Explorer et visualiser des données dans BigQuery depuis JupyterLab
Cette page présente des exemples d'exploration et de visualisation des données stockées dans BigQuery depuis l'interface JupyterLab de votre instance de notebooks gérés Vertex AI Workbench.
Ouvrir JupyterLab
Dans la console Google Cloud , accédez à la page Notebooks gérés.
À côté du nom de votre instance de notebooks gérés, cliquez sur Ouvrir JupyterLab.
Votre instance de notebooks gérés ouvre alors JupyterLab.
Lire des données de BigQuery
Dans les deux sections suivantes, vous allez lire les données de BigQuery que vous utiliserez pour les visualiser ultérieurement. Ces étapes sont identiques à celles de la section Interroger des données dans BigQuery depuis JupyterLab. Si vous les avez déjà terminées, vous pouvez passer directement à la section Obtenir un résumé des données dans une table BigQuery
Interroger des données à l'aide de la commande magique %%bigquery
Dans cette section, vous allez écrire SQL directement dans les cellules de notebook et lire des données de BigQuery dans le notebook Python.
Les commandes magiques basées sur un caractère unique ou double (% ou %%) vous permettent d'utiliser une syntaxe minimale pour interagir avec BigQuery dans le notebook. La bibliothèque cliente BigQuery pour Python est automatiquement installée dans une instance de notebooks gérés. En arrière-plan, la commande magique %%bigquery utilise la bibliothèque cliente BigQuery pour Python pour exécuter la requête concernée, convertir les résultats en objet DataFrame pandas, les enregistrer éventuellement dans une variable, puis afficher les résultats.
Remarque : Depuis la version 1.26.0 du package Python google-cloud-bigquery, l'API BigQuery Storage est utilisée par défaut pour télécharger les résultats des commandes magiques %%bigquery.
Pour ouvrir un fichier notebook, sélectionnez Fichier > Nouveau > Notebook.
Dans la boîte de dialogue Sélectionner le noyau, sélectionnez Python (Local), puis cliquez sur Sélectionner.
Votre nouveau fichier IPYNB s'ouvre.
Pour obtenir le nombre de régions par pays dans l'ensemble de données
international_top_terms, saisissez l'instruction suivante :%%bigquery SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
Cliquez sur Exécuter la cellule.
Le résultat ressemble à ce qui suit :
Query complete after 0.07s: 100%|██████████| 4/4 [00:00<00:00, 1440.60query/s] Downloading: 100%|██████████| 41/41 [00:02<00:00, 20.21rows/s] country_code country_name num_regions 0 TR Turkey 81 1 TH Thailand 77 2 VN Vietnam 63 3 JP Japan 47 4 RO Romania 42 5 NG Nigeria 37 6 IN India 36 7 ID Indonesia 34 8 CO Colombia 33 9 MX Mexico 32 10 BR Brazil 27 11 EG Egypt 27 12 UA Ukraine 27 13 CH Switzerland 26 14 AR Argentina 24 15 FR France 22 16 SE Sweden 21 17 HU Hungary 20 18 IT Italy 20 19 PT Portugal 20 20 NO Norway 19 21 FI Finland 18 22 NZ New Zealand 17 23 PH Philippines 17 ...
Dans la cellule suivante (sous la sortie de la cellule précédente), saisissez la commande suivante pour exécuter la même requête en enregistrant cette fois les résultats dans un nouveau DataFrame pandas nommé
regions_by_country. Vous devez spécifier ce nom à l'aide d'un argument avec la commande magique%%bigquery.%%bigquery regions_by_country SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
Remarque : Pour en savoir plus sur les arguments disponibles pour la commande
%%bigquery, consultez la documentation sur les commandes magiques de la bibliothèque cliente.Cliquez sur Exécuter la cellule.
Dans la cellule suivante, saisissez la commande ci-dessous pour examiner les premières lignes des résultats de la requête que vous venez de lire :
regions_by_country.head()Cliquez sur Exécuter la cellule.
Le DataFrame pandas
regions_by_countryest prêt à être représenté.
Interroger les données à l'aide de la bibliothèque cliente BigQuery directement
<
Obtenir un résumé des données dans une table BigQuery
Dans cette section, vous utilisez un raccourci de notebook pour obtenir des statistiques récapitulatives et des visualisations pour tous les champs d'une table BigQuery. Cela peut vous permettre de profiler vos données rapidement avant de les explorer plus en détail.
La bibliothèque cliente BigQuery propose une commande magique, %bigquery_stats, que vous pouvez appeler avec un nom de table spécifique pour obtenir un aperçu de la table et des statistiques détaillées sur chacune des colonnes de la table.
Dans la cellule suivante, saisissez le code suivant pour exécuter cette analyse dans la table
top_termsdes États-Unis :%bigquery_stats bigquery-public-data.google_trends.top_termsCliquez sur Exécuter la cellule.
Pendant un certain temps, une image apparaît avec différentes statistiques sur chacune des sept variables de la table
top_terms. L'image suivante montre une partie d'un exemple de résultat :
Visualiser les données BigQuery
Dans cette section, vous allez utiliser des fonctionnalités de traçage pour visualiser les résultats des requêtes que vous avez précédemment exécutées dans votre notebook Jupyter.
