Cette page explique comment entraîner un modèle de prévision à partir d'un ensemble de données tabulaire avec Workflow tabulaire pour les prévisions.
Pour en savoir plus sur les comptes de service utilisés par ce workflow, consultez la page Comptes de service pour les workflows tabulaires.
Si vous recevez une erreur liée aux quotas lors de l'exécution de Workflow tabulaire pour les prévisions, vous devrez peut-être demander un quota plus élevé. Pour en savoir plus, consultez la page Gérer les quotas des workflows tabulaires.
Le workflow tabulaire pour les prévisions n'est pas compatible avec l'exportation de modèles.
API de workflows
Ce workflow utilise les API suivantes :
- Vertex AI
- Dataflow
- Compute Engine
- Cloud Storage
Obtenir l'URI du résultat du réglage d'hyperparamètres précédent
Si vous avez déjà exécuté Workflow tabulaire pour les prévisions, vous pouvez utiliser le résultat du réglage d'hyperparamètres de l'exécution précédente pour économiser du temps et des ressources d'entraînement. Vous pouvez trouver le résultat du réglage d'hyperparamètres précédent en utilisant la console Google Cloud ou en le chargeant par programmation avec l'API.
Console Google Cloud
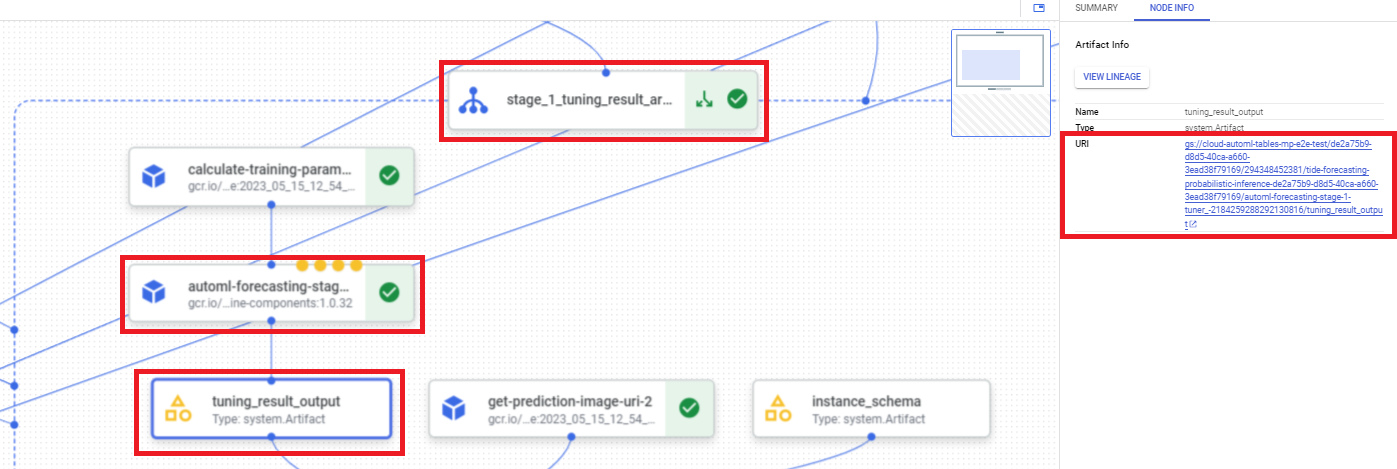
Pour rechercher l'URI du résultat des réglages d'hyperparamètres à l'aide de la console Google Cloud, procédez comme suit :
Dans la section Vertex AI de la console Google Cloud, accédez à la page Pipelines.
Sélectionnez l'onglet Exécutions.
Sélectionnez l'exécution de pipeline que vous souhaitez utiliser.
Sélectionnez Développer les artefacts.
Cliquez sur le composant exit-handler-1.
Cliquez sur le composant stage_1_tuning_result_artifact_uri_empty.
Recherchez le composant automl-forecasting-stage-1-tuner.
Cliquez sur l'artefact tuning_result_output associé.
Sélectionnez l'onglet Informations sur le nœud.
Copiez l'URI à utiliser à l'étape Entraîner un modèle.
