendizaje automático.
Los datos que tengas disponibles determinarán el tipo de problemas que puedes resolver. ¿Cuántos datos tienes disponibles? ¿Los datos son relevantes para las preguntas que quieres responder? Cuando recoja sus datos, tenga en cuenta los siguientes aspectos clave.
Selecciona las funciones pertinentes
Una función es un atributo de entrada que se usa para entrenar un modelo. Las funciones son la forma en que tu modelo identifica patrones para hacer inferencias, por lo que deben ser relevantes para tu problema. Por ejemplo, para crear un modelo que prediga si una transacción con tarjeta de crédito es fraudulenta o no, tendrás que crear un conjunto de datos que contenga detalles de la transacción, como el comprador, el vendedor, el importe, la fecha y la hora, y los artículos comprados. Otras funciones útiles podrían ser la información histórica sobre el comprador y el vendedor, y la frecuencia con la que el artículo comprado ha estado implicado en fraudes. ¿Qué otras funciones pueden ser relevantes?
Consideremos el caso práctico de marketing por correo electrónico en el sector retail que hemos visto en la introducción. Estas son algunas de las columnas de características que puedes necesitar:
- Lista de artículos comprados (incluidas las marcas, las categorías, los precios y los descuentos)
- Número de artículos comprados (último día, semana, mes o año)
- Suma del dinero gastado (último día, semana, mes o año)
- Número total de unidades vendidas de cada artículo cada día
- De cada artículo, el total en stock cada día
- Si vas a lanzar una promoción para un día concreto
- Perfil demográfico conocido del comprador
Incluir suficientes datos
En general, cuantos más ejemplos de entrenamiento tengas, mejores serán los resultados. La cantidad de datos de ejemplo necesarios también aumenta en función de la complejidad del problema que quieras resolver. No necesitarás tantos datos para obtener un modelo de clasificación binaria preciso en comparación con un modelo de varias clases, ya que es menos complicado predecir una clase a partir de dos que a partir de muchas.
No hay una fórmula perfecta, pero sí unos mínimos recomendados de datos de ejemplo:
- Problema de clasificación: 50 filas x el número de funciones
- Problema de previsión:
- 5000 filas x el número de características
- 10 valores únicos en la columna del identificador de la serie temporal x el número de características
- Problema de regresión: 200 veces el número de funciones
Capturar variación
Tu conjunto de datos debe reflejar la diversidad del problema. Cuantos más ejemplos diversos vea un modelo durante el entrenamiento, más fácilmente podrá generalizar a ejemplos nuevos o menos comunes. Imagina que tu modelo de comercio se ha entrenado solo con datos de compra del invierno. ¿Podría predecir correctamente las preferencias de ropa de verano o los comportamientos de compra?
Preparar los datos
Imagen
 Una vez que hayas decidido qué opción es la más adecuada (manual o predeterminada), puedes añadir datos en
Vertex AI mediante uno de los siguientes métodos:
Una vez que hayas decidido qué opción es la más adecuada (manual o predeterminada), puedes añadir datos en
Vertex AI mediante uno de los siguientes métodos:
- Puedes importar datos desde tu ordenador o desde Cloud Storage en un formato disponible (CSV o JSON Lines) con las etiquetas (y los cuadros delimitadores, si es necesario) insertadas. Para obtener más información sobre el formato de los archivos de importación, consulta el artículo Preparar los datos de entrenamiento. Si quieres dividir tu conjunto de datos manualmente, puedes especificar las divisiones en el archivo de importación CSV o JSON Lines.
- Si sus datos no se han anotado, puede subir imágenes sin etiquetar y usar la Google Cloud consola para aplicar anotaciones. Puedes gestionar estas anotaciones en varios conjuntos de anotaciones para el mismo conjunto de imágenes. Por ejemplo, en un conjunto de imágenes, puedes tener un conjunto de anotaciones con información de cuadros delimitadores y etiquetas para detectar objetos, así como otro conjunto de anotaciones con solo etiquetas para la clasificación.
Tabular
Una vez que hayas identificado los datos disponibles, debes asegurarte de que estén listos para el entrenamiento.
Si los datos están sesgados o contienen valores que faltan o son erróneos, esto afectará a la calidad del modelo. Antes de empezar a entrenar tu modelo, ten en cuenta lo siguiente.
Más información
Evitar las fugas de datos y la desviación entre el entrenamiento y el servicio
La fuga de datos se produce cuando usas funciones de entrada durante el entrenamiento que "filtran" información sobre el objetivo que intentas predecir, que no está disponible cuando se usa el modelo. Esto se puede detectar cuando se incluye como una de las funciones de entrada una función que está muy correlacionada con la columna de destino. Por ejemplo, si estás creando un modelo para predecir si un cliente se suscribirá en el próximo mes y una de las funciones de entrada es un pago de suscripción futuro de ese cliente. Esto puede dar lugar a un buen rendimiento del modelo durante las pruebas, pero no cuando se implementa en producción, ya que la información de pago de la suscripción futura no está disponible en el momento de la publicación.
La desviación entre el entrenamiento y el servicio se produce cuando las funciones de entrada que se usan durante el entrenamiento son diferentes de las que se proporcionan al modelo durante el servicio, lo que provoca que la calidad del modelo en producción sea deficiente. Por ejemplo, crear un modelo para predecir las temperaturas por horas, pero entrenarlo con datos que solo contengan temperaturas semanales. Otro ejemplo: siempre se proporcionan las calificaciones de un alumno en los datos de entrenamiento al predecir si abandonará los estudios, pero no se proporciona esta información en el momento de la publicación.
