With Vertex AI Neural Architecture Search, you can search for optimal neural architectures in terms of accuracy, latency, memory, a combination of these, or a custom metric.
Determine whether Vertex AI Neural Architecture Search is the best tool for me
- Vertex AI Neural Architecture Search is a high-end optimization tool used to find best neural architectures in terms of accuracy with or without constraints such as latency, memory, or a custom metric. The search space of possible neural architecture choices can be as large as 10^20. It is based on a technique, which has successfully generated several state of the art computer vision models in the past years, including Nasnet, MNasnet, EfficientNet, NAS-FPN, and SpineNet.
- Neural Architecture Search isn't a solution where you can just bring your data and expect a good result without experimentation. It is an experimentation tool.
- Neural Architecture Search isn't for hyperparameter tuning such as for tuning the learning rate or optimizer settings. It is only meant for an architecture search. You shouldn't combine hyper-parameter tuning with Neural Architecture Search.
- Neural Architecture Search is not recommended with limited training data or for highly imbalanced datasets where some classes are very rare. If you are already using heavy augmentations for your baseline training due to lack of data, then Neural Architecture Search is not recommended.
- You should first try other traditional and conventional machine learning methods and techniques such as hyperparameter tuning. You should use Neural Architecture Search only if you don't see further gain with such traditional methods.
- You should have an in-house team for model tuning, which has some basic idea about architecture parameters to modify and try. These architecture parameters can include the kernel size, number of channels or connections among many other possibilities. If you have a search space in mind to explore, then Neural Architecture Search is highly valuable and can reduce at least approximately six months of engineering time in exploring a large search space: up to 10^20 architecture choices.
- Neural Architecture Search is meant for enterprise customers who can spend several thousand dollars on an experiment.
- Neural Architecture Search isn't limited to vision only use case. Currently, only vision-based prebuilt search spaces and prebuilt trainers are provided, but customers can bring their own non-vision search spaces and trainers as well.
