Daten in BigQuery mit JupyterLab untersuchen und visualisieren
Auf dieser Seite finden Sie einige Beispiele zum Untersuchen und Visualisieren von in BigQuery gespeicherten Daten über die JupyterLab-Oberfläche der Vertex AI Workbench-Instanz.
Vorbereitung
Falls noch nicht geschehen, erstellen Sie eine Vertex AI Workbench-Instanz.
Erforderliche Rollen
Damit das Dienstkonto Ihrer Instanz die erforderlichen Berechtigungen zum Abfragen von Daten in BigQuery hat, bitten Sie Ihren Administrator, dem Dienstkonto Ihrer Instanz die IAM-Rolle „Service Usage-Nutzer“ (roles/serviceusage.serviceUsageConsumer) für das Projekt zu gewähren.
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Ihr Administrator kann dem Dienstkonto Ihrer Instanz möglicherweise auch die erforderlichen Berechtigungen über benutzerdefinierte Rollen oder andere vordefinierte Rollen erteilen.
JupyterLab öffnen
Rufen Sie in der Google Cloud Console die Seite Instanzen auf.
Klicken Sie neben dem Namen der Vertex AI Workbench-Instanz auf JupyterLab öffnen.
Ihre Vertex AI Workbench-Instanz öffnet JupyterLab.
Daten aus BigQuery lesen
In den nächsten beiden Abschnitten lesen Sie Daten aus BigQuery, die Sie später zur Visualisierung verwenden werden. Diese Schritte sind identisch mit denen in Daten in BigQuery in JupyterLab abfragen. Wenn Sie sie also bereits abgeschlossen haben, können Sie mit dem nächsten Schritt fortfahren: Zusammenfassung der Daten in einer BigQuery-Tabelle abrufen.
Daten mit dem magischen %%bigquery-Befehl abfragen
In diesem Abschnitt schreiben Sie SQL direkt in Notebook-Zellen und schreiben Daten aus BigQuery in das Python-Notebook.
Mit magischen Befehlen, die ein einzelnes oder doppeltes Prozentzeichen (% oder %%) verwenden, nutzen Sie eine minimale Syntax zur Interaktion mit BigQuery im Notebook. Die BigQuery-Clientbibliothek für Python wird in einer Vertex AI Workbench-Instanz automatisch installiert. Im Hintergrund verwendet der magische Befehl %%bigquery die BigQuery-Clientbibliothek für Python, um die angegebene Abfrage auszuführen. Die Ergebnisse werden in ein Pandas-DataFrame umgewandelt und optional in einer Variablen gespeichert. Anschließend werden die Ergebnisse angezeigt.
Hinweis: Ab Version 1.26.0 des Python-Pakets google-cloud-bigquery wird die BigQuery Storage API standardmäßig verwendet, um Ergebnisse aus den magischen %%bigquery-Befehlen herunterzuladen.
Wählen Sie zum Öffnen einer Notebook-Datei Datei > Neu > Notebook aus.
Wählen Sie im Dialogfeld Kernel auswählen die Option Python 3 aus und klicken Sie dann auf Auswählen.
Ihre neue IPYNB-Datei wird geöffnet.
Geben Sie folgende Anweisung ein, um die Anzahl der Regionen nach Land im Dataset
international_top_termsabzurufen:%%bigquery SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
Klicken Sie auf Zelle ausführen.
Die Ausgabe sieht in etwa so aus:
Query complete after 0.07s: 100%|██████████| 4/4 [00:00<00:00, 1440.60query/s] Downloading: 100%|██████████| 41/41 [00:02<00:00, 20.21rows/s] country_code country_name num_regions 0 TR Turkey 81 1 TH Thailand 77 2 VN Vietnam 63 3 JP Japan 47 4 RO Romania 42 5 NG Nigeria 37 6 IN India 36 7 ID Indonesia 34 8 CO Colombia 33 9 MX Mexico 32 10 BR Brazil 27 11 EG Egypt 27 12 UA Ukraine 27 13 CH Switzerland 26 14 AR Argentina 24 15 FR France 22 16 SE Sweden 21 17 HU Hungary 20 18 IT Italy 20 19 PT Portugal 20 20 NO Norway 19 21 FI Finland 18 22 NZ New Zealand 17 23 PH Philippines 17 ...
