Con Vertex AI Neural Architecture Search, puedes buscar arquitecturas neuronales óptimas en términos de precisión, latencia, memoria, una combinación de estos factores o una métrica personalizada.
Determinar si Vertex AI Neural Architecture Search es la mejor herramienta para mí
- Vertex AI Neural Architecture Search es una herramienta de optimización de gama alta que se usa para encontrar las mejores arquitecturas neuronales en términos de precisión con o sin restricciones, como la latencia, la memoria o una métrica personalizada. El espacio de búsqueda de las posibles opciones de arquitectura neuronal puede ser de hasta 10^20. Se basa en una técnica que ha generado correctamente varios modelos de visión artificial de vanguardia en los últimos años, como Nasnet, MNasnet, EfficientNet, NAS-FPN y SpineNet.
- Neural Architecture Search no es una solución en la que puedas aportar tus datos y esperar un buen resultado sin experimentar. Es una herramienta de experimentación.
- La búsqueda con arquitectura neuronal no se usa para ajustar hiperparámetros, como la tasa de aprendizaje o la configuración del optimizador. Solo se puede usar para buscar arquitecturas. No debes combinar el ajuste de hiperparámetros con la búsqueda con arquitectura neuronal.
- No se recomienda usar Neural Architecture Search con datos de entrenamiento limitados ni con conjuntos de datos muy desequilibrados en los que algunas clases sean muy raras. Si ya estás usando aumentos pesados para tu entrenamiento de referencia debido a la falta de datos, no se recomienda usar Neural Architecture Search.
- Primero debes probar otros métodos y técnicas de aprendizaje automático tradicionales y convencionales, como el ajuste de hiperparámetros. Solo debes usar Neural Architecture Search si no obtienes más resultados con los métodos tradicionales.
- Deberías tener un equipo interno para ajustar el modelo, que tenga una idea básica sobre los parámetros de arquitectura que se pueden modificar y probar. Estos parámetros de arquitectura pueden incluir el tamaño del kernel, el número de canales o las conexiones, entre muchas otras posibilidades. Si tienes en mente un espacio de búsqueda que explorar, la búsqueda con arquitectura neuronal es muy valiosa y puede reducir al menos unos seis meses de tiempo de ingeniería en la exploración de un espacio de búsqueda grande: hasta 10^20 opciones de arquitectura.
- La búsqueda de arquitectura neuronal está pensada para clientes empresariales que pueden invertir varios miles de dólares en un experimento.
- Neural Architecture Search no se limita a los casos prácticos de visión. Actualmente, solo se proporcionan espacios de búsqueda predefinidos y entrenadores predefinidos basados en la visión, pero los clientes también pueden usar sus propios espacios de búsqueda y entrenadores no basados en la visión.
- Neural Architecture Search no usa un enfoque de superred (NAS de un solo intento o NAS basado en el uso compartido de pesos) en el que solo tienes que aportar tus datos y usarlos como solución. Personalizar una superred no es trivial (requiere meses de esfuerzo). A diferencia de una superred, Neural Architecture Search se puede personalizar en gran medida para definir espacios de búsqueda y recompensas personalizados. La personalización puede tardar entre uno y dos días.
- Neural Architecture Search está disponible en ocho regiones de todo el mundo. Consulta la disponibilidad en tu zona.
Antes de usar Neural Architecture Search, también debes leer la siguiente sección sobre el coste esperado, las mejoras de los resultados y los requisitos de cuota de GPU.
Coste esperado, resultados y requisitos de cuota de GPU
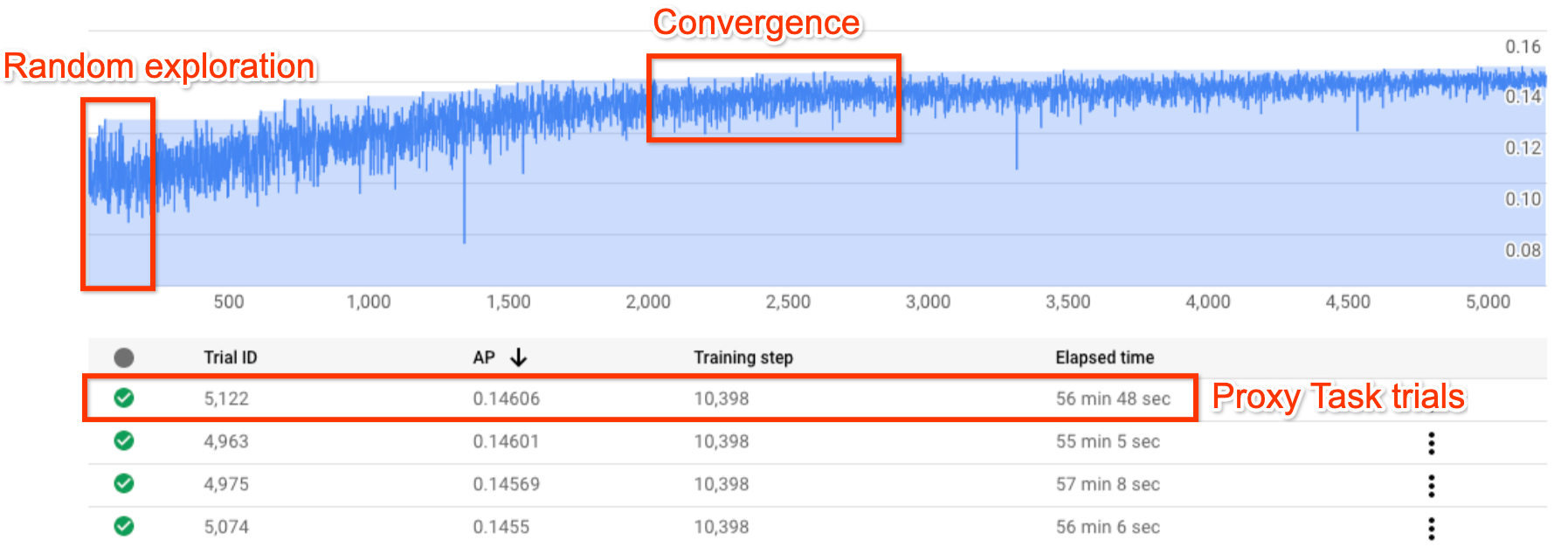
En la figura se muestra una curva típica de búsqueda con arquitectura neuronal.
