Utilisez la console Google Cloud pour vérifier les performances de votre modèle. Analysez les erreurs de test pour améliorer la qualité du modèle de manière itérative en corrigeant les problèmes liés aux données.
Ce tutoriel comporte plusieurs pages :
Créer un ensemble de données de classification d'images et importer des images
Évaluer et analyser les performances du modèle.
Déployer le modèle sur un point de terminaison et envoyer une prédiction
Chaque page suppose que vous avez déjà effectué les instructions des pages précédentes du tutoriel.
1. Comprendre les résultats de l'évaluation de modèles AutoML
Une fois l'entraînement terminé, votre modèle est automatiquement évalué en fonction de la répartition des données de test. Les résultats d'évaluation correspondants sont présentés en cliquant sur le nom du modèle depuis la page Registre de modèles ou la page Ensemble de données.
Vous pouvez ensuite accéder aux métriques permettant de mesurer les performances du modèle.
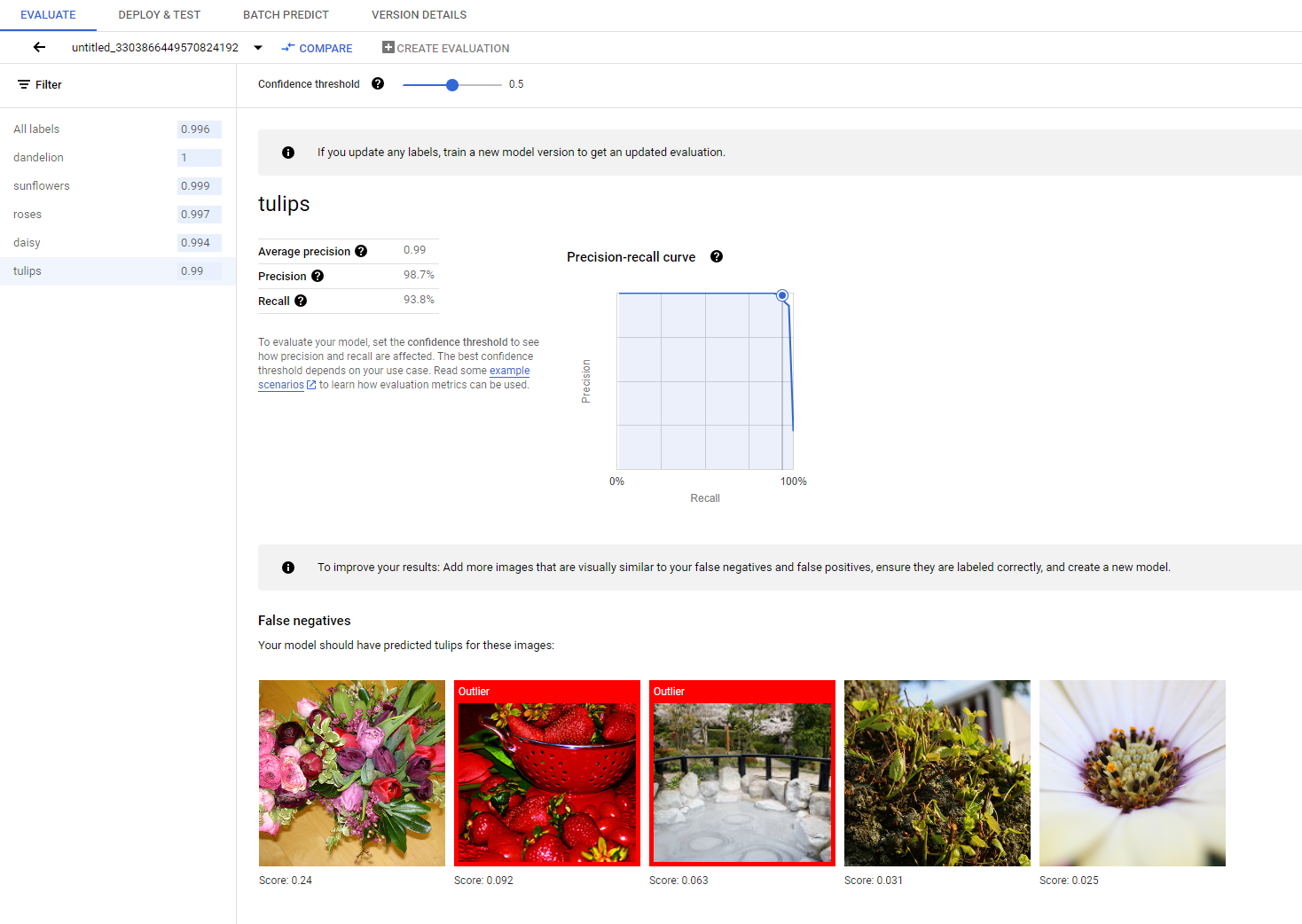
Vous trouverez une présentation plus détaillée des différentes métriques d'évaluation dans la section Évaluer, tester et déployer votre modèle.
2. Analyser les résultats des tests
Si vous souhaitez continuer à améliorer les performances du modèle, la première étape consiste souvent à examiner les cas d'erreur et à en examiner les causes potentielles. La page d'évaluation de chaque classe présente des images de test détaillées de la classe donnée, classées en tant que faux négatifs, faux positifs et vrais positifs. La définition de chaque catégorie est disponible dans la section Évaluer, tester et déployer votre modèle.
Pour chaque image de chaque catégorie, vous pouvez vérifier les détails de la prédiction en cliquant sur l'image et en accédant aux résultats d'analyse détaillés. Le panneau Examiner les images similaires s'affiche sur le côté droit de la page. Les échantillons les plus proches de l'ensemble d'entraînement sont présentés avec les distances mesurées dans l'espace des caractéristiques.
