Vertex AI fournit deux options pour projeter les valeurs futures à l'aide de votre modèle de prévision entraîné : les prédictions en ligne et les prédictions par lot.
Une prédiction en ligne est une requête synchrone. Utilisez les prédictions en ligne lorsque vous effectuez des requêtes en réponse à une entrée d'une application ou dans d'autres situations nécessitant une inférence rapide.
Une requête de prédiction par lot est une requête asynchrone. Utilisez les prédictions par lots lorsque vous n'avez pas besoin d'une réponse immédiate et souhaitez traiter les données accumulées en une seule requête.
Cette page explique comment projeter des valeurs futures à l'aide de prédictions par lots. Pour apprendre à projeter des valeurs à l'aide de prédictions en ligne, consultez la page Obtenir des prédictions en ligne pour un modèle de prévision.
Vous pouvez demander des prédictions par lots directement à partir de la ressource de modèle.
Vous pouvez demander une prédiction avec des explications (également appelées attributions de caractéristiques) pour voir comment votre modèle est arrivé à une prédiction. Les valeurs d'importance des caractéristiques locales indiquent dans quelle mesure chaque caractéristique a contribué au résultat prédit. Pour obtenir une présentation des concepts, consultez la page Attributions de caractéristiques pour la prévision.
Pour en savoir plus sur les tarifs des prédictions par lots, consultez la page Tarifs des workflows tabulaires.
Avant de commencer
Avant de pouvoir effectuer une requête de prédiction par lot, vous devez d'abord entraîner un modèle.
Données d'entrée
Les données d'entrée des requêtes de prédiction par lot sont les données que le modèle utilise pour créer des prévisions. Vous pouvez fournir des données d'entrée dans l'un des deux formats suivants :
- Objets CSV dans Cloud Storage
- Tables BigQuery
Nous vous recommandons d'utiliser le même format pour les données d'entrée et l'entraînement du modèle. Par exemple, si vous avez entraîné votre modèle à l'aide de données dans BigQuery, il est préférable d'utiliser une table BigQuery comme entrée pour la prédiction par lot. Comme Vertex AI traite tous les champs d'entrée CSV comme des chaînes, l'utilisation de formats de données d'entrée et d'entraînement différents peut entraîner des erreurs.
Votre source de données doit contenir des données tabulaires incluant toutes les colonnes, dans n'importe quel ordre, qui ont été utilisées pour entraîner le modèle. Vous pouvez inclure des colonnes qui ne figuraient pas dans les données d'entraînement, ou qui y figuraient mais qui ont été exclues de l'entraînement. Ces colonnes supplémentaires sont incluses dans le résultat, mais n'affectent pas les résultats de la prévision.
Exigences concernant les données d'entrée
Les entrées des modèles de prévision doivent respecter les exigences suivantes :
- Toutes les valeurs de la colonne Heure doivent être présentes et valides.
- La fréquence des données d'entrée et d'entraînement doit correspondre. S'il manque des lignes dans la série temporelle, vous devez les insérer manuellement en fonction des connaissances du domaine.
- Les séries temporelles avec des horodatages en double sont supprimées des prédictions. Pour les inclure, supprimez les horodatages en double.
- Fournissez des données de l'historique pour chaque série temporelle à prédire. Pour les prévisions les plus précises, la quantité de données doit être égale à la fenêtre de contexte, définie lors de l'entraînement du modèle. Par exemple, si la fenêtre de contexte est de 14 jours, indiquez au moins 14 jours de données historiques. Si vous fournissez moins de données, Vertex AI remplit les données avec des valeurs vides.
- La prévision commence à la première ligne d'une série temporelle (classée par heure) et comporte une valeur nulle dans la colonne cible. La valeur nulle doit être continue au sein de la série temporelle. Par exemple, si la colonne cible est classée par heure, vous ne pouvez pas avoir une valeur telle que
1,2,null,3,4,nulletnullpour une seule série temporelle. Pour les fichiers CSV, Vertex AI traite une chaîne vide comme une valeur nulle et, pour BigQuery, les valeurs nulles sont compatibles de manière native.
Table BigQuery
Si vous choisissez une table BigQuery comme entrée, vous devez remplir les conditions suivantes :
- Les tables de source de données BigQuery ne doivent pas dépasser 100 Go.
- Si la table se trouve dans un autre projet, vous devez accorder le rôle
BigQuery Data Editorau compte de service Vertex AI de ce projet.
Fichier CSV
Si vous choisissez un objet CSV dans Cloud Storage comme entrée, vous devez remplir les conditions suivantes :
- La source de données doit commencer par une ligne d'en-tête avec les noms de colonne.
- Chaque objet de source de données ne doit pas dépasser 10 Go. Vous pouvez inclure plusieurs fichiers, jusqu'à une taille maximale de 100 Go.