- Neural Architecture Search doesn't use a supernet (oneshot-NAS or weight-sharing based NAS) approach where you just bring your own data, and use it as a solution. It is non-trivial (months of effort) to customize a supernet. Unlike a supernet, Neural Architecture Search is highly customizable to define custom search spaces and rewards. The customization can be done in approximately one to two days.
- Neural Architecture Search is supported in 8 regions across the world. Check the availability in your region.
You should also read the following section on expected cost, result gains, and GPU quota requirements before using Neural Architecture Search.
Expected cost, result gains, and GPU quota requirements
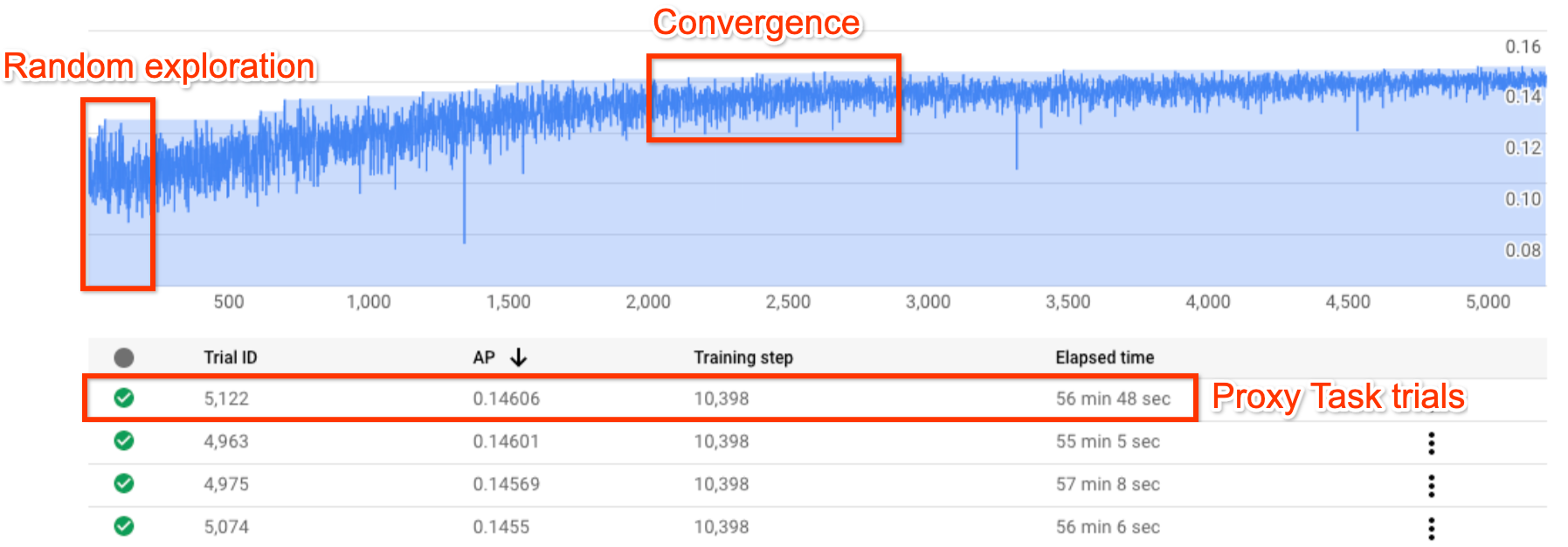
The figure shows a typical Neural Architecture Search curve.
The Y-axis shows the trial rewards, and the
X-axis shows the number of trials launched.
As the number of trials increase, the controller starts finding better
models. Therefore, the reward starts increasing, and later, the
reward variance and the reward growth start decreasing
and show the convergence. At the point of convergence, the number of trials
can vary based on the search-space size, but it is of the order of
approximately 2000 trials.
Each trial is designed to be a smaller version of
full training called proxy-task
which runs for approximately one to two hours on two Nvidia
V100 GPUs. The customer
can stop the search manually at any point and might find higher
reward models compared to their baseline
before the point of convergence occurs.
It might be better to wait until the point of convergence occurs
to choose the better results.
After the search, the next stage is to pick
top 10 trials (models) and run a full training on them.
(Optional) Test drive the prebuilt MNasNet search space and trainer
In this mode, observe the search curve or a few trials, approximately 25, and do a test drive with a prebuilt MNasNet search space and trainer.
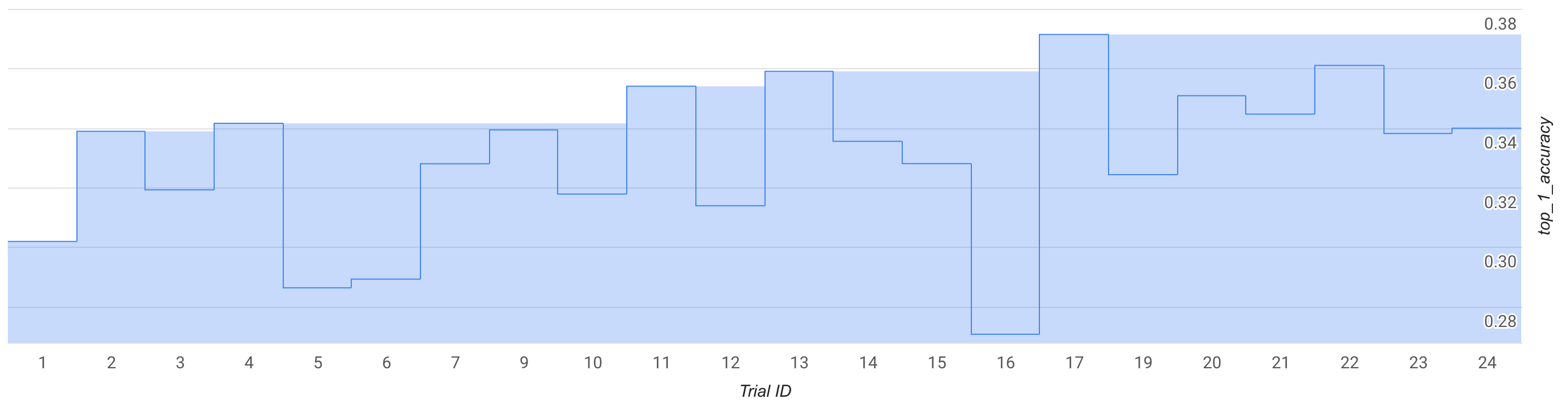
In the figure, the best stage-1 reward starts to climb up from ~0.30 at trial-1 to ~0.37 at trial-17. Your exact run may look slightly different due to sampling randomness but you should see some small increase in the best reward. Note that this is still a toy run and doesn't represent any proof-of-concept or a public benchmark validation.
