Mit Vertex AI Neural Architecture Search können Sie nach optimalen neuronalen Architekturen im Hinblick auf Genauigkeit, Latenz, Arbeitsspeicher, einer Kombination aus diesen oder einen benutzerdefinierten Messwert suchen.
Herausfinden, ob Vertex AI Neural Architecture Search das beste Tool für mich ist
- Vertex AI Neural Architecture Search ist ein hochentwickeltes Optimierungstool, mit dem Sie die besten neuronalen Architekturen im Hinblick auf Genauigkeit mit oder ohne Einschränkungen wie Latenz, Arbeitsspeicher oder einem benutzerdefinierten Messwert finden. Der Suchbereich kann bei möglichen neuronalen Architekturoptionen bis zu 10^20 betragen. Die Funktion basiert auf einer Technik, mit der in den letzten Jahren erfolgreich einige Modelle für maschinelles Sehen erzeugt wurden, darunter:Nasnet, Logo: MNasnet, EfficientNet, NAS-FPN und SpineNet.
- Die Neural Architecture Search ist keine Lösung, bei der Sie einfach Ihre Daten übertragen und ein gutes Ergebnis ohne vorherige Experimente erwarten können. Es ist ein Tool, mit dem Sie experimentieren müssen.
- Die Neural Architecture Search eignet sich nicht für die Hyperparameter-Abstimmung, wie sie z. B. zum Optimieren der Lernrate oder zur Optimierung von Einstellungen verwendet wird. Sie ist nur für Architektursuchen gedacht. Die Hyperparameterabstimmung sollte nicht mit der Neural Architecture Search kombiniert werden.
- Die Neural Architecture Search wird für begrenzte Trainingsdaten oder für sehr unausgewogene Datasets nicht empfohlen, bei denen einige Klassen sehr selten sind. Wenn Sie aufgrund fehlender Daten bereits starke Erweiterungen für Ihr Basistraining verwenden, wird die Neural Architecture Search nicht empfohlen.
- Sie sollten zuerst andere traditionelle und konventionelle Methoden und Techniken des maschinellen Lernens wie die Hyperparameterabstimmung ausprobieren. Sie sollten die Neural Architecture Search nur verwenden, wenn diese herkömmlichen Methoden Ihnen nicht mehr helfen können.
- Sie sollten ein internes Team für die Modelloptimierung haben, das einige grundlegende Kenntnisse über Architekturparameter hat, um die Suche zu bearbeiten und Versuche anzustellen. Diese Architekturparameter können unter anderem die Kernel-Größe, die Anzahl der Kanäle oder der Verbindungen umfassen. Wenn Sie einen Suchbereich entdecken möchten, ist die Neural Architecture Search sehr wertvoll und kann die Zeit der Erkundung eines großen Suchbereich mit bis zu 10^20 Architekturoptionen um mindestens sechs Monate verkürzen.
- Die Neural Architecture Search ist für Unternehmenskunden gedacht, die mehrere tausend Dollar für einen Test ausgeben können.
- Die Neural Architecture Search ist nicht auf Vision-Anwendungsfälle beschränkt. Derzeit werden nur Vision-basierte vorgefertigte Suchbereiche und vordefinierte Trainer bereitgestellt. Kunden können aber auch eigene nicht-Vision-basierte Suchbereiche und Trainer verwenden.
- Neural Architecture Search verwendet keinen Supernet-Ansatz (Oneshot-NAS oder auf gewichteten Freigaben basiertes NAS), bei dem Sie nur Ihre eigenen Daten verwenden und sie als Lösung verwenden. Es ist nicht einfach, ein Supernet anzupassen (dies benötigt Monate). Im Gegensatz zu einem Supernet können Sie mit Neural Architecture Search sehr tief anpassbare Suchbereiche und Prämien definieren. Anpassungen können in ein bis zwei Tagen durchgeführt werden.
- Neural Architecture Search wird in acht Regionen weltweit unterstützt. Prüfen Sie die Verfügbarkeit in Ihrer Region.
Außerdem sollten Sie folgenden Abschnitt zu den erwarteten Kosten, den möglichen Ergebnissen und GPU-Kontingentanforderungen lesen, bevor Sie die Neural Architecture Search verwenden.