- Si le bucket Cloud Storage se trouve dans un autre projet, vous devez attribuer le rôle
Storage Object Creatorau compte de service Vertex AI de ce projet. - Vous devez placer toutes les chaînes entre guillemets doubles (").
Format de sortie
Le format de sortie de votre requête de prédiction par lot n'a pas besoin d'être identique au format utilisé pour l'entrée. Par exemple, si vous avez utilisé la table BigQuery en tant qu'entrée, vous pouvez générer les résultats de la prévision dans un objet CSV dans Cloud Storage.
Envoyer une requête de prédiction par lot au modèle
Pour effectuer des requêtes de prédiction par lot, vous pouvez utiliser la console Google Cloud ou l'API Vertex AI. La source de données d'entrée peut être des objets CSV stockés dans un bucket Cloud Storage ou des tables BigQuery. Selon la quantité de données que vous envoyez en tant qu'entrée, une tâche de prédiction par lot peut prendre un certain temps.
console Google Cloud
Utilisez la console Google Cloud pour demander une prédiction par lot.
- Dans la console Google Cloud, dans la section Vertex AI, accédez à la page Prédictions par lot.
- Cliquez sur Créer pour ouvrir la fenêtre Nouvelle prédiction par lot.
- Pour Définir votre prédiction par lot, procédez comme suit :
- Saisissez un nom pour la prédiction par lot.
- Dans Nom du modèle, sélectionnez le nom du modèle à utiliser pour cette prédiction par lot.
- Pour Version, sélectionnez la version du modèle.
- Dans le champ Sélectionner une source, indiquez si vos données d'entrée source sont un fichier CSV sur Cloud Storage ou une table dans BigQuery.
- Pour les fichiers CSV, spécifiez l'emplacement Cloud Storage où se trouve votre fichier d'entrée CSV.
- Pour les tables BigQuery, spécifiez l'ID du projet dans lequel se trouve la table, l'ID de l'ensemble de données BigQuery, et l'ID de la table ou de la vue BigQuery.
- Dans résultat de la prédiction par lot, sélectionnez CSV ou BigQuery.
- Pour le format CSV, spécifiez le bucket Cloud Storage dans lequel Vertex AI stocke votre sortie.
- Pour BigQuery, vous pouvez spécifier un ID de projet ou un ensemble de données existant :
- Pour spécifier l'ID du projet, saisissez l'ID du projet dans le cham ID du projet Google Cloud. Vertex AI crée automatiquement un ensemble de données de sortie.
- Pour spécifier un ensemble de données existant, saisissez son chemin BigQuery dans le champ ID du projet Google Cloud, tel que
bq://projectid.datasetid.
- Facultatif. Si votre destination de sortie est BigQuery ou JSONL dans Cloud Storage, vous pouvez activer les attributions de caractéristiques en plus des prédictions. Pour ce faire, sélectionnez Activer les attributions de caractéristiques pour ce modèle. Les attributions de caractéristiques ne sont pas compatibles avec le format CSV sur Cloud Storage. En savoir plus
- Facultatif : L'analyse Model Monitoring pour les prédictions par lot est disponible en version preview. Consultez la section Prérequis pour ajouter une configuration de détection de décalages à votre tâche de prédiction par lot.
- Cliquez sur Activer la surveillance du modèle pour cette prédiction par lot.
- Sélectionnez une source de données d'entraînement. Saisissez le chemin d'accès ou l'emplacement des données pour la source de données d'entraînement que vous avez sélectionnée.
- Facultatif : Sous Seuils d'alerte, spécifiez les seuils auxquels les alertes doivent être déclenchées.
- Dans le champ E-mails de notification, saisissez une ou plusieurs adresses e-mail afin de recevoir des alertes lorsqu'un modèle dépasse un seuil d'alerte.
- Facultatif : Pour les Canaux de notification, ajoutez des canaux Cloud Monitoring afin de recevoir des alertes lorsqu'un modèle dépasse un seuil d'alerte. Vous pouvez sélectionner des canaux Cloud Monitoring existants ou en créer un en cliquant sur Gérer les canaux de notification. La console est compatible avec les canaux de notification PagerDuty, Slack et Pub/Sub.
- Cliquez sur Créer.
API : BigQuery
REST
Utilisez la méthode batchPredictionJobs.create pour demander une prédiction par lot.
Avant d'utiliser les données de requête ci-dessous, effectuez les remplacements suivants :
- LOCATION_ID : région où le modèle est stocké et la tâche de prédiction par lot est exécutée. Exemple :
us-central1. - PROJECT_ID : ID du projet.
- BATCH_JOB_NAME : nom à afficher du job par lot.
