Menjelajahi dan memvisualisasikan data di BigQuery dari dalam JupyterLab
Halaman ini menunjukkan beberapa contoh cara menjelajahi dan memvisualisasikan data yang disimpan di BigQuery dari dalam antarmuka JupyterLab instance Vertex AI Workbench Anda.
Sebelum memulai
Jika belum melakukannya, buat instance Vertex AI Workbench.
Peran yang diperlukan
Untuk memastikan akun layanan instance Anda memiliki izin yang diperlukan untuk mengkueri data di BigQuery, minta administrator Anda untuk memberikan peran IAM Service Usage Consumer kepada akun layanan instance Anda (roles/serviceusage.serviceUsageConsumer) di project.
Administrator Anda mungkin juga dapat memberikan izin yang diperlukan kepada akun layanan instance Anda melalui peran khusus atau peran yang telah ditetapkan.
Buka JupyterLab
Di konsol Google Cloud , buka halaman Instances.
Di samping nama instance Vertex AI Workbench, klik Buka JupyterLab.
Instance Vertex AI Workbench akan membuka JupyterLab.
Membaca data dari BigQuery
Di dua bagian berikutnya, Anda akan membaca data dari BigQuery yang akan digunakan untuk divisualisasikan nanti. Langkah-langkah ini identik dengan langkah di Data kueri di BigQuery dari dalam JupyterLab, jadi jika sudah menyelesaikannya, Anda dapat langsung ke Dapatkan ringkasan data dalam tabel BigQuery.
Membuat kueri data menggunakan perintah magic %%bigquery
Di bagian ini, Anda akan menulis SQL langsung di sel notebook dan membaca data dari BigQuery ke dalam notebook Python.
Perintah magic yang menggunakan karakter persentase tunggal atau ganda (% atau %%) memungkinkan Anda menggunakan sintaksis minimal untuk berinteraksi dengan BigQuery dalam notebook. Library klien BigQuery untuk Python otomatis diinstal dalam instance Vertex AI Workbench. Di balik layar, perintah magic %%bigquery menggunakan library klien BigQuery agar Python dapat menjalankan kueri yang diberikan, mengonversi hasilnya menjadi DataFrame pandas, menyimpan hasil ke variabel secara opsional, dan kemudian menampilkan hasil tersebut.
Catatan: Mulai versi 1.26.0 paket Python google-cloud-bigquery, BigQuery Storage API digunakan secara default untuk mendownload hasil dari perintah magic %%bigquery.
Untuk membuka file notebook, pilih File > New > Notebook.
Dalam dialog Select Kernel, pilih Python 3, lalu klik Select.
File IPYNB baru Anda akan terbuka.