API : Python
L'exemple de code suivant montre comment charger le résultat du réglage des hyperparamètres à l'aide de l'API. La variable job fait référence à l'exécution précédente du pipeline de modèle.
def get_task_detail(
task_details: List[Dict[str, Any]], task_name: str
) -> List[Dict[str, Any]]:
for task_detail in task_details:
if task_detail.task_name == task_name:
return task_detail
pipeline_task_details = job.gca_resource.job_detail.task_details
stage_1_tuner_task = get_task_detail(
pipeline_task_details, "automl-forecasting-stage-1-tuner"
)
stage_1_tuning_result_artifact_uri = (
stage_1_tuner_task.outputs["tuning_result_output"].artifacts[0].uri
)
Entraîner un modèle
L'exemple de code suivant montre comment exécuter un pipeline d'entraînement de modèle :
job = aiplatform.PipelineJob(
...
template_path=template_path,
parameter_values=parameter_values,
...
)
job.run(service_account=SERVICE_ACCOUNT)
Le paramètre facultatif service_account dans job.run() vous permet de définir le compte de service Vertex AI Pipelines sur le compte de votre choix.
Vertex AI est compatible avec les méthodes suivantes pour l'entraînement de votre modèle :
Encodeur dense de séries temporelles (TiDE). Pour utiliser cette méthode d'entraînement de modèle, définissez vos valeurs de pipeline et de paramètres en utilisant la fonction suivante :
template_path, parameter_values = automl_forecasting_utils.get_time_series_dense_encoder_forecasting_pipeline_and_parameters(...)Transformateur de fusion temporelle (TFT). Pour utiliser cette méthode d'entraînement de modèle, définissez vos valeurs de pipeline et de paramètres en utilisant la fonction suivante :
template_path, parameter_values = automl_forecasting_utils.get_temporal_fusion_transformer_forecasting_pipeline_and_parameters(...)AutoML (L2L). Pour utiliser cette méthode d'entraînement de modèle, définissez vos valeurs de pipeline et de paramètres en utilisant la fonction suivante :
template_path, parameter_values = automl_forecasting_utils.get_learn_to_learn_forecasting_pipeline_and_parameters(...)Seq2Seq+. Pour utiliser cette méthode d'entraînement de modèle, définissez vos valeurs de pipeline et de paramètres en utilisant la fonction suivante :
template_path, parameter_values = automl_forecasting_utils.get_sequence_to_sequence_forecasting_pipeline_and_parameters(...)
Pour en savoir plus, consultez Méthodes d'entraînement des modèles.
Les données d'entraînement peuvent être un fichier CSV dans Cloud Storage ou une table dans BigQuery.
Voici un sous-ensemble de paramètres d'entraînement de modèle :
| Nom du paramètre | Type | Définition |
|---|---|---|
optimization_objective |
Chaîne | Par défaut, Vertex AI minimise la racine carrée de l'erreur quadratique moyenne (RMSE). Si vous souhaitez un objectif d'optimisation différent pour votre modèle de prévision, choisissez l'une des options disponibles dans la section Objectifs d'optimisation pour les modèles de prévision. Si vous choisissez de minimiser la perte de quantiles, vous devez également spécifier une valeur pour quantiles. |
enable_probabilistic_inference |
Booléen | Si la valeur est true, Vertex AI modélise la distribution de probabilité de la prévision. L'inférence probabiliste peut améliorer la qualité du modèle en gérant les données comportant du bruit et en quantifiant l'incertitude. Si des quantiles sont spécifiés, Vertex AI renvoie également les quantiles de la distribution. L'inférence probabiliste n'est compatible qu'avec les méthodes d'entraînement de séries temporelles (TiDE) et AutoML (L2L). L'inférence probabiliste n'est pas compatible avec l'objectif d'optimisation minimize-quantile-loss. |
quantiles |
Liste[float] | Quantiles à utiliser pour l'objectif d'optimisation minimize-quantile-loss et l'inférence probabiliste. Fournissez une liste de cinq numéros uniques au maximum entre 0 et 1, exclusifs. |
time_column |
Chaîne | Colonne d'heure Pour en savoir plus, consultez la section Exigences concernant la structure des données. |
time_series_identifier_columns |
Liste[chaîne] | Colonnes d'identifiant de série temporelle Pour en savoir plus, consultez la section Exigences concernant la structure des données. |
weight_column |
Chaîne | (facultatif) Colonne de pondération Pour en savoir plus, consultez la section Ajouter des pondérations aux données d'entraînement. |
time_series_attribute_columns |
Liste[chaîne] | (facultatif) Nom ou noms des colonnes qui sont des attributs de série temporelle Pour en savoir plus, consultez la section Type de fonctionnalité et disponibilité au moment de la prévision. |
available_at_forecast_columns |
Liste[chaîne] | (facultatif) nom ou noms des colonnes covariées dont la valeur est connue au moment de la prévision. Pour en savoir plus, consultez la section Type de fonctionnalité et disponibilité au moment de la prévision. |
unavailable_at_forecast_columns |
Liste[chaîne] | (facultatif) nom ou noms des colonnes covariées dont la valeur est inconnue au moment de la prévision. Pour en savoir plus, consultez la section Type de fonctionnalité et disponibilité au moment de la prévision. |
forecast_horizon |
Entier | (facultatif) L'horizon de prévision détermine jusqu'à quand le modèle prévoit la valeur cible pour chaque ligne de données de prédiction. Pour en savoir plus, consultez la section Horizon de prévision, fenêtre de contexte et période de prévision. |
