A Vertex AI oferece um serviço de treinamento gerenciado que ajuda você a operar o treinamento de modelos em grande escala. É possível usar a Vertex AI para executar aplicativos de treinamento com base em qualquer framework de machine learning (ML) na infraestrutura doGoogle Cloud . Para os seguintes frameworks de ML conhecidos, a Vertex AI também tem suporte integrado que simplifica o processo de preparação para treinamento e disponibilização de modelos:
Nesta página, explicamos os benefícios do treinamento personalizado na Vertex AI, o fluxo de trabalho envolvido e as várias opções de treinamento disponíveis.
Vertex AI operacionaliza o treinamento em escala
Há vários desafios para operacionalizar o treinamento de modelo. Esses desafios incluem o tempo e o custo necessários para treinar modelos, a profundidade de habilidades necessárias para gerenciar a infraestrutura de computação e a necessidade de fornecer segurança de nível empresarial. A Vertex AI aborda esses desafios e oferece vários outros benefícios.
Infraestrutura de computação totalmente gerenciada
|
|
O treinamento de modelos na Vertex AI é um serviço totalmente gerenciado que não requer administração de infraestrutura física. É possível treinar modelos de ML sem provisionar ou gerenciar servidores. Você paga apenas pelos recursos de computação que consumir. A Vertex AI também lida com geração de registros, filas e monitoramento de jobs. |
Alto desempenho
|
|
Os jobs de treinamento da Vertex AI são otimizados para treinamento de modelo de ML, o que pode oferecer desempenho mais rápido do que a execução direta do aplicativo de treinamento em um cluster do Google Kubernetes Engine (GKE). Também é possível identificar e depurar gargalos de desempenho no seu job de treinamento usando o Cloud Profiler. |
Treinamento distribuído
|
|
O Servidor de redução é um algoritmo de redução total na Vertex AI que pode aumentar a capacidade e reduzir a latência do treinamento distribuído de vários nós em unidades de processamento gráfico (GPUs) da NVIDIA. Essa otimização ajuda a reduzir o tempo e o custo da conclusão de grandes jobs de treinamento. |
Otimização de hiperparâmetros
|
|
Os jobs de ajuste de hiperparâmetros executam vários testes do aplicativo de treinamento usando valores de hiperparâmetros diferentes. Ao especificar um intervalo de valores, a Vertex AI descobre os valores ideais para o modelo nesse intervalo. |
Segurança corporativa
|
|
A Vertex AI fornece os seguintes recursos de segurança empresarial:
|
Integrações de operações de ML (MLOps)
|
|
A Vertex AI oferece um conjunto de ferramentas de MLOps integradas e recursos que podem ser usados para as seguintes finalidades:
|
Fluxo de trabalho para treinamento personalizado
Veja no diagrama a seguir uma visão geral de alto nível do fluxo de trabalho de treinamento personalizado na Vertex AI. As seções a seguir descrevem cada etapa em detalhes.