- MODEL_ID : ID du modèle à utiliser pour effectuer des prédictions.
-
INPUT_URI : référence à la source de données BigQuery. Sous la forme :
bq://bqprojectId.bqDatasetId.bqTableId
-
OUTPUT_URI : référence à la destination BigQuery (où les prédictions seront écrites). Spécifiez l'ID du projet et, éventuellement, un un ID d'ensemble de données existant. Utilisez le formulaire suivant :
bq://bqprojectId.bqDatasetId
bq://bqprojectId
- GENERATE_EXPLANATION : La valeur par défaut est false. Définissez la valeur sur true pour activer les attributions de caractéristiques. Pour en savoir plus, consultez la page Attributions de caractéristiques pour la prévision.
Méthode HTTP et URL :
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs
Corps JSON de la requête :
{
"displayName": "BATCH_JOB_NAME",
"model": "projects/PROJECT_ID/locations/LOCATION_ID/models/MODEL_ID",
"inputConfig": {
"instancesFormat": "bigquery",
"bigquerySource": {
"inputUri": "INPUT_URI"
}
},
"outputConfig": {
"predictionsFormat": "bigquery",
"bigqueryDestination": {
"outputUri": "OUTPUT_URI"
}
},
"generate_explanation": GENERATE_EXPLANATION
}
Pour envoyer votre requête, choisissez l'une des options suivantes :
curl
Enregistrez le corps de la requête dans un fichier nommé request.json, puis exécutez la commande suivante :
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs"
PowerShell
Enregistrez le corps de la requête dans un fichier nommé request.json, puis exécutez la commande suivante :
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs" | Select-Object -Expand Content
Vous devriez recevoir une réponse JSON de ce type :
{
"name": "projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs/67890",
"displayName": "batch_job_1 202005291958",
"model": "projects/12345/locations/us-central1/models/5678",
"state": "JOB_STATE_PENDING",
"inputConfig": {
"instancesFormat": "bigquery",
"bigquerySource": {
"inputUri": "INPUT_URI"
}
},
"outputConfig": {
"predictionsFormat": "bigquery",
"bigqueryDestination": {
"outputUri": bq://12345
}
},
"dedicatedResources": {
"machineSpec": {
"machineType": "n1-standard-32",
"acceleratorCount": "0"
},
"startingReplicaCount": 2,
"maxReplicaCount": 6
},
"manualBatchTuningParameters": {
"batchSize": 4
},
"outputInfo": {
"bigqueryOutputDataset": "bq://12345.reg_model_2020_10_02_06_04
}
"state": "JOB_STATE_PENDING",
"createTime": "2020-09-30T02:58:44.341643Z",
"updateTime": "2020-09-30T02:58:44.341643Z",
}
Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java décrites dans le guide de démarrage rapide de Vertex AI à l'aide des bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API Vertex AI Java.
Pour vous authentifier auprès de Vertex AI, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Dans l'exemple suivant, remplacez INSTANCES_FORMAT et PREDICTIONS_FORMAT par "bigquery". Pour savoir comment remplacer les autres espaces réservés, consultez l'onglet "REST et ligne de commande" de cette section.Python
Pour savoir comment installer ou mettre à jour le SDK Vertex AI pour Python, consultez la section Installer le SDK Vertex AI pour Python. Pour en savoir plus, consultez la documentation de référence de l'API Python.
API : Cloud Storage
REST
Utilisez la méthode batchPredictionJobs.create pour demander une prédiction par lot.
Avant d'utiliser les données de requête ci-dessous, effectuez les remplacements suivants :
- LOCATION_ID : région où le modèle est stocké et la tâche de prédiction par lot est exécutée. Exemple :
us-central1. - PROJECT_ID : ID du projet.
- BATCH_JOB_NAME : nom à afficher du job par lot.
- MODEL_ID : ID du modèle à utiliser pour effectuer des prédictions.
-
URI : chemins (URI) vers les buckets Cloud Storage contenant les données d'entraînement.
Il peut y en avoir plusieurs. Chaque URI se présente sous la forme suivante :
gs://bucketName/pathToFileName
-
OUTPUT_URI_PREFIX : chemin d'accès à une destination Cloud Storage où les prédictions seront écrites. Vertex AI écrit des prédictions par lots dans un sous-répertoire horodaté de ce chemin. Définissez cette valeur sur une chaîne au format suivant :
gs://bucketName/pathToOutputDirectory
- GENERATE_EXPLANATION : La valeur par défaut est false. Définissez la valeur sur true pour activer les attributions de caractéristiques. Cette option n'est disponible que si votre destination de sortie est JSONL. Les attributions de caractéristiques ne sont pas compatibles avec le format CSV sur Cloud Storage. Pour en savoir plus, consultez la page Attributions de caractéristiques pour la prévision.
