Dengan asumsi bahwa Anda telah menjalankan tutorial, halaman ini menguraikan praktik terbaik untuk Neural Architecture Search. Bagian pertama merangkum alur kerja lengkap, yang dapat Anda ikuti untuk tugas Neural Architecture Search. Bagian lainnya memberikan deskripsi mendetail untuk setiap langkah. Sebaiknya pelajari seluruh halaman ini sebelum menjalankan tugas Neural Architecture Search pertama Anda.
Alur kerja yang disarankan
Di sini kami merangkum alur kerja yang disarankan untuk Neural Architecture Search dan memberikan link ke bagian yang sesuai untuk detail lebih lanjut:
- Pisahkan set data pelatihan Anda untuk penelusuran tahap 1.
- Pastikan bahwa ruang penelusuran Anda mengikuti panduan kami.
- Jalankan pelatihan penuh dengan model dasar pengukuran Anda dan dapatkan kurva validasi.
- Jalankan alat desain tugas proxy untuk menemukan tugas proxy terbaik.
- Lakukan pemeriksaan akhir untuk tugas proxy Anda.
- Tetapkan jumlah total uji coba dan uji coba paralel yang tepat, lalu mulai penelusuran.
- Pantau plot penelusuran dan hentikan saat plot menunjukkan konvergensi atau menampilkan error dalam jumlah besar atau tidak menunjukkan tanda-tanda konvergensi.
- Jalankan pelatihan penuh dengan ~10 uji coba teratas yang dipilih dari penelusuran Anda untuk mendapatkan hasil akhir. Untuk pelatihan penuh, Anda dapat menggunakan lebih banyak augmentasi atau bobot yang telah dilatih sebelumnya untuk mendapatkan performa terbaik.
- Menganalisis metrik/data yang disimpan dari penelusuran dan menarik kesimpulan untuk iterasi ruang penelusuran di masa mendatang.
Neural Architecture Search Umum
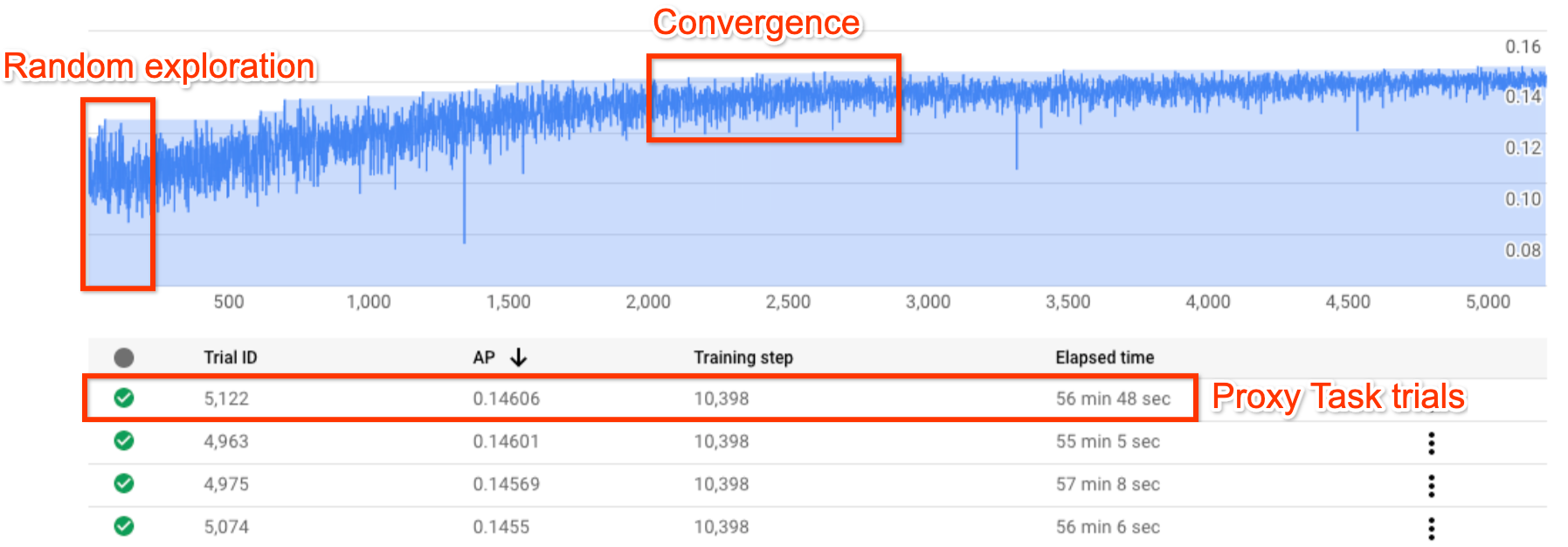
Gambar di atas menunjukkan kurva Neural Architecture Search standar.
