En supposant que vous ayez déjà exécuté les tutoriels, cette page décrit les bonnes pratiques concernant Neural Architecture Search. La première section récapitule un workflow complet que vous pouvez suivre pour votre tâche Neural Architecture Search. Les autres sections fournissent une description détaillée de chaque étape. Nous vous recommandons vivement de parcourir l'intégralité de cette page avant d'exécuter votre première tâche Neural Architecture Search.
Suggestion de workflow
Ici, nous résumons un workflow suggéré pour Neural Architecture Search et fournissons des liens vers les sections correspondantes pour en savoir plus :
- Divisez votre ensemble de données d'entraînement pour la recherche de la phase 1.
- Assurez-vous que votre espace de recherche respecte nos consignes.
- Exécutez l'entraînement complet avec votre modèle de référence et obtenez une courbe de validation.
- Exécutez les outils de conception de tâche de proxy pour trouver la meilleure tâche de proxy.
- Effectuez des vérifications finales pour votre tâche de proxy.
- Définissez le nombre approprié d'essais totaux et d'essais parallèles, puis lancez la recherche.
- Surveillez le tracé de recherche et arrêtez-le en cas de convergence, ou lorsqu'il indique un grand nombre d'erreurs ou aucun signe de convergence.
- Effectuez un entraînement complet avec les 10 principaux essais sélectionnés dans votre recherche pour le résultat final. Pour un entraînement complet, vous pouvez utiliser une augmentation plus élevée ou des pondérations pré-entraînées afin d'obtenir les meilleures performances possibles.
- Analysez les métriques ou données enregistrées à partir de la recherche et tirez des conclusions pour les futures itérations d'espace de recherche.
Neural Architecture Search typique
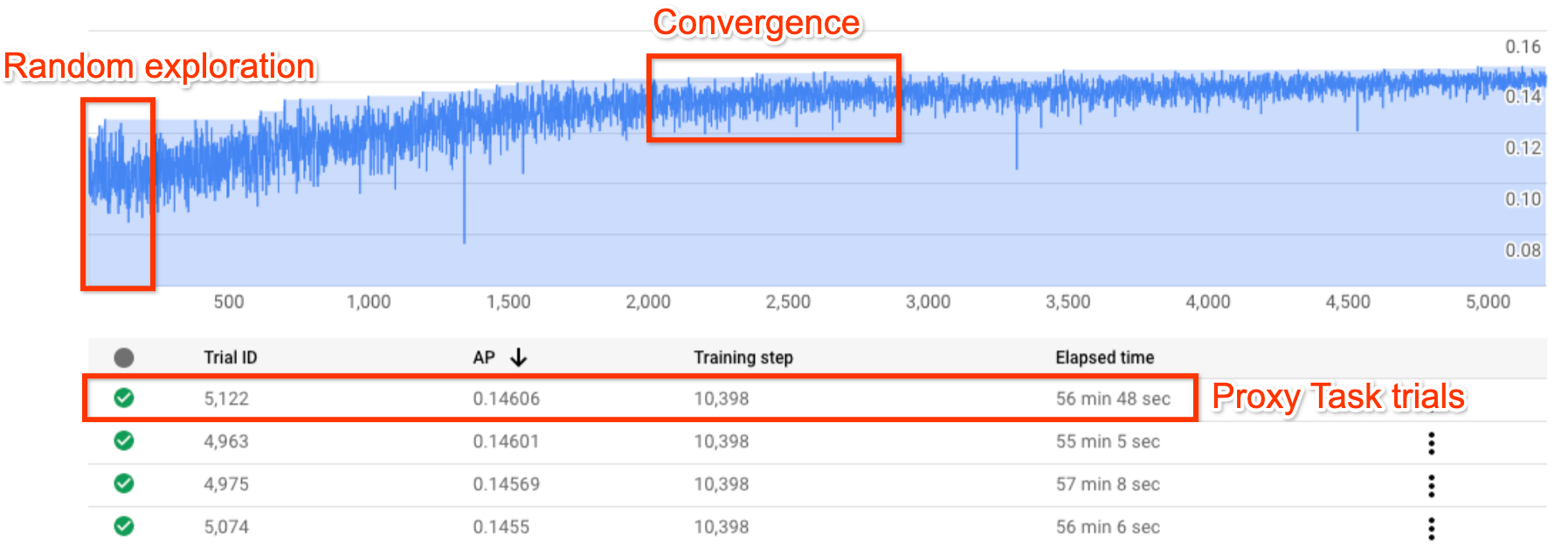
La figure ci-dessus montre une courbe Neural Architecture Search typique.