context_window |
Entier | (facultatif) La fenêtre de contexte définit jusqu'où le modèle remonte dans le temps lors de l'entraînement (et des prévisions). En d'autres termes, pour chaque point de données d'entraînement, la fenêtre de contexte détermine jusqu'à quelle période le modèle recherche des modèles prédictifs. Pour en savoir plus, consultez la section Horizon de prévision, fenêtre de contexte et période de prévision. |
window_max_count |
Entier | (facultatif) Vertex AI génère des fenêtres de prévision à partir des données d'entrée à l'aide d'une stratégie de fenêtre glissante. La stratégie par défaut est Count (Nombre). La valeur par défaut pour le nombre maximal de fenêtres est 100,000,000. Définissez ce paramètre pour fournir une valeur personnalisée pour le nombre maximal de fenêtres. Pour en savoir plus, consultez la section Stratégies de fenêtre glissante. |
window_stride_length |
Entier | (facultatif) Vertex AI génère des fenêtres de prévision à partir des données d'entrée à l'aide d'une stratégie de fenêtre glissante. Pour sélectionner la stratégie Pas, définissez ce paramètre sur la valeur de la longueur de pas. Pour en savoir plus, consultez la section Stratégies de fenêtre glissante. |
window_predefined_column |
Chaîne | (facultatif) Vertex AI génère des fenêtres de prévision à partir des données d'entrée à l'aide d'une stratégie de fenêtre glissante. Pour sélectionner la stratégie Colonne, définissez ce paramètre sur le nom de la colonne avec des valeurs True ou False. Pour en savoir plus, consultez la section Stratégies de fenêtre glissante. |
holiday_regions |
Liste[chaîne] | (facultatif) Vous pouvez sélectionner une ou plusieurs régions géographiques pour activer la modélisation des effets des jours fériés. Pendant l'entraînement, Vertex AI crée des caractéristiques catégorielles de jours fériés dans le modèle en fonction de la date de time_column et des régions géographiques spécifiées. Par défaut, la modélisation des effets des jours fériés est désactivée. Pour en savoir plus, consultez la page Jours fériés par région. |
predefined_split_key |
Chaîne | (facultatif) Par défaut, Vertex AI utilise un algorithme de répartition chronologique pour séparer vos données de prévision en trois divisions. Si vous souhaitez contrôler les lignes de données d'entraînement utilisées par la répartition, indiquez le nom de la colonne contenant les valeurs de répartition des données (TRAIN, VALIDATION, TEST). Pour en savoir plus, consultez la section Répartition des données pour la prévision. |
training_fraction |
Float | (facultatif) Par défaut, Vertex AI utilise un algorithme de répartition chronologique pour séparer vos données de prévision en trois divisions. 80 % des données sont attribuées à l'ensemble d'entraînement, 10 % à la division de validation et 10% à la division de test. Définissez ce paramètre si vous souhaitez personnaliser la fraction des données attribuée à l'ensemble d'entraînement. Pour en savoir plus, consultez la section Répartition des données pour la prévision. |
validation_fraction |
Float | (facultatif) Par défaut, Vertex AI utilise un algorithme de répartition chronologique pour séparer vos données de prévision en trois divisions. 80 % des données sont attribuées à l'ensemble d'entraînement, 10 % à la division de validation et 10% à la division de test. Définissez ce paramètre si vous souhaitez personnaliser la fraction des données attribuée à l'ensemble de validation. Pour en savoir plus, consultez la section Répartition des données pour la prévision. |
test_fraction |
Float | (facultatif) Par défaut, Vertex AI utilise un algorithme de répartition chronologique pour séparer vos données de prévision en trois divisions. 80 % des données sont attribuées à l'ensemble d'entraînement, 10 % à la division de validation et 10% à la division de test. Définissez ce paramètre si vous souhaitez personnaliser la fraction des données attribuée à l'ensemble de test. Pour en savoir plus, consultez la section Répartition des données pour la prévision. |
data_source_csv_filenames |
Chaîne | URI d'un fichier CSV stocké dans Cloud Storage. |
data_source_bigquery_table_path |
Chaîne | URI d'une table BigQuery. |
dataflow_service_account |
Chaîne | (Facultatif) Compte de service personnalisé permettant d'exécuter des tâches Dataflow. La tâche Dataflow peut être configurée pour utiliser des adresses IP privées et un sous-réseau VPC spécifique. Ce paramètre sert de valeur de remplacement pour le compte de service de nœud de calcul Dataflow par défaut. |
run_evaluation |
Booléen | Si ce champ est défini sur True, Vertex AI évalue le modèle assemblé sur la division de test. |
evaluated_examples_bigquery_path |
Chaîne | Chemin de l'ensemble de données BigQuery utilisé lors de l'évaluation du modèle. L'ensemble de données sert de destination pour les exemples prédits. La valeur du paramètre doit être définie si run_evaluation est défini sur True et doit être au format suivant : bq://[PROJECT].[DATASET]. |
Transformations
Vous pouvez fournir un mappage de dictionnaires de résolutions automatiques ou par type avec des colonnes de caractéristiques. Les types compatibles sont : auto, numérique, catégorielle, texte et horodatage.