Erwartete Kosten, Ergebnisse und GPU-Kontingentanforderungen
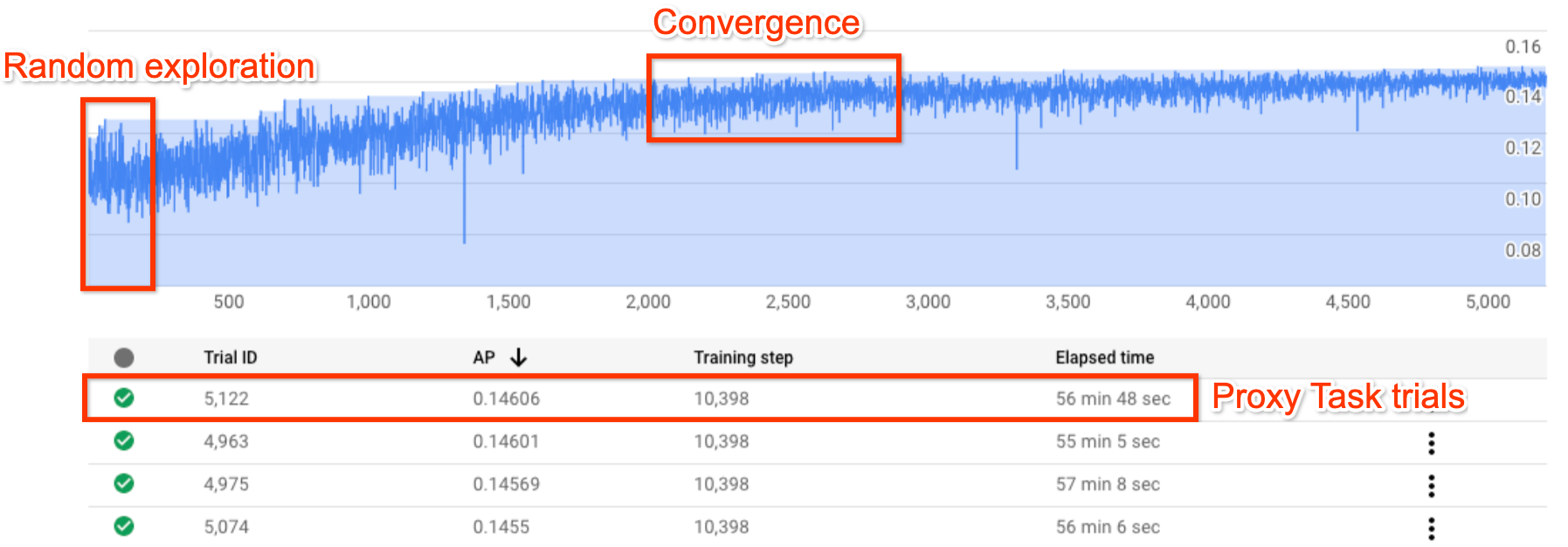
Die Abbildung zeigt eine typische Kurve der Neural Architecture Search.
Y-axis zeigt die Testprämien und X-axis die Anzahl der gestarteten Tests an.
Wenn die Anzahl der Tests zunimmt, beginnt der Controller mit der Suche nach besseren Modellen. Daher erhöht sich die Prämie. Später nimmt die Varianz der Prämie und das Prämienwachstum ab und zeigt die Konvergenz. Zur Zeit der Konvergenz kann die Anzahl der Tests je nach Größe des Suchbereichs variieren. Sie beträgt jedoch immer etwa 2.000 Tests.
Jeder Test wurde als kleinere Version eines vollständigen Trainings namens proxy-task entworfen, das etwa ein bis zwei Stunden auf zwei Nvidia V100-GPUs ausgeführt wird. Der Kunde kann die Suche jederzeit manuell beenden und höhere Prämienmodelle im Vergleich zu seiner Referenz finden, bevor der Punkt der Konvergenz auftritt.
Es kann besser sein, bis zum Punkt der Konvergenz zu warten, um besseren Ergebnisse wählen zu können.
Nach der Suche besteht die nächste Phase darin, die 10 besten Tests (Modelle) auszuwählen und ein vollständiges Training durchzuführen.
(Optional) Testlauf des vordefinierten MNasNet-Suchbereichs und Trainers
In diesem Modus können Sie die Suchkurve oder einige Tests (ca. 25) beobachten und einen Testlauf mit einem vordefinierten MNasNet-Suchbereich und -Trainer durchführen.
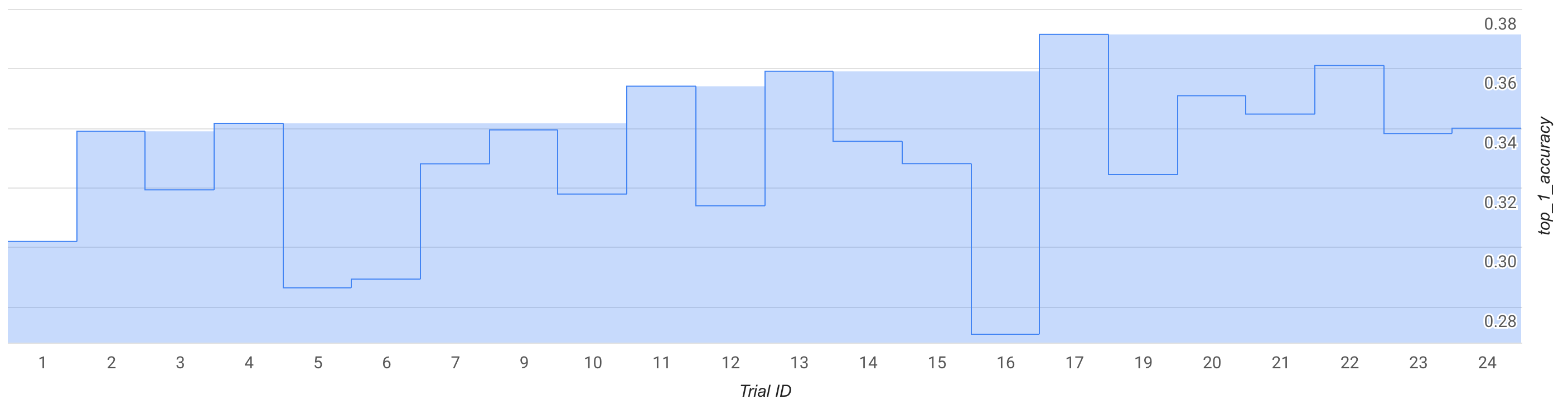
In der Abbildung erhöht sich die beste Phase-1-Prämie von ~0,30 bei Test-1 auf ~0,37 bei Test-17. Ihre genaue Ausführung kann aufgrund der zufälligen Stichprobenerfassung etwas anders aussehen, Sie sollten aber einen geringfügigen Anstieg bei der besten Prämie feststellen. Beachten Sie, dass dies immer noch ein Spiellauf ist und weder ein Proof of Concept noch eine öffentliche Benchmarkvalidierung.