La valeur Y-axis indique les récompenses des essais et la valeur X-axis indique le nombre d'essais lancés jusqu'à présent.
Les 100 à 200 premiers essais sont principalement des explorations aléatoires de l'espace de recherche par le contrôleur.
Lors de ces explorations initiales, les récompenses présentent une variance importante, car de nombreux types de modèles sont testés dans l'espace de recherche.
À mesure que le nombre d'essais augmente, le contrôleur commence à trouver des modèles plus performants. Par conséquent, la récompense commence à augmenter, puis sa variance et sa croissance commencent à diminuer. Cela indique une convergence. Le nombre d'essais permettant d'obtenir une convergence peut varier en fonction de la taille de l'espace de recherche, mais il est généralement de l'ordre d'environ 2 000 essais.
Deux étapes de Neural Architecture Search : tâche de proxy et entraînement complet
Neural Architecture Search comporte deux étapes :
La recherche à l'étape 1 utilise une représentation beaucoup plus petite de l'entraînement complet, qui se termine généralement dans un délai d'environ une à deux heures. Cette représentation est appelée tâche de proxy et elle permet de réduire le coût de recherche.
L'entraînement complet à l'étape 2 consiste à effectuer un entraînement complet pour les dix principaux modèles de notation issus de la recherche à l'étape 1. En raison de la nature stochastique de la recherche, il est possible que le modèle le plus pertinent de la recherche à l'étape 1 ne soit pas le modèle le plus pertinent lors de l'entraînement complet à l'étape 2. Il est donc important de sélectionner un pool de modèles pour un entraînement complet.
Étant donné que le contrôleur obtient le signal de récompense de la tâche de proxy plus petite au lieu de l'entraînement complet, il est important de trouver une tâche de proxy optimale pour votre tâche.
Coût de Neural Architecture Search
Le coût de Neural Architecture Search est calculé comme suit : search-cost = num-trials-to-converge * avg-proxy-task-cost.
En supposant que le temps de calcul de la tâche de proxy représente environ 1/30e du temps de l'entraînement complet et que le nombre d'essais nécessaires pour la convergence est d'environ 2 000, le coût de recherche est d'environ 67 * full-training-cost.
Le coût de Neural Architecture Search est élevé. Il est donc conseillé de consacrer du temps au réglage de votre tâche de proxy et d'utiliser un espace de recherche plus petit pour votre première recherche.
Ensemble de données divisé en deux étapes de Neural Architecture Search
En supposant que vous disposiez déjà des données d'entraînement et des données de validation pour votre entraînement de référence, la répartition suivante de l'ensemble de données est recommandée pour les deux étapes de Neural Architecture Search (NAS) :
- Entraînement de la recherche à l'étape 1 : environ 90 % des données d'entraînement
Validation de la recherche à l'étape 1 : environ 10 % des données d'entraînement
Entraînement de l'entraînement complet à l'étape 2 : 100 % des données d'entraînement
Validation de l'entraînement complet à l'étape 2 : 100 % des données de validation
La répartition des données de l'entraînement complet à l'étape 2 est identique à celle de l'entraînement habituel. Toutefois, la recherche à l'étape 1 utilise une répartition des données d'entraînement pour la validation. L'utilisation de différentes données de validation aux étapes 1 et 2 permet de détecter tout biais de recherche de modèle dû à la répartition de l'ensemble de données. Assurez-vous que les données d'entraînement sont bien brassées avant d'être partitionnées davantage et que la répartition finale de 10 % des données d'entraînement est semblable à celle des données de validation d'origine.
Données de petite taille ou déséquilibrées
La recherche d'architecture n'est pas recommandée avec des données d'entraînement limitées ou pour des ensembles de données très déséquilibrés dans lesquels certaines classes sont très rares. Si vous utilisez déjà des augmentations élevées pour votre entraînement de référence en raison d'un manque de données, la recherche de modèles n'est pas recommandée.
Dans ce cas, vous pouvez uniquement exécuter la recherche d'augmentation pour rechercher la meilleure stratégie d'augmentation plutôt que de rechercher une architecture optimale.
Conception d'espace de recherche
La recherche d'architecture ne doit pas être associée à une recherche d'augmentation ou d'hyperparamètres (par exemple, taux d'apprentissage ou paramètres de l'optimiseur). L'objectif de la recherche d'architecture est de comparer les performances du modèle A à celles du modèle B lorsqu'il n'existe que des différences basées sur l'architecture. Par conséquent, les paramètres d'augmentation et d'hyperparamètres doivent rester identiques.