Y-axis di sini menampilkan reward uji coba dan
X-axis menunjukkan jumlah uji coba yang diluncurkan sejauh ini.
~100-200 uji coba pertama sebagian besar merupakan eksplorasi acak
dari ruang penelusuran oleh pengontrol.
Selama eksplorasi awal ini, reward menunjukkan
varian yang besar karena banyak jenis model di
ruang penelusuran yang sedang dicoba.
Saat jumlah uji coba meningkat, pengontrol mulai menemukan model
yang lebih baik. Oleh karena itu, pertama-tama, reward mulai meningkat, lalu
varian reward dan pertumbuhan reward mulai menurun
sehingga menunjukkan konvergensi. Jumlah uji coba
saat konvergensi terjadi dapat bervariasi berdasarkan
ukuran ruang penelusuran, tetapi biasanya berjumlah sekitar ~2.000 uji coba.
Dua tahap Neural Architecture Search: tugas proxy dan pelatihan penuh
Neural Architecture Search bekerja dalam dua tahap:
Penelusuran tahap 1 menggunakan representasi pelatihan lengkap yang jauh lebih kecil, yang biasanya selesai dalam waktu ~1-2 jam. Representasi ini disebut tugas proxy dan membantu menekan biaya penelusuran.
Pelatihan penuh tahap 2 melibatkan pelatihan penuh untuk ~10 model skor teratas dari penelusuran tahap 1. Karena sifat penelusuran yang stokastik, model teratas dari penelusuran tahap 1 mungkin bukan model teratas selama pelatihan penuh tahap 2. Oleh karena itu, penting untuk memilih kumpulan model untuk pelatihan penuh.
Karena pengontrol mendapatkan sinyal reward dari tugas proxy yang lebih kecil, alih-alih menyelesaikan pelatihan, penting untuk menemukan tugas proxy yang optimal untuk tugas Anda.
Biaya Neural Architecture Search
Biaya Neural Architecture Search diberikan oleh:
search-cost = num-trials-to-converge * avg-proxy-task-cost.
Dengan asumsi bahwa waktu komputasi tugas proxy adalah sekitar 1/30 dari
waktu pelatihan penuh dan jumlah uji coba yang diperlukan untuk menunjukkan konvergensi
sekitar ~2.000, maka
biaya penelusuran menjadi ~ 67 * full-training-cost.
Karena biaya Neural Architecture Search tinggi, sebaiknya luangkan waktu untuk menyesuaikan tugas proxy dan menggunakan ruang penelusuran yang lebih kecil untuk penelusuran pertama Anda.
Set data dipisahkan menjadi dua tahap Neural Architecture Search
Dengan asumsi bahwa Anda sudah memiliki data pelatihan dan data validasi untuk pelatihan dasar pengukuran, pemisahan set data berikut direkomendasikan untuk dua tahap NAS Neural Architecture Search:
- Pelatihan penelusuran tahap 1: ~90% data pelatihan
Validasi penelusuran tahap 1: ~10% dari data pelatihan
Pelatihan pelatihan penuh tahap 2: 100% dari data pelatihan
Validasi pelatihan penuh tahap 2: 100% dari data validasi
Pembagian data pelatihan tahap 2 sama dengan pelatihan reguler. Namun, penelusuran tahap 1 menggunakan pemisahan data pelatihan untuk validasi. Menggunakan data validasi yang berbeda di tahap 1 dan tahap 2 akan membantu mendeteksi bias penelusuran model apa pun karena pemisahan set data. Pastikan data pelatihan diacak dengan baik sebelum mempartisinya lebih lanjut dan 10% pemisahan data pelatihan yang terakhir memiliki distribusi yang serupa dengan data validasi asli.
