CustomTrainingJob を作成する準備が整いました。
CustomTrainingJob を作成する際には、バックグラウンドでトレーニング パイプラインを定義します。Vertex AI は、トレーニング パイプラインと Python トレーニング スクリプトのコードを使用して、モデルのトレーニングと作成を行います。詳細については、トレーニング パイプラインの作成をご覧ください。
トレーニング パイプラインを定義する
トレーニング パイプラインを作成するために、CustomTrainingJob オブジェクトを作成します。次のステップでは、CustomTrainingJob の run コマンドを使用してモデルを作成し、トレーニングします。CustomTrainingJob を作成するには、そのコンストラクタに次のパラメータを渡します。
display_name- Python トレーニング スクリプトのコマンド引数を定義したときに作成したJOB_NAME変数。script_path- このチュートリアルで前に作成した Python トレーニング スクリプトのパス。container_url- モデルのトレーニングに使用される Docker コンテナ イメージの URI。requirements- スクリプトの Python パッケージ依存関係のリスト。model_serving_container_image_uri- モデルの予測を行う Docker コンテナ イメージの URI。このコンテナには、事前ビルド済みのものや独自のカスタム イメージを使用できます。このチュートリアルでは、事前ビルド済みのコンテナを使用します。
次のコードを実行して、トレーニング パイプラインを作成します。CustomTrainingJob メソッドは、task.py ファイルの Python トレーニング スクリプトを使用して CustomTrainingJob を作成します。
job = aiplatform.CustomTrainingJob(
display_name=JOB_NAME,
script_path="task.py",
container_uri="us-docker.pkg.dev/vertex-ai/training/tf-cpu.2-8:latest",
requirements=["google-cloud-bigquery>=2.20.0", "db-dtypes", "protobuf<3.20.0"],
model_serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest",
)
モデルを作成してトレーニングする
前の手順では、job という名前の CustomTrainingJob を作成しました。モデルを作成してトレーニングするには、CustomTrainingJob オブジェクトの run メソッドを呼び出し、以下のパラメータを渡します。
dataset- このチュートリアルで前に作成した表形式のデータセット。このパラメータには、表形式、画像、動画、テキストのデータセットを指定できます。model_display_name- モデルの名前。bigquery_destination- BigQuery データセットのロケーションを指定する文字列。args- Python トレーニング スクリプトに渡すコマンドライン引数。
データのトレーニングを開始してモデルを作成するには、ノートブックで次のコードを実行します。
MODEL_DISPLAY_NAME = "penguins_model_unique"
# Start the training and create your model
model = job.run(
dataset=dataset,
model_display_name=MODEL_DISPLAY_NAME,
bigquery_destination=f"bq://{project_id}",
args=CMDARGS,
)
次のステップに進む前に、job.run コマンドの出力に次の内容が含まれていることを確かめ、完了していることを確認します。
CustomTrainingJob run completed。
トレーニング ジョブが完了すると、モデルをデプロイできます。
モデルをデプロイする
モデルをデプロイするときに、予測に使用される Endpoint リソースも作成します。モデルをデプロイしてエンドポイントを作成するには、ノートブックで次のコードを実行します。
DEPLOYED_NAME = "penguins_deployed_unique"
endpoint = model.deploy(deployed_model_display_name=DEPLOYED_NAME)
モデルがデプロイされるまで待ってから次のステップに進みます。モデルをデプロイすると、Endpoint model deployed というテキストが出力されます。
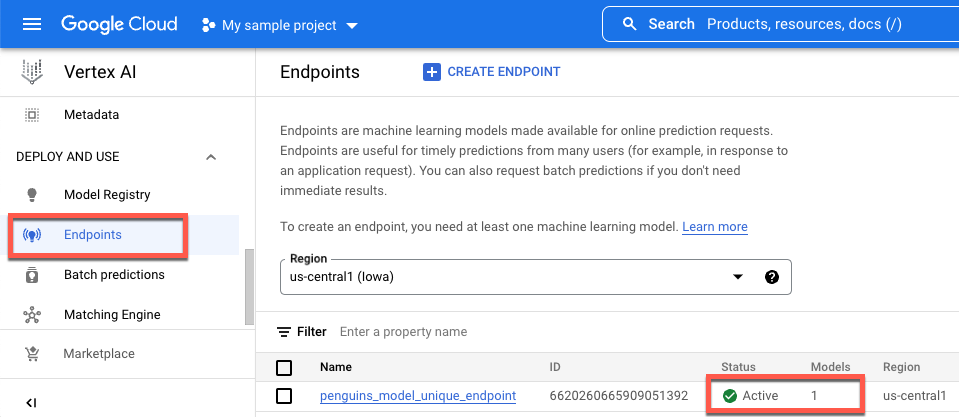
Google Cloud コンソールでデプロイのステータスを表示するには、次の操作を行います。
Google Cloud コンソールで、[エンドポイント] ページに移動します。
[モデル] で値をモニタリングします。エンドポイントが作成されてからモデルがデプロイされるまでの値は
0です。モデルがデプロイされると値は1に更新されます。エンドポイントが作成されてからモデルがデプロイされるまでのエンドポイントを次に示します。
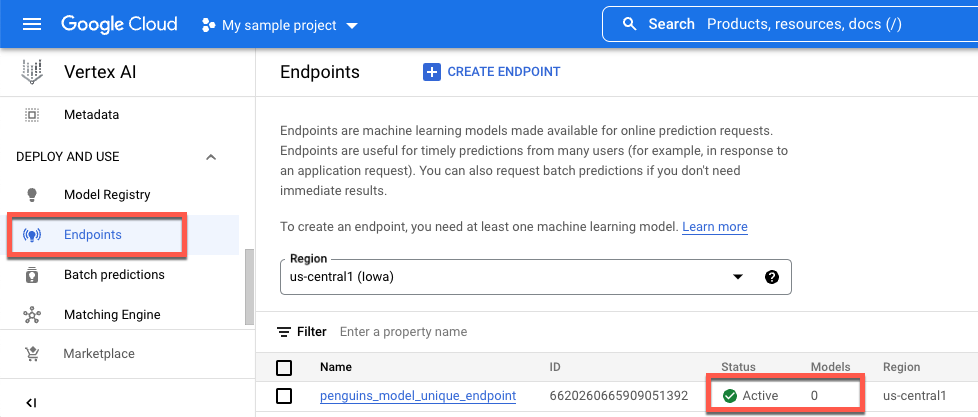
エンドポイントが作成されてモデルがデプロイされた後のエンドポイントを次に示します。