이 가이드는 Google의 사전 빌드된 검색 공간과 MnasNet 및 SpineNet용 TF-Vision을 기반으로 사전 빌드된 트레이너 코드를 사용하여 Vertex AI 신경망 아키텍처 검색 작업을 실행하는 방법을 보여줍니다. 엔드 투 엔드 예시는 MnasNet 분류 노트북 및 SpineNet 객체 감지 노트북을 참고하세요.
사전 빌드된 트레이너를 위한 데이터 준비
신경망 아키텍처 검색 사전 빌드된 트레이너를 사용하려면 tf.train.Example을 포함하여 데이터가 TFRecord 형식이어야 합니다. tf.train.Example에는 다음 필드가 포함되어야 합니다.
'image/encoded': tf.FixedLenFeature(tf.string)
'image/height': tf.FixedLenFeature(tf.int64)
'image/width': tf.FixedLenFeature(tf.int64)
# For image classification only.
'image/class/label': tf.FixedLenFeature(tf.int64)
# For object detection only.
'image/object/bbox/xmin': tf.VarLenFeature(tf.float32)
'image/object/bbox/xmax': tf.VarLenFeature(tf.float32)
'image/object/bbox/ymin': tf.VarLenFeature(tf.float32)
'image/object/bbox/ymax': tf.VarLenFeature(tf.float32)
'image/object/class/label': tf.VarLenFeature(tf.int64)
여기에서 ImageNet 데이터 준비 안내를 따를 수 있습니다.
커스텀 데이터를 변환하려면 다운로드한 샘플 코드 및 유틸리티에 포함된 파싱 스크립트를 사용합니다. 데이터 파싱을 맞춤설정하려면 tf_vision/dataloaders/*_input.py 파일을 수정합니다.
TFRecord 및 tf.train.Example에 대해 자세히 알아보세요.
실험 환경 변수 정의
실험을 실행하기 전에 다음을 포함하여 몇 가지 환경 변수를 정의해야 합니다.
- TRAINER_DOCKER_ID:
${USER}_nas_experiment(권장 형식) 실험에 사용할 학습 및 검증 데이터 세트의 Cloud Storage 위치입니다. 예를 들면 다음과 같습니다(삭제의 경우 CoCo).
gs://cloud-samples-data/ai-platform/built-in/image/coco/train*gs://cloud-samples-data/ai-platform/built-in/image/coco/val*
실험 출력을 위한 Cloud Storage 위치입니다. 추천 형식:
gs://${USER}_nas_experiment
REGION: 실험 출력 버킷 리전과 동일한 리전입니다. 예를 들면
us-central1입니다.PARAM_OVERRIDE: 사전 빌드된 트레이너의 매개변수를 재정의하는 .yaml 파일입니다. 신경망 아키텍처 검색에서는 사용할 수 있는 몇 가지 기본 구성을 제공합니다.
PROJECT_ID=PROJECT_ID
TRAINER_DOCKER_ID=TRAINER_DOCKER_ID
LATENCY_CALCULATOR_DOCKER_ID=LATENCY_CALCULATOR_DOCKER_ID
GCS_ROOT_DIR=OUTPUT_DIR
REGION=REGION
PARAM_OVERRIDE=tf_vision/configs/experiments/spinenet_search_gpu.yaml
TRAINING_DATA_PATH=gs://PATH_TO_TRAINING_DATA
VALIDATION_DATA_PATH=gs://PATH_TO_VALIDATION_DATA
학습 요구사항에 맞는 재정의 파일을 선택하거나 수정할 수도 있습니다. 한 가지 예를 살펴보겠습니다.
--accelerator_type을 설정하여 GPU 또는 CPU 중에서 선택할 수 있습니다. CPU를 사용하여 빠른 테스트를 수행하기 위해 일부 에포크만 실행하려면--accelerator_type=""플래그를 설정하고tf_vision/test_files/fast_nas_detection_spinenet_search_for_testing.yaml구성 파일을 사용할 수 있습니다.- 에포크 수
- 학습 런타임
- 학습률과 같은 초매개변수
학습 작업을 제어하는 모든 매개변수 목록은 tf_vision/configs/를 참조하세요. 주요 매개변수는 다음과 같습니다.