Data yang kecil atau tidak seimbang
Penelusuran arsitektur tidak direkomendasikan dengan data pelatihan terbatas atau untuk set data yang sangat tidak seimbang yang beberapa kelasnya sangat jarang. Jika Anda sudah menggunakan augmentasi besar untuk pelatihan dasar pengukuran karena kurangnya data, penelusuran model tidak direkomendasikan.
Dalam hal ini, Anda hanya dapat menjalankan penelusuran augmentasi untuk menelusuri kebijakan augmentasi terbaik, bukan menelusuri arsitektur yang optimal.
Desain ruang penelusuran
Penelusuran arsitektur tidak boleh dicampur dengan penelusuran augmentasi atau penelusuran hyperparameter (seperti setelan kecepatan pembelajaran atau pengoptimal). Tujuan penelusuran arsitektur adalah untuk membandingkan performa model A dengan model B saat hanya ada perbedaan berbasis arsitektur. Oleh karena itu, setelan augmentasi dan hyperparameter harus tetap sama.
Penelusuran augmentasi dapat dilakukan sebagai tahap yang berbeda setelah penelusuran arsitektur selesai.
Neural Architecture Search dapat mencapai 10^20 dalam ukuran ruang penelusuran. Namun, jika ruang penelusuran Anda lebih besar, Anda dapat membagi ruang penelusuran menjadi beberapa bagian yang tidak dapat muncul bersamaan. Misalnya, Anda dapat menelusuri encoder secara terpisah dari decoder atau head terlebih dahulu. Jika masih ingin melakukan penelusuran bersama untuk semuanya, Anda dapat membuat ruang penelusuran yang lebih kecil untuk opsi individu terbaik yang sebelumnya ditemukan.
(Opsional) Anda dapat melakukan penskalaan model dari desain blok saat mendesain ruang penelusuran. Penelusuran desain blok harus dilakukan terlebih dahulu dengan model yang skalanya diperkecil. Hal ini dapat membuat biaya runtime tugas proxy menjadi jauh lebih rendah. Kemudian, Anda dapat melakukan penelusuran terpisah untuk menaikkan skala model. Untuk informasi selengkapnya, lihat
Examples of scaled down models.
Mengoptimalkan waktu pelatihan dan penelusuran
Sebelum menjalankan Neural Architecture Search, penting untuk mengoptimalkan waktu pelatihan untuk model dasar Anda. Ini akan menghemat biaya Anda dalam jangka panjang. Berikut adalah beberapa opsi untuk mengoptimalkan pelatihan:
- Memaksimalkan kecepatan pemuatan data:
- Pastikan bucket tempat data Anda berada ada di region yang sama dengan tugas Anda.
- Jika menggunakan TensorFlow, lihat
Best practice summary. Anda juga dapat mencoba menggunakan format TFRecord untuk data Anda. - Jika menggunakan PyTorch, ikuti panduan untuk pelatihan PyTorch yang efisien.
- Gunakan pelatihan terdistribusi untuk memanfaatkan beberapa akselerator atau beberapa mesin.
- Gunakan pelatihan presisi campuran
untuk mendapatkan kecepatan pelatihan yang signifikan dan pengurangan penggunaan memori.
Untuk pelatihan presisi campuran TensorFlow,
lihat
Mixed Precision. - Beberapa akselerator (seperti A100) biasanya lebih hemat biaya.
- Sesuaikan ukuran tumpukan untuk memastikan Anda memaksimalkan pemanfaatan GPU.
Plot berikut menunjukkan pemakaian GPU yang kurang (50%).
 Meningkatkan ukuran tumpukan dapat membantu memanfaatkan GPU lebih lanjut. Namun, ukuran tumpukan
harus ditingkatkan dengan hati-hati karena dapat meningkatkan
error kehabisan memori selama penelusuran.
Meningkatkan ukuran tumpukan dapat membantu memanfaatkan GPU lebih lanjut. Namun, ukuran tumpukan
harus ditingkatkan dengan hati-hati karena dapat meningkatkan
error kehabisan memori selama penelusuran. - Jika blok arsitektur tertentu tidak bergantung pada ruang penelusuran, Anda dapat mencoba memuat checkpoint yang telah dilatih sebelumnya untuk blok ini agar lebih cepat dilatih. Checkpoint yang telah dilatih sebelumnya harus sama di atas ruang penelusuran dan tidak boleh menimbulkan bias. Misalnya, jika ruang penelusuran Anda hanya untuk decoder, maka encoder dapat menggunakan checkpoint yang telah dilatih sebelumnya.