La recherche d'augmentation peut être effectuée à une autre étape, après la recherche de l'architecture.
Neural Architecture Search peut atteindre une taille d'espace de recherche de 10^20. Toutefois, si votre espace de recherche est plus vaste, vous pouvez le diviser en parties s'excluant mutuellement. Par exemple, vous pouvez rechercher l'encodeur séparément du décodeur ou de la base. Si vous souhaitez toujours effectuer une recherche conjointe sur l'ensemble de ces éléments, vous pouvez créer un espace de recherche plus petit portant sur les meilleures options individuelles trouvées précédemment.
(Facultatif) Vous pouvez modéliser le scaling à partir de la conception de blocs lorsque vous concevez un espace de recherche. La recherche de conception de blocs doit d'abord être effectuée avec un modèle à capacité réduite. Cela peut réduire considérablement le coût d'exécution de la tâche de proxy. Vous pouvez ensuite effectuer une recherche distincte pour effectuer un scaling du modèle à la hausse. Pour en savoir plus, consultez la page concernant
Examples of scaled down models
Optimiser le temps d'entraînement et de recherche
Avant d'exécuter Neural Architecture Search, il est important d'optimiser le temps d'entraînement de votre modèle de référence. Vous pourrez ainsi réaliser des économies sur le long terme. Voici quelques-unes des options permettant d'optimiser l'entraînement :
- Optimiser la vitesse de chargement des données :
- Assurez-vous que le bucket contenant vos données se trouve dans la même région que votre tâche.
- Si vous utilisez TensorFlow, consultez la page
Best practice summary. Vous pouvez également essayer d'utiliser le format TFRecord pour vos données. - Si vous utilisez PyTorch, suivez les consignes pour un entraînement efficace dans PyTorch.
- Utilisez l'entraînement distribué pour exploiter plusieurs accélérateurs ou plusieurs machines.
- Utilisez l'entraînement de précision mixte pour accélérer considérablement l'entraînement et réduire l'utilisation de la mémoire.
Pour en savoir plus sur l'entraînement de précision mixte sur TensorFlow, consultez
Mixed Precision. - Certains accélérateurs (tels que A100) sont généralement plus rentables.
- Ajustez la taille de lot pour vous assurer d'optimiser l'utilisation du GPU.
Le tracé suivant indique la sous-utilisation des GPU (50 %).
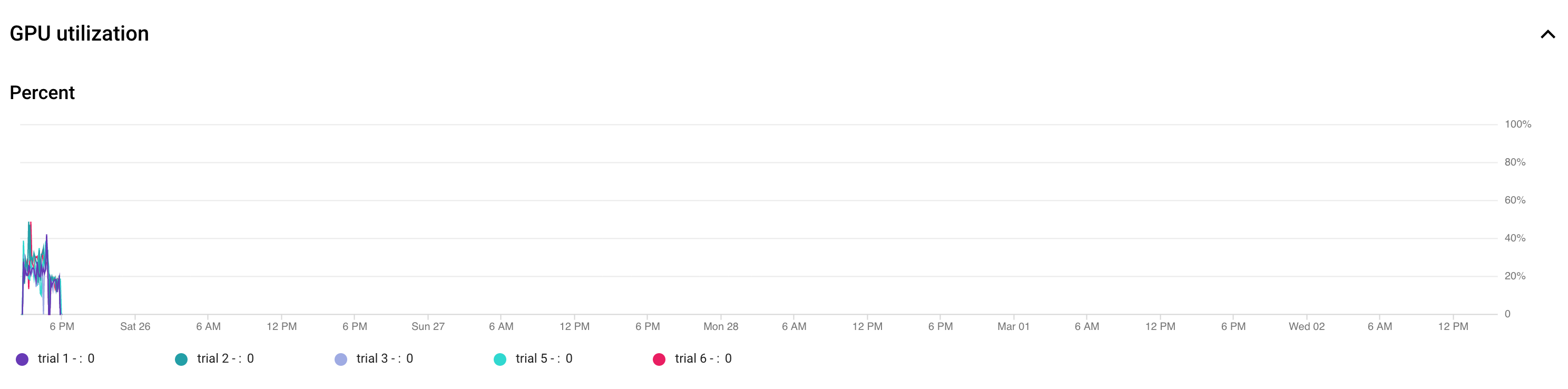 L'augmentation de la taille de lot peut aider à utiliser davantage de GPU. Cependant, réfléchissez bien avant d'augmenter la taille de lot, car elle peut augmenter les erreurs de mémoire insuffisante pendant la recherche.