Es importante que conozcas tus datos de entrenamiento para evitar fugas de datos y sesgos entre el entrenamiento y el servicio:
- Antes de usar cualquier dato, asegúrate de saber qué significa y si debes usarlo como una función.
- Consulta la correlación en la pestaña Entrenar. Las correlaciones altas deben marcarse para su revisión.
- Desfase entre el entrenamiento y el servicio: asegúrate de proporcionar al modelo solo las funciones de entrada que estén disponibles en el mismo formato en el momento del servicio.
Limpiar los datos que faltan, que están incompletos o que son incoherentes
Es habitual que falten valores o que sean imprecisos en los datos de ejemplo. Dedica tiempo a revisar y, si es posible, mejorar la calidad de tus datos antes de usarlos para el entrenamiento. Cuantos más valores falten, menos útiles serán los datos para entrenar un modelo de aprendizaje automático.
- Compruebe si faltan valores en sus datos y corríjalos si es posible. Si la columna se ha configurado para aceptar valores nulos, deje el valor en blanco. Vertex AI puede gestionar los valores que faltan, pero es más probable que obtengas resultados óptimos si todos los valores están disponibles.
- Para las previsiones, comprueba que el intervalo entre las filas de entrenamiento sea constante. Vertex AI puede imputar los valores que faltan, pero es más probable que obtengas resultados óptimos si todas las filas están disponibles.
- Limpia tus datos corrigiendo o eliminando errores o ruido. Unifica tus datos: Revisa la ortografía, las abreviaturas y el formato.
Analizar los datos después de importarlos
Vertex AI ofrece una vista general de tu conjunto de datos después de importarlo. Revisa el conjunto de datos importado para asegurarte de que cada columna tiene el tipo de variable correcto. Vertex AI detectará automáticamente el tipo de variable en función de los valores de las columnas, pero es mejor que revises cada una. También debe revisar si se pueden incluir valores nulos en cada columna, lo que determina si una columna puede tener valores que faltan o valores nulos.
Entrenar
Imagen
Considera cómo usa Vertex AI tu conjunto de datos para crear un modelo personalizado
Tu conjunto de datos contiene conjuntos de entrenamiento, validación y prueba. Si no especificas las divisiones (consulta Preparar los datos), Vertex AI usará automáticamente el 80% de las imágenes para el entrenamiento, el 10% para la validación y el 10% para las pruebas.
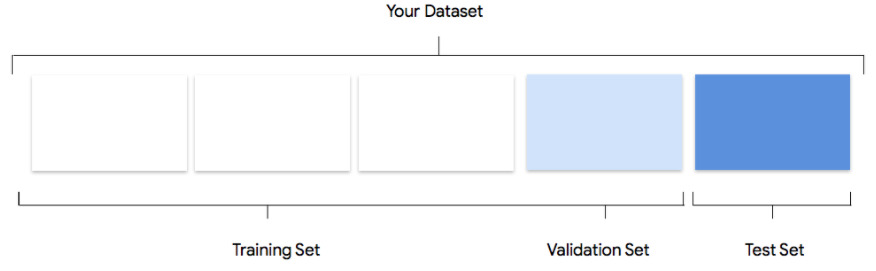
Conjunto de entrenamiento
 La gran mayoría de los datos deben estar en el conjunto de entrenamiento. Estos son los datos que "ve" tu modelo
durante el entrenamiento: se usan para aprender los parámetros del modelo, es decir, los pesos de las
conexiones entre los nodos de la red neuronal.
La gran mayoría de los datos deben estar en el conjunto de entrenamiento. Estos son los datos que "ve" tu modelo
durante el entrenamiento: se usan para aprender los parámetros del modelo, es decir, los pesos de las
conexiones entre los nodos de la red neuronal.
Conjunto de validación
 El conjunto de validación, a veces también llamado conjunto de desarrollo, también se usa durante el proceso de entrenamiento.
Después de que el framework de aprendizaje del modelo incorpore los datos de entrenamiento durante cada iteración del proceso de entrenamiento, usa el rendimiento del modelo en el conjunto de datos de validación para ajustar los hiperparámetros del modelo, que son variables que especifican la estructura del modelo. Si has intentado usar el conjunto de entrenamiento para ajustar los hiperparámetros, es muy probable que el modelo se centre demasiado en los datos de entrenamiento y tenga dificultades para generalizar los ejemplos que no coincidan exactamente con ellos.
Si usas un conjunto de datos algo novedoso para ajustar la estructura del modelo, este se generalizará mejor.
El conjunto de validación, a veces también llamado conjunto de desarrollo, también se usa durante el proceso de entrenamiento.
Después de que el framework de aprendizaje del modelo incorpore los datos de entrenamiento durante cada iteración del proceso de entrenamiento, usa el rendimiento del modelo en el conjunto de datos de validación para ajustar los hiperparámetros del modelo, que son variables que especifican la estructura del modelo. Si has intentado usar el conjunto de entrenamiento para ajustar los hiperparámetros, es muy probable que el modelo se centre demasiado en los datos de entrenamiento y tenga dificultades para generalizar los ejemplos que no coincidan exactamente con ellos.