Die Kosten für diesen Lauf sind wie folgt aufgeschlüsselt:
- Phase-1:
- Anzahl der Versuche: 25
- Anzahl der GPUs pro Test: 2
- GPU-Typ: TESLA_T4
- Anzahl der CPUs pro Test: 1
- CPU-Typ: n1-highmem-16
- Durchschnittliche Trainingszeit einer einzelnen Testversion: 3 Stunden
- Anzahl paralleler Tests: 6
- Verwendetes GPU-Kontingent: (Anzahl der GPUs pro Test * Anzahl der parallelen Test) = 12 GPUs. Verwenden Sie für die Testfahrt die Region us-central1 und hosten Sie die Trainingsdaten in derselben Region. Kein zusätzliches Kontingent erforderlich.
- Ausführungsdauer: (Gesamtzahl der Tests * Trainingszeit pro Test)/(Anzahl der parallelen Tests) = 12 Stunden
- GPU-Stunden: (Gesamtzahl der Tests * Trainingszeit pro Test * Anzahl der GPUs pro Test) = 150 T4-GPU-Stunden
- CPU-Stunden: (Gesamtzahl der Tests * Trainingszeit pro Test * Anzahl der GPUs pro Test) = 75 n1-highmem-16 Stunden
- Kosten: ca. 185 $. Sie können den Job früher beenden, um die Kosten zu senken. Auf der Preisseite können Sie den genauen Preis berechnen.
Da dies ein Spiellauf ist, ist es nicht erforderlich, ein vollständiges Phase-2-Training für Phase-1-Modelle auszuführen. Weitere Informationen zur Ausführung von Phase-2 finden Sie in Anleitung 3.
Für diesen Durchlauf wird das MnasNet-Notebook verwendet.
(Optional) PoC-Lauf (Proof of Concept) des vordefinierten MNasNet-Suchbereichs und Trainers
Wenn Sie ein veröffentlichtes MNasnet-Ergebnis annähernd replizieren möchten, können Sie diesen Modus verwenden. Laut dem Paper erreicht MnasNet eine Top-1-Genauigkeit von 75,2 % mit einer Latenz von 78 ms auf einem Pixelfone, das 1,8-mal schneller als das MobileNetV2 (Genauigkeit um 0,5 % höher) und 2,3-mal schneller als das NASNet (Genauigkeit um 1,2 % höher) ist. In diesem Beispiel werden jedoch GPUs statt TPUs für das Training verwendet und es wird eine Cloud-CPU (n1-highmem-8) zur Bewertung der Latenz verwendet. In diesem Beispiel beträgt die erwartete Phase2-Top-1-Genauigkeit für MNasNet 75,2 % mit einer Latenz von 50 ms auf der Cloud-CPU (n1-highmem-8).
Die Kosten für diesen Lauf sind wie folgt aufgeschlüsselt:
Phase-1-Suche:
- Anzahl der Versuche: 2.000
- Anzahl der GPUs pro Test: 2
- GPU-Typ: TESLA_T4
- Durchschnittliche Trainingszeit einer einzelnen Testversion: 3 Stunden
- Anzahl paralleler Tests: 10
- Verwendetes GPU-Kontingent: (Anzahl der GPUs pro Test * Anzahl der parallelen Test) = 20 T4-GPUs. Da diese Zahl das Standardkontingent übersteigt, müssen Sie über Ihre Projekt-UI eine Kontingentanfrage erstellen. Weitere Informationen finden Sie unter setting_up_path.
- Ausführungsdauer (Gesamtzahl der Tests * Trainingszeit pro Test)/(Anzahl der parallelen Test)/24 = 25 Tage. Hinweis: Der Job wird nach 14 Tagen beendet. Anschließend können Sie den Suchjob einfach mit einem Befehl weitere 14 Tage fortsetzen. Bei einem höheren GPU-Kontingent verkürzt sich die Laufzeit entsprechend.
- GPU-Stunden: (Gesamtzahl der Tests * Trainingszeit pro Test * Anzahl der GPUs pro Test) = 12.000 T4-GPU-Stunden.
- Kosten: ~15.000 $
Vollständiges Phase-2-Training mit den Top-10-Modellen:
- Anzahl der Versuche: 10
- Anzahl der GPUs pro Test: 4
- GPU-Typ: TESLA_T4
- Durchschnittliche Trainingszeit einer einzelnen Testversion: ~9 Tage
- Anzahl paralleler Tests: 10
- Verwendetes GPU-Kontingent: (Anzahl der GPUs pro Test * Anzahl der parallelen Test) = 40 T4-GPUs. Da diese Zahl das Standardkontingent übersteigt, müssen Sie über Ihre Projekt-UI eine Kontingentanfrage erstellen. Weitere Informationen finden Sie unter setting_up_path. Sie können diesen Job auch mit 20 T4-GPUs ausführen. Führen Sie dazu den Job zweimal mit je fünf Modellen aus, anstatt alle 10 Parallele zu verwenden.
- Ausführungsdauer (Gesamtzahl der Tests * Trainingszeit pro Test)/(Anzahl der parallelen Test)/24 = ~9 Tage.
- GPU-Stunden: (Gesamtzahl der Tests * Trainingszeit pro Test * Anzahl der GPUs pro Test) = 8.960 T4-GPU-Stunden.