Geben Sie in die nächste Zelle (unter der Ausgabe der vorherigen Zelle) den folgenden Befehl ein, um dieselbe Abfrage auszuführen. Dieses Mal speichern Sie die Ergebnisse jedoch in einem neuen Pandas-DataFrame namens
regions_by_country. Sie geben diesen Namen über ein Argument mit dem magischen Befehl%%bigqueryan.%%bigquery regions_by_country SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
Hinweis: Weitere Informationen zu verfügbaren Argumenten für den
%%bigquery-Befehl finden Sie in der Clientbibliothek-Dokumentation der magischen Befehle.Klicken Sie auf Zelle ausführen.
Geben Sie in die nächste Zelle folgenden Befehl ein, um die ersten Zeilen der Abfrageergebnisse aufzurufen, die Sie gerade eingelesen haben:
regions_by_country.head()Klicken Sie auf Zelle ausführen.
Der Pandas-DataFrame
regions_by_countrykann jetzt dargestellt werden.
Daten über die BigQuery-Clientbibliothek direkt abfragen
In diesem Abschnitt verwenden Sie die BigQuery-Clientbibliothek für Python direkt, um Daten in das Python-Notebook einzulesen.
Mit der Clientbibliothek haben Sie mehr Kontrolle über Ihre Abfragen und können komplexere Konfigurationen für Abfragen und Jobs nutzen. Durch die Einbindung der Bibliothek in Pandas können Sie deklarativen SQL-Dialekt mit imperativem Code (Python) kombinieren, um die Daten zu analysieren, zu visualisieren und zu transformieren.
Hinweis: Sie können verschiedene Python-Bibliotheken für Datenanalyse, Data Wrangling und Visualisierung verwenden, z. B. numpy, pandas, matplotlib viele weitere. Mehrerer dieser Bibliotheken basieren auf einem DataFrame-Objekt.
Geben Sie in die nächste Zelle folgenden Python-Code ein, um die BigQuery-Clientbibliothek für Python zu importieren und einen Client zu initialisieren:
from google.cloud import bigquery client = bigquery.Client()Der BigQuery-Client wird zum Senden und Empfangen von Nachrichten von der BigQuery API verwendet.
Klicken Sie auf Zelle ausführen.
Geben Sie in die nächste Zelle folgenden Code ein, um den Prozentsatz der täglichen Top-Suchbegriffe in den US-
top_termsabzurufen, die sich im Laufe der Zeit überschneiden; dabei wird deren Abstand nach Tagen berücksichtigt. Der Grundgedanke ist dabei, dass Sie sich die Top-Begriffe des jeweiligen Tages ansehen und herausfinden, welcher Prozentsatz dieser Begriffe mit den Top-Begriffen vom Vortag, von zwei Tagen zuvor, drei Tagen zuvor usw. überlappen. Es werden Paare von Datumsangaben über einen Zeitraum von einem Monat berücksichtigt.sql = """ WITH TopTermsByDate AS ( SELECT DISTINCT refresh_date AS date, term FROM `bigquery-public-data.google_trends.top_terms` ), DistinctDates AS ( SELECT DISTINCT date FROM TopTermsByDate ) SELECT DATE_DIFF(Dates2.date, Date1Terms.date, DAY) AS days_apart, COUNT(DISTINCT (Dates2.date || Date1Terms.date)) AS num_date_pairs, COUNT(Date1Terms.term) AS num_date1_terms, SUM(IF(Date2Terms.term IS NOT NULL, 1, 0)) AS overlap_terms, SAFE_DIVIDE( SUM(IF(Date2Terms.term IS NOT NULL, 1, 0)), COUNT(Date1Terms.term) ) AS pct_overlap_terms FROM TopTermsByDate AS Date1Terms CROSS JOIN DistinctDates AS Dates2 LEFT JOIN TopTermsByDate AS Date2Terms ON Dates2.date = Date2Terms.date AND Date1Terms.term = Date2Terms.term WHERE Date1Terms.date <= Dates2.date GROUP BY days_apart ORDER BY days_apart; """ pct_overlap_terms_by_days_apart = client.query(sql).to_dataframe() pct_overlap_terms_by_days_apart.head()
Das verwendete SQL-Objekt ist in einem Python-String gekapselt und wird dann zur Ausführung einer Abfrage an die
query()-Methode übergeben. Dieto_dataframe-Methode wartet, bis die Abfrage abgeschlossen ist, und lädt die Ergebnisse mit der BigQuery Storage API in einen Pandas-DataFrame.Klicken Sie auf Zelle ausführen.