Si usas un conjunto de datos algo novedoso para ajustar la estructura del modelo, este se generalizará mejor.
Conjunto de prueba
 El conjunto de pruebas no participa en el proceso de entrenamiento. Una vez que el modelo haya completado todo el entrenamiento, usaremos el conjunto de pruebas como un reto completamente nuevo para tu modelo. El
rendimiento de tu modelo en el conjunto de prueba te dará una idea bastante precisa de cómo
funcionará tu modelo con datos reales.
El conjunto de pruebas no participa en el proceso de entrenamiento. Una vez que el modelo haya completado todo el entrenamiento, usaremos el conjunto de pruebas como un reto completamente nuevo para tu modelo. El
rendimiento de tu modelo en el conjunto de prueba te dará una idea bastante precisa de cómo
funcionará tu modelo con datos reales.
División manual
 También puedes dividir tu conjunto de datos. Dividir los datos manualmente es una buena opción cuando quieres tener más control sobre el proceso o si hay ejemplos específicos que quieres incluir en una parte concreta del ciclo de vida del entrenamiento del modelo.
También puedes dividir tu conjunto de datos. Dividir los datos manualmente es una buena opción cuando quieres tener más control sobre el proceso o si hay ejemplos específicos que quieres incluir en una parte concreta del ciclo de vida del entrenamiento del modelo.
Tabular
Una vez que hayas importado el conjunto de datos, el siguiente paso es entrenar un modelo. Vertex AI generará un modelo de aprendizaje automático fiable con los valores predeterminados de entrenamiento, pero es posible que quieras ajustar algunos de los parámetros en función de tu caso práctico.
Intenta seleccionar tantas columnas de características como sea posible para el entrenamiento, pero revisa cada una de ellas para asegurarte de que es adecuada para el entrenamiento. Ten en cuenta lo siguiente al seleccionar funciones:
- No seleccione columnas de características que generen ruido, como columnas de identificadores asignados aleatoriamente con un valor único para cada fila.
- Asegúrese de que entiende cada columna de características y sus valores.
- Si vas a crear varios modelos a partir de un conjunto de datos, elimina las columnas de destino que no formen parte del problema de inferencia actual.
- Recuerda los principios de equidad: ¿estás entrenando tu modelo con una función que podría dar lugar a toma de decisiones sesgada o injusta para grupos marginados?
Cómo usa Vertex AI tu conjunto de datos
Tu conjunto de datos se dividirá en conjuntos de entrenamiento, validación y prueba. La división predeterminada que aplica Vertex AI depende del tipo de modelo que estés entrenando. También puedes especificar las divisiones (divisiones manuales) si es necesario. Para obtener más información, consulta Acerca de las divisiones de datos para los modelos de AutoML.
Conjunto de entrenamiento
La gran mayoría de los datos deben estar en el conjunto de entrenamiento. Estos son los datos que "ve" tu modelo
durante el entrenamiento: se usan para aprender los parámetros del modelo, es decir, los pesos de las
conexiones entre los nodos de la red neuronal.
Conjunto de validación
El conjunto de validación, a veces también llamado conjunto de desarrollo, también se usa durante el proceso de entrenamiento.
Después de que el framework de aprendizaje del modelo incorpore los datos de entrenamiento durante cada iteración del proceso de entrenamiento, usa el rendimiento del modelo en el conjunto de datos de validación para ajustar los hiperparámetros del modelo, que son variables que especifican la estructura del modelo. Si has intentado usar el conjunto de entrenamiento para ajustar los hiperparámetros, es muy probable que el modelo se centre demasiado en los datos de entrenamiento y tenga dificultades para generalizar los ejemplos que no coincidan exactamente con ellos.
Si usas un conjunto de datos algo novedoso para ajustar la estructura del modelo, este se generalizará mejor.
Conjunto de prueba
El conjunto de pruebas no participa en el proceso de entrenamiento. Una vez que el modelo haya completado el entrenamiento, Vertex AI usará el conjunto de prueba como un reto completamente nuevo para el modelo.
El rendimiento de tu modelo en el conjunto de prueba te dará una idea bastante precisa de cómo se comportará tu modelo con datos reales.
Evalúa, prueba y despliega tu modelo
Evaluar modelo
Imagen
Una vez que se haya entrenado el modelo, recibirás un resumen de su rendimiento. Haz clic en Evaluar o Ver evaluación completa para ver un análisis detallado.
 Depurar un modelo consiste más en depurar los datos que el modelo en sí. Si en algún momento tu modelo empieza a actuar de forma inesperada mientras evalúas su rendimiento antes y después de implementarlo en producción, deberías volver y revisar tus datos para ver dónde se puede mejorar.
Depurar un modelo consiste más en depurar los datos que el modelo en sí. Si en algún momento tu modelo empieza a actuar de forma inesperada mientras evalúas su rendimiento antes y después de implementarlo en producción, deberías volver y revisar tus datos para ver dónde se puede mejorar.
¿Qué tipos de análisis puedo realizar en Vertex AI?
En la sección de evaluación de Vertex AI, puedes evaluar el rendimiento de tu modelo personalizado usando la salida del modelo en ejemplos de prueba y métricas comunes de aprendizaje automático. En esta sección, explicaremos qué significa cada uno de estos conceptos.