Méthode HTTP et URL :
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs
Corps JSON de la requête :
{
"displayName": "BATCH_JOB_NAME",
"model": "projects/PROJECT_ID/locations/LOCATION_ID/models/MODEL_ID",
"inputConfig": {
"instancesFormat": "csv",
"gcsSource": {
"uris": [
URI1,...
]
},
},
"outputConfig": {
"predictionsFormat": "csv",
"gcsDestination": {
"outputUriPrefix": "OUTPUT_URI_PREFIX"
}
},
"generate_explanation": GENERATE_EXPLANATION
}
Pour envoyer votre requête, choisissez l'une des options suivantes :
curl
Enregistrez le corps de la requête dans un fichier nommé request.json, puis exécutez la commande suivante :
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs"
PowerShell
Enregistrez le corps de la requête dans un fichier nommé request.json, puis exécutez la commande suivante :
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs" | Select-Object -Expand Content
Vous devriez recevoir une réponse JSON de ce type :
{
"name": "projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs/67890",
"displayName": "batch_job_1 202005291958",
"model": "projects/12345/locations/us-central1/models/5678",
"state": "JOB_STATE_PENDING",
"inputConfig": {
"instancesFormat": "csv",
"gcsSource": {
"uris": [
"gs://bp_bucket/reg_mode_test"
]
}
},
"outputConfig": {
"predictionsFormat": "csv",
"gcsDestination": {
"outputUriPrefix": "OUTPUT_URI_PREFIX"
}
},
"dedicatedResources": {
"machineSpec": {
"machineType": "n1-standard-32",
"acceleratorCount": "0"
},
"startingReplicaCount": 2,
"maxReplicaCount": 6
}
"outputInfo": {
"gcsOutputDataset": "OUTPUT_URI_PREFIX/prediction-batch_job_1 202005291958-2020-09-30T02:58:44.341643Z"
}
"state": "JOB_STATE_PENDING",
"createTime": "2020-09-30T02:58:44.341643Z",
"updateTime": "2020-09-30T02:58:44.341643Z",
}
Python
Pour savoir comment installer ou mettre à jour le SDK Vertex AI pour Python, consultez la section Installer le SDK Vertex AI pour Python. Pour en savoir plus, consultez la documentation de référence de l'API Python.
Récupérer des résultats de prédiction par lot
Vertex AI envoie la sortie des prédictions par lot à la destination spécifiée, qui peut être BigQuery ou Cloud Storage.
La sortie Cloud Storage pour les attributions de caractéristiques n'est actuellement pas disponible.
BigQuery
Ensemble de données de sortie
Si vous utilisez BigQuery, le résultat de la prédiction par lot est stocké dans un ensemble de données de sortie. Si vous avez fourni un ensemble de données à Vertex AI, le nom de l'ensemble de données (BQ_DATASET_NAME) est le nom que vous avez fourni précédemment. Si vous n'avez pas spécifié d'ensemble de données de sortie, Vertex AI en a créé un pour vous. Vous pouvez trouver son nom (BQ_DATASET_NAME) en procédant comme suit :
- Dans la console Google Cloud, accédez à la page Prédictions par lots de Vertex AI.
- Sélectionnez la prédiction que vous avez créée.
-
L'ensemble de données de sortie est indiqué dans Emplacement d'exportation. Le nom de la ressource est formaté de la façon suivante :
prediction_MODEL_NAME_TIMESTAMP
Tables de sortie
L'ensemble de données de sortie contient une ou plusieurs des tables de sortie suivantes :
-
Table des prédictions
Cette table contient une ligne pour chaque ligne de vos données d'entrée où une prédiction a été demandée (c'est-à-dire une ligne avec TARGET_COLUMN_NAME = null). Par exemple, si votre entrée comprend 14 entrées NULL pour la colonne cible (telles que les ventes pour les 14 jours suivants), votre requête de prédiction renvoie 14 lignes, le nombre de ventes de chaque jour. Si votre requête de prédiction dépasse l'horizon de prévision du modèle, Vertex AI ne renvoie que les prédictions jusqu'à l'horizon de prévision.
-
Table de validation des erreurs
Cette table contient une ligne pour chaque erreur non critique rencontrée pendant la phase d'agrégation qui a lieu avant la prédiction par lot. Chaque erreur non critique correspond à une ligne dans les données d'entrée pour laquelle Vertex AI n'a pas pu renvoyer de prévision.
-
Table des erreurs
Cette table contient une ligne pour chaque erreur non critique rencontrée lors de la prédiction par lot. Chaque erreur non critique correspond à une ligne dans les données d'entrée pour laquelle Vertex AI n'a pas pu renvoyer de prévision.