- Kosten: ~8.000 $
Gesamtkosten: Etwa 23.000 $. Den genauen Preis können Sie auf der Preisseite berechnen. Hinweis: Dieses Beispiel ist kein durchschnittlicher regulärer Trainingsjob. Das vollständige Training benötigt ungefähr neun Tage auf vier TESLA_T4-GPUs.
Für diesen Durchlauf wird das MnasNet-Notebook verwendet.
Suchbereich und Trainer verwenden
Wir geben einen ungefähren Preis für einen durchschnittlichen benutzerdefinierten Nutzer an. Ihre Anforderungen können je nach Trainingsaufgabe, GPUs und CPUs variieren. Für einen End-to-End-Lauf benötigen Sie ein Kontingent von mindestens 20 GPUs, wie hier beschrieben. Hinweis: Der Leistungsgewinn hängt ganz von Ihrer Aufgabe ab. Wir können nur Beispiele wie MNasnet als Referenzbeispiele für Leistungssteigerungen angeben.
Die Kosten für diese hypothetische benutzerdefinierte Ausführung werden so aufgeschlüsselt:
Phase-1-Suche:
- Anzahl der Versuche: 2.000
- Anzahl der GPUs pro Test: 2
- GPU-Typ: TESLA_T4
- Durchschnittliche Trainingszeit einer einzelnen Testversion: 1,5 Stunden
- Anzahl paralleler Tests: 10
- Verwendetes GPU-Kontingent: (Anzahl der GPUs pro Test * Anzahl der parallelen Test) = 20 T4-GPUs. Da diese Zahl das Standardkontingent übersteigt, müssen Sie über Ihre Projekt-UI eine Kontingentanfrage erstellen. Weitere Informationen finden Sie unter Zusätzliche Gerätekontingente für das Projekt anfordern.
- Ausführungsdauer (Gesamtzahl der Tests * Trainingszeit pro Test)/(Anzahl der parallelen Test)/24 = 12,5 Tage.
- GPU-Stunden: (Gesamtzahl der Tests * Trainingszeit pro Test * Anzahl der GPUs pro Test) = 6.000 T4-GPU-Stunden.
- Kosten: ca. 7.400 $
Vollständiges Phase-2-Training mit den Top-10-Modellen:
- Anzahl der Versuche: 10
- Anzahl der GPUs pro Test: 2
- GPU-Typ: TESLA_T4
- Durchschnittliche Trainingszeit einer einzelnen Testversion: etwa 4 Tage
- Anzahl paralleler Tests: 10
- Verwendetes GPU-Kontingent: (Anzahl der GPUs pro Test * Anzahl der parallelen Test) = 20 T4-GPUs. **Da diese Zahl das Standardkontingent übersteigt, müssen Sie über Ihre Projekt-UI eine Kontingentanfrage erstellen. Weitere Informationen finden Sie unter Zusätzliche Gerätekontingente für das Projekt anfordern. Informationen zu benutzerdefinierten Kontingentanforderungen finden Sie in derselben Dokumentation.
- Ausführungszeit: (Gesamtzahl der Tests * Trainingszeit pro Test)/(Anzahl paralleler Tests)/24 = etwa 4 Tage
- GPU-Stunden: (Gesamtzahl der Tests * Trainingszeit pro Test * Anzahl der GPUs pro Test) = 1.920 T4-GPU-Stunden.
- Kosten: ca. 2.400 $
Weitere Informationen zu den Designkosten für Proxy-Aufgaben finden Sie unter Design der Proxy-Aufgabe. Die Kosten ähneln dem Training für 12 Modelle (Phase-2 in der Abbildung verwendet 10 Modelle):
- Verwendetes GPU-Kontingent: Wie bei der Phase 2-Ausführung in der Abbildung.
- Kosten: (12/10) * Phase-2 Kosten für 10 Modelle = ~2.880 $
Gesamtkosten: ca. 12.680 $. Den genauen Preis können Sie auf der Preisseite berechnen.
Diese Phase-1-Suchkosten gelten für die Suche bis zum Erreichen des Konvergenzpunkts und für eine maximale Leistungssteigerung. Warten Sie jedoch nicht, bis die Suche konvergiert. Sie können einen geringeren Leistungsanstieg bei geringeren Suchkosten erwarten, wenn Sie das vollständige Phase 2-Training mit dem bisher besten Modell ausführen, falls die Suchkurve angestiegen ist. Beispiel: Warten Sie für das zuvor angezeigte Suchdiagramm nicht, bis die 2.000 Tests für die Konvergenz erreicht wurden. Möglicherweise haben Sie mit 700 oder 1.200 Tests bessere Modelle gefunden und können für diese ein vollständiges Phase 2-Training ausführen. Sie können die Suche jederzeit beenden, um die Kosten zu senken. Sie können auch ein vollständige Phase 2-Training parallel ausführen, während die Suche ausgeführt wird. Achten Sie jedoch darauf, dass Sie ein GPU-Kontingent haben, das einen zusätzlichen parallelen Job unterstützt.
Zusammenfassung: Leistung und Kosten
In der folgenden Tabelle sind einige Datenpunkte mit unterschiedlichen Anwendungsfällen sowie der jeweiligen Leistung und der Kosten zusammengefasst.