Untuk mendapatkan jumlah region berdasarkan negara dalam set data
international_top_terms, masukkan pernyataan berikut:%%bigquery SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
Klik Run cell.
Outputnya mirip dengan hal berikut ini:
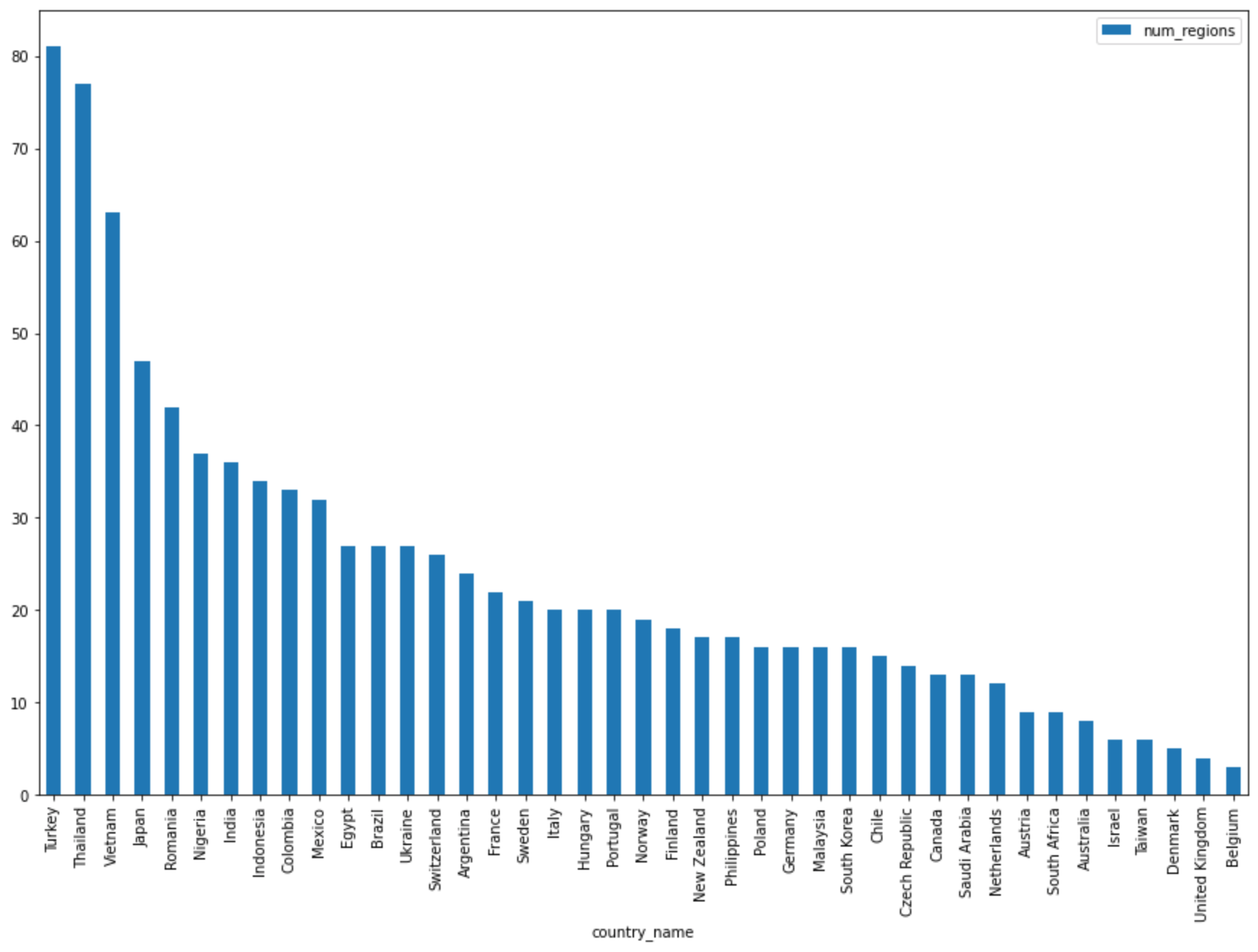
Query complete after 0.07s: 100%|██████████| 4/4 [00:00<00:00, 1440.60query/s] Downloading: 100%|██████████| 41/41 [00:02<00:00, 20.21rows/s] country_code country_name num_regions 0 TR Turkey 81 1 TH Thailand 77 2 VN Vietnam 63 3 JP Japan 47 4 RO Romania 42 5 NG Nigeria 37 6 IN India 36 7 ID Indonesia 34 8 CO Colombia 33 9 MX Mexico 32 10 BR Brazil 27 11 EG Egypt 27 12 UA Ukraine 27 13 CH Switzerland 26 14 AR Argentina 24 15 FR France 22 16 SE Sweden 21 17 HU Hungary 20 18 IT Italy 20 19 PT Portugal 20 20 NO Norway 19 21 FI Finland 18 22 NZ New Zealand 17 23 PH Philippines 17 ...
Pada sel berikutnya (di bawah output dari sel sebelumnya), masukkan perintah berikut untuk menjalankan kueri yang sama, tetapi kali ini simpan hasilnya ke DataFrame pandas baru yang bernama
regions_by_country. Anda memberikan nama tersebut menggunakan argumen dengan perintah magic%%bigquery.%%bigquery regions_by_country SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
Catatan: Untuk informasi selengkapnya tentang argumen yang tersedia untuk perintah
%%bigquery, lihat dokumentasi keajaiban library klien.Klik Run cell.
Di sel berikutnya, masukkan perintah berikut untuk melihat beberapa baris pertama hasil kueri yang baru saja Anda baca:
regions_by_country.head()Klik Run cell.
DataFrame
regions_by_countrypandas siap dipetakan.
Membuat kueri data dengan langsung menggunakan library klien BigQuery
Di bagian ini, Anda akan langsung menggunakan library klien BigQuery untuk Python untuk membaca data ke notebook Python.
Library klien memberi Anda kontrol lebih besar atas kueri dan memungkinkan Anda menggunakan konfigurasi yang lebih kompleks untuk kueri dan tugas. Integrasi library dengan pandas memungkinkan Anda menggabungkan kecanggihan SQL deklaratif dengan kode imperatif (Python) untuk membantu Anda menganalisis, memvisualisasikan, dan mengubah data.
Catatan: Anda dapat menggunakan sejumlah library analisis data, data wrangling, dan visualisasi Python, seperti numpy, pandas, matplotlib, dan banyak lagi. Beberapa library ini dibangun di atas objek DataFrame.