Jumlah GPU untuk setiap uji coba penelusuran
Gunakan jumlah GPU yang lebih kecil per uji coba untuk mengurangi waktu mulai. Misalnya, 2 GPU membutuhkan waktu 5 menit untuk dimulai sedangkan 8 GPU membutuhkan waktu 20 menit. Menggunakan 2 GPU per uji coba untuk menjalankan tugas proxy tugas Neural Architecture Search dinilai lebih efisien.
Total uji coba dan uji coba paralel untuk penelusuran
Total setelan uji coba
Setelah menelusuri dan memilih tugas proxy terbaik, Anda siap meluncurkan penelusuran lengkap. Anda tidak dapat mengetahui pasti tentang berapa banyak uji coba yang diperlukan untuk melakukan konvergensi sebelum benar-benar melakukannya. Jumlah uji coba saat konvergensi terjadi dapat bervariasi berdasarkan ukuran ruang penelusuran, tetapi biasanya berjumlah sekitar 2.000 uji coba.
Kami merekomendasikan setelan yang sangat tinggi
untuk --max_nas_trial: sekitar 5.000-10.000, lalu
membatalkan tugas penelusuran sebelumnya jika
plot penelusuran menunjukkan konvergensi
Anda juga memiliki opsi untuk melanjutkan tugas penelusuran sebelumnya menggunakan
perintah search_resume.
Namun, Anda tidak dapat melanjutkan penelusuran dari tugas melanjutkan penelusuran lain.
Oleh karena itu, Anda hanya dapat melanjutkan tugas penelusuran asli satu kali.
Setelan uji coba paralel
Tugas penelusuran tahap 1 melakukan batch processing dengan menjalankan
--max_parallel_nas_trial uji coba secara paralel
dalam satu waktu. Hal ini sangat penting dalam mengurangi keseluruhan runtime
untuk tugas penelusuran. Anda dapat menghitung perkiraan jumlah hari untuk penelusuran:
days-required-for-search = (trials-to-converge / max-parallel-nas-trial) * (avg-trial-duration-in-hours / 24)
Catatan: Awalnya Anda dapat menggunakan 3000 sebagai perkiraan
kasar untuk trials-to-converge, yang merupakan batas atas yang baik
untuk memulai. Awalnya, Anda dapat menggunakan 2 jam
sebagai perkiraan kasar untuk avg-trial-duration-in-hours yang
merupakan batas atas yang baik untuk waktu yang dibutuhkan oleh setiap tugas proxy.
Sebaiknya
gunakan setelan --max_parallel_nas_trial dari
~20 hingga 50, tergantung kuota akselerator yang dimiliki project Anda
dan days-required-for-search.
Misalnya, jika Anda menetapkan --max_parallel_nas_trial sebagai 20
dan setiap tugas proxy menggunakan dua GPU NVIDIA T4, berarti Anda harus
mencadangkan kuota setidaknya 40 GPU NVIDIA T4. Setelan --max_parallel_nas_trial tidak memengaruhi hasil penelusuran secara keseluruhan, tetapi memengaruhi days-required-for-search.
Setelan yang lebih kecil untuk max_parallel_nas_trial
seperti sekitar 10 GPU yang dapat digunakan (20 GPU), tetapi Anda juga harus
memperkirakan secara kasar days-required-for-search dan memastikannya
berada dalam batas waktu tunggu tugas.
Tugas pelatihan penuh tahap 2 biasanya melatih semua uji coba secara paralel secara default. Biasanya, ini adalah 10 uji coba teratas yang berjalan secara paralel. Namun, jika setiap uji coba pelatihan penuh tahap 2 menggunakan terlalu banyak GPU (misalnya, masing-masing delapan GPU) untuk kasus penggunaan Anda dan Anda tidak memiliki kuota yang cukup, maka Anda dapat menjalankan tugas tahap 2 secara manual dalam batch seperti menjalankan pelatihan penuh tahap 2 hanya untuk lima uji coba terlebih dahulu, lalu menjalankan pelatihan penuh tahap 2 lainnya untuk 5 uji coba berikutnya.