| Nom du paramètre | Type | Définition |
|---|---|---|
transformations |
Dictionnaire[chaîne, Liste[chaîne]] | Mappage de dictionnaire avec des résolutions automatiques ou par type |
Le code suivant fournit une fonction d'assistance pour renseigner le paramètre transformations. Elle montre également comment utiliser cette fonction pour appliquer des transformations automatiques à un ensemble de colonnes défini par une variable features.
def generate_transformation(
auto_column_names: Optional[List[str]]=None,
numeric_column_names: Optional[List[str]]=None,
categorical_column_names: Optional[List[str]]=None,
text_column_names: Optional[List[str]]=None,
timestamp_column_names: Optional[List[str]]=None,
) -> List[Dict[str, Any]]:
if auto_column_names is None:
auto_column_names = []
if numeric_column_names is None:
numeric_column_names = []
if categorical_column_names is None:
categorical_column_names = []
if text_column_names is None:
text_column_names = []
if timestamp_column_names is None:
timestamp_column_names = []
return {
"auto": auto_column_names,
"numeric": numeric_column_names,
"categorical": categorical_column_names,
"text": text_column_names,
"timestamp": timestamp_column_names,
}
transformations = generate_transformation(auto_column_names=features)
Pour en savoir plus sur les transformations, consultez la page Types de données et transformations.
Options de personnalisation du workflow
Vous pouvez personnaliser le workflow tabulaire pour la prévision en définissant les valeurs d'argument transmises dans la définition de pipeline. Vous pouvez personnaliser votre workflow de différentes manières :
- Configurer le matériel
- Ignorer la recherche d'architecture
Configurer le matériel
Le paramètre d'entraînement de modèle suivant vous permet de configurer les types et le nombre de machines pour l'entraînement. Cette option est idéale si vous disposez d'un ensemble de données volumineux et que vous souhaitez optimiser le matériel de la machine en conséquence.
| Nom du paramètre | Type | Définition |
|---|---|---|
stage_1_tuner_worker_pool_specs_override |
Dict[String, Any] | (facultatif) Configuration personnalisée des types et du nombre de machines pour l'entraînement. Ce paramètre configure le composant automl-forecasting-stage-1-tuner du pipeline. |
Le code suivant montre comment définir le type de machine n1-standard-8 pour le nœud principal TensorFlow et le type de machine n1-standard-4 pour le nœud d'évaluateur TensorFlow :
worker_pool_specs_override = [
{"machine_spec": {"machine_type": "n1-standard-8"}}, # override for TF chief node
{}, # override for TF worker node, since it's not used, leave it empty
{}, # override for TF ps node, since it's not used, leave it empty
{
"machine_spec": {
"machine_type": "n1-standard-4" # override for TF evaluator node
}
}
]
Ignorer la recherche d'architecture
Le paramètre suivant vous permet d'exécuter le pipeline sans la recherche d'architecture et de fournir un ensemble d'hyperparamètres issus d'une exécution de pipeline précédente.
| Nom du paramètre | Type | Définition |
|---|---|---|
stage_1_tuning_result_artifact_uri |
Chaîne | (Facultatif) URI issu du réglage des hyperparamètres à partir d'une exécution de pipeline précédente. |
Étapes suivantes
- Découvrez les prédictions par lot pour les modèles de prévision.
- Découvrez les tarifs de l'entraînement de modèle.