- Salida del modelo
- El umbral de puntuación
- Verdaderos positivos, verdaderos negativos, falsos positivos y falsos negativos
- Precisión y recuperación
- Curvas de precisión y recuperación
- Precisión media
¿Cómo interpreto los resultados del modelo?
Vertex AI extrae ejemplos de tus datos de prueba para plantear retos totalmente nuevos a tu modelo. En cada ejemplo, el modelo genera una serie de números que indican la intensidad con la que asocia cada etiqueta a ese ejemplo. Si el número es alto, el modelo tiene un nivel de confianza alto de que la etiqueta se debe aplicar a ese documento.

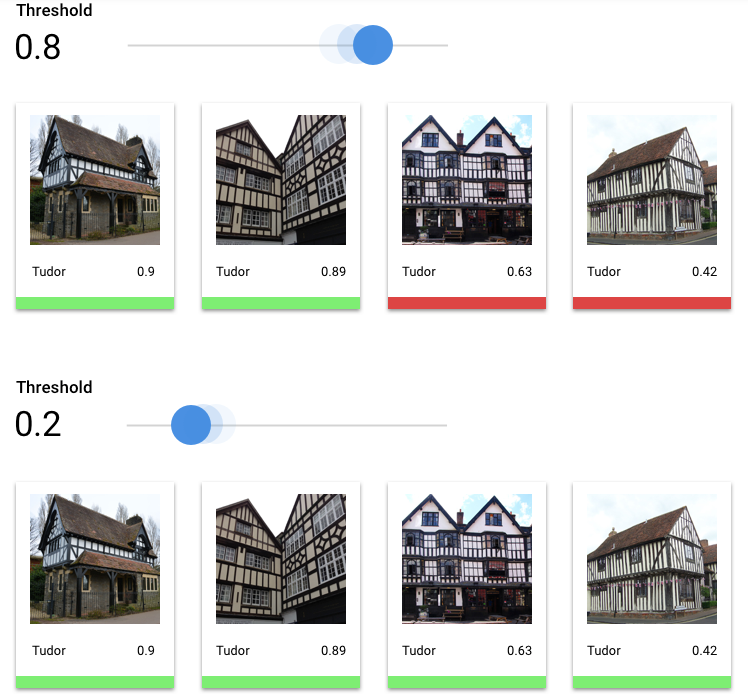
¿Qué es el umbral de puntuación?
Podemos convertir estas probabilidades en valores binarios de activado o desactivado definiendo un umbral de puntuación.
El umbral de puntuación es el nivel de confianza que debe tener el modelo para asignar una categoría a un elemento de prueba. El control deslizante del umbral de puntuación de la Google Cloud consola es una herramienta visual para probar el efecto de diferentes umbrales en todas las categorías y en categorías concretas de tu conjunto de datos.
Si el umbral de puntuación es bajo, el modelo clasificará más imágenes, pero corre el riesgo de clasificar erróneamente algunas imágenes durante el proceso. Si el umbral de puntuación es alto, el modelo clasificará menos imágenes, pero tendrá un menor riesgo de clasificarlas incorrectamente. Puedes modificar los umbrales por categoría en la Google Cloud consola para experimentar. Sin embargo, cuando utilice su modelo en producción, debe aplicar los umbrales que haya determinado como óptimos.
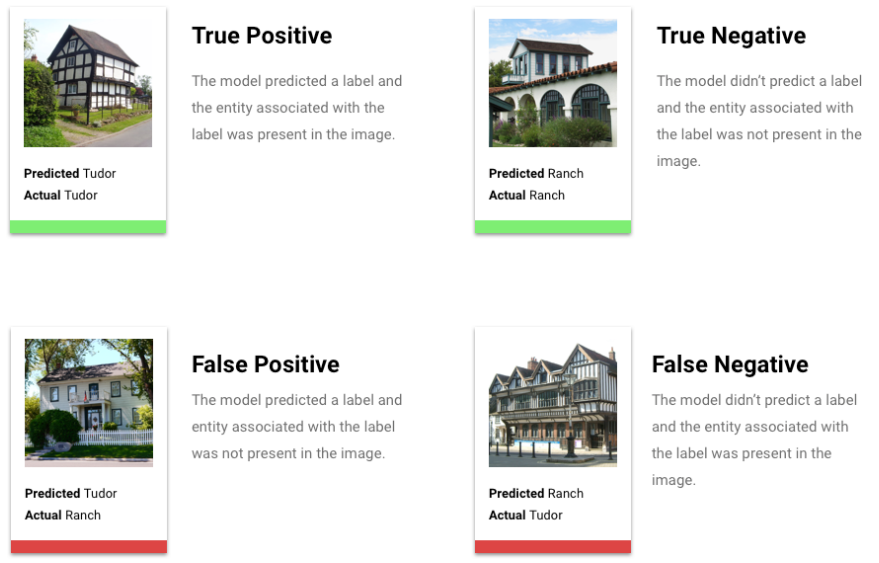
¿Qué son los verdaderos positivos, los verdaderos negativos, los falsos positivos y los falsos negativos?
Después de aplicar el umbral de puntuación, las inferencias que haga tu modelo se incluirán en una de las cuatro categorías siguientes:
Los umbrales que hayas considerado óptimos.