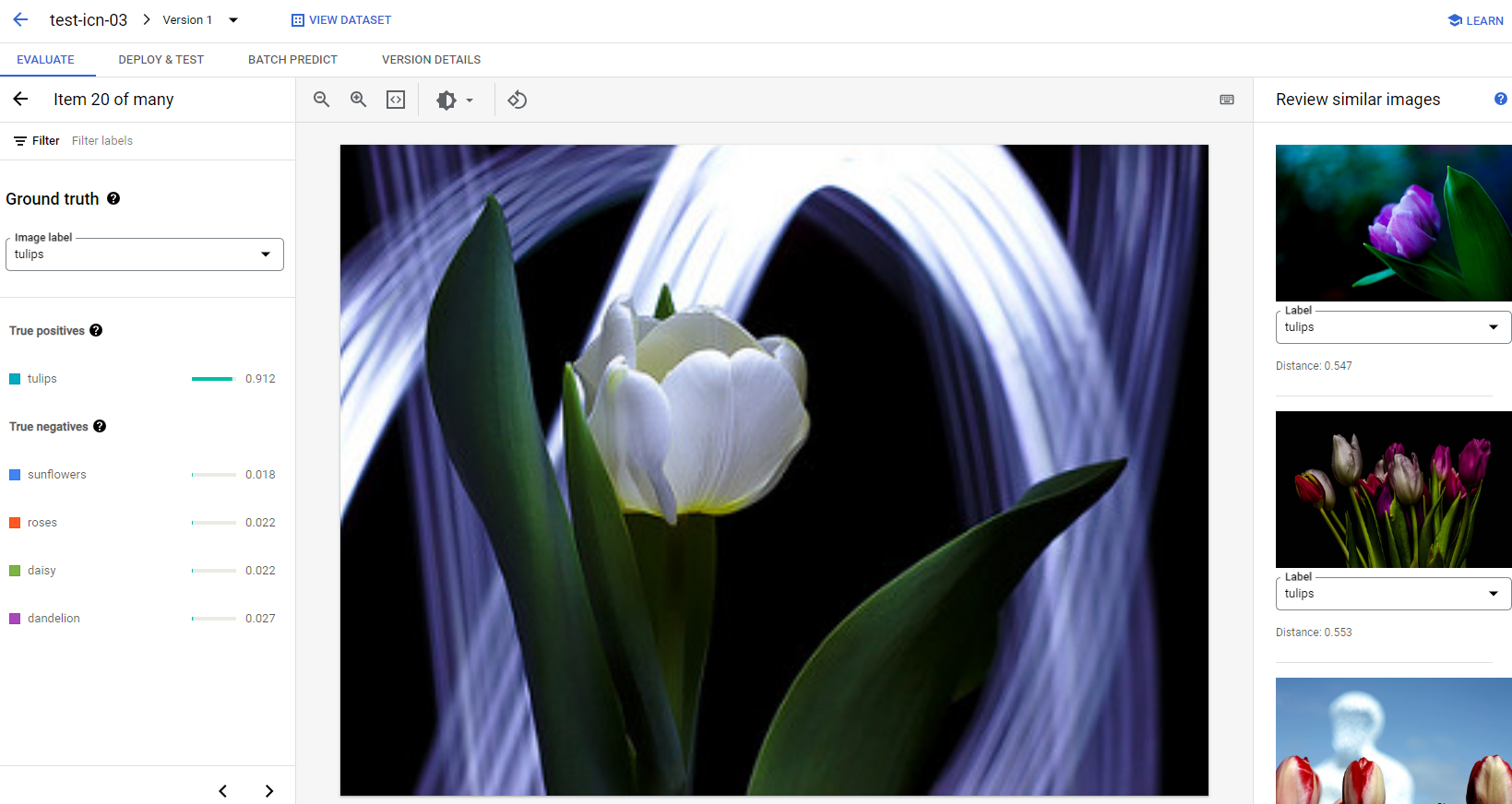
Il existe deux types de problèmes liés aux données que vous pouvez surveiller:
Incohérence au niveau des libellés. Si un échantillon visuellement semblable de l'ensemble d'entraînement présente des libellés différents de l'échantillon de test, il est possible que l'un d'eux soit incorrect ou que la différence subtile nécessite plus de données pour que le modèle puisse apprendre, ou que les libellés de classe actuels ne sont tout simplement pas assez précis pour décrire l'échantillon donné. L'examen d'images similaires peut vous aider à obtenir des informations précises sur le libellé en corrigeant les cas d'erreur ou en excluant l'échantillon problématique de l'ensemble de test. Vous pouvez facilement modifier le libellé de l'image de test ou des images d'entraînement dans le panneau Examiner des images similaires de la même page.
Anomalies Si un échantillon de test est marqué comme étant une anomalie, il est possible que l'ensemble d'entraînement ne comporte aucun échantillon visuellement semblable pour entraîner le modèle. L'examen d'images similaires dans l'ensemble d'entraînement peut vous aider à identifier ces échantillons et à ajouter des images similaires dans l'ensemble d'entraînement pour améliorer les performances du modèle dans ces cas-là.
Étapes suivantes
Si vous êtes satisfait des performances du modèle, suivez la page suivante de ce tutoriel pour déployer votre modèle AutoML entraîné sur un point de terminaison et envoyer une image au modèle pour la prédiction. Sinon, si vous apportez des corrections aux données, entraînez un nouveau modèle à l'aide du tutoriel Entraîner un modèle de classification d'images AutoML.