El Y-axis muestra las recompensas de la prueba y el X-axis indica el número de pruebas iniciadas.
A medida que aumenta el número de pruebas, el controlador empieza a encontrar mejores modelos. Por lo tanto, la recompensa empieza a aumentar y, más adelante, la varianza y el crecimiento de la recompensa empiezan a disminuir y muestran la convergencia. En el punto de convergencia, el número de pruebas puede variar en función del tamaño del espacio de búsqueda, pero es del orden de aproximadamente 2000 pruebas.
Cada prueba se diseña para que sea una versión más pequeña del entrenamiento completo, denominada tarea proxy, que se ejecuta durante aproximadamente una o dos horas en dos GPUs Nvidia V100. El cliente puede detener la búsqueda manualmente en cualquier momento y puede encontrar modelos de recompensa más altos en comparación con su valor de referencia antes de que se produzca el punto de convergencia.
Puede que sea mejor esperar a que se produzca el punto de convergencia para elegir los mejores resultados.
Después de la búsqueda, la siguiente fase es elegir las 10 mejores pruebas (modelos) y llevar a cabo un entrenamiento completo con ellas.
(Opcional) Prueba el espacio de búsqueda y el entrenador predefinidos de MNasNet
En este modo, observa la curva de búsqueda o haz unas 25 pruebas y prueba un espacio de búsqueda y un entrenador de MNasNet predefinidos.
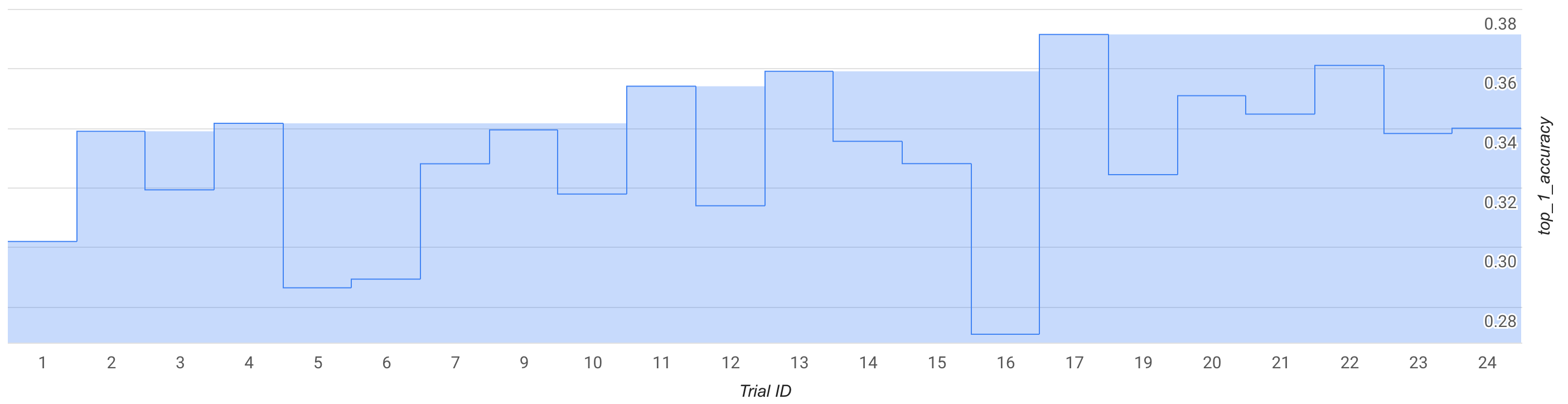
En la figura, la mejor recompensa de la fase 1 empieza a aumentar desde ~0,30 en la prueba 1 hasta ~0,37 en la prueba 17. Tu carrera puede ser ligeramente diferente debido a la aleatoriedad del muestreo, pero deberías ver un pequeño aumento en la mejor recompensa. Ten en cuenta que se trata de una prueba y no representa ninguna prueba de concepto ni una validación de referencia pública.