Die ersten Zeilen der Abfrageergebnisse werden unterhalb der Codezelle angezeigt.
days_apart num_date_pairs num_date1_terms overlap_terms pct_overlap_terms 0 0 32 800 800 1.000000 1 1 31 775 203 0.261935 2 2 30 750 73 0.097333 3 3 29 725 31 0.042759 4 4 28 700 23 0.032857
Weitere Informationen zur Verwendung von BigQuery-Clientbibliotheken finden Sie in der Kurzanleitung Clientbibliotheken verwenden.
Zusammenfassung der Daten in einer BigQuery-Tabelle abrufen
In diesem Abschnitt verwenden Sie eine Notebook-Verknüpfung, um zusammenfassende Statistiken und Visualisierungen für alle Felder einer BigQuery-Tabelle abzurufen. So können Sie Ihre Daten schnell profilieren, bevor Sie sich weiter mit ihnen befassen.
Die BigQuery-Clientbibliothek stellt den magischen Befehl %bigquery_stats bereit, den Sie mit einem bestimmten Tabellennamen aufrufen können, um eine Übersicht über die Tabelle und detaillierte Statistiken für alle Spalten der Tabelle bereitzustellen.
Geben Sie in die nächste Zelle folgenden Code ein, um diese Analyse in der Tabelle
top_termsfür die USA auszuführen:%bigquery_stats bigquery-public-data.google_trends.top_termsKlicken Sie auf Zelle ausführen.
Nach einiger Zeit wird ein Bild mit verschiedenen Statistiken zu jeder der sieben Variablen in der Tabelle
top_termsangezeigt. Die folgende Abbildung zeigt einen Teil einer Beispielausgabe: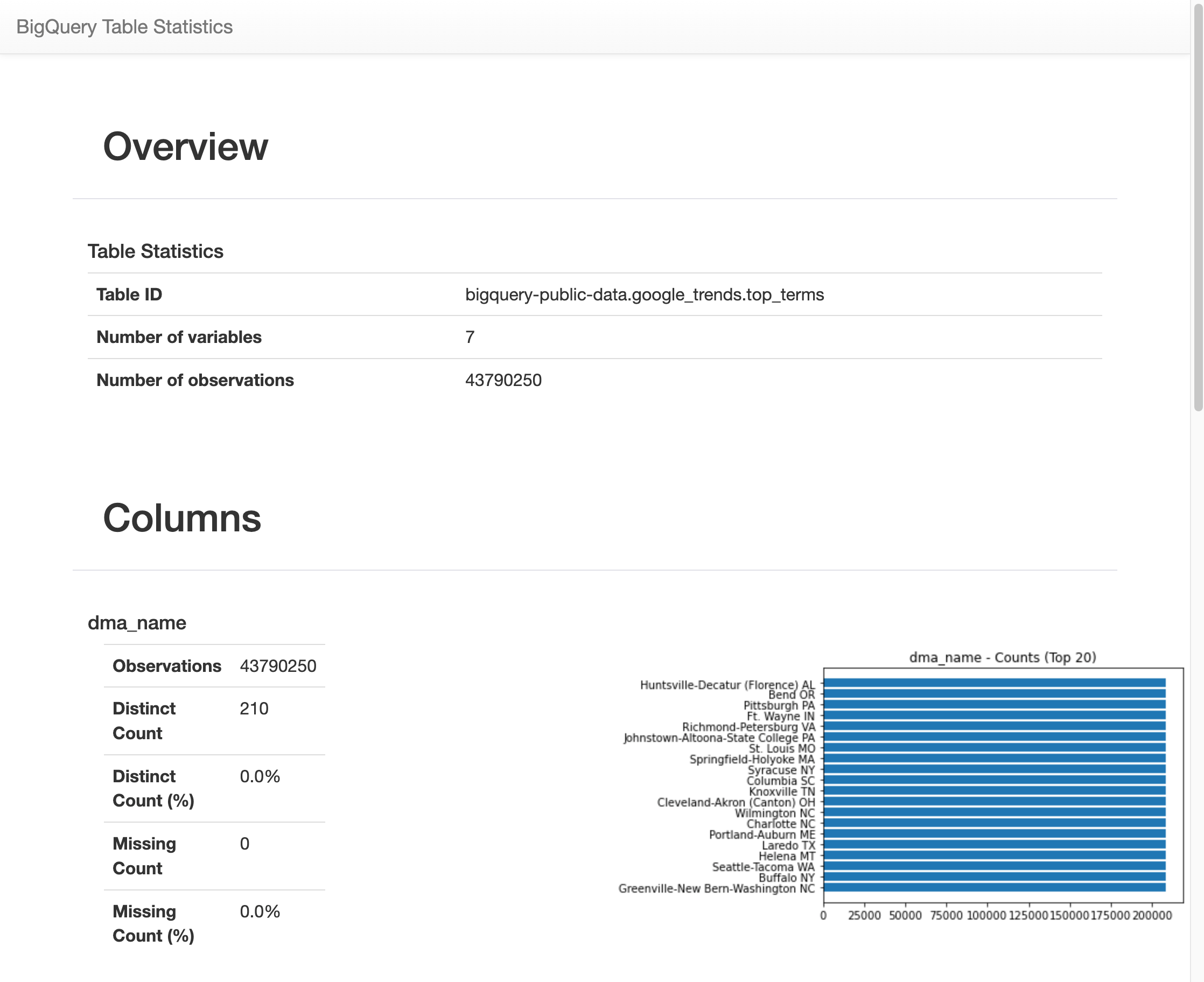
BigQuery-Daten visualisieren
In diesem Abschnitt verwenden Sie Darstellungsfunktionen, um die Ergebnisse der Abfragen zu visualisieren, die Sie zuvor in Ihrem Jupyter-Notebook ausgeführt haben.
Geben Sie in die nächste Zelle folgenden Code ein, um mit der Pandas-Methode
DataFrame.plot()ein Balkendiagramm zu erstellen, das die Ergebnisse der Abfrage visualisiert, die die Anzahl der Regionen nach Land zurückgibt:regions_by_country.plot(kind="bar", x="country_name", y="num_regions", figsize=(15, 10))Klicken Sie auf Zelle ausführen.
