Rasakan kecanggihan teknologi penelusuran vektor tercanggih dengan demo interaktif Penelusuran Vektor. Dengan memanfaatkan set data dunia nyata, demo ini memberikan contoh realistis yang akan membantu Anda mempelajari cara kerja Vector Search, menjelajahi penelusuran semantik dan campuran, serta melihat cara kerja pemeringkatan ulang. Kirimkan deskripsi singkat tentang hewan, tumbuhan, merchandise e-commerce, atau item lainnya, dan biarkan Vector Search melakukan sisanya.
Cobalah!
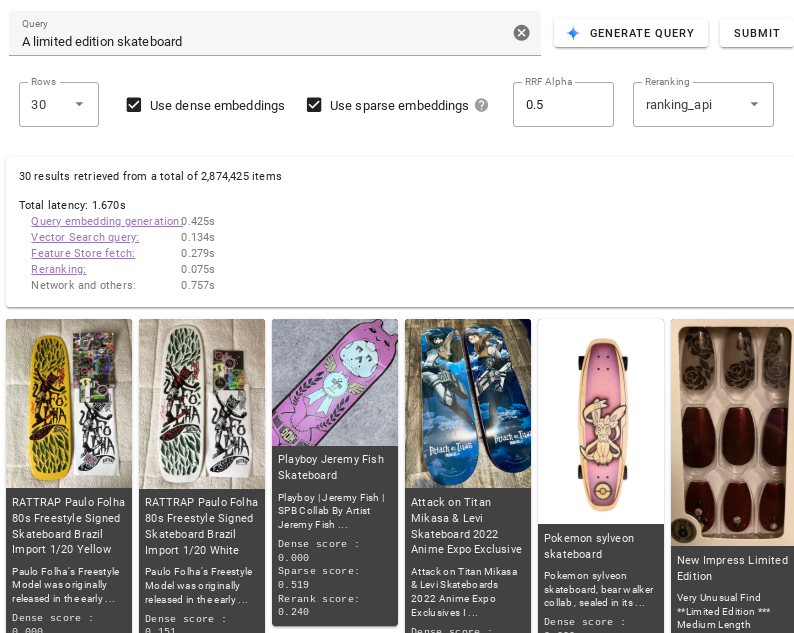
Bereksperimenlah dengan berbagai opsi dalam demo untuk mulai menggunakan Penelusuran Vektor dan memahami dasar-dasar teknologi penelusuran vektor.
Untuk menjalankan:
Di kolom teks Query, deskripsikan item yang ingin Anda kueri (misalnya,
vintage 1970s pinball machine). Atau, klik Generate Query untuk membuat deskripsi secara otomatis.Klik Kirim.
Untuk mempelajari lebih lanjut apa yang dapat Anda lakukan dalam demo, lihat Antarmuka Pengguna.
Antarmuka Pengguna
Bagian ini menjelaskan setelan di UI yang dapat Anda gunakan untuk mengontrol hasil yang ditampilkan oleh Vector Search dan cara hasil tersebut diberi peringkat.
Set data
Gunakan drop-down Dataset untuk memilih dataset yang akan digunakan Vector Search untuk menjalankan kueri Anda. Lihat Set data untuk mengetahui detail tentang masing-masing set data.
Kueri
Untuk kolom Kueri, tambahkan deskripsi atau satu atau beberapa kata kunci untuk menentukan item yang ingin Anda temukan dengan Vector Search. Atau, klik Buat Kueri untuk membuat deskripsi secara otomatis.

Mengubah
Beberapa opsi tersedia yang mengubah hasil yang ditampilkan Penelusuran Vektor:

