表格工作流是一组集成式、全代管式和可扩缩流水线,适用于使用表格数据的端对端机器学习。它利用 Google 的技术进行模型开发,并为您提供可满足您需求的自定义选项。
优势
- 全代管式:您不必担心更新、依赖项和冲突。
- 易于扩缩:随着工作负载或数据集的增长,您无需重新设计基础架构。
- 优化的性能:系统会自动为工作流要求配置正确的硬件。
- 深度集成:与 Vertex AI MLOps 套件中的产品兼容(例如 Vertex AI Pipelines 和 Vertex AI Experiments),让您可以在短时间内运行许多实验。
技术概览
每个工作流都是 Vertex AI Pipelines 的代管式实例。
Vertex AI Pipelines 是一种用于运行 Kubeflow 流水线的无服务器服务。您可以使用流水线来自动执行及监控机器学习和数据准备任务。流水线中的每个步骤都会执行流水线工作流的一部分。例如,一个流水线可以包含用于拆分数据、转换数据类型和训练模型的各个步骤。由于步骤是流水线组件的实例,因此步骤中包含输入、输出和容器映像。步骤输入可根据流水线的输入进行设置,也可以依赖于此流水线中其他步骤的输出。这些依赖项将流水线的工作流定义为有向非循环图。
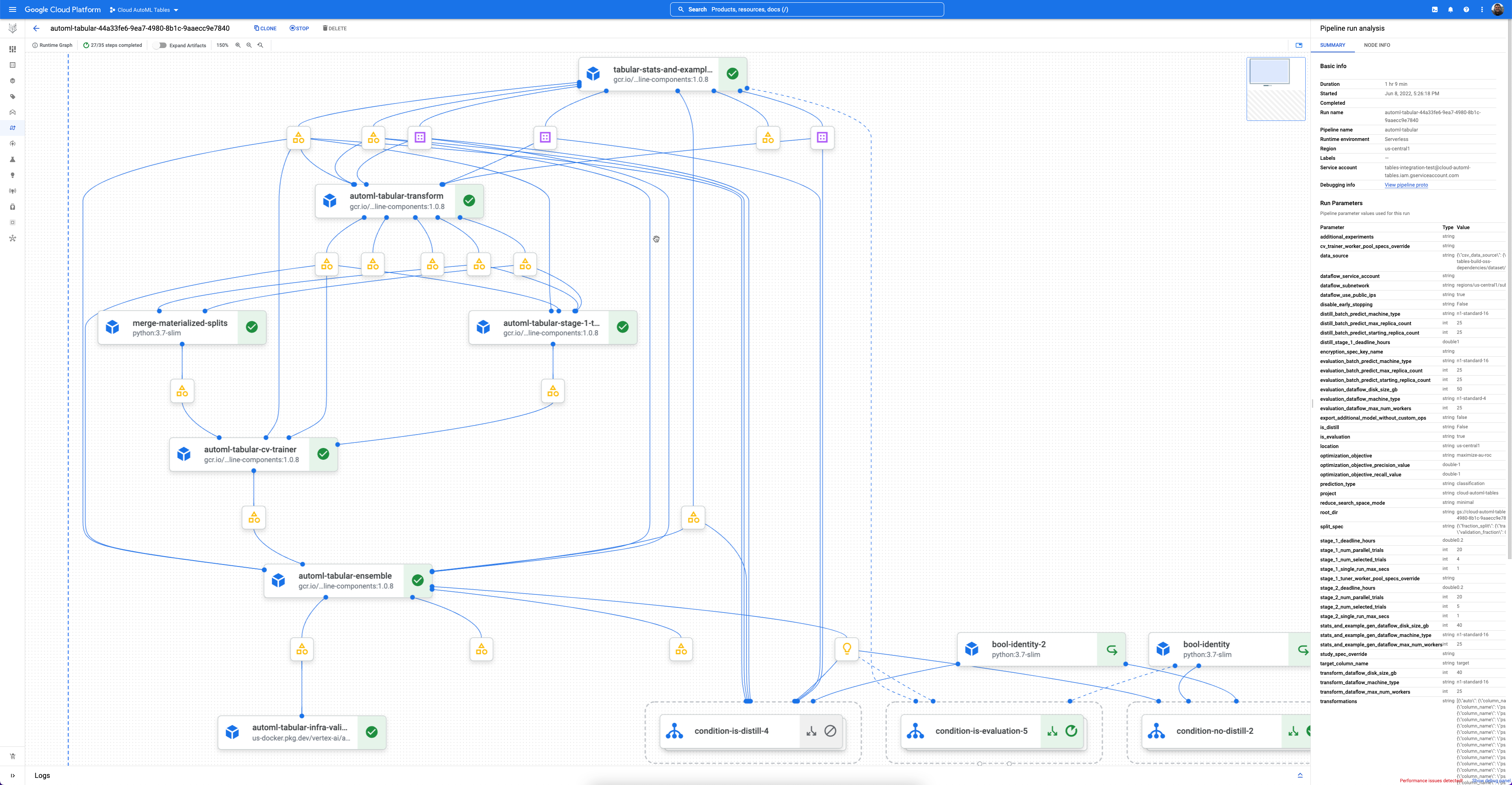
开始使用
在大多数情况下,使用Google Cloud Pipeline Components SDK 定义和运行流水线。以下示例代码演示了此过程。请注意,代码的实际实现可能会有所不同。
// Define the pipeline and the parameters
template_path, parameter_values = tabular_utils.get_default_pipeline_and_parameters(
…
optimization_objective=optimization_objective,
data_source=data_source,
target_column_name=target_column_name
…)
// Run the pipeline
job = pipeline_jobs.PipelineJob(..., template_path=template_path, parameter_values=parameter_values)
job.run(...)
如需查看 Colab 和笔记本示例,请与您的销售代表联系或填写申请表。
版本控制和维护
表格工作流具有有效的版本控制系统,可让您持续更新和改进,而不会对应用造成破坏性更改。
每个工作流都作为Google Cloud Pipeline Components SDK 的一部分进行发布和更新。任何工作流的更新和修改都将作为该工作流的新版本发布。每个工作流的先前版本始终通过旧版本的 SDK 提供。如果 SDK 版本已固定,则工作流的版本也会固定。
