En esta guía se muestra cómo ejecutar un trabajo de búsqueda de arquitectura neuronal de Vertex AI mediante los espacios de búsqueda y el código de entrenador predefinidos de Google basados en TF-vision para MnasNet y SpineNet. Consulta los ejemplos completos de la notebook de clasificación de MnasNet y la notebook de detección de objetos de SpineNet.
Preparación de datos para el entrenador prediseñado
El entrenador precompilado de Neural Architecture Search requiere que los datos estén en formato TFRecord y contengan tf.train.Examples. Los tf.train.Examples deben incluir los siguientes campos:
'image/encoded': tf.FixedLenFeature(tf.string)
'image/height': tf.FixedLenFeature(tf.int64)
'image/width': tf.FixedLenFeature(tf.int64)
# For image classification only.
'image/class/label': tf.FixedLenFeature(tf.int64)
# For object detection only.
'image/object/bbox/xmin': tf.VarLenFeature(tf.float32)
'image/object/bbox/xmax': tf.VarLenFeature(tf.float32)
'image/object/bbox/ymin': tf.VarLenFeature(tf.float32)
'image/object/bbox/ymax': tf.VarLenFeature(tf.float32)
'image/object/class/label': tf.VarLenFeature(tf.int64)
Puedes seguir las instrucciones para preparar los datos de ImageNet.
Para convertir sus datos personalizados, utilice la secuencia de comandos de análisis que se incluye en el código de ejemplo y las utilidades que ha descargado. Para personalizar el análisis de datos, modifique los archivos tf_vision/dataloaders/*_input.py.
Consulta más información sobre TFRecord y tf.train.Example.
Definir variables de entorno del experimento
Antes de ejecutar los experimentos, deberá definir varias variables de entorno, entre las que se incluyen las siguientes:
- TRAINER_DOCKER_ID:
${USER}_nas_experiment(formato recomendado) Ubicaciones de Cloud Storage de los conjuntos de datos de entrenamiento y validación que usará el experimento. Por ejemplo, en el caso de la detección (CoCo):
gs://cloud-samples-data/ai-platform/built-in/image/coco/train*gs://cloud-samples-data/ai-platform/built-in/image/coco/val*
Ubicación de Cloud Storage para la salida del experimento. Formato recomendado:
gs://${USER}_nas_experiment
REGION: una región que debe ser la misma que la región del segmento de salida del experimento. Por ejemplo:
us-central1.PARAM_OVERRIDE: un archivo .yaml que anula los parámetros del entrenador precompilado. Búsqueda con arquitectura neuronal proporciona algunas configuraciones predeterminadas que puedes usar:
PROJECT_ID=PROJECT_ID
TRAINER_DOCKER_ID=TRAINER_DOCKER_ID
LATENCY_CALCULATOR_DOCKER_ID=LATENCY_CALCULATOR_DOCKER_ID
GCS_ROOT_DIR=OUTPUT_DIR
REGION=REGION
PARAM_OVERRIDE=tf_vision/configs/experiments/spinenet_search_gpu.yaml
TRAINING_DATA_PATH=gs://PATH_TO_TRAINING_DATA
VALIDATION_DATA_PATH=gs://PATH_TO_VALIDATION_DATA
Puede que quieras seleccionar o modificar el archivo de anulación que se ajuste a tus requisitos de entrenamiento. Ten en cuenta lo siguiente:
- Puedes definir
--accelerator_typepara elegir entre GPU o CPU. Para ejecutar solo algunas épocas para hacer pruebas rápidas con la CPU, puedes definir la marca--accelerator_type=""y usar el archivo de configuracióntf_vision/test_files/fast_nas_detection_spinenet_search_for_testing.yaml. - Número de épocas
- Tiempo de ejecución del entrenamiento
- Hiperparámetros como la tasa de aprendizaje
Para ver una lista de todos los parámetros para controlar los trabajos de entrenamiento, consulta tf_vision/configs/. Estos son los parámetros clave:
task:
train_data:
global_batch_size: 80
validation_data:
global_batch_size: 16
init_checkpoint: null
trainer:
train_steps: 16634
steps_per_loop: 1386
optimizer_config:
learning_rate:
cosine:
initial_learning_rate: 0.16
decay_steps: 16634
type: 'cosine'
warmup:
type: 'linear'
linear:
warmup_learning_rate: 0.0067
warmup_steps: 1386
Crea un segmento de Cloud Storage para que Neural Architecture Search almacene los resultados de tus trabajos (es decir, los puntos de control):
gcloud storage buckets create $GCS_ROOT_DIR
Crear un contenedor de entrenador y un contenedor de calculadora de latencia
El siguiente comando creará una imagen de entrenador en Google Cloud con el siguiente URI:
gcr.io/PROJECT_ID/TRAINER_DOCKER_ID, que se usará en la tarea de búsqueda de arquitectura neuronal en el siguiente paso.