Podemos usar estas categorías para calcular la precisión y el recuerdo, métricas que nos ayudan a medir la eficacia de nuestro modelo.
¿Qué son la precisión y la recuperación?
La precisión y la recuperación nos ayudan a entender cómo capta la información nuestro modelo y cuánta información deja fuera. La precisión nos indica, de todos los ejemplos de prueba a los que se les ha asignado una etiqueta, cuántos se suponía que debían categorizarse con esa etiqueta. La recuperación nos indica, de todos los ejemplos de prueba que deberían haber tenido asignada la etiqueta, cuántos la tenían asignada.
¿Debo optimizar la precisión o la recuperación?
En función de tu caso práctico, puede que te interese optimizar la precisión o la recuperación. Ten en cuenta los dos casos prácticos que se indican a continuación para decidir qué enfoque es el más adecuado para ti.
Caso práctico: privacidad en las imágenes
Supongamos que quieres crear un sistema que detecte automáticamente información sensible y la oculte.

En este caso, los falsos positivos serían elementos que no necesitan desenfocarse y que se desenfocan,
lo que puede resultar molesto, pero no perjudicial.

En este caso, se produce un falso negativo cuando no se difumina algo que debería difuminarse, como una tarjeta de crédito, lo que puede provocar un robo de identidad.
En este caso, te convendría optimizar la recuperación. Esta métrica mide, de todas las inferencias realizadas, cuántas se están omitiendo. Es probable que un modelo de alta recuperación etiquete ejemplos marginalmente relevantes. Esto es útil en los casos en los que tu categoría tiene pocos datos de entrenamiento.
Caso práctico: búsqueda de fotos de stock
Supongamos que quieres crear un sistema que encuentre la mejor foto de stock para una palabra clave determinada.

En este caso, se produce un falso positivo cuando se devuelve una imagen irrelevante. Como tu producto se caracteriza por devolver solo las imágenes que mejor se ajustan a la consulta, esto sería un error grave.

En este caso, se produce un falso negativo cuando no se devuelve una imagen relevante para una búsqueda por palabras clave. Como muchos términos de búsqueda tienen miles de fotos que son una coincidencia potencial, no hay problema.
En este caso, le convendría optimizar la precisión. Esta métrica mide la precisión de todas las inferencias realizadas. Es probable que un modelo de alta precisión solo etiquete los ejemplos más relevantes, lo que resulta útil en los casos en los que tu clase sea habitual en los datos de entrenamiento.
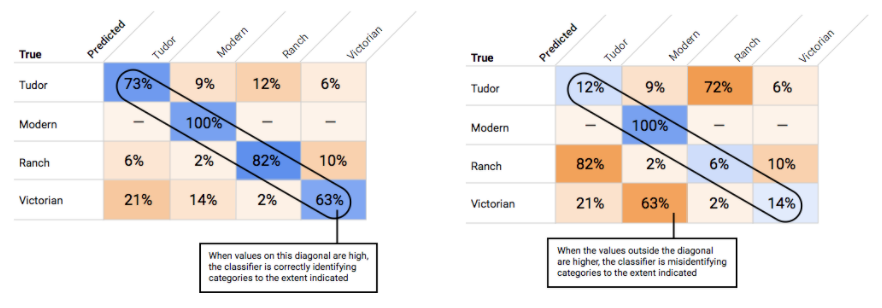
