CustomTrainingJob.
Lorsque vous créez un CustomTrainingJob, vous définissez un pipeline d'entraînement en arrière-plan. Vertex AI utilise le pipeline d'entraînement et le code de votre script d'entraînement Python pour entraîner et créer votre modèle. Pour en savoir plus, consultez la section Créer des pipelines d'entraînement.
Définir votre pipeline d'entraînement
Pour créer un pipeline d'entraînement, vous créez un objet CustomTrainingJob. Dans l'étape suivante, vous allez utiliser la commande run de CustomTrainingJob pour créer et entraîner votre modèle. Pour créer un CustomTrainingJob, vous transmettez les paramètres suivants à son constructeur :
display_name- variableJOB_NAMEque vous avez créée lorsque vous avez défini les arguments de commande pour le script d'entraînement Python.script_path- chemin d'accès au script d'entraînement Python que vous avez créé précédemment dans ce tutoriel.container_url- URI d'une image de conteneur Docker utilisée pour entraîner votre modèle.requirements- liste des dépendances de package Python du script.model_serving_container_image_uri- URI d'une image de conteneur Docker qui diffuse des prédictions pour votre modèle. Ce conteneur peut être prédéfini ou votre propre image personnalisée. Ce tutoriel utilise un conteneur prédéfini.
Exécutez le code suivant pour créer votre pipeline d'entraînement. La méthode CustomTrainingJob utilise le script d'entraînement Python dans le fichier task.py pour créer un CustomTrainingJob.
job = aiplatform.CustomTrainingJob(
display_name=JOB_NAME,
script_path="task.py",
container_uri="us-docker.pkg.dev/vertex-ai/training/tf-cpu.2-8:latest",
requirements=["google-cloud-bigquery>=2.20.0", "db-dtypes", "protobuf<3.20.0"],
model_serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest",
)
Créer et entraîner votre modèle
À l'étape précédente, vous avez créé un CustomTrainingJob nommé job. Pour créer et entraîner votre modèle, appelez la méthode run sur votre objet CustomTrainingJob et transmettez-lui les paramètres suivants :
dataset- ensemble de données tabulaire que vous avez créé précédemment dans ce tutoriel. Ce paramètre peut être un ensemble de données tabulaires, d'image, de vidéo ou de texte.model_display_name- nom pour votre modèle.bigquery_destination- chaîne spécifiant l'emplacement de votre ensemble de données BigQuery.args- arguments de ligne de commande transmis au script d'entraînement Python.
Pour commencer à entraîner vos données et à créer votre modèle, exécutez le code suivant dans votre notebook :
MODEL_DISPLAY_NAME = "penguins_model_unique"
# Start the training and create your model
model = job.run(
dataset=dataset,
model_display_name=MODEL_DISPLAY_NAME,
bigquery_destination=f"bq://{project_id}",
args=CMDARGS,
)
Avant de passer à l'étape suivante, assurez-vous que ce qui suit apparaît dans le résultat de la commande job.run pour vérifier que tout est prêt :
CustomTrainingJob run completed.
Une fois le job d'entraînement terminé, vous pouvez déployer votre modèle.
Déployer le modèle
Lorsque vous déployez votre modèle, vous créez également une ressource Endpoint utilisée pour effectuer des prédictions. Pour déployer votre modèle et créer un point de terminaison, exécutez le code suivant dans votre notebook :
DEPLOYED_NAME = "penguins_deployed_unique"
endpoint = model.deploy(deployed_model_display_name=DEPLOYED_NAME)
Attendez que votre modèle soit déployé avant de passer à l'étape suivante. Une fois votre modèle déployé, le résultat inclut le texte, Endpoint model deployed.
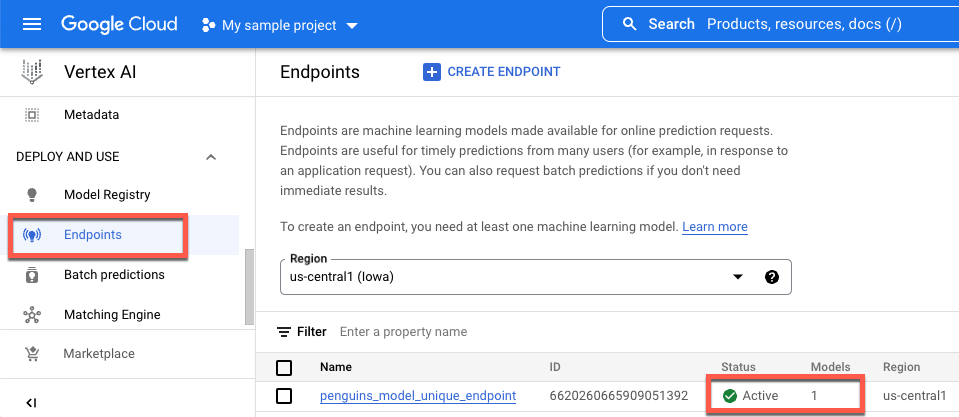
Pour afficher l'état de votre déploiement dans la console Google Cloud , procédez comme suit:
Dans la Google Cloud console, accédez à la page Points de terminaison.
Surveillez la valeur sous Modèles. La valeur est de
0après la création du point de terminaison et avant le déploiement du modèle. Une fois le modèle déployé, la valeur passe à1.L'illustration suivante montre un point de terminaison après sa création et avant le déploiement d'un modèle.
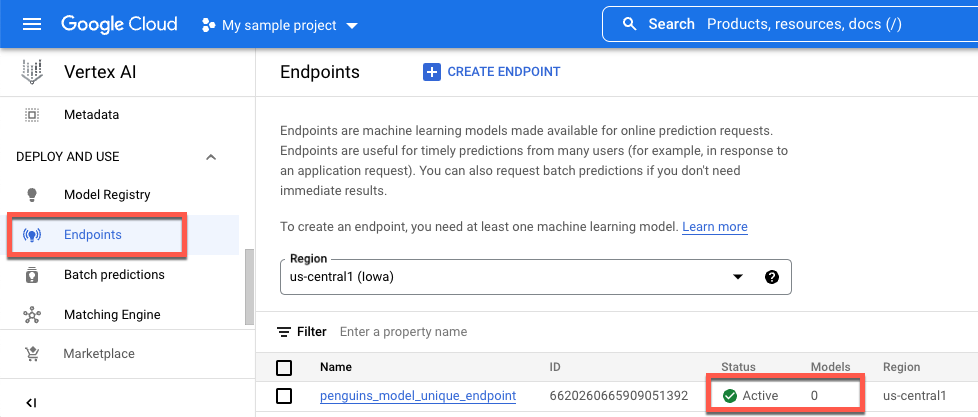
L'illustration suivante montre un point de terminaison après sa création et après le déploiement d'un modèle.