The cost for this run is detailed as follows:
- Stage-1:
- Number of trials: 25
- Number of GPUs per trial: 2
- GPU type: TESLA_T4
- Number of CPUs per trial: 1
- CPU type: n1-highmem-16
- Avg single trial training time: 3 hours
- Number of parallel trials: 6
- GPU quota used: (num-gpus-per-trial * num-parallel-trials) = 12 GPUs. Use us-central1 region for the test drive and host training data in the same region. No extra quota needed.
- Time to run: (total-trials * training-time-per-trial)/(num-parallel-trials) = 12 hours
- GPU hours: (total-trials * training-time-per-trial * num-gpus-per-trial) = 150 T4 GPU hours
- CPU hours: (total-trials * training-time-per-trial * num-cpus-per-trial) = 75 n1-highmem-16 hours
- Cost: Approximately $185. You can stop the job earlier to reduce the cost. Refer to the pricing page to calculate exact price.
Because this is a toy run, there is no need to run a full stage-2 training for models from stage-1. To learn more about running stage-2, see tutorial 3.
The MnasNet notebook is used for this run.
(Optional) Proof-of-concept (POC) run of the prebuilt MNasNet search space and trainer
In case you are interested in almost replicating a published MNasnet result, you can use this mode. According to the paper, MnasNet achieves 75.2% top-1 accuracy with 78 ms latency on a Pixel phone, which is 1.8x faster than the MobileNetV2 with 0.5% higher accuracy and 2.3x faster than NASNet with 1.2% higher accuracy. However, this example uses GPUs instead of TPUs for training and uses cloud-CPU (n1-highmem-8) to evaluate latency. With this example, the expected Stage2 top-1 accuracy on MNasNet is 75.2% with 50ms latency on cloud-CPU (n1-highmem-8).
The cost for this run is detailed as follows:
Stage-1 search:
- Number of trials: 2000
- Number of GPUs per trial: 2
- GPU type: TESLA_T4
- Avg single trial training time: 3 hours
- Number of parallel trials: 10
- GPU quota used: (num-gpus-per-trial * num-parallel-trials) = 20 T4 GPUs. Since this number is above the default quota, create a quota request from your project UI. For more information, see setting_up_path.
- Time to run: (total-trials * training-time-per-trial)/(num-parallel-trials)/24 = 25 days. Note: The job terminates after 14 days. After that time, you can resume the search job easily with one command for another 14 days. If you have higher GPU quota, then the runtime decreases proportionately.
- GPU hours: (total-trials * training-time-per-trial * num-gpus-per-trial) = 12000 T4 GPU hours.
- Cost: ~$15,000
Stage-2 full-training with top 10 models:
- Number of trials: 10
- Number of GPUs per trial: 4
- GPU type: TESLA_T4
- Avg single trial training time: ~9 days
- Number of parallel trials: 10
- GPU quota used: (num-gpus-per-trial * num-parallel-trials) = 40 T4 GPUs. Because this number is above the default quota, create a quota request from your project UI. For more information, see setting_up_path. You can also run this with 20 T4 GPUs by running the job twice with five models at a time instead of all 10 in parallel.
- Time to run: (total-trials * training-time-per-trial)/(num-parallel-trials)/24 = ~9 days
- GPU hours: (total-trials * training-time-per-trial * num-gpus-per-trial) = 8960 T4 GPU hours.
- Cost: ~$8,000
Total cost: Approximately $23,000. Refer to the pricing page to calculate exact price. Note: This example isn't an average regular training job. The full training runs for approximately nine days on four TESLA_T4 GPUs.