¿Cómo uso la matriz de confusión?
¿Cómo interpreto las curvas de precisión-recuperación?
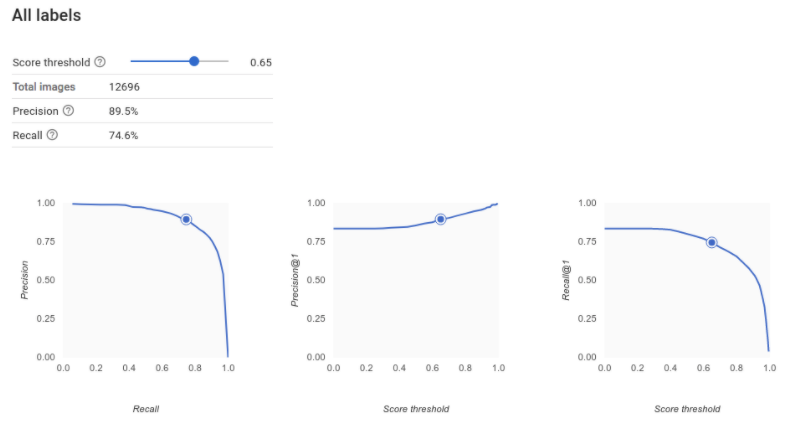
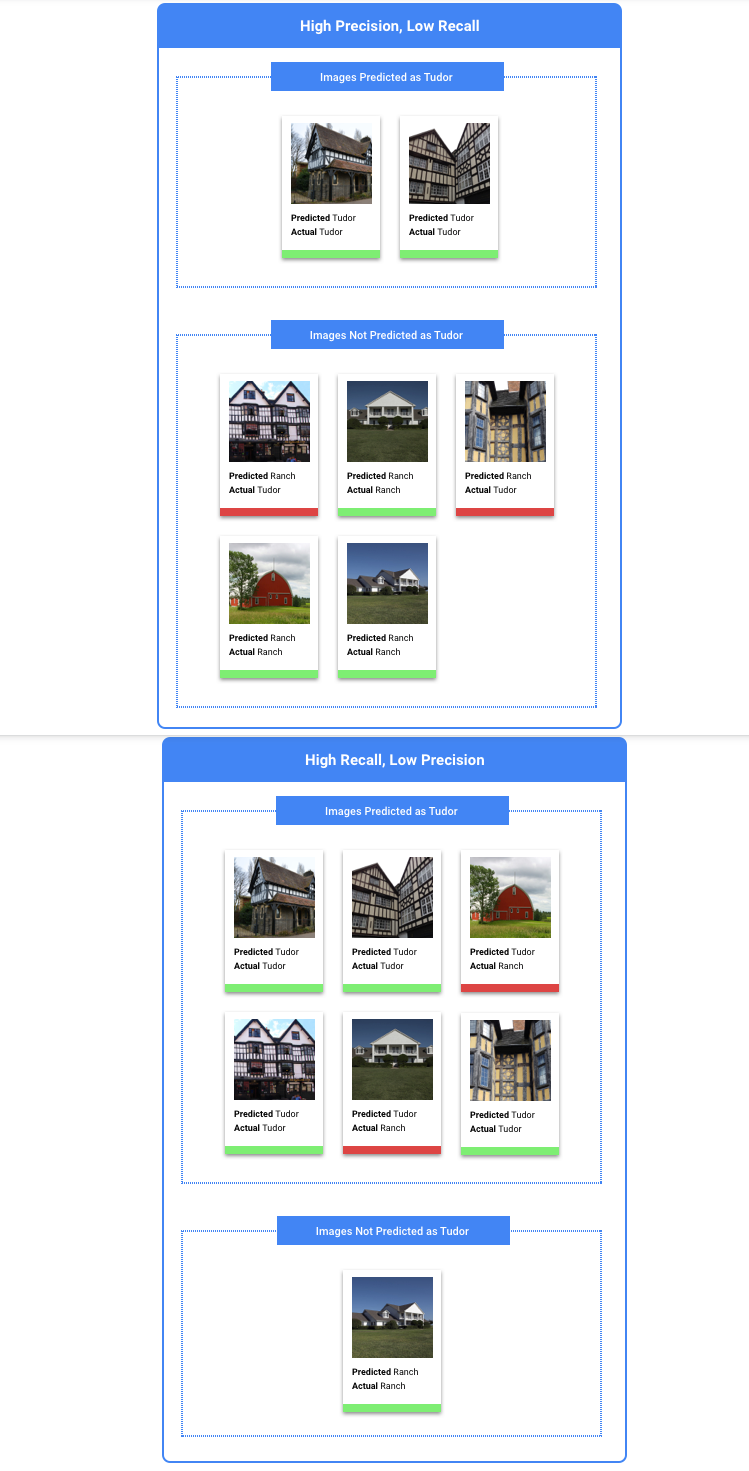
La herramienta de umbral de puntuación te permite ver cómo afecta el umbral de puntuación que has elegido a la precisión y la recuperación. Mientras arrastras el control deslizante de la barra de umbral de puntuación, puedes ver en qué punto de la curva de compensación de precisión-recuperación te sitúa ese umbral, así como el efecto que tiene en la precisión y la recuperación por separado (en el caso de los modelos multiclase, en estos gráficos, la precisión y la recuperación significan que la única etiqueta que se usa para calcular las métricas de precisión y recuperación es la etiqueta con la puntuación más alta del conjunto de etiquetas que devolvemos). De esta forma, podrás encontrar un buen equilibrio entre los falsos positivos y los falsos negativos.
Una vez que hayas elegido un umbral que te parezca aceptable para tu modelo en general, haz clic en las etiquetas individuales y consulta dónde se encuentra ese umbral en su curva de precisión-recall por etiqueta. En algunos casos, puede que obtengas muchas inferencias incorrectas para algunas etiquetas, lo que puede ayudarte a decidirte por un umbral por clase personalizado para esas etiquetas. Por ejemplo, supongamos que examinas tu conjunto de datos de casas y observas que un umbral de 0,5 tiene una precisión y un recall razonables para todos los tipos de imágenes, excepto para "Tudor", quizá porque es una categoría muy general. En esa categoría, verás muchísimos falsos positivos. En ese caso, puede que decidas usar un umbral de 0,8 solo para "Tudor" cuando llames al clasificador para obtener inferencias.
¿Qué es la precisión media?
Una métrica útil para medir la precisión de un modelo es el área por debajo de la curva de precisión-recuperación. Mide el rendimiento de tu modelo en todos los umbrales de puntuación. En Vertex AI, esta métrica se llama "Precisión media". Cuanto más se acerque esta puntuación a 1, mejor será el rendimiento de tu modelo en el conjunto de prueba. Un modelo que adivinara al azar cada etiqueta obtendría una precisión media de aproximadamente 0,5.
Tabular
Una vez que se haya entrenado el modelo, recibirás un resumen de su rendimiento. Las métricas de evaluación del modelo se basan en el rendimiento del modelo en una parte de su conjunto de datos (el conjunto de datos de prueba). Hay un par de métricas y conceptos clave que debes tener en cuenta para determinar si tu modelo está listo para usarse con datos reales.