Dans la cellule suivante, saisissez le code ci-dessous afin d'utiliser la méthode
DataFrame.plot()pandas pour créer un graphique à barres qui représente les résultats de la requête qui renvoie le nombre de régions par pays.regions_by_country.plot(kind="bar", x="country_name", y="num_regions", figsize=(15, 10))Cliquez sur Exécuter la cellule.
La réponse est semblable à ce qui suit :

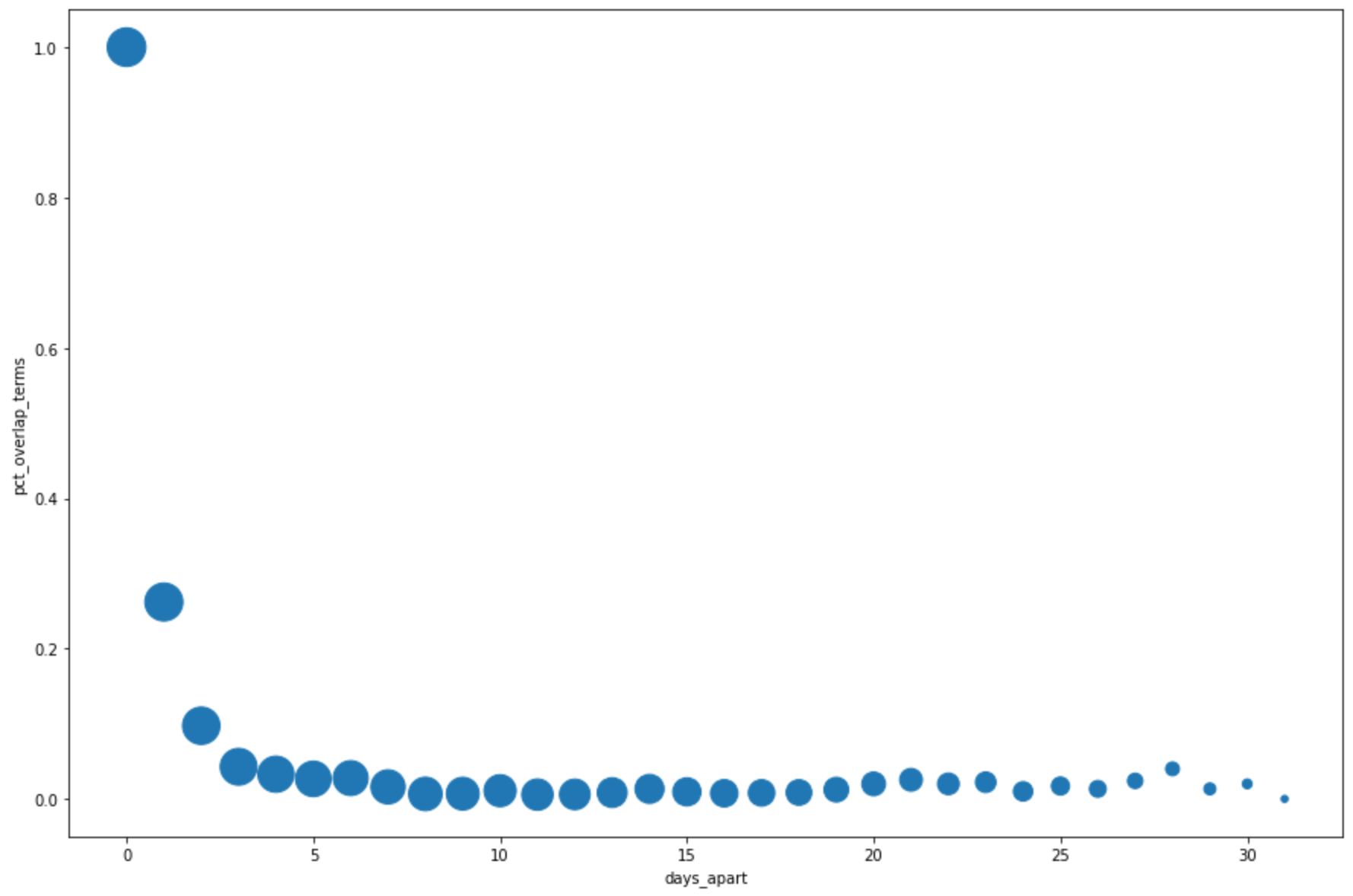
Dans la cellule suivante, saisissez le code ci-dessous afin d'utiliser la méthode
DataFrame.plot()pandas pour créer un nuage de points qui permet de visualiser les résultats de la requête en pourcentage de chevauchement dans les principaux termes de recherche par jours d'intervalle :pct_overlap_terms_by_days_apart.plot( kind="scatter", x="days_apart", y="pct_overlap_terms", s=len(pct_overlap_terms_by_days_apart["num_date_pairs"]) * 20, figsize=(15, 10) )Cliquez sur Exécuter la cellule.
La réponse est semblable à ce qui suit : La taille de chaque point reflète le nombre de paires de dates par intervalle de plusieurs jours dans les données. Par exemple, il y a davantage de paires à un jour d'intervalle qu'à plus de 30 jours d'intervalle, car les principaux termes de recherche sont affichés quotidiennement sur une période d'environ un mois.
Pour en savoir plus sur la visualisation des données, consultez la documentation de Pandas.