The MnasNet notebook is used for this run.
Using your search space and trainers
We provide an approximate cost for an average custom user. Your needs can vary depending on your training task and GPUs and CPUs used. You need at least 20 GPUs quota for an end-to-end run as documented here. Note: The performance gain is completely dependent on your task. We can only provide examples like MNasnet as referenced examples for performance gain.
The cost for this hypothetical custom run is detailed as follows:
Stage-1 search:
- Number of trials: 2,000
- Number of GPUs per trial: 2
- GPU type: TESLA_T4
- Avg single trial training time: 1.5 hours
- Number of parallel trials: 10
- GPU quota used: (num-gpus-per-trial * num-parallel-trials) = 20 T4 GPUs. Because this number is above the default quota, you need to create a quota request from your project UI. For more information, see Request additional device quota for the project.
- Time to run: (total-trials * training-time-per-trial)/(num-parallel-trials)/24 = 12.5 days
- GPU hours: (total-trials * training-time-per-trial * num-gpus-per-trial) = 6000 T4 GPU hours.
- Cost: approximately $7,400
Stage-2 full training with top 10 models:
- Number of trials: 10
- Number of GPUs per trial: 2
- GPU type: TESLA_T4
- Average single trial training time: approximately 4 days
- Number of parallel trials: 10
- GPU quota used: (num-gpus-per-trial * num-parallel-trials) = 20 T4 GPUs. **Since this number is above the default quota, you need to create a quota request from your project UI. For more information, see Request additional device quota for the project. Refer to the same documentation for custom quota needs.
- Time to run: (total-trials * training-time-per-trial)/(num-parallel-trials)/24 = approximately 4 days
- GPU hours: (total-trials * training-time-per-trial * num-gpus-per-trial) = 1920 T4 GPU hours.
- Cost: approximately $2,400
For more information on proxy-task design cost, see Proxy task design The cost is similar to training 12 models (stage-2 in the figure uses 10 models):
- GPU quota used: Same as stage-2 run in the figure.
- Cost: (12/10) * stage-2-cost-for-10-models = ~$2,880
Total cost: approximately $12,680. Refer to the pricing page to calculate exact price.