L'augmentation de la taille de lot peut aider à utiliser davantage de GPU. Cependant, réfléchissez bien avant d'augmenter la taille de lot, car elle peut augmenter les erreurs de mémoire insuffisante pendant la recherche. - Si certains blocs d'architecture sont indépendants de l'espace de recherche, vous pouvez essayer de charger des points de contrôle pré-entraînés pour ces blocs afin d'accélérer l'entraînement. Les points de contrôle pré-entraînés doivent être identiques sur l'espace de recherche et ne doivent pas introduire de biais. Par exemple, si votre espace de recherche ne concerne que le décodeur, l'encodeur peut utiliser des points de contrôle pré-entraînés.
Nombre de GPU pour chaque essai de recherche
Utilisez un plus petit nombre de GPU par essai pour réduire l'heure de début. Par exemple, le démarrage de deux GPU prend cinq minutes, contre 20 minutes pour huit GPU. Il est plus efficace d'utiliser deux GPU par essai pour exécuter une tâche de proxy Neural Architecture Search.
Nombre d'essais totaux et d'essais parallèles pour la recherche
Paramètre du nombre d'essais totaux
Une fois que vous avez recherché et sélectionné la meilleure tâche de proxy, vous êtes prêt à lancer une recherche complète. Il n'est pas possible de savoir au préalable le nombre d'essais nécessaires à la convergence. Le nombre d'essais permettant d'obtenir une convergence peut varier en fonction de la taille de l'espace de recherche, mais il est généralement de l'ordre d'environ 2 000 essais.
Nous vous recommandons d'utiliser un paramètre très élevé pour --max_nas_trial, entre 5 000 et 10 000, puis d'annuler plus tôt la tâche de recherche si le tracé de recherche affiche la convergence.
Vous avez également la possibilité de reprendre une tâche de recherche précédente à l'aide de la commande search_resume.
En revanche, vous ne pouvez pas reprendre la recherche à partir d'une autre tâche de reprise de la recherche.
Par conséquent, vous ne pouvez reprendre une tâche de recherche d'origine qu'une seule fois.
Paramètre d'essais parallèles
La tâche stage1-search effectue un traitement par lot en exécutant un nombre d'essais --max_parallel_nas_trial en parallèle à la fois. Cela est essentiel pour réduire le temps d'exécution global de la tâche de recherche. Vous pouvez calculer le nombre de jours attendu pour la recherche : days-required-for-search = (trials-to-converge / max-parallel-nas-trial) * (avg-trial-duration-in-hours / 24). Remarque: Vous pouvez initialement utiliser 3000 comme estimation approximative pour trials-to-converge, ce qui est une limite supérieure intéressante pour commencer. Vous pouvez initialement utiliser 2 heures comme estimation approximative pour avg-trial-duration-in-hours, ce qui est une bonne limite supérieure pour le temps pris par chaque tâche de proxy.
Il est préférable d'utiliser un paramètre --max_parallel_nas_trial entre 20 et 50 en fonction du quota d'accélérateur de votre projet et de days-required-for-search.
Par exemple, si vous définissez --max_parallel_nas_trial sur 20 et que chaque tâche de proxy utilise deux GPU NVIDIA T4, vous devez réserver un quota d'au moins 40 GPU NVIDIA T4. Le paramètre --max_parallel_nas_trial n'a aucune incidence sur le résultat de recherche global, mais il a un impact sur days-required-for-search.
Un paramètre max_parallel_nas_trial plus petit, par exemple d'environ 10 (20 GPU), est également possible. Toutefois, vous devez estimer approximativement days-required-for-search et vous assurer qu'il se situe dans la limite de délai avant expiration de la tâche.
Par défaut, le job d'entraînement complet à l'étape 2 entraîne généralement tous les essais en parallèle. Il s'agit généralement des 10 meilleurs essais exécutés en parallèle. Toutefois, si chaque essai d'entraînement complet à l'étape 2 utilise trop de GPU (par exemple, huit GPU) pour votre cas d'utilisation et que vous ne disposez pas d'un quota suffisant, vous pouvez exécuter manuellement les tâches d'étape 2 par lots (comme l'exécution d'un entraînement complet à l'étape 2) pour cinq essais seulement, puis exécuter un autre entraînement complet à l'étape 2 pour les cinq essais suivants.