Table des prédictions
Le nom de la table (BQ_PREDICTIONS_TABLE_NAME) est constitué en ajoutant "predictions_" avec l'horodatage du début de la tâche de prédiction par lot : predictions_TIMESTAMP
Pour récupérer la table des prédictions, procédez comme suit :
-
Dans la console, accédez à la page BigQuery.
Accéder à BigQuery -
Exécutez la requête suivante :
SELECT * FROM BQ_DATASET_NAME.BQ_PREDICTIONS_TABLE_NAME
Vertex AI stocke les prédictions dans la colonne predicted_TARGET_COLUMN_NAME.value.
Si vous avez entraîné un modèle à l'aide du transformateur de fusion temporelle (TFT), vous trouverez le résultat d'interprétabilité TFT dans la colonne predicted_TARGET_COLUMN_NAME.tft_feature_importance.
Cette colonne est divisée en deux parties :
context_columns: caractéristiques de prévision dont les valeurs de fenêtre de contexte servent d'entrées dans l'encodeur TFT de type LSTM (Long Short-Term Memory).context_weights: pondérations de l'importance des caractéristiques associées à chacune descontext_columnspour l'instance prédite.horizon_columns: caractéristiques de prévision dont la valeur de l'horizon de prévision est utilisée comme entrées pour le décodeur TFT de type LSTM (Long Short-Term Memory).horizon_weights: pondérations de l'importance des caractéristiques associées à chacune deshorizon_columnspour l'instance prédite.attribute_columns: fonctionnalités de prévision invariantes dans le temps.attribute_weights: pondérations associées à chacun desattribute_columns.
Si votre modèle est optimisé pour la perte de quantiles et que votre ensemble de quantiles inclut la médiane, predicted_TARGET_COLUMN_NAME.value est la valeur de prédiction à la médiane. Sinon, predicted_TARGET_COLUMN_NAME.value est la valeur de prédiction au quantile le plus bas de l'ensemble. Par exemple, si votre ensemble de quantiles est [0.1, 0.5, 0.9], value correspond à la prédiction pour le quantile 0.5.
Si votre ensemble de quantiles est [0.1, 0.9], value correspond à la prédiction pour le quantile 0.1.
De plus, Vertex AI stocke les valeurs et les prédictions de quantiles dans les colonnes suivantes :
-
predicted_TARGET_COLUMN_NAME.quantile_values: valeurs des quantiles, qui sont définies lors de l'entraînement du modèle. Exemples :0.1,0.5et0.9. -
predicted_TARGET_COLUMN_NAME.quantile_predictions: valeurs de prédiction associées aux valeurs quantiles.
Si votre modèle utilise une inférence probabiliste, predicted_TARGET_COLUMN_NAME.value contient la minimisation de l'objectif d'optimisation. Par exemple, si votre objectif d'optimisation est minimize-rmse, predicted_TARGET_COLUMN_NAME.value contient la valeur moyenne. Si la valeur est minimize-mae, predicted_TARGET_COLUMN_NAME.value contient la valeur médiane.
Si votre modèle utilise une inférence probabiliste avec des quantiles, Vertex AI stocke les valeurs et les prédictions de quantiles dans les colonnes suivantes :
-
predicted_TARGET_COLUMN_NAME.quantile_values: valeurs des quantiles, qui sont définies lors de l'entraînement du modèle. Exemples :0.1,0.5et0.9. predicted_TARGET_COLUMN_NAME.quantile_predictions: valeurs de prédiction associées aux valeurs de quantiles.
Si vous avez activé les attributions de caractéristiques, vous pouvez également les trouver dans la table des prédictions. Pour accéder aux attributions d'une fonctionnalité BQ_FEATURE_NAME, exécutez la requête suivante :
SELECT explanation.attributions[OFFSET(0)].featureAttributions.BQ_FEATURE_NAME FROM BQ_DATASET_NAME.BQ_PREDICTIONS_TABLE_NAME
Pour en savoir plus, consultez la page Attributions de caractéristiques pour la prévision.
Table de validation des erreurs
Le nom de la table (BQ_ERRORS_VALIDATION_TABLE_NAME) est constitué en ajoutant "errors_validation" avec l'horodatage du début de la tâche de prédiction par lot : errors_validation_TIMESTAMP
-
Dans la console, accédez à la page BigQuery.
Accéder à BigQuery -
Exécutez la requête suivante :
SELECT * FROM BQ_DATASET_NAME.BQ_ERRORS_VALIDATION_TABLE_NAME
- errors_TARGET_COLUMN_NAME
Table des erreurs
Le nom de la table (BQ_ERRORS_TABLE_NAME) est constitué en ajoutant "errors_" avec l'horodatage du début du job de prédiction par lot : errors_TIMESTAMP
-
Dans la console, accédez à la page BigQuery.