El coste de esta ejecución se detalla de la siguiente manera:
- Fase 1:
- Número de pruebas: 25
- Número de GPUs por prueba: 2
- Tipo de GPU: TESLA_T4
- Número de CPUs por prueba: 1
- Tipo de CPU: n1-highmem-16
- Tiempo medio de entrenamiento de una sola prueba: 3 horas
- Número de pruebas paralelas: 6
- Cuota de GPUs usada: (num-gpus-per-trial * num-parallel-trials) = 12 GPUs. Usa la región us-central1 para la prueba y aloja los datos de entrenamiento en la misma región. No se necesita ninguna cuota adicional.
- Tiempo de ejecución: (total-trials * training-time-per-trial)/(num-parallel-trials) = 12 horas
- Horas de GPU: (total-pruebas * tiempo-entrenamiento-por-prueba * num-gpus-por-prueba) = 150 horas de GPU T4
- Horas de CPU: (total-trials * training-time-per-trial * num-cpus-per-trial) = 75 horas de n1-highmem-16
- Coste: aproximadamente 185 USD. Puedes detener el trabajo antes para reducir el coste. Consulta la página de precios para calcular el precio exacto.
Como se trata de una prueba, no es necesario ejecutar un entrenamiento completo de la fase 2 para los modelos de la fase 1. Para obtener más información sobre cómo ejecutar la fase 2, consulta el tutorial 3.
En esta ejecución se usa el cuaderno MnasNet.
(Opcional) Prueba de concepto del espacio de búsqueda y del entrenador de MNasNet precompilados
Si quieres replicar casi por completo un resultado de MNasnet publicado, puedes usar este modo. Según el artículo, MnasNet consigue una precisión del 75,2% con una latencia de 78 ms en un teléfono Pixel, lo que supone 1,8 veces más rápido que MobileNetV2 con una precisión 0,5% mayor y 2,3 veces más rápido que NASNet con una precisión 1,2% mayor. Sin embargo, en este ejemplo se usan GPUs en lugar de TPUs para el entrenamiento y se usa una CPU de Cloud (n1-highmem-8) para evaluar la latencia. En este ejemplo, la precisión del top-1 de la fase 2 esperada en MNasNet es del 75,2% con una latencia de 50 ms en la CPU en la nube (n1-highmem-8).
El coste de esta ejecución se detalla de la siguiente manera:
Búsqueda de la fase 1:
- Número de pruebas: 2000
- Número de GPUs por prueba: 2
- Tipo de GPU: TESLA_T4
- Tiempo medio de entrenamiento de una sola prueba: 3 horas
- Número de pruebas paralelas: 10
- Cuota de GPUs usada: (num-gpus-per-trial * num-parallel-trials) = 20 GPUs T4. Como este número supera la cuota predeterminada, crea una solicitud de cuota desde la interfaz de usuario de tu proyecto. Para obtener más información, consulta setting_up_path.
- Tiempo de ejecución: (total-trials * training-time-per-trial)/(num-parallel-trials)/24 = 25 días. Nota: La tarea finaliza al cabo de 14 días. Después de ese tiempo, puedes reanudar la búsqueda de empleo fácilmente con un comando durante otros 14 días. Si tienes una cuota de GPU más alta, el tiempo de ejecución se reduce proporcionalmente.
- Horas de GPU: (total_pruebas * tiempo_entrenamiento_por_prueba * num_gpus_por_prueba) = 12.000 horas de GPU T4.
- Coste: unos 15.000 USD
Entrenamiento completo de la fase 2 con los 10 mejores modelos:
- Número de pruebas: 10
- Número de GPUs por prueba: 4
- Tipo de GPU: TESLA_T4
- Tiempo medio de entrenamiento de una sola prueba: unos 9 días
- Número de pruebas paralelas: 10
- Cuota de GPUs usada: (num-gpus-per-trial * num-parallel-trials) = 40 GPUs T4. Como este número supera la cuota predeterminada, crea una solicitud de cuota desde la interfaz de usuario de tu proyecto. Para obtener más información, consulta setting_up_path. También puedes ejecutarlo con 20 GPUs T4 ejecutando el trabajo dos veces con cinco modelos a la vez en lugar de los 10 en paralelo.
- Tiempo de ejecución: (total-trials * training-time-per-trial)/(num-parallel-trials)/24 = ~9 días
- Horas de GPU: (total-pruebas * tiempo-entrenamiento-por-prueba * num-gpus-por-prueba) = 8960 horas de GPU T4.
- Coste: unos 8000 USD
Coste total: aproximadamente 23.000 USD. Consulta la página de precios para calcular el precio exacto. Nota: Este ejemplo no es un trabajo de entrenamiento normal. El entrenamiento completo se ejecuta durante aproximadamente nueve días en cuatro GPUs TESLA_T4.
En esta ejecución se usa el cuaderno MnasNet.
Usar tu espacio de búsqueda y tus entrenadores
Proporcionamos un coste aproximado para un usuario personalizado medio. Tus necesidades pueden variar en función de la tarea de entrenamiento y de las GPUs y CPUs que utilices. Necesitas al menos 20 cuotas de GPU para una ejecución de principio a fin, como se indica aquí. Nota: El aumento del rendimiento depende por completo de la tarea. Solo podemos proporcionar ejemplos como MNasnet como ejemplos de referencia para mejorar el rendimiento.