task:
train_data:
global_batch_size: 80
validation_data:
global_batch_size: 16
init_checkpoint: null
trainer:
train_steps: 16634
steps_per_loop: 1386
optimizer_config:
learning_rate:
cosine:
initial_learning_rate: 0.16
decay_steps: 16634
type: 'cosine'
warmup:
type: 'linear'
linear:
warmup_learning_rate: 0.0067
warmup_steps: 1386
작업 출력을 저장할 신경망 아키텍처 검색을 위한 Cloud Storage 버킷을 만듭니다(예: 체크포인트).
gcloud storage buckets create $GCS_ROOT_DIR
트레이너 컨테이너 및 지연 시간 계산기 컨테이너 빌드
다음 명령어는 다음 단계의 신경망 아키텍처 검색 작업에서 사용되는 gcr.io/PROJECT_ID/TRAINER_DOCKER_ID URI를 사용하여 Google Cloud 에 트레이너 이미지를 빌드합니다.
python3 vertex_nas_cli.py build \
--project_id=PROJECT_ID \
--trainer_docker_id=TRAINER_DOCKER_ID \
--latency_calculator_docker_id=LATENCY_CALCULATOR_DOCKER_ID \
--trainer_docker_file=tf_vision/nas_multi_trial.Dockerfile \
--latency_calculator_docker_file=tf_vision/latency_computation_using_saved_model.Dockerfile
검색 공간 및 리워드를 변경하려면 Python 파일에서 이를 업데이트한 후 docker 이미지를 다시 빌드합니다.
트레이너를 로컬에서 테스트
Google Cloud 서비스에서 작업을 실행하는 데 몇 분 정도 걸리므로 TFRecord 형식 유효성 검사와 같이 트레이너 docker를 로컬에서 테스트하는 것이 더 편리할 수 있습니다. spinenet 검색 공간을 예시로 사용하고, 검색 작업을 로컬로 실행할 수 있습니다(모델이 무작위로 샘플링됨).
# Define the local job output dir.
JOB_DIR="/tmp/iod_${search_space}"
python3 vertex_nas_cli.py search_in_local \
--project_id=PROJECT_ID \
--trainer_docker_id=TRAINER_DOCKER_ID \
--prebuilt_search_space=spinenet \
--use_prebuilt_trainer=True \
--local_output_dir=${JOB_DIR} \
--search_docker_flags \
params_override="tf_vision/test_files/fast_nas_detection_spinenet_search_for_testing.yaml" \
training_data_path=TEST_COCO_TF_RECORD \
validation_data_path=TEST_COCO_TF_RECORD \
model=retinanet
training_data_path 및 validation_data_path는 TFRecords의 경로입니다.
Google Cloud에서 stage-1 검색 후 stage-2 학습 작업 실행
엔드 투 엔드 예시는 MnasNet 분류 노트북 및 SpineNet 객체 감지 노트북을 참조하세요.
--max_parallel_nas_trial및--max_nas_trial플래그를 설정해서 맞춤설정할 수 있습니다. 신경망 아키텍처 검색은max_parallel_nas_trial시도를 병렬로 시작하고max_nas_trial시도 후 완료됩니다.--target_device_latency_ms플래그가 설정된 경우--target_device_type플래그로 지정된 가속기를 사용하여latency calculator작업이 실행됩니다.Neural Architecture Search 컨트롤러는
--nas_params_str플래그를 통해 새 아키텍처 후보에 대한 권장항목을 각 시도에 제공합니다.각 시도는
nas_params_str플래그의 값을 기반으로 그래프를 빌드하고 학습 작업을 시작합니다. 각 시도는 값을 json 파일(os.path.join(nas_job_dir, str(trial_id), "nas_params_str.json"))에 저장합니다.
지연 시간 제약조건이 있는 리워드
MnasNet 분류 노트북은 클라우드 CPU 기기 기반 지연 시간이 제한된 검색의 예시를 보여줍니다.
지연 시간 제약조건을 사용하여 모델을 검색하려면 트레이너가 정확도 및 지연 시간의 함수로 리워드를 보고할 수 있습니다.