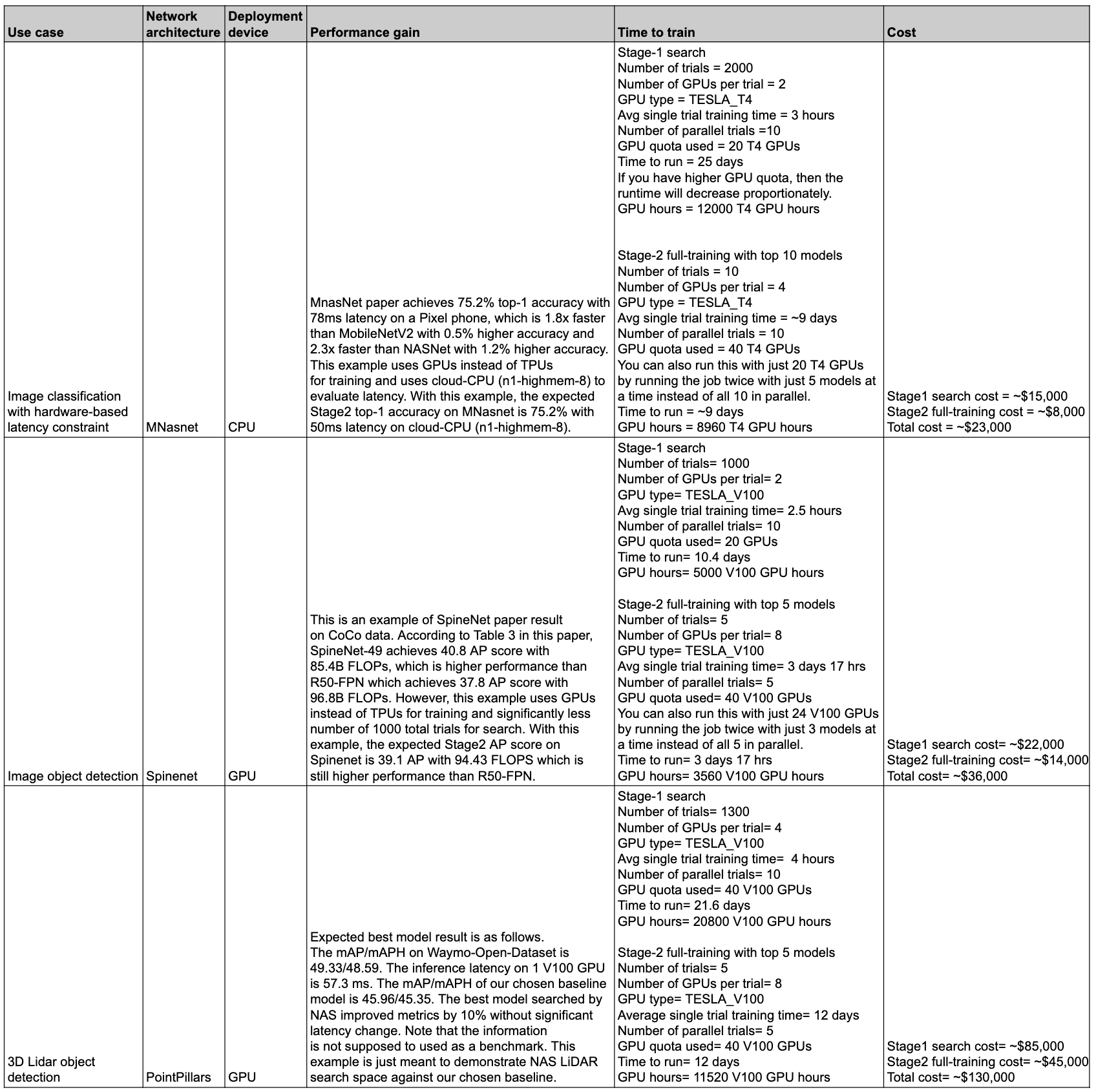
Anwendungsfälle und Features
Die Features der Neural Architecture Search sind sowohl flexibel als auch nutzerfreundlich. Einsteiger können mit vordefinierten Suchbereichen, vordefinierten Trainern und einem Notebook ohne weiteres Einrichten beginnen, Vertex AI Neural Architecture Search für ihr Dataset zu verwenden. Gleichzeitig kann ein Experte Neural Architecture Search mit seinem benutzerdefinierten Trainer, seinem benutzerdefinierten Suchbereich und seinem benutzerdefinierten Inferenzgerät verwenden und sogar die Architektursuche für nicht optische Anwendungsfälle erweitern.
Neural Architecture Search bietet vordefinierte Trainer und Suchbereiche, die auf GPUs für folgende Anwendungsfälle ausgeführt werden können:
- TensorFlow-Trainer mit öffentlichen Dataset-basierten Ergebnissen, die in einem Notebook veröffentlicht wurden
- PyTorch-Trainer, die nur als Beispiel für die Anleitung verwendet werden dürfen
- Beispiel für einen Suchbereich für die medizinische PyDrch-3D-Bildsegmentierung
- PyTorch-basierte MNasNet-Klassifizierung
- Latenz- und speicherbeschränkte Suche für Zielgeräte
- Zusätzliche TensorFlow-basierte, vordefinierte moderne Suchbereiche mit Code
- Modellskalierung
- Datenerweiterung
Die vollständige Funktion der Neural Architecture Search kann auch für benutzerdefinierte Architekturen und Anwendungsfälle verwendet werden:
- Eine Neural Architecture Search-Sprache, um einen benutzerdefinierten Suchbereich für mögliche neuronale Architekturen zu definieren und diesen Suchbereich in benutzerdefinierten Trainercode einzubinden.