Métricas de clasificación
Umbral de puntuación
Imagina un modelo de aprendizaje automático que predice si un cliente comprará una chaqueta el año que viene. ¿Con qué certeza debe contar el modelo para predecir que un cliente comprará una chaqueta? En los modelos de clasificación, a cada inferencia se le asigna una puntuación de fiabilidad, que es una evaluación numérica de la certeza del modelo de que la clase predicha es correcta. El umbral de puntuación es el número que determina cuándo se convierte una puntuación en una decisión afirmativa o negativa. Es decir, el valor en el que tu modelo dice "sí, esta puntuación de confianza es lo suficientemente alta como para concluir que este cliente comprará un abrigo el año que viene".
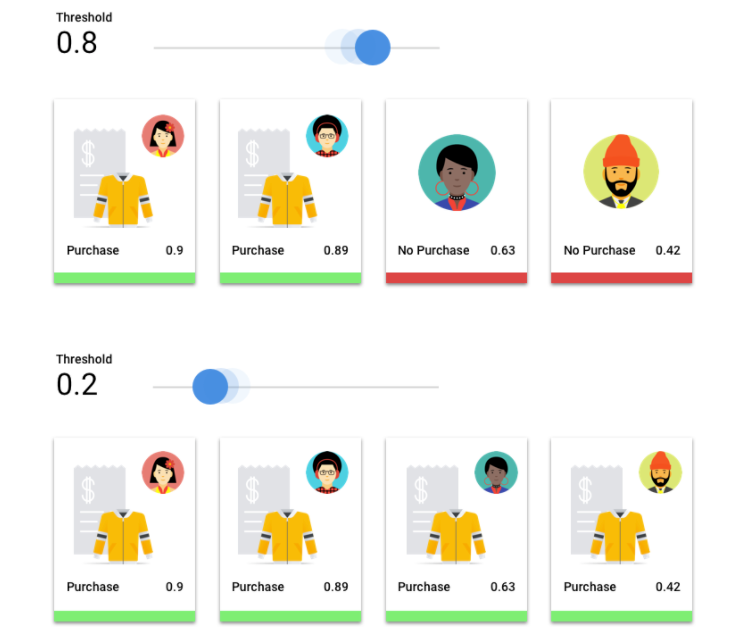
Si el umbral de puntuación es bajo, el modelo correrá el riesgo de clasificar erróneamente los datos. Por ese motivo, el umbral de puntuación debe basarse en un caso práctico concreto.
Resultados de inferencia
Después de aplicar el umbral de puntuación, las inferencias que haga tu modelo se incluirán en una de las cuatro categorías. Para entender estas categorías, volvamos a imaginar un modelo de clasificación binaria de chaquetas. En este ejemplo, la clase positiva (lo que el modelo intenta predecir) es que el cliente comprará una chaqueta el año que viene.
- Verdadero positivo: el modelo predice correctamente la clase positiva. El modelo ha predicho correctamente que un cliente ha comprado una chaqueta.
- Falso positivo: el modelo predice incorrectamente la clase positiva. El modelo ha predicho que un cliente ha comprado una chaqueta, pero no es así.
- Negativo verdadero: el modelo predice correctamente la clase negativa. El modelo ha predicho correctamente que un cliente no ha comprado una chaqueta.
- Falso negativo: el modelo predice incorrectamente una clase negativa. El modelo predijo que un cliente no compró una chaqueta, pero sí lo hizo.

Precisión y recuperación
Las métricas de precisión y recuerdo te ayudan a saber cómo de bien capta la información tu modelo y qué deja fuera. Consulta más información sobre la precisión y la recuperación.
- La precisión es la fracción de las inferencias positivas que han sido correctas. De todas las inferencias de compra de un cliente, ¿qué fracción fueron compras reales?
- Recall es la fracción de filas con esta etiqueta que el modelo predijo correctamente. De todas las compras de clientes que se podrían haber identificado, ¿qué fracción se identificó?
En función de tu caso práctico, puede que tengas que optimizar la precisión o la recuperación.
Otras métricas de clasificación
- AUC PR: el área por debajo de la curva de precisión-recuperación (PR). Este valor va de cero a uno; cuanto mayor es el valor, más calidad tiene el modelo.
- AUC ROC: el área por debajo de la curva de característica operativa del receptor (ROC). Va de cero a uno; cuanto mayor es el valor, más calidad tiene el modelo.
- Precisión: la fracción de las inferencias de clasificación correctas que produjo el modelo.
- Pérdida logarítmica: la entropía cruzada entre las inferencias del modelo y los valores objetivo. Va de cero a infinito; cuanto menor es el valor, más calidad tiene el modelo.
- Puntuación F1: media armónica de la precisión y la recuperación. La métrica F1 resulta útil si buscas un equilibrio entre la precisión y la recuperación, así como si las clases están distribuidas de manera desigual.
Métricas de previsión y regresión
Una vez que se ha creado el modelo, Vertex AI proporciona una serie de métricas estándar que puedes consultar. No hay una respuesta perfecta sobre cómo evaluar tu modelo. Ten en cuenta las métricas de evaluación en el contexto de tu tipo de problema y lo que quieres conseguir con tu modelo. En la siguiente lista se ofrece una descripción general de algunas métricas que puede proporcionar Vertex AI.