El coste de esta ejecución personalizada hipotética se detalla a continuación:
Búsqueda de la fase 1:
- Número de pruebas: 2000
- Número de GPUs por prueba: 2
- Tipo de GPU: TESLA_T4
- Tiempo medio de entrenamiento de una sola prueba: 1,5 horas
- Número de pruebas paralelas: 10
- Cuota de GPUs usada: (num-gpus-per-trial * num-parallel-trials) = 20 GPUs T4. Como este número es superior a la cuota predeterminada, debes crear una solicitud de cuota desde la interfaz de usuario de tu proyecto. Para obtener más información, consulta Solicitar cuota de dispositivos adicional para el proyecto.
- Tiempo de ejecución: (total-trials * training-time-per-trial)/(num-parallel-trials)/24 = 12,5 días
- Horas de GPU: (total-pruebas * tiempo-entrenamiento-por-prueba * num-gpus-por-prueba) = 6000 horas de GPU T4.
- Coste: aproximadamente 7400 USD
Entrenamiento completo de la fase 2 con los 10 mejores modelos:
- Número de pruebas: 10
- Número de GPUs por prueba: 2
- Tipo de GPU: TESLA_T4
- Tiempo medio de entrenamiento de una sola prueba: aproximadamente 4 días
- Número de pruebas paralelas: 10
- Cuota de GPUs usada: (num-gpus-per-trial * num-parallel-trials) = 20 GPUs T4. **Como este número supera la cuota predeterminada, debes crear una solicitud de cuota desde la interfaz de usuario de tu proyecto. Para obtener más información, consulta Solicitar cuota de dispositivos adicional para el proyecto. Consulta la misma documentación para obtener información sobre las cuotas personalizadas.
- Tiempo de ejecución: (total_pruebas * tiempo_entrenamiento_por_prueba)/(num_pruebas_paralelas)/24 = aproximadamente 4 días
- Horas de GPU: (total_pruebas * tiempo_entrenamiento_por_prueba * num_gpus_por_prueba) = 1920 horas de GPU T4.
- Coste: aproximadamente 2400 USD
Para obtener más información sobre el coste del diseño de tareas proxy, consulta Diseño de tareas proxy. El coste es similar al de entrenar 12 modelos (la fase 2 de la figura usa 10 modelos):
- Cuota de GPU usada: igual que la ejecución de la fase 2 de la figura.
- Coste: (12/10) * coste de la fase 2 para 10 modelos = 2880 USD (aproximadamente)
Coste total: aproximadamente 12.680 USD. Consulta la página de precios para calcular el precio exacto.
Estos costes de búsqueda de la fase 1 corresponden a la búsqueda hasta que se alcanza el punto de convergencia y a la ganancia de rendimiento máxima. Sin embargo, no esperes a que la búsqueda converja. Si la curva de recompensa de búsqueda ha empezado a crecer, puedes esperar un aumento del rendimiento menor con un coste de búsqueda más bajo si ejecutas la fase 2 del entrenamiento completo con el mejor modelo hasta el momento. Por ejemplo, en el gráfico de búsqueda que se ha mostrado antes, no esperes a que se alcancen las 2000 pruebas para la convergencia. Es posible que hayas encontrado mejores modelos con 700 o 1200 pruebas y que puedas ejecutar el entrenamiento completo de la fase 2 para esos modelos. Siempre puedes detener la búsqueda antes para reducir el coste. También puedes hacer un entrenamiento completo de la fase 2 en paralelo mientras se ejecuta la búsqueda, pero asegúrate de tener cuota de GPU para admitir un trabajo paralelo adicional.
Resumen del rendimiento y los costes
En la siguiente tabla se resumen algunos puntos de datos con diferentes casos prácticos, así como el rendimiento y el coste asociados.