Di sel berikutnya, masukkan kode Python berikut untuk mengimpor library klien BigQuery untuk Python dan melakukan inisialisasi klien:
from google.cloud import bigquery client = bigquery.Client()Klien BigQuery digunakan untuk mengirim dan menerima pesan dari BigQuery API.
Klik Run cell.
Di sel berikutnya, masukkan kode berikut untuk mengambil persentase istilah teratas harian di
top_termsAS yang tumpang-tindih dengan istilah teratas dari beberapa hari sebelumnya. Intinya adalah melihat istilah teratas setiap hari dan mencari tahu berapa persen yang tumpang tindih dengan istilah teratas dari hari sebelumnya, 2 hari sebelumnya, 3 hari sebelumnya, dan seterusnya (untuk semua pasangan tanggal selama rentang waktu sekitar satu bulan).sql = """ WITH TopTermsByDate AS ( SELECT DISTINCT refresh_date AS date, term FROM `bigquery-public-data.google_trends.top_terms` ), DistinctDates AS ( SELECT DISTINCT date FROM TopTermsByDate ) SELECT DATE_DIFF(Dates2.date, Date1Terms.date, DAY) AS days_apart, COUNT(DISTINCT (Dates2.date || Date1Terms.date)) AS num_date_pairs, COUNT(Date1Terms.term) AS num_date1_terms, SUM(IF(Date2Terms.term IS NOT NULL, 1, 0)) AS overlap_terms, SAFE_DIVIDE( SUM(IF(Date2Terms.term IS NOT NULL, 1, 0)), COUNT(Date1Terms.term) ) AS pct_overlap_terms FROM TopTermsByDate AS Date1Terms CROSS JOIN DistinctDates AS Dates2 LEFT JOIN TopTermsByDate AS Date2Terms ON Dates2.date = Date2Terms.date AND Date1Terms.term = Date2Terms.term WHERE Date1Terms.date <= Dates2.date GROUP BY days_apart ORDER BY days_apart; """ pct_overlap_terms_by_days_apart = client.query(sql).to_dataframe() pct_overlap_terms_by_days_apart.head()
SQL yang digunakan digabungkan dalam string Python, lalu diteruskan ke metode
query()untuk menjalankan kueri. Metodeto_dataframemenunggu kueri selesai dan mendownload hasilnya ke DataFrame pandas menggunakan BigQuery Storage API.Klik Run cell.
Beberapa baris pertama hasil kueri muncul di bawah sel kode.
days_apart num_date_pairs num_date1_terms overlap_terms pct_overlap_terms 0 0 32 800 800 1.000000 1 1 31 775 203 0.261935 2 2 30 750 73 0.097333 3 3 29 725 31 0.042759 4 4 28 700 23 0.032857
Untuk mengetahui informasi lebih lanjut tentang cara menggunakan library klien BigQuery, lihat panduan memulai Menggunakan library klien.
Mendapatkan ringkasan data dalam tabel BigQuery
Di bagian ini, Anda akan menggunakan pintasan notebook guna mendapatkan ringkasan statistik dan visualisasi untuk semua kolom tabel BigQuery. Ini bisa menjadi cara cepat untuk membuat profil data Anda sebelum mempelajarinya lebih lanjut.
Library klien BigQuery menyediakan perintah magic,
%bigquery_stats, yang dapat Anda panggil dengan nama tabel tertentu untuk memberikan
ringkasan tabel dan statistik mendetail dari setiap kolom
tabel.
Di sel berikutnya, masukkan kode berikut untuk menjalankan analisis tersebut di tabel
top_termsAS:%bigquery_stats bigquery-public-data.google_trends.top_termsKlik Run cell.