Das Diagramm sieht etwa so aus:
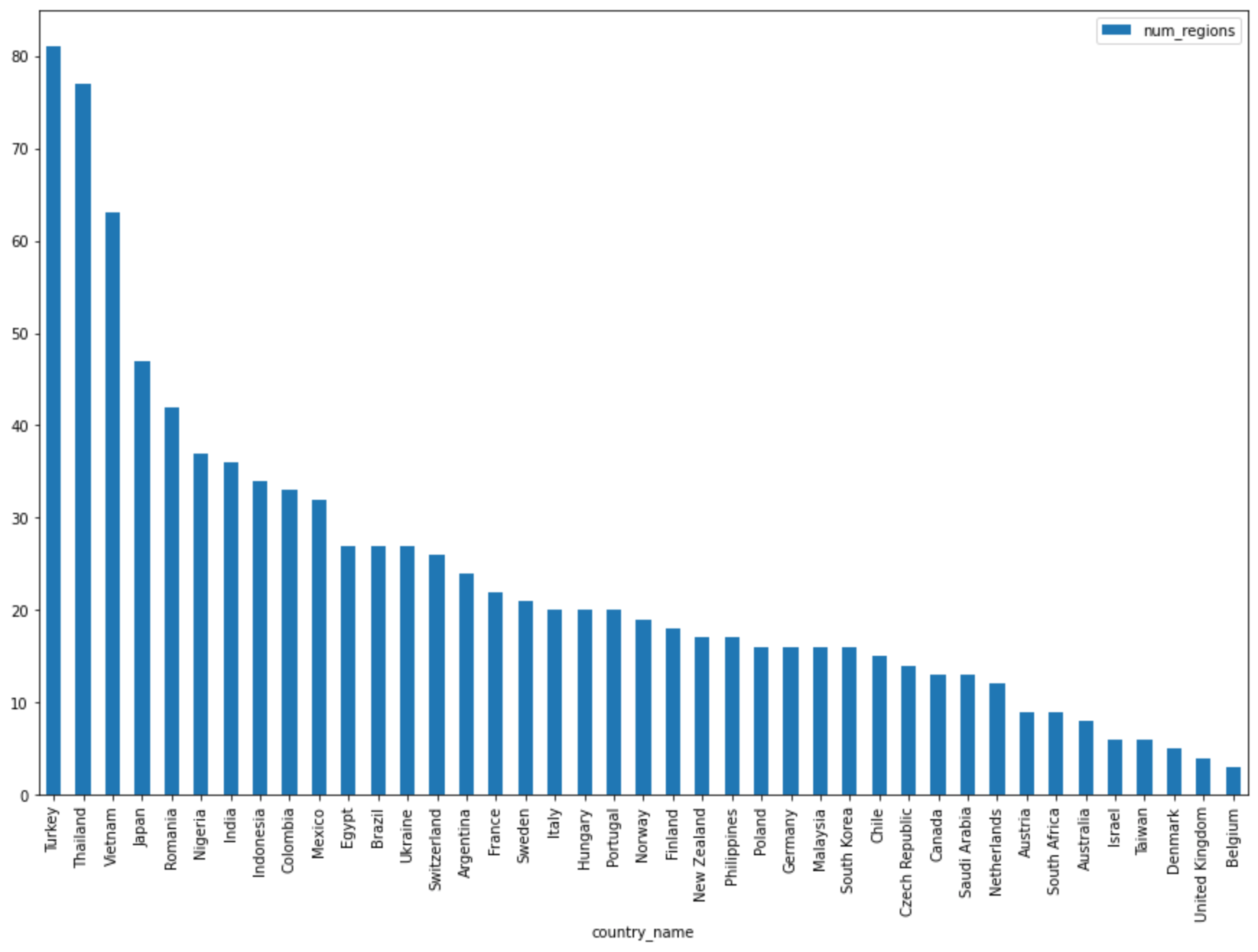
Geben Sie in die nächste Zelle folgenden Code ein, um mit der Pandas-Methode
DataFrame.plot()ein Streudiagramm zu erstellen, mit dem die Ergebnisse der Abfrage für den Prozentsatz der Überschneidung der wichtigsten Begriffe visualisiert werden, wobei der Abstand nach Tagen berücksichtigt wird:pct_overlap_terms_by_days_apart.plot( kind="scatter", x="days_apart", y="pct_overlap_terms", s=len(pct_overlap_terms_by_days_apart["num_date_pairs"]) * 20, figsize=(15, 10) )Klicken Sie auf Zelle ausführen.
Das Diagramm sieht etwa so aus: Die Größe jedes Punkts gibt die Anzahl der Datumspaare an, die um jeweils eine bestimmt Anzahl an Tage auseinander liegen. Es gibt beispielsweise mehr Paare, die 1 Tag als 30 Tage auseinander liegen, da die häufigsten Suchbegriffe täglich über etwa einen Monat angezeigt werden.