Accéder à BigQuery -
Exécutez la requête suivante :
SELECT * FROM BQ_DATASET_NAME.BQ_ERRORS_TABLE_NAME
- errors_TARGET_COLUMN_NAME.code
- errors_TARGET_COLUMN_NAME.message
Cloud Storage
Si vous avez spécifié Cloud Storage comme destination de sortie, les résultats de votre requête de prédiction par lot sont affichés sous forme d'objets CSV dans un nouveau dossier du bucket spécifié. Le nom du dossier est celui de votre modèle, précédé de "prédiction-" et suivi de l'horodatage du début de la tâche de prédiction par lot. Vous trouverez le nom du dossier Cloud Storage dans l'onglet Prédictions par lot de votre modèle.
Le dossier Cloud Storage contient deux types d'objets :-
Objets de prédiction
Les objets de prédiction sont nommés "predictions_1.csv", "predictions_2.csv", etc. Ils contiennent une ligne d'en-tête avec les noms de colonne et une ligne pour chaque prédiction affichée. Le nombre de valeurs de prédiction dépend de vos données d'entrée et de l'horizon de prévision. Par exemple, si votre entrée comprend 14 entrées NULL pour la colonne cible (telles que les ventes pour les 14 jours suivants), votre requête de prédiction renvoie 14 lignes, le nombre de ventes de chaque jour. Si votre requête de prédiction dépasse l'horizon de prévision du modèle, Vertex AI ne renvoie que les prédictions jusqu'à l'horizon de prévision.
Les valeurs prédites sont renvoyées dans une colonne nommée "predicted_TARGET_COLUMN_NAME". Pour les prévisions de quantiles, la colonne de sortie contient les prédictions et les valeurs de quantiles au format JSON.
-
Objets d'erreur
Les objets d'erreur sont nommés "errors_1.csv", "errors_2.csv", etc. Ils contiennent une ligne d'en-tête et une ligne pour chaque ligne de vos données d'entrée pour laquelle Vertex AI n'a pas pu renvoyer de prévision (par exemple, une caractéristique ne pouvant être vide contient une valeur nulle).
Remarque : Si les résultats comportent une grande quantité de données, ils sont divisés en plusieurs objets.
Exemples de requêtes d'attribution de caractéristiques dans BigQuery
Exemple 1 : Déterminer les attributions pour une seule prédiction
Posez-vous la question suivante :
Dans quelle proportion une publicité pour un produit a augmenté les ventes prévues le 24 novembre dans un magasin donné ?
La requête correspondante est la suivante :
SELECT
* EXCEPT(explanation, predicted_sales),
ROUND(predicted_sales.value, 2) AS predicted_sales,
ROUND(
explanation.attributions[OFFSET(0)].featureAttributions.advertisement,
2
) AS attribution_advertisement
FROM
`project.dataset.predictions`
WHERE
product = 'product_0'
AND store = 'store_0'
AND date = '2019-11-24'
Exemple 2 : Déterminer l'importance des caractéristiques globales
Posez-vous la question suivante :
Dans quelle mesure chaque fonctionnalité a-t-elle contribué à la prédiction des ventes ?
Vous pouvez calculer manuellement l'importance globale des fonctionnalités en agrégeant les attributions d'importance des fonctionnalités locales. La requête correspondante est la suivante :
WITH
/*
* Aggregate from (id, date) level attributions to global feature importance.
*/
attributions_aggregated AS (
SELECT
SUM(ABS(attributions.featureAttributions.date)) AS date,
SUM(ABS(attributions.featureAttributions.advertisement)) AS advertisement,
SUM(ABS(attributions.featureAttributions.holiday)) AS holiday,
SUM(ABS(attributions.featureAttributions.sales)) AS sales,
SUM(ABS(attributions.featureAttributions.store)) AS store,
SUM(ABS(attributions.featureAttributions.product)) AS product,
FROM
project.dataset.predictions,
UNNEST(explanation.attributions) AS attributions
),
/*
* Calculate the normalization constant for global feature importance.
*/
attributions_aggregated_with_total AS (
SELECT
*,
date + advertisement + holiday + sales + store + product AS total
FROM
attributions_aggregated
)
/*
* Calculate the normalized global feature importance.