- Einsatzbereite vordefinierte Suchbereiche mit Code.
- Sofort einsatzbereiter Trainer mit Code, der auf einer GPU ausgeführt wird.
- Ein verwalteter Dienst für die Architektursuche, einschließlich
- Ein Neural Architecture Search-Controller, der den Suchbereich durchsucht, um die beste Architektur zu finden.
- Vordefinierte Docker/Bibliotheken mit Code zum Berechnen von Latenz/FLOPs/Arbeitsspeicher auf benutzerdefinierter Hardware.
- Anleitungen zur NAS-Nutzung
- Eine Reihe von Tools zum Entwerfen von Proxyaufgaben.
- Hinweise und Beispiel für ein effizientes PyTorch-Training mit Vertex AI.
- Bibliotheksunterstützung für die Berichterstellung und Analyse von benutzerdefinierten Messwerten
- Google Cloud Console-UI zum Überwachen und Verwalten von Jobs.
- Nutzerfreundliche Notebooks zum Starten der Suche
- Bibliotheksunterstützung für die Verwaltung der GPU-/CPU-Ressourcennutzung auf Projekt- oder Jobebene.
- Python-basierter Nas-Client zum Erstellen von Dockers, zum Starten von NAS-Jobs und zum Fortsetzen eines vorherigen Suchjobs.
- Google Cloud -basierter Kundensupport.
Hintergrund
Die Neural Architecture Search ist eine Technik zur Automatisierung der Entwicklung neuronaler Netzwerke. Sie hat in den letzten Jahren erfolgreich einige Modelle für maschinelles Sehen erzeugt, darunter:
Die resultierenden Modelle sind bei allen drei Klassen von Problemen mit maschinellem Sehen führend: Bildklassifizierung, Objekterkennung und Segmentierung.
Mit Neural Architecture Search können Entwickler Modelle im selben Test auf Genauigkeit, Latenz und Arbeitsspeicher optimieren und so die Zeit für die Bereitstellung von Modellen reduzieren. Neural Architecture Search untersucht viele verschiedene Arten von Modellen: Der Controller schlägt ML-Modelle vor, trainiert und bewertet die Modelle und iteriert 1000 Mal, um die besten Lösungen mit Latenz- und/oder Arbeitsspeicherbeschränkungen auf den Zielgeräten zu finden. Die folgende Abbildung zeigt die Schlüsselkomponenten des Architecture Search-Frameworks:
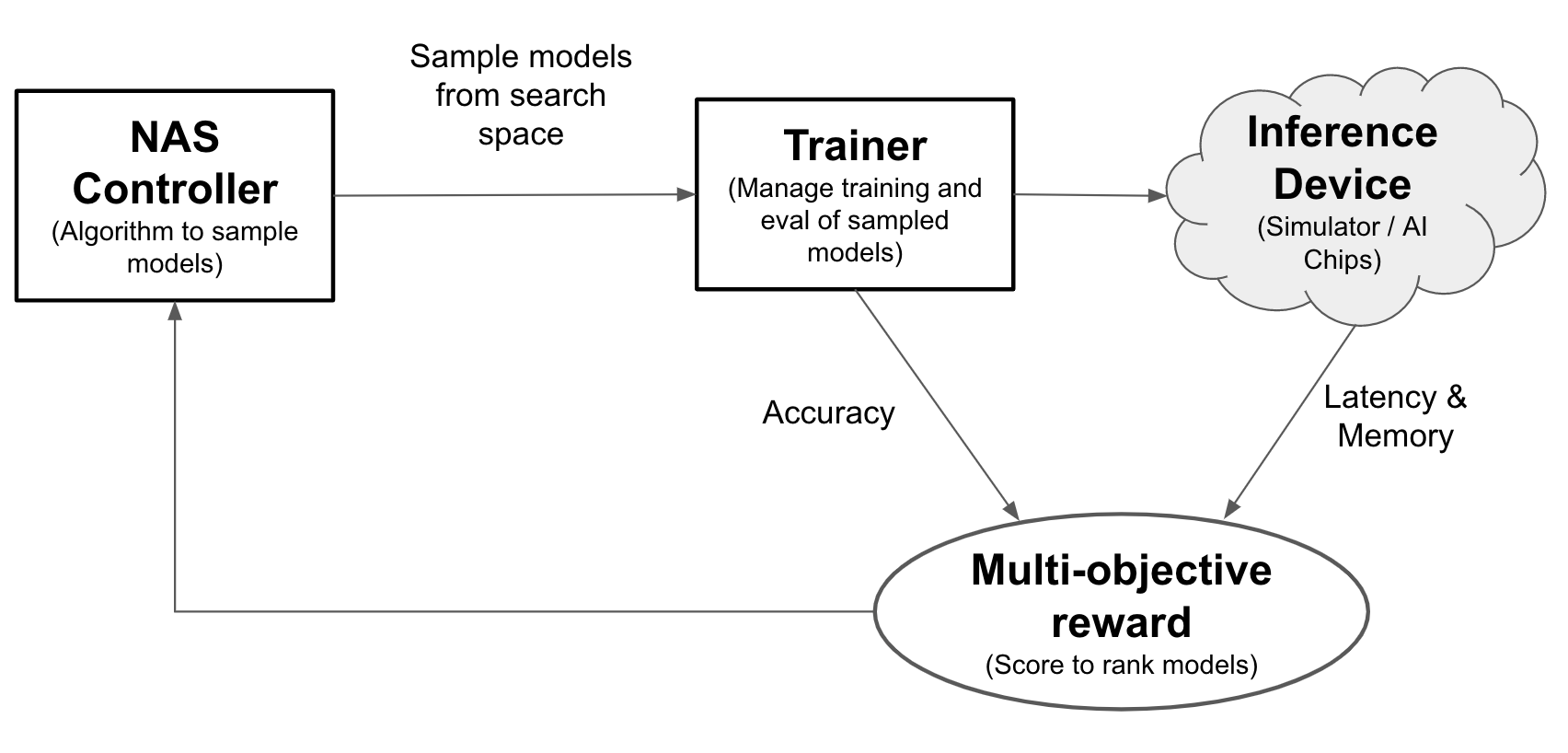
- Modell: Eine neuronale Architektur mit Vorgängen und Verbindungen.