Error absoluto medio (MAE)
El MAE es la diferencia absoluta media entre los valores objetivo y los predichos. Mide la magnitud media de los errores, es decir, la diferencia entre un valor objetivo y un valor predicho, en un conjunto de inferencias. Además, como usa valores absolutos, el error absoluto medio no tiene en cuenta la dirección de la relación ni indica si el rendimiento es inferior o superior al esperado. Al evaluar el MAE, cuanto menor sea el valor, mayor será la calidad del modelo (un 0 representa un predictor perfecto).
Raíz cuadrada del error cuadrático medio (RMSE)
El RMSE es la raíz cuadrada de la diferencia cuadrática media entre los valores objetivo y los predichos. El RMSE es más sensible a los valores atípicos que el MAE, por lo que, si te preocupan los errores grandes, el RMSE puede ser una métrica más útil para evaluar. Al igual que el error absoluto medio, cuanto menor sea el valor, mayor será la calidad del modelo (un 0 representa un predictor perfecto).
Error logarítmico cuadrático medio de la raíz (RMSLE)
El RMSLE es el RMSE a escala logarítmica. RMSLE es más sensible a los errores relativos que a los absolutos y se centra más en el rendimiento inferior al esperado que en el superior.
Cuantil observado (solo para previsiones)
Para un cuantil objetivo determinado, el cuantil observado muestra la fracción real de valores observados por debajo de los valores de inferencia del cuantil especificado. El cuantil observado muestra lo lejos o cerca que está el modelo del cuantil objetivo. Cuanto menor sea la diferencia entre los dos valores, mayor será la calidad del modelo.
Pérdida de pinball escalada (solo para previsiones)
Mide la calidad de un modelo en un cuantil objetivo determinado. Cuanto menor sea el número, mayor será la calidad del modelo. Puedes comparar la métrica de pérdida de pinball escalada en diferentes cuantiles para determinar la precisión relativa de tu modelo entre esos cuantiles.
Prueba tu modelo
Imagen
Vertex AI usa automáticamente el 10% de tus datos (o el porcentaje que hayas elegido si has definido la división de los datos) para probar el modelo. En la página "Evaluar" se indica el rendimiento del modelo con esos datos de prueba. Pero, por si quieres comprobar la confianza de tu modelo, hay varias formas de hacerlo. La forma más sencilla es subir algunas imágenes en la página "Implementar y probar" y consultar las etiquetas que elige el modelo para tus ejemplos. Esperamos que se ajuste a tus expectativas. Prueba con algunos ejemplos de cada tipo de imagen que esperes recibir.
Si prefieres usar tu modelo en tus propias pruebas automatizadas, en la página "Implementar y probar" también se explica cómo hacer llamadas al modelo de forma programática.
Tabular
La evaluación de las métricas de tu modelo es la forma principal de determinar si está listo para implementarse, pero también puedes probarlo con datos nuevos. Sube datos nuevos para ver si las inferencias del modelo se ajustan a tus expectativas. En función de las métricas de evaluación o de las pruebas con datos nuevos, es posible que tengas que seguir mejorando el rendimiento de tu modelo.
Desplegar un modelo
Imagen
Cuando estés satisfecho con el rendimiento del modelo, será el momento de usarlo. Quizá se trate de un uso a escala de producción o de una solicitud de inferencia única. En función de tu caso práctico, puedes usar tu modelo de diferentes formas.
Inferencia por lotes
La inferencia por lotes es útil para hacer muchas solicitudes de inferencia a la vez. La inferencia por lotes es asíncrona, lo que significa que el modelo esperará hasta que procese todas las solicitudes de inferencia antes de devolver un archivo JSON Lines con valores de inferencia.
Inferencia online
Despliega tu modelo para que esté disponible para las solicitudes de inferencia mediante una API REST. La inferencia online es síncrona (en tiempo real), lo que significa que devolverá rápidamente un resultado de inferencia, pero solo acepta una solicitud de inferencia por llamada a la API. La inferencia online es útil si tu modelo forma parte de una aplicación y algunas partes de tu sistema dependen de una inferencia rápida.
Tabular
Cuando estés satisfecho con el rendimiento del modelo, será el momento de usarlo. Quizá se trate de un uso a escala de producción o de una solicitud de inferencia única. En función de tu caso práctico, puedes usar tu modelo de diferentes formas.
Inferencia por lotes
La inferencia por lotes es útil para hacer muchas solicitudes de inferencia a la vez. La inferencia por lotes es asíncrona, lo que significa que el modelo esperará hasta que procese todas las solicitudes de inferencia antes de devolver un archivo CSV o una tabla de BigQuery con los valores de inferencia.
Inferencia online
Despliega tu modelo para que esté disponible para las solicitudes de inferencia mediante una API REST. La inferencia online es síncrona (en tiempo real), lo que significa que devolverá una inferencia rápidamente, pero solo acepta una solicitud de inferencia por llamada a la API. La inferencia online es útil si tu modelo forma parte de una aplicación y algunas partes de tu sistema dependen de que la inferencia se realice rápidamente.
Limpieza
Para evitar cargos no deseados, anula el despliegue de tu modelo cuando no lo estés usando.
Cuando termines de usar el modelo, elimina los recursos que hayas creado para evitar que se te cobren cargos innecesarios en tu cuenta.
- Datos de imagen de tipo "Hello": eliminar los recursos utilizados del proyecto
- Datos tabulares de tipo "Hello": eliminar los recursos utilizados del proyecto