These stage-1 search cost are for the search until the convergence point is reached and for maximum performance gain. However, don't wait until the search converges. You can expect to see a smaller amount of performance gain with a smaller search cost by running stage-2 full training with the best model so far if the search-reward curve has started growing. For example, for the search-plot shown earlier, don't wait until the 2,000 trials for convergence are reached. You might have found better models at 700 or 1,200 trials and can run stage-2 full training for those. You can always stop the search earlier to reduce the cost. You might also do stage-2 full training in parallel while the search is running, but make sure you have GPU quota to support an extra parallel job.
Summary of performance and cost
The following table summarizes some data points with different use cases and associated performance and cost.
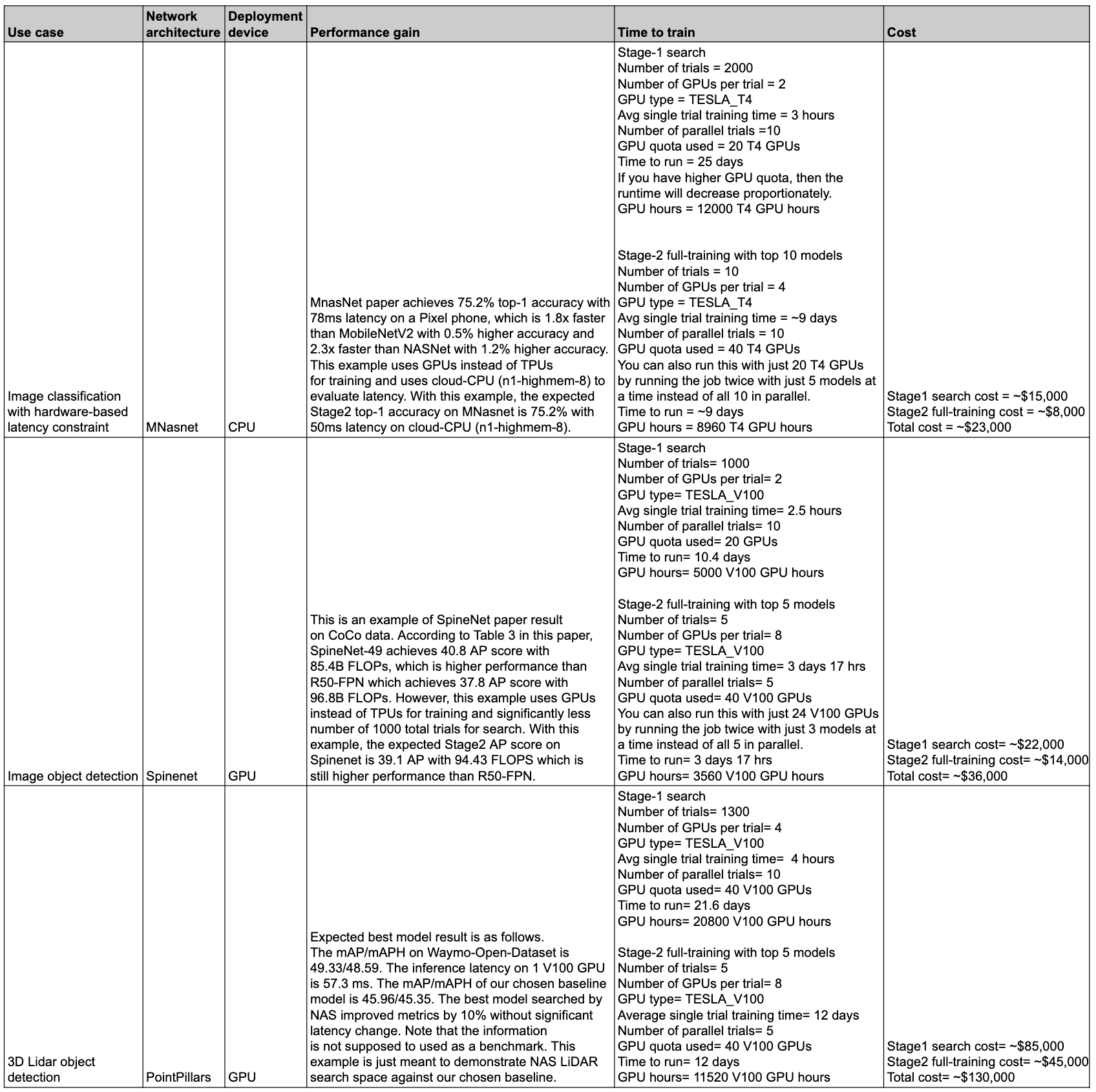
Use cases and features
Neural Architecture Search features are both flexible and easy to use. A novice user can use prebuilt search spaces, prebuilt-trainer, and notebooks without any further setup to start exploring Vertex AI Neural Architecture Search for their dataset. At the same time, an expert user can use Neural Architecture Search with their custom trainer, custom search space, and custom inference device and even extend architecture-search for non-vision use cases as well.
Neural Architecture Search offers prebuilt trainers and search spaces to be run on GPUs for the following use cases:
- Tensorflow trainers with public dataset based results published in a notebook
- PyTorch trainers to be used only as a tutorial example
- PyTorch 3D medical image segmentation search space example
- PyTorch-based MNasNet classification
- Latency and memory constrained search for targeting devices
- Additional Tensorflow based prebuilt state-of-the-art search spaces with code
- Model Scaling
- Data Augmentation
The full set of features that Neural Architecture Search offers can be used easily for customized architectures and use cases as well:
- A Neural Architecture Search language to define a custom search space over possible neural-architectures and integrate this search space with custom trainer code.
- Ready-to-use prebuilt state-of-the-art search spaces with code.
- Ready-to-use prebuilt Trainer, with code, which runs on GPU.
- A Managed Service for architecture-search including
- A Neural Architecture Search controller which samples the search space to find the best architecture.
- Prebuilt docker/libraries, with code, to calculate latency/FLOPs/Memory on custom hardware.