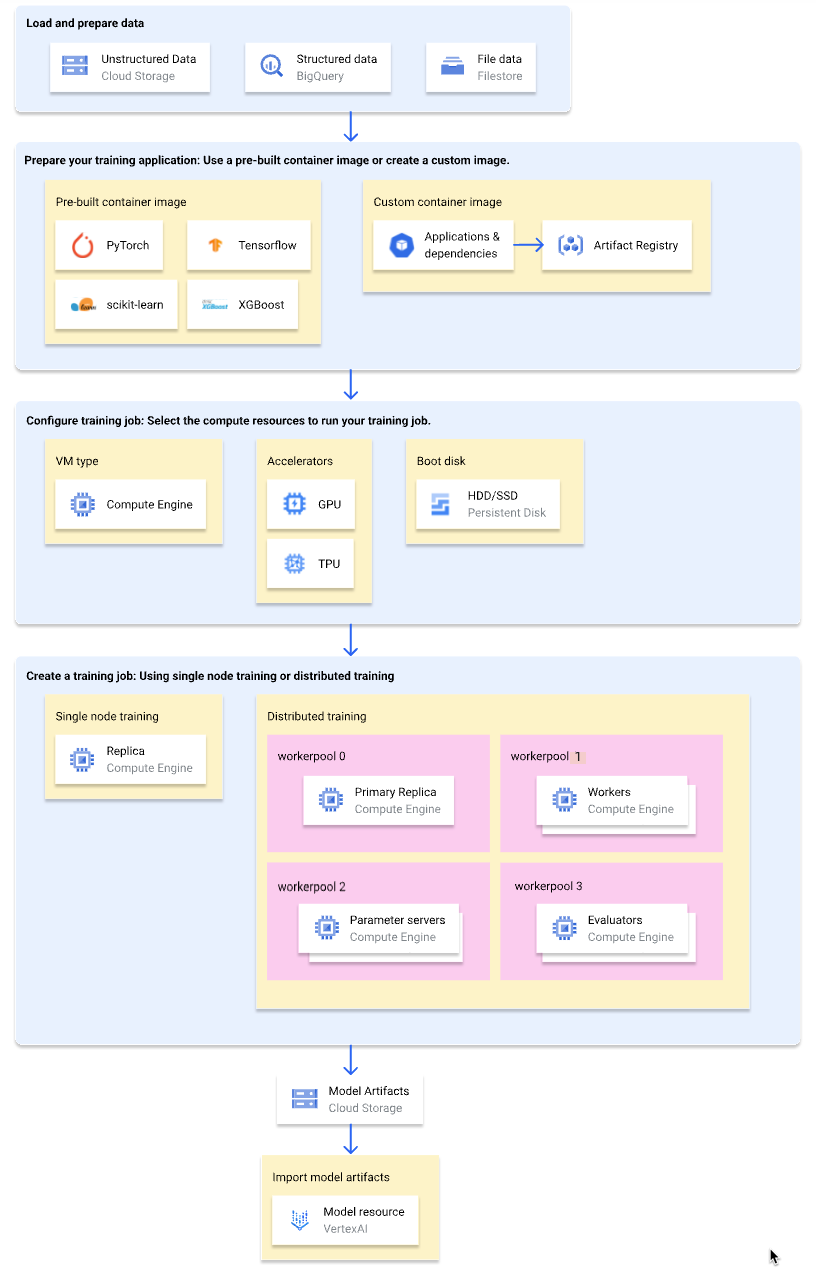
Carregar e preparar dados de treinamento
Para ter o melhor desempenho e suporte, use um dos seguintes serviços do Google Cloud como fonte de dados:
Para uma comparação desses serviços, consulte Visão geral da preparação de dados.
Também é possível especificar um conjunto de dados gerenciado da Vertex AI como a fonte de dados ao usar um pipeline de treinamento para treinar seu modelo. O treinamento de um modelo personalizado e um modelo do AutoML usando o mesmo conjunto de dados permite comparar a performance dos dois modelos.
Preparar o aplicativo de treinamento
Para preparar o aplicativo de treinamento para uso na Vertex AI, realize estas ações:
- Implemente práticas recomendadas de código de treinamento para a Vertex AI.
- Determine um tipo de imagem de contêiner a ser usada.
- Empacote o aplicativo de treinamento em um formato compatível com base no tipo de imagem do contêiner selecionado.
Implementar práticas recomendadas de código de treinamento
O aplicativo de treinamento precisa implementar as práticas recomendadas de código de treinamento para a Vertex AI. As práticas recomendadas estão relacionadas à capacidade do aplicativo de treinamento de realizar as seguintes ações:
- Acessar serviços Google Cloud .
- Carregar dados de entrada
- Ative o registro automático para o acompanhamento de experimentos.
- Exportar artefatos de modelo.
- Usar as variáveis de ambiente da Vertex AI.
- Garantir resiliência a reinicializações da VM.
Selecione um tipo de contêiner
A Vertex AI executa seu aplicativo de treinamento em uma imagem de contêiner do Docker. Uma imagem de contêiner do Docker é um pacote de software autônomo que contém código e todas as dependências, o que pode ser executado em quase todos os ambientes de computação. É possível especificar o URI de uma imagem de contêiner pré-criada para usar ou criar e fazer upload de uma imagem de contêiner personalizada com seu aplicativo de treinamento e dependências pré-instalados.