可用的工作流
Vertex AI 提供以下表格工作流:
| 名称 | 类型 | 可用性 |
|---|---|---|
| Feature Transform Engine | 特征工程 | 公开预览版 |
| 端到端 AutoML | 分类和回归 | 正式版 |
| TabNet | 分类和回归 | 公开预览版 |
| Wide & Deep | 分类和回归 | 公开预览版 |
| 预测 | 预测 | 公开预览版 |
如需了解详情和查看笔记本示例,请与您的销售代表联系或填写申请表。
Feature Transform Engine
Feature Transform Engine 执行特征选择和特征转换。如果启用了特征选择,Feature Transform Engine 会创建一组经过排序的重要特征。如果启用了特征转换,Feature Transform Engine 会处理特征,以确保模型训练和模型服务的输入一致。Feature Transform Engine 可以单独使用,也可以与任何表格训练工作流结合使用。它支持 TensorFlow 框架和非 TensorFlow 框架。
如需了解详情,请参阅特征工程。
用于分类和回归的表格工作流
端到端 AutoML 表格工作流
端到端 AutoML 的表格工作流是用于分类和回归任务的完整 AutoML 流水线。它与 AutoML API 类似,但允许您选择要控制的内容及自动化的内容。您可以控制流水线中的每个步骤,而不是控制整个流水线。这些流水线控制包括:
- 数据拆分
- 特征工程
- 架构搜索
- 模型训练
- 模型集成学习
- 模型提炼
优势
- 支持大小超过 1 TB 且最多包含 1000 列的大型数据集。
- 使您能够通过限制架构类型的搜索空间或跳过架构搜索来提高稳定性并缩短训练时间。
- 允许您通过手动选择用于训练和架构搜索的硬件来提高训练速度。
- 允许您通过精馏或更改集成学习规模来缩减模型规模并缩短延迟时间。
- 每个 AutoML 组件都可以在强大的流水线图界面中进行检查,使您可以查看转换后的数据表、评估的模型架构以及更多详细信息。
- 每个 AutoML 组件都可提供更高的灵活性和透明度,例如能够自定义参数、硬件,查看进程状态、日志等。
输入-输出
- 将 BigQuery 表或 Cloud Storage 中的 CSV 文件作为输入。
- 生成一个 Vertex AI 模型作为输出。
- 中间输出包括数据集统计信息和数据集拆分。
如需了解详情,请参阅端到端 AutoML 的表格工作流。
TabNet 的表格工作流
TabNet 的表格工作流是可用于训练分类或回归模型的流水线。 TabNet 使用顺序注意力来选择每个决策步骤要推理的特征。这提高了可解释性和学习效率,因为学习容量用于最显著的特征。