- Tutorials to teach NAS usage.
- A set of tools to design proxy-tasks.
- Guidance and example for efficient PyTorch training with Vertex AI.
- Library support for custom metrics reporting and analysis.
- Google Cloud console UI to monitor and manage jobs.
- Easy to use notebooks to kick-start the search.
- Library support for GPU/CPU resource usage management on per project or per job level of granularity.
- Python-based Nas-client to build dockers, launch NAS jobs, and resume a previous search job.
- Google Cloud console UI-based customer support.
Background
Neural Architecture Search is a technique for automating the design of neural networks. It has successfully generated several state of the art computer vision models in the past years, including:
These resulting models are leading the way in all 3 key classes of computer vision problems: image classification, object detection, and segmentation.
With Neural Architecture Search, engineers can optimize models for accuracy, latency, and memory in the same trial, reducing the time needed to deploy models. Neural Architecture Search explores many different types of models: the controller proposes ML models, then trains and evaluates models and iterates 1k+ times to find the best solutions with latency and/or memory constraint on targeting devices. The following figure shows the key components of the architecture search framework:
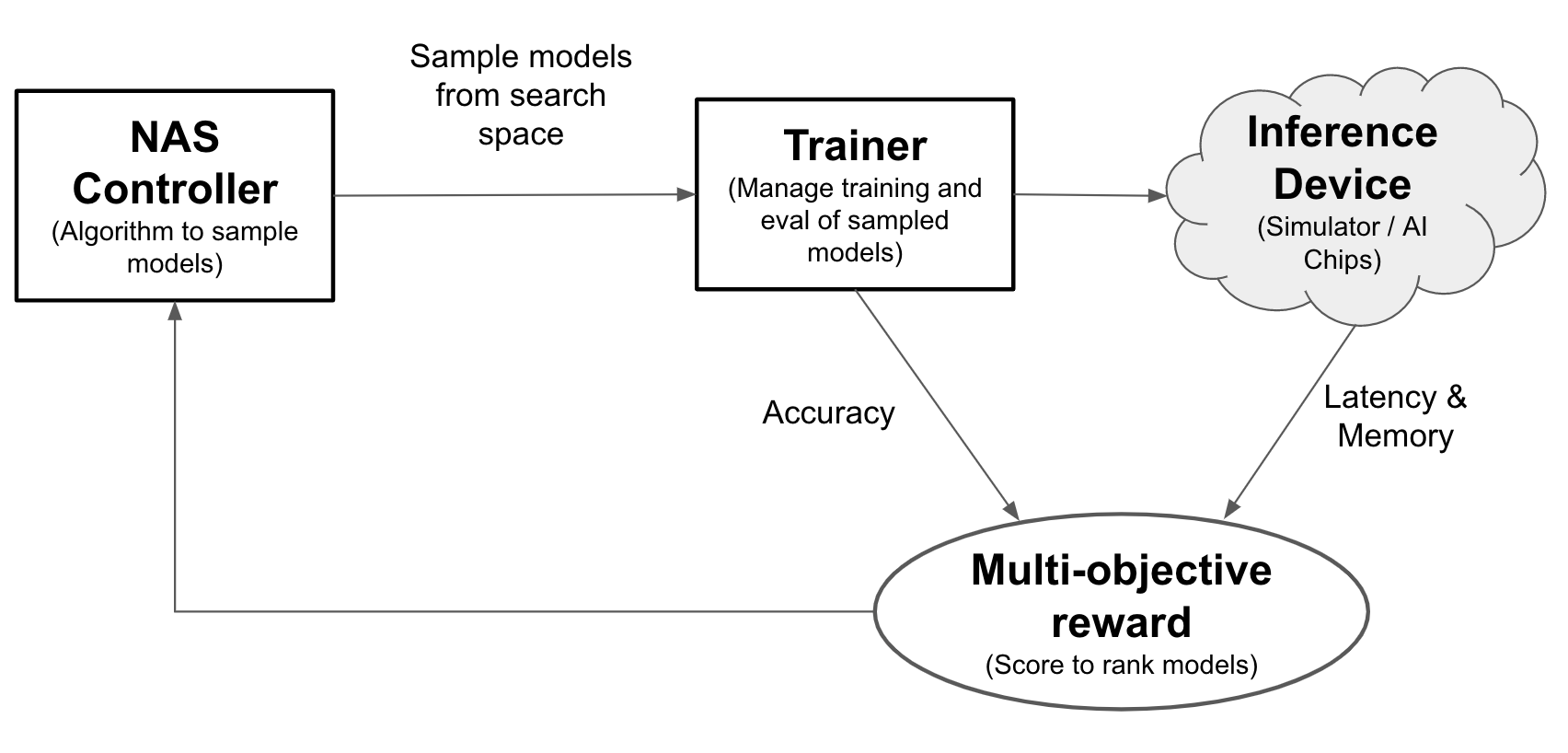
- Model: A neural architecture with operations and connections.