A tabela a seguir mostra as diferenças entre imagens de contêiner personalizadas e pré-criadas:
| Especificações | Imagens de contêiner pré-criadas | Imagens de contêiner personalizadas |
|---|---|---|
| Framework de ML | Cada imagem de contêiner é específica de um framework de ML. | Use qualquer framework de ML ou não use nenhum. |
| Versão do framework de MLs | Cada imagem de contêiner é específica a uma versão do framework de ML. | Use qualquer versão do framework de ML, incluindo versões secundárias e versões noturnas. |
| Dependências do aplicativo | As dependências comuns do framework de ML são pré-instaladas. É possível especificar outras dependências para instalar no aplicativo de treinamento. | Pré-instale as dependências necessárias ao aplicativo de treinamento. |
| Formato de exibição do aplicativo |
|
Pré-instale o aplicativo de treinamento na imagem do contêiner personalizado. |
| Configurar o recurso | Baixa | Alta |
| Recomendado para | Aplicativos de treinamento em Python baseados em uma estrutura e versão de ML com uma imagem de contêiner pré-criada disponível. |
|
Empacotar o aplicativo de treinamento
Depois de determinar o tipo de imagem do contêiner a ser usado, empacote o aplicativo de treinamento em um dos formatos a seguir com base no tipo de imagem do contêiner:
Um único arquivo Python para uso em um contêiner pré-criado
Escreva seu aplicativo de treinamento como um único arquivo Python e use o SDK da Vertex AI para Python para criar uma classe
CustomJobouCustomTrainingJob. O arquivo Python é empacotado em uma distribuição de origem do Python e instalado em uma imagem de contêiner pré-criada. Fornecer seu aplicativo de treinamento como um único arquivo Python é adequado para prototipagem. Para aplicativos de treinamento de produção, é provável que seu aplicativo de treinamento seja organizado em mais de um arquivo.Distribuição de origem do Python para uso em um contêiner pré-criado
Empacote o aplicativo de treinamento em uma ou mais distribuições de origem do Python e faça upload delas em um bucket do Cloud Storage. A Vertex AI instala as distribuições de origem em uma imagem de contêiner pré-criada quando você cria um job de treinamento.
Imagem de contêiner personalizada
Crie sua própria imagem de contêiner do Docker que tenha o aplicativo de treinamento e as dependências pré-instalados e faça o upload para o Artifact Registry. Se o aplicativo de treinamento for escrito em Python, você poderá seguir essas etapas usando um comando da CLI do Google Cloud.
Configure o job de treinamento
Um job de treinamento da Vertex AI executa as seguintes tarefas:
- Provisiona uma máquina virtual (VM) de (treinamento de nó único) ou mais (treinamento distribuído).
- Executa seu aplicativo de treinamento conteinerizado nas VMs provisionadas.
- Exclui as VMs após a conclusão do job de treinamento.
A Vertex AI oferece três tipos de jobs de treinamento para executar seu aplicativo de treinamento:
-
Um job personalizado (
CustomJob) executa o aplicativo de treinamento. Se você estiver usando uma imagem de contêiner pré-criada, os artefatos do modelo serão gerados no bucket do Cloud Storage especificado. Para imagens de contêiner personalizadas, seu aplicativo de treinamento também pode gerar artefatos de modelo para outros locais. Job de ajuste de hiperparâmetros
Um job de ajuste de hiperparâmetros (
HyperparameterTuningJob) executa vários testes do aplicativo de treinamento usando diferentes valores de hiperparâmetros até produzir artefatos de modelo com o hiperparâmetro de melhor desempenho valores. Especifique o intervalo de valores de hiperparâmetros a testar e as métricas a serem otimizadas.-
Um pipeline de treinamento (
CustomTrainingJob) executa um job personalizado ou de ajuste de hiperparâmetros e, opcionalmente, exporta os artefatos de modelo para a Vertex AI para criar um recurso de modelo. É possível especificar um conjunto de dados gerenciado da Vertex AI como sua fonte de dados.