优势
- 根据数据集大小、推理类型和训练预算自动选择适当的超参数搜索空间。
- 与 Vertex AI 集成。经过训练的模型是 Vertex AI 模型。您可以运行批量推理或部署模型以立即进行在线推理。
- 提供固有的模型可解释性。您可以深入了解 TabNet 使用哪些功能来做出决定。
- 支持 GPU 训练。
输入-输出
从 Cloud Storage 获取 BigQuery 表或 CSV 文件作为输入,并提供 Vertex AI 模型作为输出。
如需了解详情,请参阅 TabNet 的表格工作流。
Wide & Deep 的表格工作流
Wide & Deep 的表格工作流是可用于训练分类或回归模型的流水线。 Wide & Deep 会联合广度线性模型和深度神经网络进行训练。它结合了记忆和泛化的优势。一些在线实验还表明,与仅涉及广度和仅涉及深度的模型相比,Wide & Deep 显著提高了 Google 商店应用的流量获取。
优势
- 与 Vertex AI 集成。经过训练的模型是 Vertex AI 模型。您可以运行批量推理或部署模型以立即进行在线推理。
输入-输出
从 Cloud Storage 获取 BigQuery 表或 CSV 文件作为输入,并提供 Vertex AI 模型作为输出。
如需了解详情,请参阅 Wide & Deep 的表格工作流。
用于预测的表格式工作流
预测表格工作流
用于预测的表格工作流是预测任务的完整流水线。它与 AutoML API 类似,但允许您选择要控制的内容及自动化的内容。您可以控制流水线中的每个步骤,而不是控制整个流水线。这些流水线控制包括:
- 数据拆分
- 特征工程
- 架构搜索
- 模型训练
- 模型集成学习
优势
- 支持大小不超过 1TB 且最多包含 200 列的大型数据集。
- 使您能够通过限制架构类型的搜索空间或跳过架构搜索来提高稳定性并缩短训练时间。
- 允许您通过手动选择用于训练和架构搜索的硬件来提高训练速度。
- 允许您通过更改集成学习规模,来缩减模型规模并缩短延迟时间。
- 每个组件都可以在强大的流水线图界面中进行检查,使您可以查看转换后的数据表、评估的模型架构以及更多详细信息。
- 每个组件都可提供更高的灵活性和透明度,例如能够自定义参数、硬件,查看进程状态、日志等。
输入-输出
- 将 BigQuery 表或 Cloud Storage 中的 CSV 文件作为输入。
- 生成一个 Vertex AI 模型作为输出。
- 中间输出包括数据集统计信息和数据集拆分。
如需了解详情,请参阅用于预测的表格式工作流。
后续步骤
- 了解端到端 AutoML 的表格工作流。
- 了解 TabNet 的表格工作流。
- 了解 Wide & Deep 的表格工作流。
- 了解用于预测的表格式工作流。
- 了解特征工程。
- 了解表格工作流的价格。