Waktu tunggu tugas default
Waktu tunggu tugas NAS default ditetapkan ke 14 hari dan setelah itu, tugas akan dibatalkan. Jika Anda berencana menjalankan tugas untuk durasi yang lebih lama, Anda dapat mencoba melanjutkan tugas penelusuran sekali lagi selama 14 hari lagi. Secara keseluruhan, Anda dapat menjalankan tugas penelusuran selama 28 hari termasuk melanjutkan.
Setelan uji coba gagal maksimum
Jumlah maksimum uji coba yang gagal harus ditetapkan ke sekitar 1/3 dari setelan max_nas_trial. Tugas akan dibatalkan jika jumlah
uji coba yang gagal mencapai batas ini.
Kapan penelusuran dihentikan
Sebaiknya Anda menghentikan penelusuran saat:
Kurva penelusuran mulai menunjukkan konvergensi (varian menurun):
Catatan: Jika tidak ada batasan latensi yang digunakan, atau batasan latensi kuat
digunakan dengan batas latensi longgar, maka kurva mungkin tidak menunjukkan
peningkatan reward tetapi tetap harus menunjukkan konvergensi. Hal ini terjadi karena
pengontrol mungkin sudah melihat akurasi yang baik
di awal dalam penelusuran.Lebih dari 20% uji coba Anda menampilkan reward yang tidak valid (kegagalan):
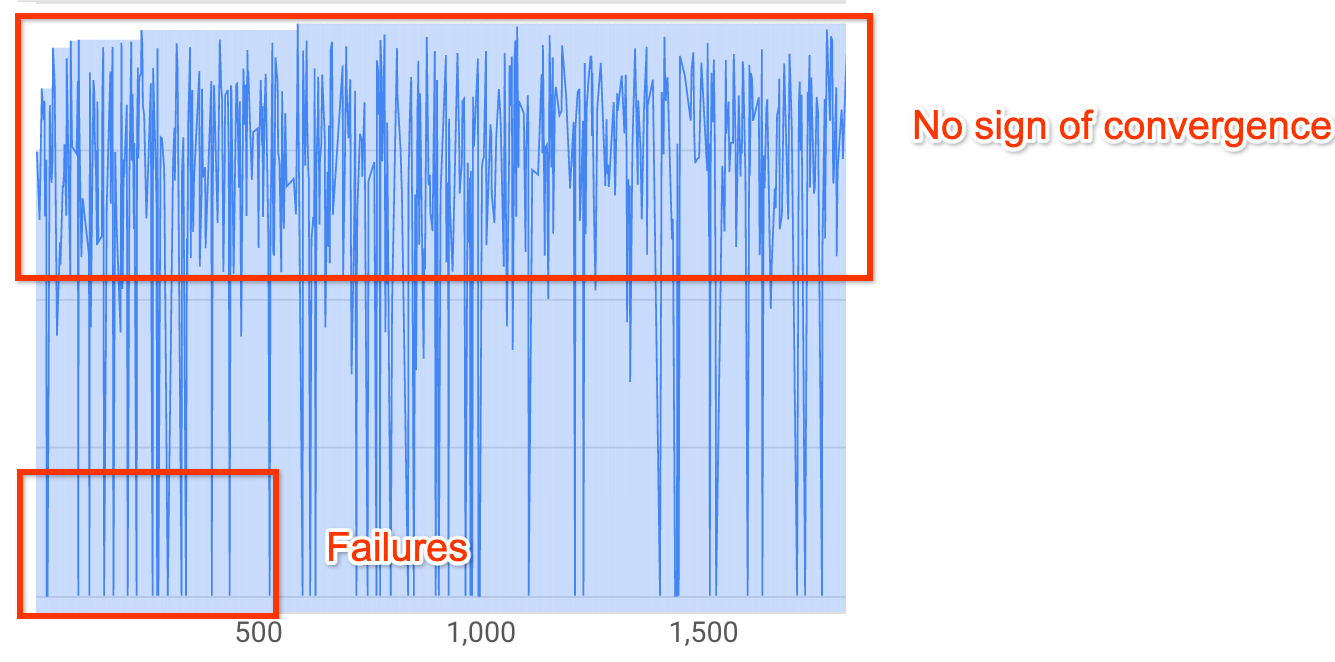
Kurva penelusuran tidak meningkat atau tidak menunjukkan konvergensi (seperti yang ditunjukkan di atas) bahkan setelah ~500 uji coba. Jika dasbor menunjukkan peningkatan reward atau penurunan varian, Anda dapat melanjutkan.