*/
SELECT
ROUND(date / total, 2) AS date,
ROUND(advertisement / total, 2) AS advertisement,
ROUND(holiday / total, 2) AS holiday,
ROUND(sales / total, 2) AS sales,
ROUND(store / total, 2) AS store,
ROUND(product / total, 2) AS product,
FROM
attributions_aggregated_with_total
Exemple de résultat d'une prédiction par lot dans BigQuery
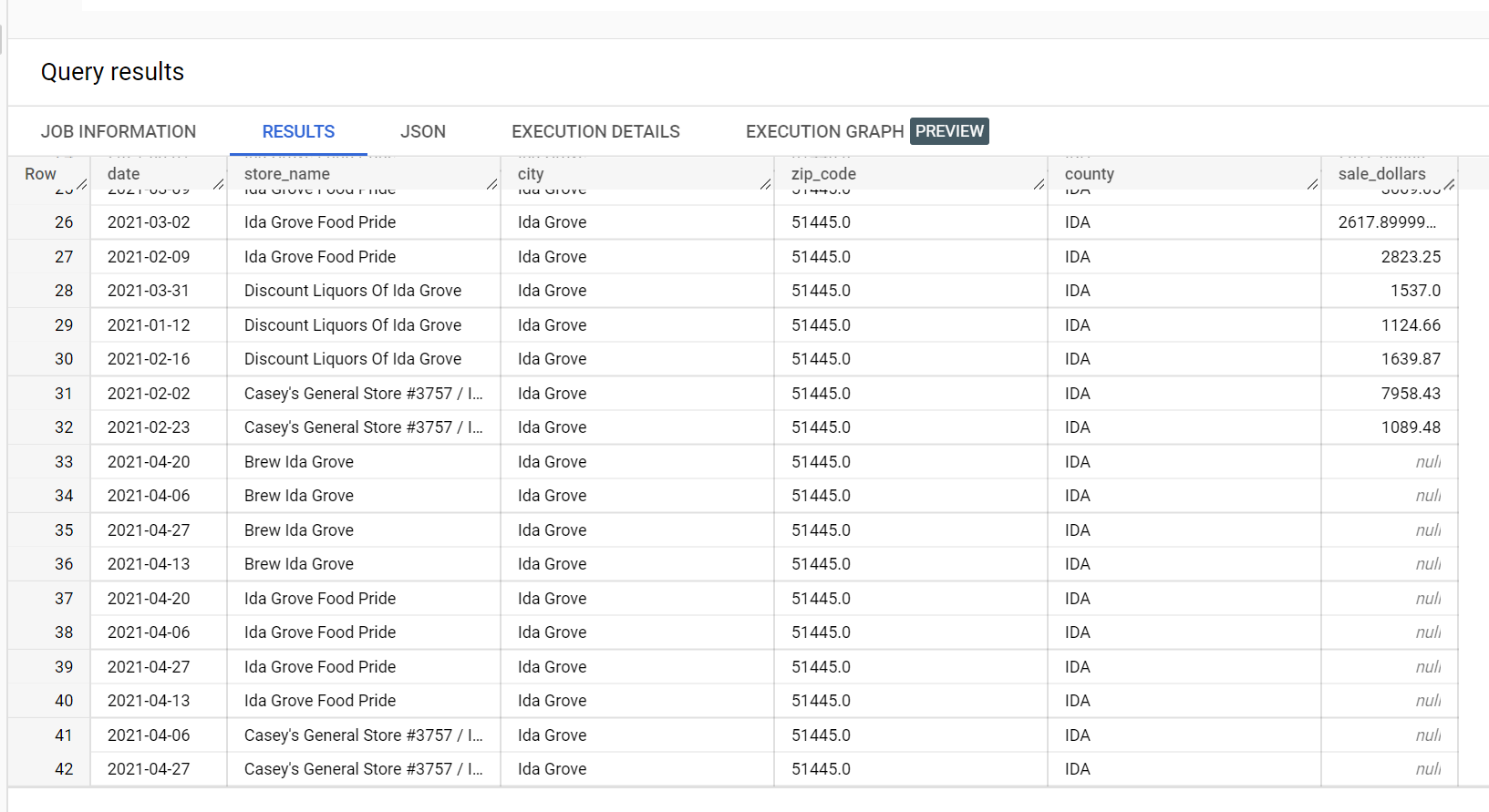
Dans l'exemple d'ensemble de données des ventes de liqueurs, il existe quatre magasins dans la ville de "Ida Grove" : "Ida Grove Food Pride", "Discount Liquors of Ida Grove", "Casey's General Store #3757", et "Brew Ida Grove". store_name est le series identifier, et trois des quatre magasins demandent des prédictions pour la colonne cible sale_dollars. Une erreur de validation est générée, car aucune prévision n'a été demandée pour "Discount Liquors of Ida Grove".