Setelah berjalan selama beberapa waktu, gambar akan muncul dengan berbagai statistik untuk masing-masing dari 7 variabel dalam tabel
top_terms. Gambar berikut menunjukkan bagian dari beberapa contoh output: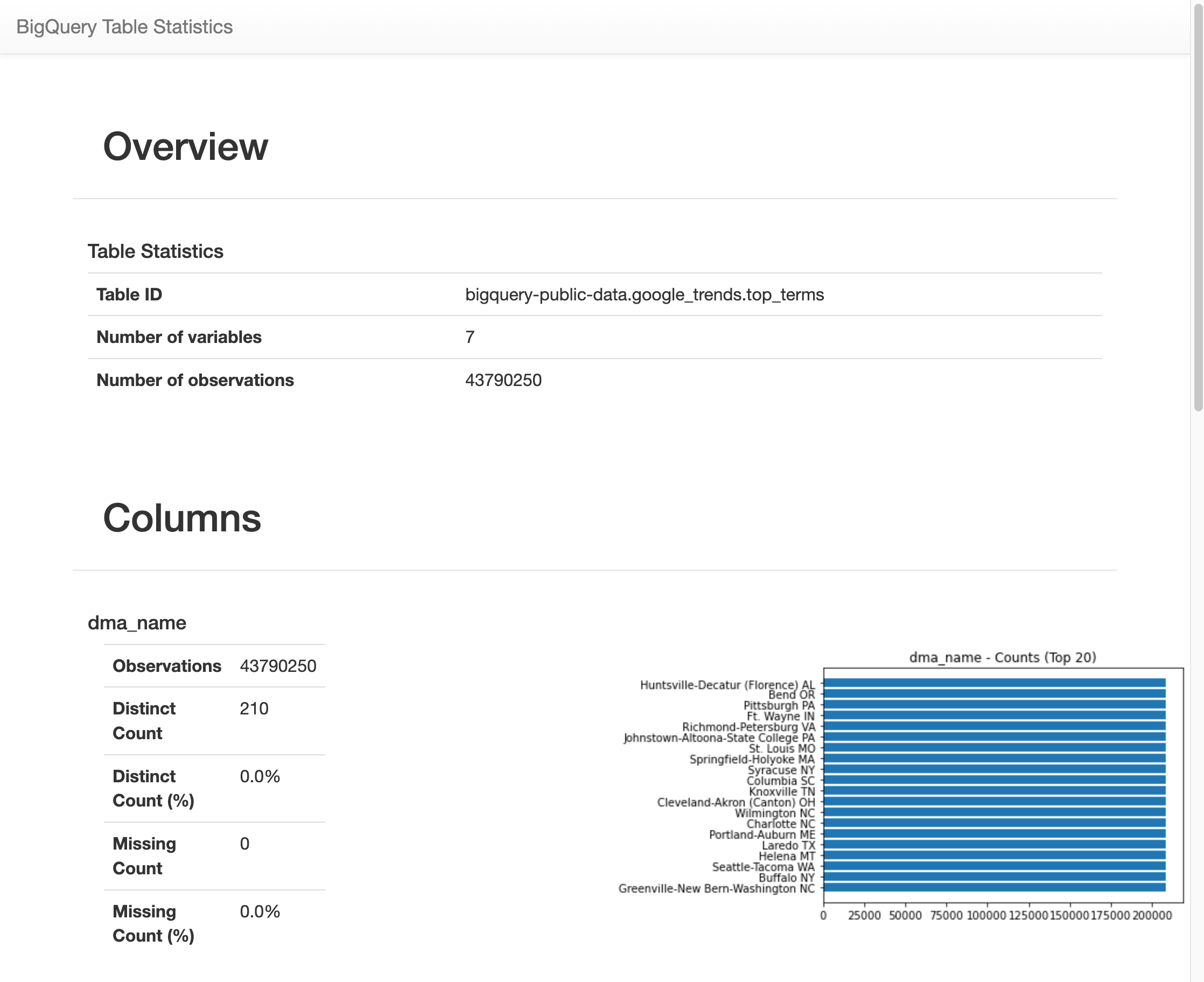
Memvisualisasikan data BigQuery
Di bagian ini, Anda akan menggunakan kemampuan plot untuk memvisualisasikan hasil dari kueri yang sebelumnya Anda jalankan di notebook Jupyter.
Di sel berikutnya, masukkan kode berikut untuk menggunakan metode
DataFrame.plot()pandas untuk membuat diagram batang yang memvisualisasikan hasil kueri yang menampilkan jumlah region berdasarkan negara:regions_by_country.plot(kind="bar", x="country_name", y="num_regions", figsize=(15, 10))Klik Run cell.
Outputnya mirip dengan yang berikut ini:
Di sel berikutnya, masukkan kode berikut untuk menggunakan metode
DataFrame.plot()pandas guna membuat diagram sebar yang memvisualisasikan hasil dari kueri untuk persentase tumpang tindih dengan istilah penelusuran teratas dari beberapa hari sebelumnya:pct_overlap_terms_by_days_apart.plot( kind="scatter", x="days_apart", y="pct_overlap_terms", s=len(pct_overlap_terms_by_days_apart["num_date_pairs"]) * 20, figsize=(15, 10) )Klik Run cell.
Outputnya serupa dengan yang berikut ini: Ukuran setiap titik mencerminkan jumlah pasangan tanggal yang berjarak beberapa hari dalam data. Misalnya, ada lebih banyak pasangan yang berjarak 1 hari daripada yang berjarak 30 hari karena istilah penelusuran teratas muncul setiap hari selama sekitar satu bulan.

Untuk mengetahui informasi selengkapnya tentang visualisasi data, lihat dokumentasi pandas.