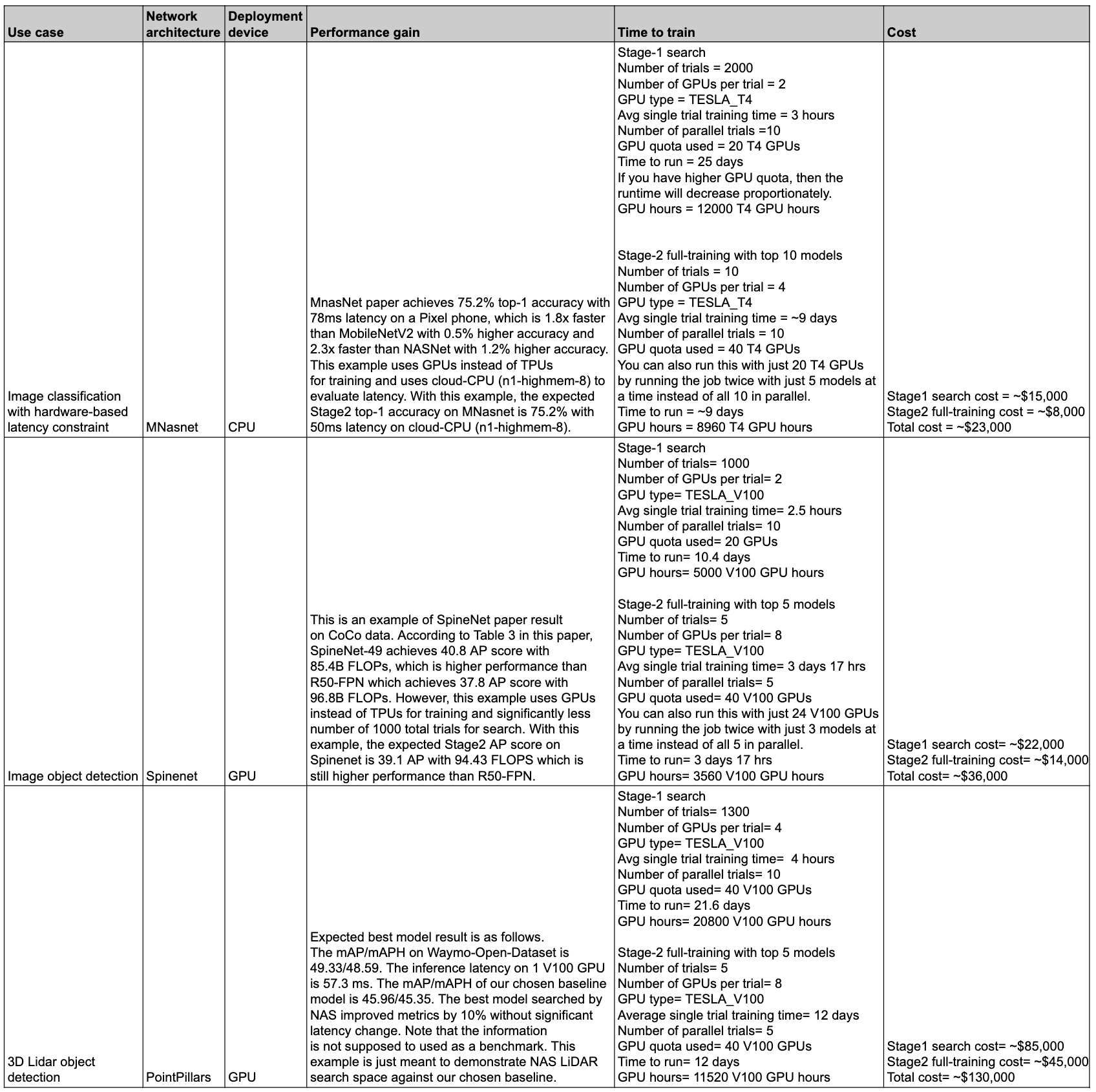
Casos prácticos y funciones
Las funciones de Neural Architecture Search son flexibles y fáciles de usar. Un usuario principiante puede usar espacios de búsqueda predefinidos, un entrenador predefinido y cuadernos sin necesidad de realizar ninguna otra configuración para empezar a explorar Vertex AI Neural Architecture Search en su conjunto de datos. Al mismo tiempo, un usuario experto puede usar Neural Architecture Search con su entrenador personalizado, su espacio de búsqueda personalizado y su dispositivo de inferencia personalizado, e incluso ampliar la búsqueda de arquitectura a casos prácticos que no sean de visión.
La búsqueda con arquitectura neuronal ofrece instructores y espacios de búsqueda predefinidos que se pueden ejecutar en GPUs para los siguientes casos prácticos:
- Entrenadores de TensorFlow con resultados basados en conjuntos de datos públicos publicados en un cuaderno
- Detección de objetos de imagen con espacios de búsqueda de extremo a extremo (SpineNet)
- Clasificación con espacios de búsqueda de backbone precompilado (MnasNet)
- Detección de objetos con nubes de puntos 3D LiDAR con espacios de búsqueda integrales precompilados
- Búsqueda con restricciones de latencia y memoria para dispositivos de segmentación
- Entrenadores de PyTorch que solo se pueden usar como ejemplo de tutorial
- Ejemplo de espacio de búsqueda de segmentación de imágenes médicas 3D de PyTorch
- Clasificación de MNasNet basada en PyTorch
- Búsqueda con restricciones de latencia y memoria para dispositivos de segmentación
- Espacios de búsqueda precompilados adicionales basados en TensorFlow con código de vanguardia
- Escalado de modelos
- Aumento de datos
El conjunto completo de funciones que ofrece Neural Architecture Search se puede usar fácilmente para arquitecturas y casos prácticos personalizados:
- Un lenguaje de búsqueda con arquitectura neuronal para definir un espacio de búsqueda personalizado sobre posibles arquitecturas neuronales e integrar este espacio de búsqueda con código de entrenador personalizado.
- Espacios de búsqueda predefinidos y listos para usar con código.
- Entrenador precompilado listo para usar, con código, que se ejecuta en la GPU.
- Un servicio gestionado para la búsqueda de arquitecturas, que incluye lo siguiente:
- Un controlador de búsqueda con arquitectura neuronal que muestrea el espacio de búsqueda para encontrar la mejor arquitectura.