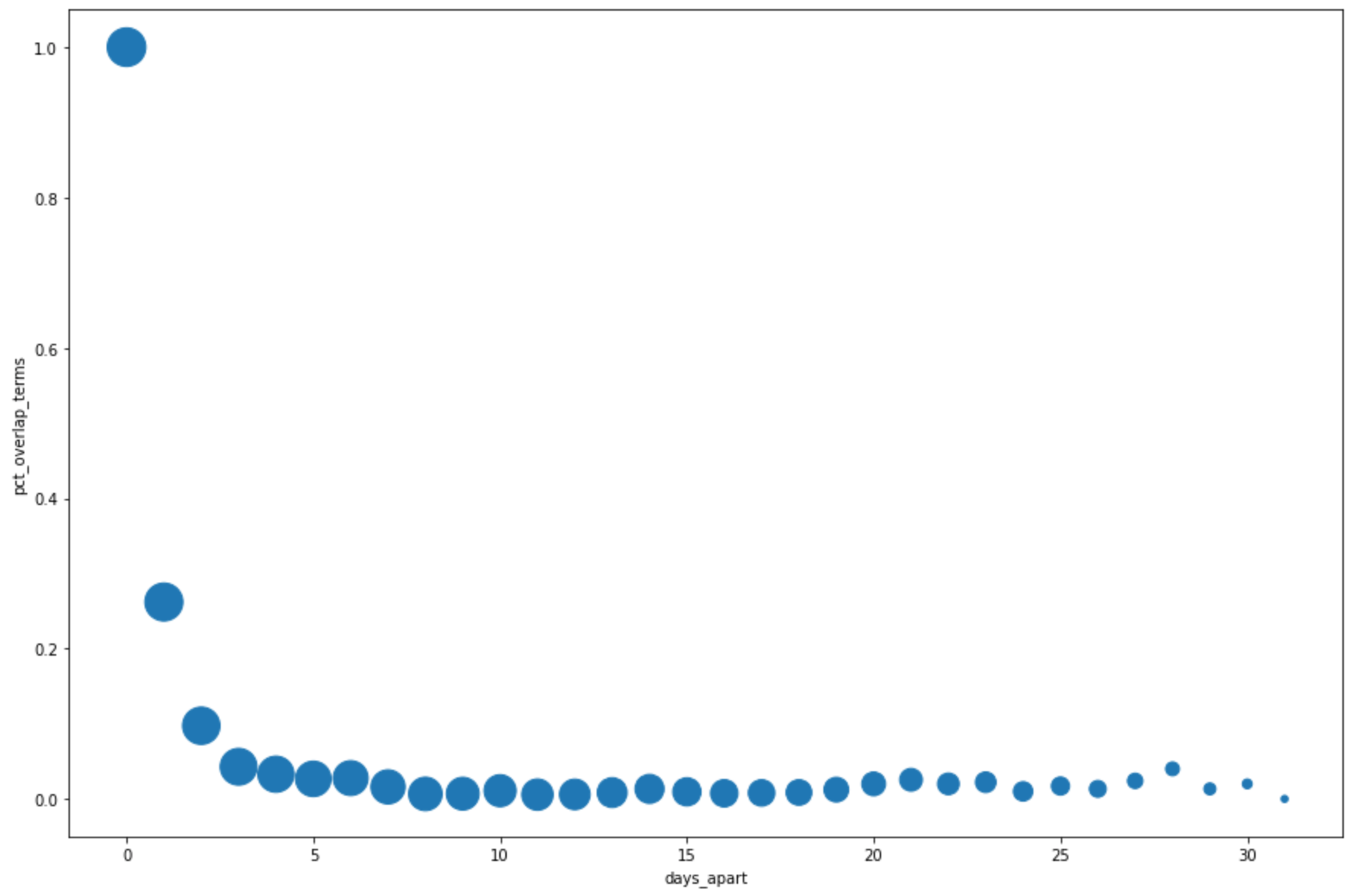
Weitere Informationen zur Datenvisualisierung finden Sie in der Pandas-Dokumentation.