- Search space: The space of possible models (operations and connections) that can be designed and optimized.
- Trainer docker: User customizable trainer code to train and evaluate a model and compute accuracy of the model.
- Inference device: A hardware device such as CPU/GPU on which the model latency and memory usage is computed.
- Reward: A combination of model metrics such as the accuracy, latency, and memory used for ranking the models as better or worse.
- Neural Architecture Search Controller: The orchestrating algorithm that (a) samples the models from the search space, (b) receives the model-rewards, and (c) provides next set of model suggestions to evaluate to find the most optimal models.
User setup tasks
Neural Architecture Search offers prebuilt trainer integrated with prebuilt search spaces which can be easily used with provided notebooks without any further setup.
However, most users need to use their custom trainer, custom search spaces, custom metrics (memory, latency, and training time, for examples), and custom reward (combination of things such as accuracy and latency). For this, you need to:
- Define a custom search space using the provided Neural Architecture Search language.
- Integrate the search space definition into the trainer code.
- Add custom metrics reporting to the trainer code.
- Add custom reward to the trainer code.
- Build training container and use it to start Neural Architecture Search jobs.
The following diagram illustrates this:
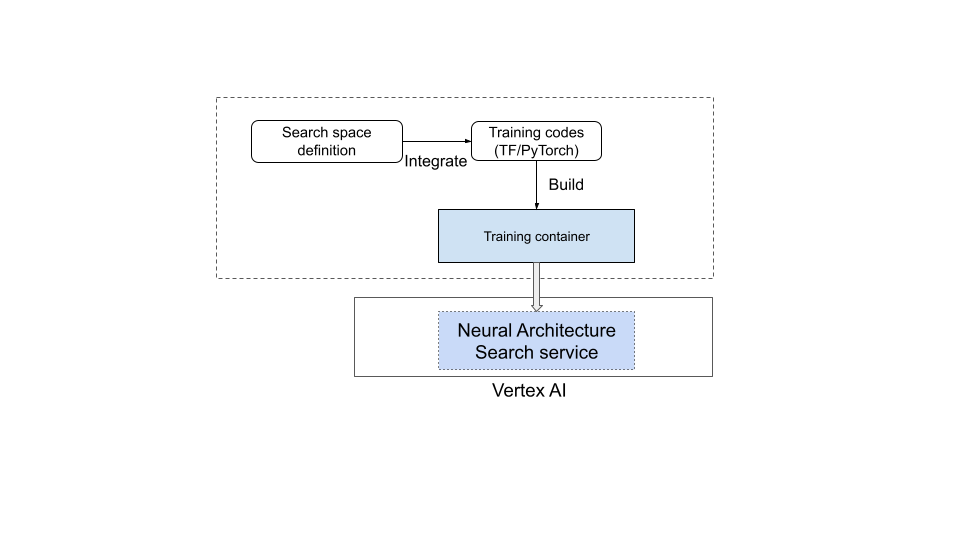
Neural Architecture Search service in operation
After you set up the training container to use, the Neural Architecture Search service then launches multiple training-containers in parallel on multiple GPU devices. You can control how many trials to use in parallel for training and how many total trials to launch. Each training-container is provided a suggested architecture from the search space. The training-container builds the suggested model, does train/eval, and then reports rewards back to the Neural Architecture Search service. As this process progresses, the Neural Architecture Search service uses the reward feedback to find better and better model-architectures. After the search, you have access to the reported metrics for further analysis.