Délai avant expiration par défaut d'un job
Le délai avant expiration par défaut du job NAS est défini sur 14 jours, après quoi le job est annulé. Si vous prévoyez d'exécuter le job plus longtemps, vous ne pouvez essayer de le réactiver qu'une seule fois pour 14 jours supplémentaires. Dans l'ensemble, vous pouvez exécuter une tâche de recherche pendant 28 jours, y compris la reprise.
Paramètre du nombre maximal d'essai échoués
Le nombre maximal d'essais échoués doit être défini sur environ un tiers du paramètre max_nas_trial. La tâche est annulée lorsque le nombre d'essais ayant échoué atteint cette limite.
Quand arrêter la recherche
Vous devez arrêter la recherche lorsque :
La courbe de recherche commence à converger (la variance diminue) :
Remarque : Si aucune contrainte de latence n'est utilisée ou que la contrainte de latence stricte est utilisée avec une limite de latence faible, il est possible que la courbe ne présente pas d'augmentation de récompense, mais qu'elle indique tout de même une convergence. En effet, le contrôleur a peut-être déjà constaté une bonne justesse au début de la recherche.Plus de 20 % de vos essais affichent des récompenses non valides (échecs) :
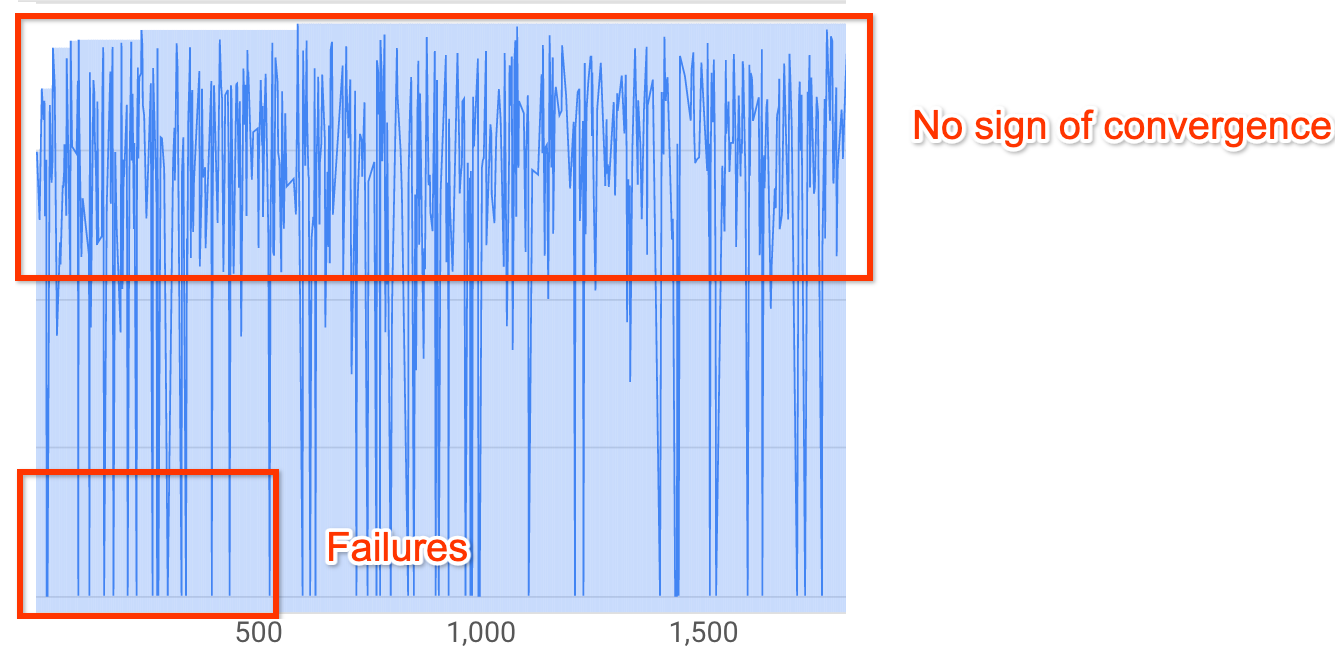
La courbe de recherche n'augmente pas et ne converge pas (comme indiqué ci-dessus), même après environ 500 essais. Si elle indique une augmentation de récompense ou une diminution de la variance, vous pouvez continuer.