- Docker o bibliotecas precompilados, con código, para calcular la latencia, las FLOPS o la memoria en hardware personalizado.
- Tutoriales para enseñar a usar NAS.
- Un conjunto de herramientas para diseñar tareas proxy.
- Guía y ejemplo para entrenar PyTorch de forma eficiente con Vertex AI.
- Compatibilidad con la biblioteca para la creación de informes y análisis de métricas personalizadas.
- Google Cloud Interfaz de usuario de la consola para monitorizar y gestionar tareas.
- Cuadernos fáciles de usar para empezar la búsqueda.
- Compatibilidad con bibliotecas para la gestión del uso de recursos de GPU o CPU con una granularidad por proyecto o por trabajo.
- Nas-client basado en Python para crear dockers, iniciar trabajos de NAS y reanudar un trabajo de búsqueda anterior.
- Google Cloud Asistencia al cliente basada en la interfaz de usuario de la consola.
Fondo
La búsqueda de arquitectura neuronal es una técnica para automatizar el diseño de redes neuronales. En los últimos años, ha generado varios modelos de visión artificial de última generación, como los siguientes:
Estos modelos están marcando el camino en las tres clases principales de problemas de visión artificial: clasificación de imágenes, detección de objetos y segmentación.
Con la búsqueda de arquitectura neuronal, los ingenieros pueden optimizar los modelos para mejorar la precisión, la latencia y la memoria en la misma prueba, lo que reduce el tiempo necesario para implementar los modelos. La búsqueda de arquitectura neuronal explora muchos tipos de modelos diferentes: el controlador propone modelos de aprendizaje automático, luego entrena y evalúa modelos, e itera más de 1000 veces para encontrar las mejores soluciones con restricciones de latencia o memoria en los dispositivos de segmentación. En la siguiente figura se muestran los componentes clave del marco de búsqueda de la arquitectura:
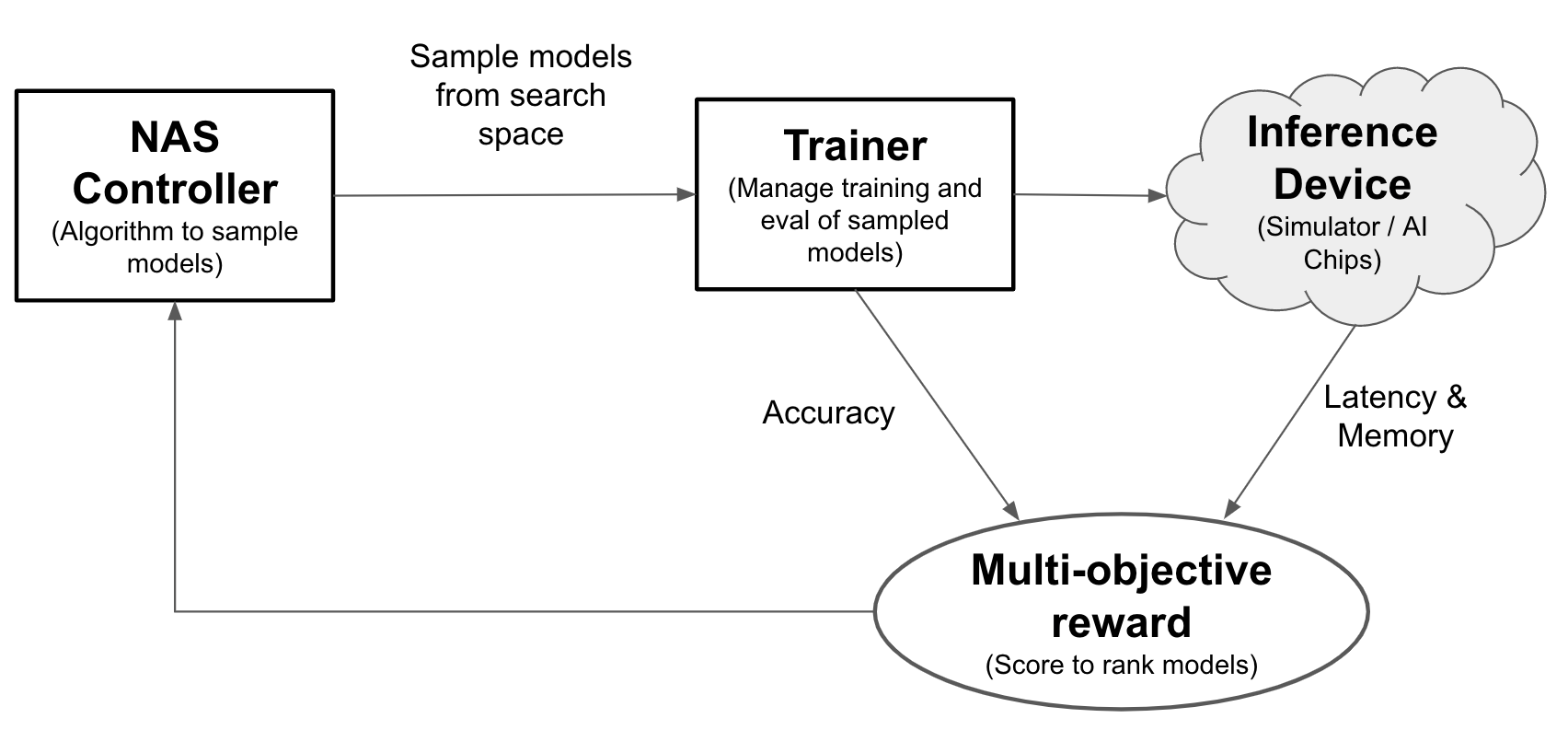
- Modelo: una arquitectura neuronal con operaciones y conexiones.