공유 소스 코드에서 리워드는 다음과 같이 계산됩니다.
def compute_reward(target_latency, accuracy, inference_latency, weight=0.07):
"""Compute reward from accuracy and latency."""
speed_ratio = target_latency / inference_latency
return accuracy * (speed_ratio**weight)
mnasnet 자료의 3페이지에서 reward 계산의 다른 변형을 사용할 수 있습니다.
target_device_type은NVIDIA_TESLA_P100와 같이 Google Cloud에서 지원되는 대상 기기 유형을 지정합니다.use_prebuilt_latency_calculator는 사전 정의된 지연 시간 계산기tf_vision/latency_computation_using_saved_model.py를 사용합니다.target_device_latency_ms는 대상 기기 지연 시간을 지정합니다.
지연 시간 계산 함수를 맞춤설정하는 방법은 tf_vision/latency_computation_using_saved_model.py를 참조하세요.
신경망 아키텍처 검색 작업 진행 상황 모니터링
Google Cloud Console 작업 페이지의 차트에는 reward vs. trial number가 표시되고 테이블에는 각 시도에 대한 보상이 표시됩니다. 리워드가 가장 높은 최상위 시도를 찾을 수 있습니다.
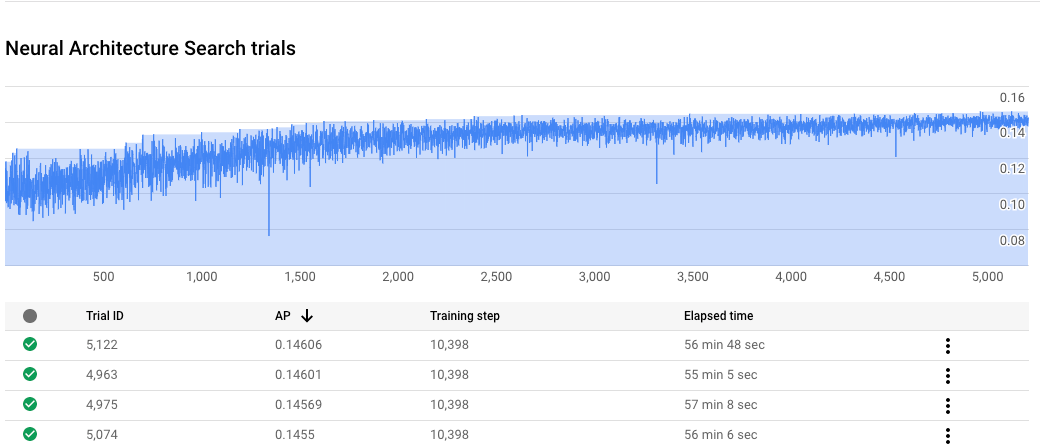
stage-2 학습 곡선 표시
stage-2 학습 후에는 Cloud Shell 또는 Google CloudTensorBoard를 사용하여 작업 디렉터리를 가리키고 학습 곡선을 표시합니다.
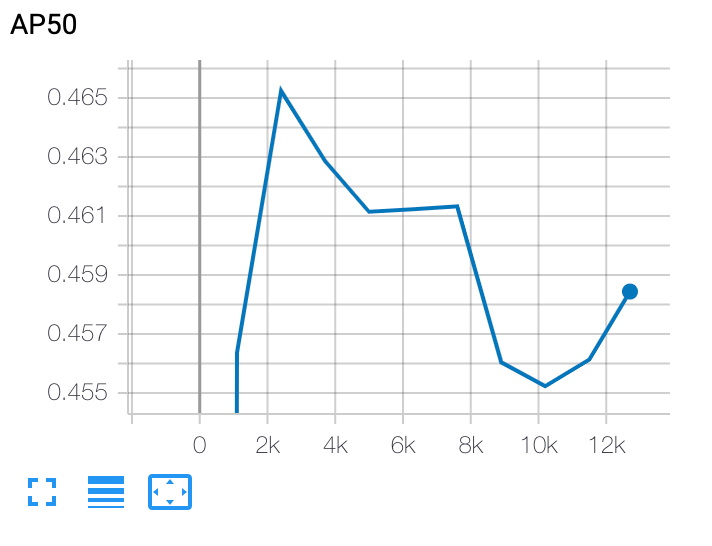
선택한 모델 배포
SavedModel을 만들려면 export_saved_model.py 스크립트를 params_override=${GCS_ROOT_DIR}/${TRIAL_ID}/params.yaml과 함께 사용할 수 있습니다.