Ao criar um job de treinamento, é preciso especificar os recursos de computação a serem usados para executar o aplicativo de treinamento e definir as configurações do contêiner.
Configurações de computação
Especifique os recursos de computação que serão usados em um job de treinamento. A Vertex AI oferece suporte para treinamento de nó único, em que o job de treinamento é executado em uma VM, e o treinamento distribuído, em que o job de treinamento é executado em várias VMs.
Os recursos de computação que você pode especificar para seu job de treinamento são os seguintes:
Tipo de máquina de VM
Diferentes tipos de máquina oferecem diferentes CPUs, tamanho de memória e largura de banda.
Unidades de processamento gráfico (GPUs)
É possível adicionar uma ou mais GPUs às VMs do tipo A2 ou N1. Se o aplicativo de treinamento for projetado para usar GPUs, a adição de GPUs poderá melhorar significativamente o desempenho.
Unidades de Processamento de Tensor (TPUs)
As TPUs foram projetadas especificamente para acelerar as cargas de trabalho de machine learning. Ao usar uma VM de TPU para treinamento, especifique apenas um pool de workers. Esse pool de workers pode ter apenas uma réplica.
Discos de inicialização
É possível usar SSDs (padrão) ou HDDs no disco de inicialização. Se o aplicativo de treinamento ler e gravar no disco, o uso de SSDs poderá melhorar o desempenho. Também é possível especificar o tamanho do disco de inicialização com base na quantidade de dados temporários que o aplicativo de treinamento grava no disco. Os discos de inicialização podem ter entre 100 GiB (padrão) e 64.000 GiB. Todas as VMs em um pool de workers precisam usar o mesmo tipo e tamanho do disco de inicialização.
Configurações do contêiner
As configurações de contêiner que você precisa fazer dependem do uso de uma imagem de contêiner pré-criada ou personalizada.
Configurações de contêiner pré-criadas:
- Especifique o URI da imagem de contêiner pré-criada que você quer usar.
- Se o aplicativo de treinamento for empacotado como uma distribuição de origem Python, especifique o URI do Cloud Storage em que o pacote está localizado.
- Especifique o módulo do ponto de entrada do aplicativo de treinamento.
- Opcional: especifique uma lista de argumentos de linha de comando para transmitir ao módulo de ponto de entrada do seu aplicativo de treinamento.
Configurações de contêiner personalizadas:
- Especifique o URI da imagem de contêiner personalizada, que pode ser um URI do Artifact Registry ou do Docker Hub.
- Opcional: substitua as instruções
ENTRYPOINTouCMDna imagem do contêiner.
Criar um job de treinamento
Depois que os dados de treinamento e o aplicativo de treinamento estiverem preparados, execute o aplicativo de treinamento criando um dos jobs de treinamento a seguir:
- Criar um job personalizado
- Criar um job de ajuste de hiperparâmetros.
- Criar um pipeline de treinamento.
Para criar o job de treinamento, é possível usar o console Google Cloud , a CLI do Google Cloud, o SDK da Vertex AI para Python ou a API Vertex AI.
(Opcional) Importar artefatos de modelo para a Vertex AI
Seu aplicativo de treinamento provavelmente gera um ou mais artefatos de modelo em um local especificado, geralmente um bucket do Cloud Storage. Antes de receber inferências na Vertex AI dos seus artefatos de modelo, primeiro importe os artefatos para o Vertex AI Model Registry.
Assim como as imagens de contêiner para treinamento, a Vertex AI oferece a opção de usar imagens de contêiner pré-criadas ou personalizadas para inferências. Se uma imagem de contêiner pré-criada para inferências estiver disponível para sua estrutura de ML e versão do framework, recomendamos o uso de uma imagem de contêiner pré-criada.
A seguir
- Receba inferências do modelo.
- Avalie o modelo.
- Veja o tutorial Olá, treinamento personalizado para ver instruções detalhadas sobre o treinamento de um modelo de classificação de imagens do Keras Keras na Vertex AI.