- Espacio de búsqueda: el espacio de los posibles modelos (operaciones y conexiones) que se pueden diseñar y optimizar.
- Docker de entrenador: código de entrenador personalizable por el usuario para entrenar y evaluar un modelo, así como para calcular la precisión del modelo.
- Dispositivo de inferencia: un dispositivo de hardware, como una CPU o una GPU, en el que se calcula la latencia y el uso de memoria del modelo.
- Recompensa: una combinación de métricas del modelo, como la precisión, la latencia y la memoria utilizada para clasificar los modelos como mejores o peores.
- Controlador de búsqueda de arquitectura neuronal: algoritmo de orquestación que (a) toma muestras de los modelos del espacio de búsqueda, (b) recibe las recompensas de los modelos y (c) proporciona el siguiente conjunto de sugerencias de modelos para evaluar y encontrar los modelos más óptimos.
Tareas de configuración de usuarios
Neural Architecture Search ofrece un entrenador predefinido integrado con espacios de búsqueda predefinidos que se pueden usar fácilmente con los cuadernos proporcionados sin necesidad de realizar ninguna configuración adicional.
Sin embargo, la mayoría de los usuarios necesitan usar su entrenador personalizado, sus espacios de búsqueda personalizados, sus métricas personalizadas (como la memoria, la latencia y el tiempo de entrenamiento) y su recompensa personalizada (una combinación de elementos como la precisión y la latencia). Para ello, debes hacer lo siguiente:
- Define un espacio de búsqueda personalizado con el lenguaje de Neural Architecture Search proporcionado.
- Integra la definición del espacio de búsqueda en el código del entrenador.
- Añade informes de métricas personalizadas al código del entrenador.
- Añade una recompensa personalizada al código de entrenador.
- Crea un contenedor de entrenamiento y úsalo para iniciar trabajos de búsqueda con arquitectura neuronal.
En el siguiente diagrama se muestra este proceso:
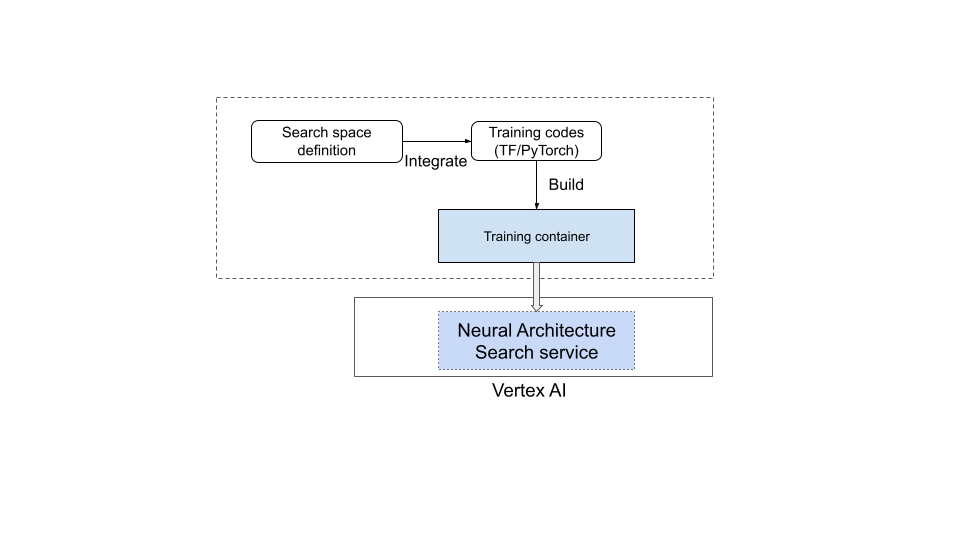
Servicio de búsqueda con arquitectura neuronal en funcionamiento
Una vez que hayas configurado el contenedor de entrenamiento que vas a usar, el servicio de búsqueda con arquitectura neuronal lanzará varios contenedores de entrenamiento en paralelo en varios dispositivos de GPU. Puedes controlar cuántas pruebas se deben usar en paralelo para el entrenamiento y cuántas pruebas se deben lanzar en total. A cada contenedor de entrenamiento se le proporciona una arquitectura sugerida del espacio de búsqueda. El contenedor de entrenamiento crea el modelo sugerido, realiza el entrenamiento y la evaluación, y, a continuación, comunica las recompensas al servicio de búsqueda con arquitectura neuronal. A medida que avanza este proceso, el servicio de búsqueda con arquitectura neuronal usa la información de recompensa para encontrar arquitecturas de modelos cada vez mejores. Después de la búsqueda, tendrás acceso a las métricas registradas para analizarlas más a fondo.