python3 vertex_nas_cli.py build \
--project_id=PROJECT_ID \
--trainer_docker_id=TRAINER_DOCKER_ID \
--latency_calculator_docker_id=LATENCY_CALCULATOR_DOCKER_ID \
--trainer_docker_file=tf_vision/nas_multi_trial.Dockerfile \
--latency_calculator_docker_file=tf_vision/latency_computation_using_saved_model.Dockerfile
Para cambiar el espacio de búsqueda y la recompensa, actualízalos en tu archivo de Python y, a continuación, vuelve a compilar la imagen de Docker.
Probar el entrenador de forma local
Como se tarda varios minutos en lanzar un trabajo en el servicio Google Cloud , puede ser más cómodo probar el docker del entrenador de forma local, por ejemplo, validando el formato TFRecord. Si tomamos como ejemplo el spinenetespacio de búsqueda, puedes ejecutar el trabajo de búsqueda de forma local (el modelo se muestreará de forma aleatoria):
# Define the local job output dir.
JOB_DIR="/tmp/iod_${search_space}"
python3 vertex_nas_cli.py search_in_local \
--project_id=PROJECT_ID \
--trainer_docker_id=TRAINER_DOCKER_ID \
--prebuilt_search_space=spinenet \
--use_prebuilt_trainer=True \
--local_output_dir=${JOB_DIR} \
--search_docker_flags \
params_override="tf_vision/test_files/fast_nas_detection_spinenet_search_for_testing.yaml" \
training_data_path=TEST_COCO_TF_RECORD \
validation_data_path=TEST_COCO_TF_RECORD \
model=retinanet
training_data_path y validation_data_path son las rutas a tus TFRecords.
Lanza una búsqueda de la fase 1 seguida de un trabajo de entrenamiento de la fase 2 en Google Cloud
Consulta el notebook de clasificación de MnasNet y el notebook de detección de objetos de SpineNet para ver ejemplos completos.
Puedes definir las marcas
--max_parallel_nas_trialy--max_nas_trialpara personalizarlo. La búsqueda con arquitectura neuronal iniciarámax_parallel_nas_trialpruebas en paralelo y finalizará después demax_nas_trialpruebas.Si se define la marca
--target_device_latency_ms, se iniciará un trabajolatency calculatorindependiente con el acelerador especificado por la marca--target_device_type.El controlador de búsqueda con arquitectura neuronal proporcionará a cada prueba una sugerencia para un nuevo candidato de arquitectura a través de la marca
--nas_params_str.Cada prueba creará un gráfico basado en el valor de la marca
nas_params_stre iniciará una tarea de entrenamiento. Cada prueba también guarda su valor en un archivo JSON (enos.path.join(nas_job_dir, str(trial_id), "nas_params_str.json")).
Recompensa con una restricción de latencia
El notebook de clasificación de MnasNet muestra un ejemplo de búsqueda con restricciones de latencia basada en dispositivos de CPU en la nube.
Para buscar modelos con una restricción de latencia, el entrenador puede registrar la recompensa como una función de la precisión y la latencia.