- Suchbereich: Der Bereich möglicher Modelle (Vorgänge und Verbindungen), die entworfen und optimiert werden können.
- Trainer-Docker: Vom Nutzer anpassbarer Trainercode zum Trainieren und Bewerten eines Modells und zur Berechnung der Genauigkeit des Modells.
- Inferenzgerät: Ein Hardwaregerät wie CPU/GPU, auf dem die Modelllatenz und die Speichernutzung berechnet werden.
- Prämie: Eine Kombination aus Modellmesswerten wie der Genauigkeit, Latenz, Speicher, die zum Ranking der Modelle als besser oder schlechter verwendet wird.
- Neural Architecture Search Controller: Der Orchestrierungsalgorithmus, der (a) die Modelle aus dem Suchbereich stichprobenweise prüft, (b) die Modellprämien empfängt und (c) den nächsten Satz von Modellvorschlägen zur Bewertung bereitstellt, um die optimalen Modelle zu finden.
Aufgaben zur Nutzereinrichtung
Neural Architecture Search bietet vorgefertigte Trainer, die in vorgefertigte Suchbereiche integriert sind und mit den bereitgestellten Notebooks ohne weitere Einstellungen verwendet werden können.
Die meisten Nutzer müssen jedoch ihre benutzerdefinierten Trainer, benutzerdefinierten Suchbereiche, benutzerdefinierte Messwerte (z. B. Speicher, Latenz und Trainingszeit) und benutzerdefinierte Prämien (Kombination aus Genauigkeit und Latenz) verwenden. Gehen Sie dazu so vor:
- Definieren Sie einen benutzerdefinierten Suchbereich mit der bereitgestellten Neural Architecture Search-Sprache.
- Binden Sie die Suchbereichsdefinition in den Trainercode ein:
- Fügen Sie dem Trainercode benutzerdefinierte Messwerte hinzu.
- Fügen Sie dem Trainercode eine benutzerdefinierte Prämie hinzu.
- Erstellen Sie einen Trainingscontainer und verwenden Sie ihn, um Neural Architecture Search-Jobs zu starten.
Dies wird im folgenden Diagramm veranschaulicht:
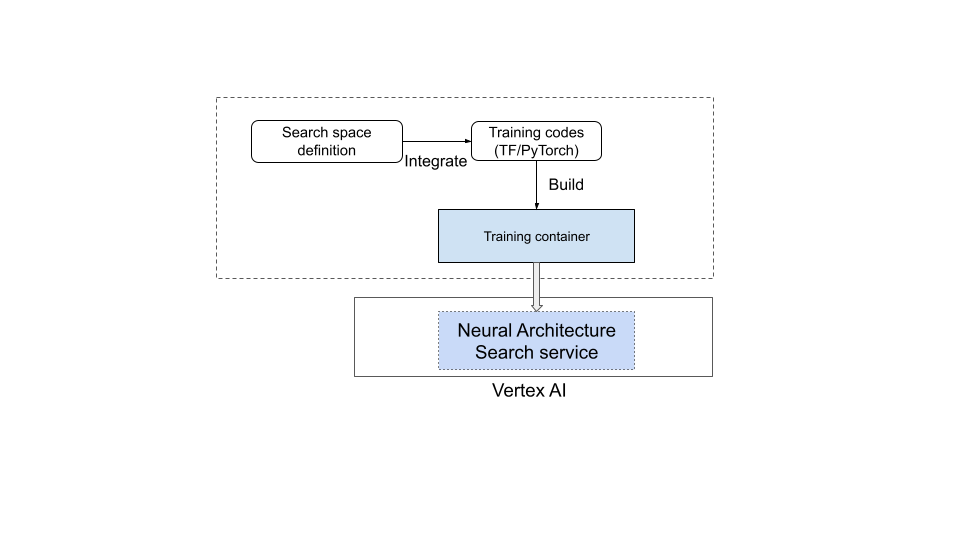
Neural Architecture Search-Dienst in Betrieb
Nachdem Sie den zu verwendenden Trainingscontainer eingerichtet haben, startet der Neural Architecture Search-Dienst mehrere Trainingscontainer parallel auf mehreren GPU-Geräten. Sie können festlegen, wie viele Tests parallel für das Training verwendet und wie viele Tests insgesamt gestartet werden sollen. Jedem Trainingscontainer wird eine vorgeschlagene Architektur aus dem Suchbereich bereitgestellt. Der Trainingscontainer erstellt das vorgeschlagene Modell, trainiert es und wertet es aus und meldet dann Prämien an den Neural Architecture Search-Dienst. Im Laufe dieses Prozesses verwendet der Neural Architecture Search-Dienst das Prämienfeedback, um bessere und bessere Modellarchitekturen zu finden. Nach der Suche haben Sie Zugriff auf die gemeldeten Messwerte zur weiteren Analyse.