Klik Baris dan pilih jumlah maksimum hasil penelusuran yang Anda inginkan agar Penelusuran Vektor ditampilkan.
Pilih Gunakan embedding padat jika Anda ingin Vector Search menampilkan hasil yang serupa secara semantik.
Pilih Gunakan embedding renggang jika Anda ingin Penelusuran Vektor menampilkan hasil berdasarkan sintaksis teks kueri Anda. Tidak semua set data yang tersedia mendukung model penyematan jarang.
Pilih Gunakan embedding padat dan Gunakan embedding renggang jika Anda ingin Vector Search menggunakan penelusuran campuran. Tidak semua set data mendukung model ini. Penelusuran hybrid menggabungkan elemen sematan padat dan jarang yang dapat meningkatkan kualitas hasil penelusuran. Untuk mempelajari lebih lanjut, buka Tentang penelusuran hybrid.
Di kolom Alfa RRF, masukkan nilai antara 0,0 dan 1,0 untuk menentukan efek peringkat RRF.
Untuk mengurutkan ulang hasil penelusuran, pilih ranking_api dari drop-down Pengurutan ulang atau pilih Tidak ada untuk menonaktifkan pengurutan ulang.
Metrik
Setelah kueri berjalan, Anda akan mendapatkan metrik latensi yang menguraikan waktu yang diperlukan untuk menyelesaikan berbagai tahap penelusuran.

Proses Kueri
Saat kueri diproses, hal berikut akan terjadi:
Pembuatan embedding kueri: Embedding dibuat untuk teks kueri yang ditentukan.
Kueri Vector Search: Kueri dijalankan dengan indeks Vector Search.
Pengambilan Vertex AI Feature Store: Fitur dibaca (misalnya, nama item, deskripsi, atau URL gambar) dari Vertex AI Feature Store menggunakan daftar ID item yang ditampilkan oleh Vector Search.
Pengurutan ulang: Item yang diambil diurutkan melalui API peringkat yang menggunakan teks kueri, nama item, dan deskripsi item untuk menghitung skor relevansi.
Embedding
Multimodal: Penelusuran semantik multimodal pada gambar item. Untuk mengetahui detailnya, buka Apa itu Penelusuran Multimodal: "LLM dengan visi" mengubah bisnis.
Teks (kemiripan semantik): Penelusuran semantik teks pada nama dan deskripsi item berdasarkan kemiripan semantik. Untuk mempelajari lebih lanjut, buka Vertex AI Embeddings untuk Teks: Cara mudah Grounding LLM.
Teks (jawab pertanyaan): Penelusuran semantik teks pada nama dan deskripsi item, dengan kualitas penelusuran yang ditingkatkan menurut jenis tugas QUESTION_ANSWERING. Cara ini cocok untuk aplikasi jenis Tanya Jawab. Untuk mengetahui informasi tentang embedding jenis tugas, buka Meningkatkan kasus penggunaan AI generatif Anda dengan embedding Vertex AI dan jenis tugas.
Renggang (Penelusuran Hybrid): Penelusuran kata kunci (berbasis token) pada nama dan deskripsi item, yang dibuat dengan algoritma TF-IDF. Untuk mengetahui informasi selengkapnya, buka Tentang penelusuran hybrid.
Set data
Demo interaktif ini mencakup beberapa set data yang dapat Anda jalankan kuerinya. Set data berbeda satu sama lain berdasarkan model embedding, dukungan untuk embedding jarang, dimensi embedding, dan jumlah item yang disimpan.
| Set data | Model Penyematan | Model Embedding Renggang | Dimensi Sematan | Jumlah Item |
|---|---|---|---|---|
| Embedding Multimodal + Sparse Mercari | Embedding multimodal | TF-IDF (nama dan deskripsi item) |
1408 | ~3 juta |
| Teks Mercari (kemiripan semantik) + Embedding sparse | text-embedding-005 (Jenis tugas: SEMANTIC_SIMILARITY) |
TF-IDF (nama dan deskripsi item) |
768 | ~3 juta |
| Teks Mercari (question answering) + Embedding jarang | text-embedding-005 (Jenis tugas: QUESTION_ANSWERING) |
TF-IDF (nama dan deskripsi item) |
768 | ~3 juta |
| GBIF Flowers Multimodal + Sparse embeddings | Embedding multimodal | TF-IDF (nama dan deskripsi item) |
1408 | ~3,3 juta |
| Embedding Multimodal GBIF Animals | Embedding multimodal | T/A | 1408 | ~7 juta |
Langkah berikutnya
Setelah memahami demo, Anda siap mempelajari lebih dalam cara menggunakan Penelusuran Vektor.
Panduan memulai: Gunakan set data contoh untuk membuat dan men-deploy indeks dalam waktu 30 menit atau kurang.
Sebelum memulai: Cari tahu apa yang harus dilakukan untuk menyiapkan embedding dan tentukan jenis endpoint untuk men-deploy indeks Anda.