En el código fuente compartido, la recompensa se calcula de la siguiente manera:
def compute_reward(target_latency, accuracy, inference_latency, weight=0.07):
"""Compute reward from accuracy and latency."""
speed_ratio = target_latency / inference_latency
return accuracy * (speed_ratio**weight)
Puedes usar otras variantes del cálculo de reward en la página 3 del documento de mnasnet.
target_device_typeespecifica el tipo de dispositivo de destino que se admite Google Cloud, comoNVIDIA_TESLA_P100.use_prebuilt_latency_calculatorusa nuestra calculadora de latencia precompiladatf_vision/latency_computation_using_saved_model.py.target_device_latency_msespecifica la latencia del dispositivo de destino.
Para obtener información sobre cómo personalizar la función de cálculo de la latencia, consulta tf_vision/latency_computation_using_saved_model.py.
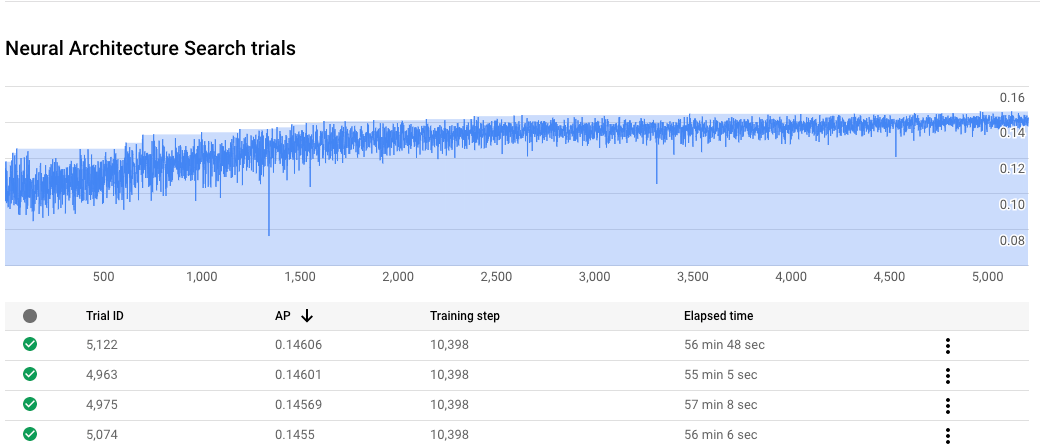
Monitorizar el progreso de un trabajo de búsqueda con arquitectura neuronal
En la Google Cloud consola, en la página del trabajo, el gráfico muestra la reward vs. trial number
mientras que la tabla muestra las recompensas de cada prueba. Puedes encontrar las pruebas principales con la recompensa más alta.
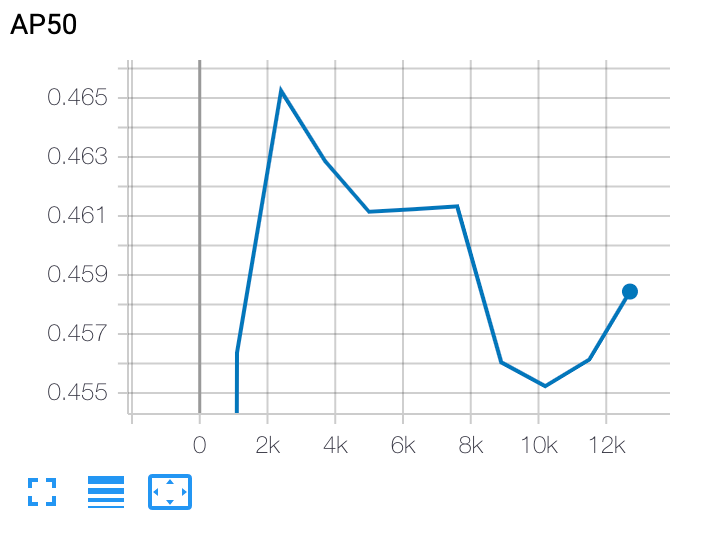
Trazar una curva de entrenamiento de la fase 2
Después del entrenamiento de la fase 2, puedes usar Cloud Shell o Google Cloud
TensorBoard para trazar la curva de entrenamiento indicando el directorio de la tarea:
Desplegar un modelo seleccionado
Para crear un SavedModel, puedes usar la secuencia de comandos export_saved_model.py con params_override=${GCS_ROOT_DIR}/${TRIAL_ID}/params.yaml.