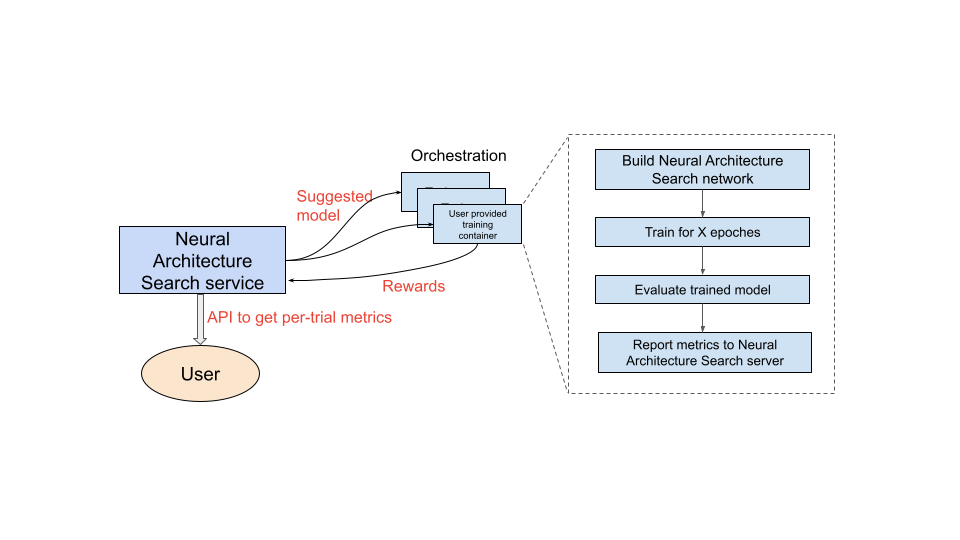
Überblick über die Verwendung von Neural Architecture Search
Die wichtigsten Schritte für die Durchführung eines Neural Architecture Search-Experiments sind die folgenden:
Einrichtung und Definitionen:
- Identifizieren Sie das mit Labels versehene Dataset und geben Sie den Aufgabentyp an, z. B. Erkennung oder Segmentierung.
- Trainercode anpassen:
- Verwenden Sie einen vordefinierten Suchbereich oder definieren Sie einen benutzerdefinierten Suchbereich mithilfe der Neural Architecture Search-Sprache.
- Binden Sie die Suchbereichsdefinition in den Trainercode ein:
- Fügen Sie dem Trainercode benutzerdefinierte Messwerte hinzu.
- Fügen Sie dem Trainercode eine benutzerdefinierte Prämie hinzu.
- Erstellen Sie einen Trainercontainer.
- Richten Sie Suchtestparameter für Teiltrainings (Proxyaufgabe) ein. Das Suchtraining sollte idealerweise schnell abgeschlossen sein (z. B. in 30 bis 60 Minuten), um die Modelle teilweise zu trainieren:
- Mindestepochen, die für die Erfassung von Modellstichproben erforderlich sind, um Prämien zu sammeln (die Mindestepochen müssen eine Modellkonvergenz nicht gewährleisten).
- Hyperparameter (z. B. Lernrate).
Führen Sie die Suche lokal aus, um sicherzustellen, dass der integrierte Suchbereich-Container ordnungsgemäß ausgeführt werden kann.
Starten Sie den Google Cloud Suchjob (Phase 1) mit fünf Tests und prüfen Sie, ob die Suchtests die Ziele hinsichtlich Laufzeit und Genauigkeit erfüllen.
Starten Sie den Google Cloud Search-Job (Phase 1) mit mehr als 1.000 Tests.
Legen Sie im Rahmen der Suche auch ein reguläres Intervall fest, um die besten N Modelle zu trainieren (stage-2):
- Hyperparameter und Algorithmus für die Hyperparameter-Suche. Stage-2 verwendet in der Regel die ähnliche Konfiguration wie stage-1, aber mit höheren Einstellungen für bestimmte Parameter wie Trainingsschritte/Epochen und Anzahl der Kanäle.
- Stoppkriterien (Anzahl der Epochen).
Analysieren Sie die gemeldeten Messwerte und/oder visualisieren Sie die Architekturen, um Informationen zu erhalten.
Auf ein Experiment zur Architektursuche kann ein Skalierungssuchtest, gefolgt von einem Erweiterungssuchtest, folgen.
Leserichtung der Dokumentation
- (Erforderlich) Umgebung einrichten
- (Erforderlich) Anleitungen
- (Nur für PyTorch-Kunden erforderlich) PyTorch: effizientes Training mit Cloud-Daten
- (Erforderlich) Best Practices und Vorschläge für den Workflow
- (Erforderlich) Proxy-Aufgabendesign
- (Nur erforderlich, wenn vordefinierte Trainer verwendet werden) Vordefinierte Suchbereiche und einen vordefinierten Trainer verwenden
Verweise
- Mit maschinellem Lernen Neural Network Architecture entdecken
- MnasNet: Zur Automatisierung des Designs von Modellen für mobiles maschinelles Lernen
- EfficientNet: Genauigkeit und Effizienz durch AutoML und Modellskalierung verbessern
- NAS-FPN: Lernen Sie die Architektur der skalierbaren Feature-Pyramide für die Objekterkennung
- SpineNet: Lernen Sie das skalenbasierte Backbone für Erkennung und Lokalisierung
- RandAugment