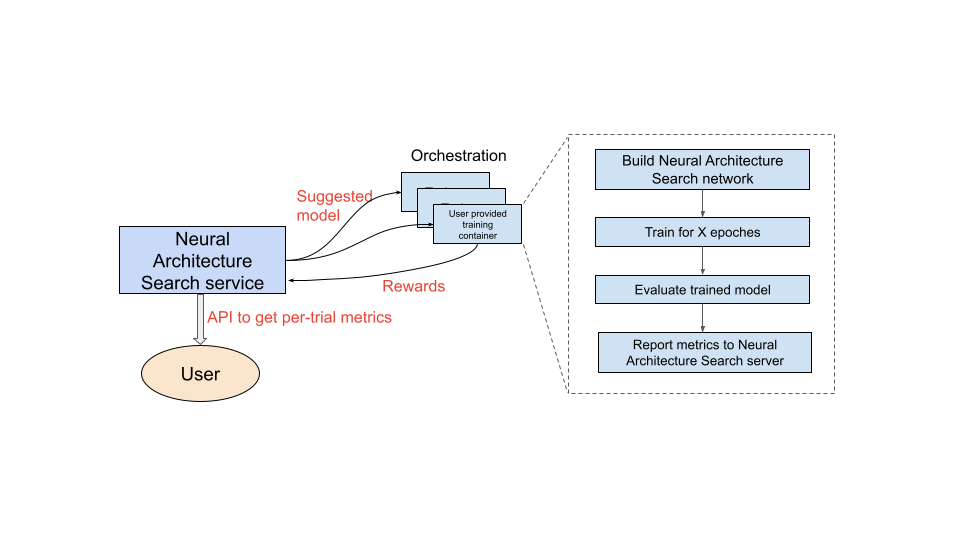
Overview of user journey for Neural Architecture Search
The high level steps for performing an Neural Architecture Search experiment are as follows:
Setups and definitions:
- Identify the labeled dataset and specify the task type (detection or segmentation, for example).
- Customize trainer code:
- Use a prebuilt search space or define a custom search space using the Neural Architecture Search language.
- Integrate the search-space definition into the trainer code.
- Add custom metrics reporting to the trainer code.
- Add custom reward to the trainer code.
- Build a trainer container.
- Set up search trial parameters for partial training (proxy task). The
search training should ideally finish fast (for example, 30-60 minutes)
to partially train the models:
- Minimum epochs needed for sampled models to gather reward (the minimum epochs don't need to ensure model convergence).
- Hyperparameters (for example, learning rate).
Run search locally to ensure the search space integrated container can run properly.
Start the Google Cloud search (stage-1) job with five test trials and verify that the search trials meet the runtime and accuracy goals.
Start the Google Cloud search (stage-1) job with +1k trials.
As part of the search, also set a regular interval to train (stage-2) top N models:
- Hyperparameters and algorithm for hyperparameter search. stage-2 normally uses the similar configuration as stage-1, but with higher settings for certain parameters, such as training steps/epochs, and number of channels.
- Stop criteria (the number of epochs).
Analyze the reported metrics and/or visualize architectures for insights.
An architecture-search experiment can be followed up by a scaling-search experiment, followed up by an augmentation search experiment as well.
Documentation reading order
- (Required) Set up your environment
- (Required) Tutorials
- (Required only for PyTorch customers) PyTorch efficient training with cloud data
- (Required) Best practices and suggested workflow
- (Required) Proxy task design
- (Required only when using prebuilt trainers) How to use prebuilt search spaces and a prebuilt trainer
References
- Using Machine Learning to Explore Neural Network Architecture
- MnasNet: Towards Automating the Design of Mobile Machine Learning Models
- EfficientNet: Improving Accuracy and Efficiency through AutoML and Model Scaling
- NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection
- SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization
- RandAugment