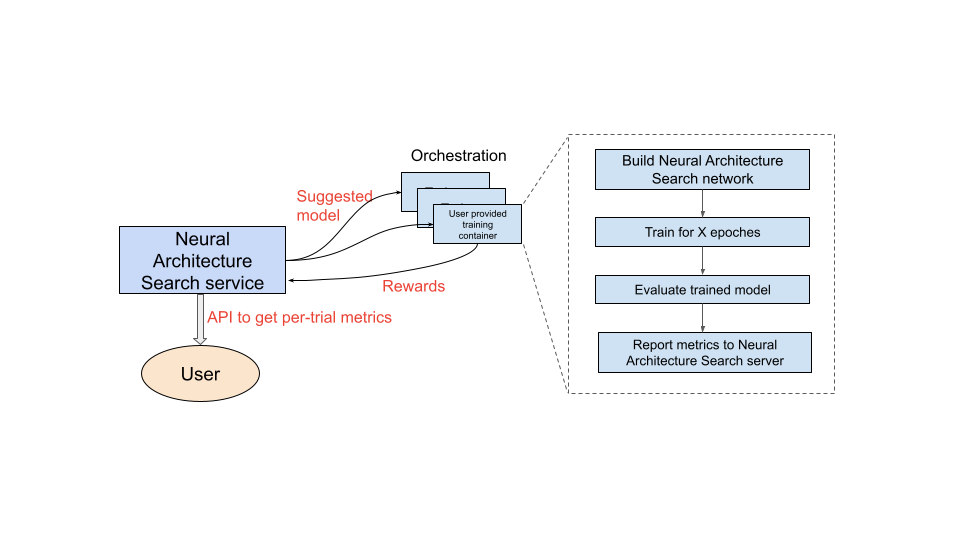
Descripción general del recorrido del usuario de Neural Architecture Search
Estos son los pasos generales para llevar a cabo un experimento de búsqueda con arquitectura neuronal:
Configuraciones y definiciones:
- Identifique el conjunto de datos etiquetado y especifique el tipo de tarea (detección o segmentación, por ejemplo).
- Personalizar el código de entrenador:
- Usa un espacio de búsqueda predefinido o define un espacio de búsqueda personalizado con el lenguaje de Neural Architecture Search.
- Integra la definición del espacio de búsqueda en el código del entrenador.
- Añade informes de métricas personalizadas al código del entrenador.
- Añade una recompensa personalizada al código de entrenador.
- Crea un contenedor de entrenador.
- Define los parámetros de prueba de búsqueda para el entrenamiento parcial (tarea proxy). Lo ideal es que el entrenamiento de búsqueda termine rápido (por ejemplo, en 30-60 minutos) para entrenar parcialmente los modelos:
- Número mínimo de épocas necesarias para que los modelos muestreados obtengan recompensas (el número mínimo de épocas no tiene que asegurar la convergencia del modelo).
- Hiperparámetros (por ejemplo, la tasa de aprendizaje).
Ejecuta la búsqueda de forma local para asegurarte de que el contenedor integrado del espacio de búsqueda se puede ejecutar correctamente.
Inicia el trabajo de Google Cloud búsqueda (fase 1) con cinco pruebas y verifica que las pruebas de búsqueda cumplen los objetivos de tiempo de ejecución y precisión.
Inicia el trabajo de Google Cloud búsqueda (fase 1) con +1000 pruebas.
Como parte de la búsqueda, también se debe definir un intervalo regular para entrenar los N modelos principales (fase 2):
- Hiperparámetros y algoritmo para la búsqueda de hiperparámetros. La fase 2 suele usar una configuración similar a la de la fase 1, pero con ajustes más altos para determinados parámetros, como los pasos o las épocas de entrenamiento y el número de canales.
- Criterios de parada (el número de épocas).
Analiza las métricas registradas o visualiza las arquitecturas para obtener información valiosa.
Un experimento de búsqueda de arquitectura puede ir seguido de un experimento de búsqueda de escalado, que a su vez puede ir seguido de un experimento de búsqueda de aumento.
Orden de lectura de la documentación
- Configurar el entorno (obligatorio)
- (Obligatorio) Tutoriales
- (Solo es obligatorio para los clientes de PyTorch) Entrenamiento eficiente de PyTorch con datos en la nube
- Prácticas recomendadas y flujo de trabajo sugerido (obligatorio)
- (Obligatorio) Diseño de tareas de proxy
- (Solo es obligatorio cuando se usan entrenadores predefinidos) Cómo usar espacios de búsqueda y un entrenador predefinidos
Referencias
- Usar el aprendizaje automático para explorar la arquitectura de redes neuronales
- MnasNet: hacia la automatización del diseño de modelos de aprendizaje automático para móviles
- EfficientNet: mejora de la precisión y la eficiencia mediante AutoML y el escalado de modelos
- NAS-FPN: aprendizaje de una arquitectura de pirámide de características escalable para la detección de objetos
- SpineNet: aprendizaje de una red troncal con permutación de escala para el reconocimiento y la localización
- RandAugment