Voici un extrait de l'ensemble de données d'entrée utilisé pour la prédiction :
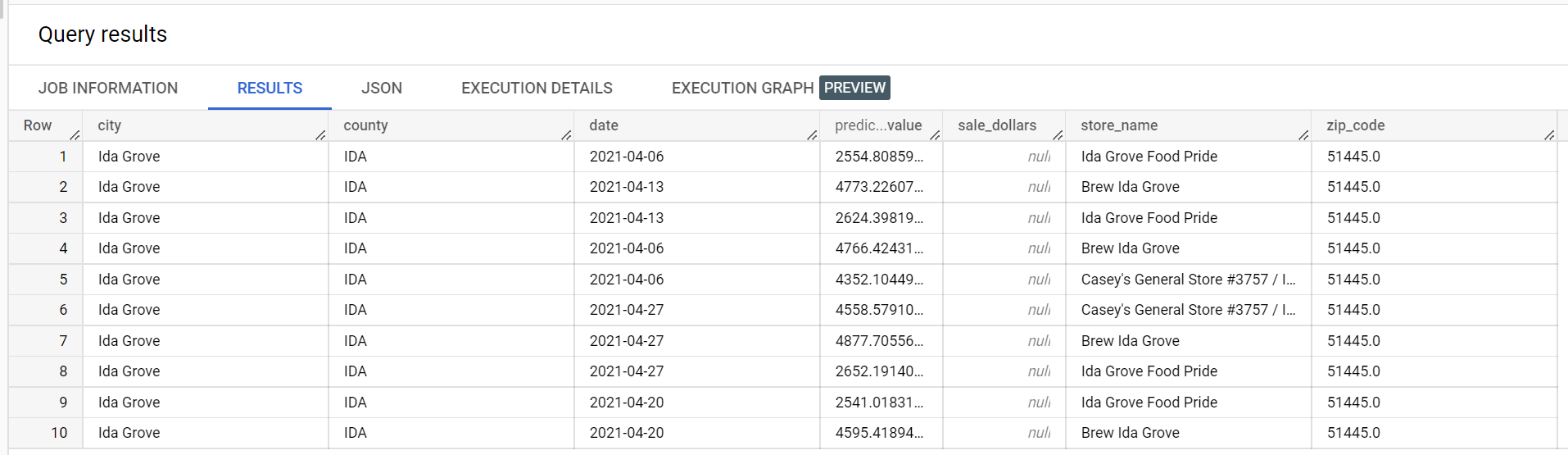
Voici un extrait des résultats de la prédiction :
Voici un extrait des erreurs de validation :

Exemple de résultat d'une prédiction par lot pour un modèle optimisé pour la perte de quantiles
L'exemple suivant est une sortie de prédiction par lot pour un modèle optimisé pour la perte de quantiles. Dans ce scénario, le modèle de prévision prédit les ventes des 14 prochains jours pour chaque magasin.
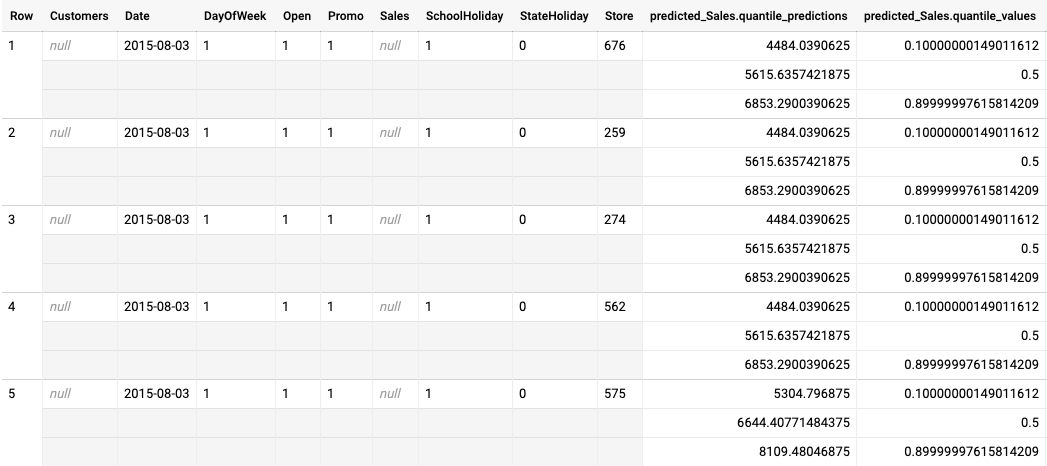
Les valeurs de quantile sont indiquées dans la colonne predicted_Sales.quantile_values. Dans cet exemple, le modèle a prédit des valeurs pour les quantiles 0.1, 0.5 et 0.9.
Les valeurs de prédiction sont indiquées dans la colonne predicted_Sales.quantile_predictions.
Il s'agit d'un tableau de valeurs de vente, qui correspondent aux valeurs de quantile présentes dans la colonne predicted_Sales.quantile_values. Sur la première ligne, nous constatons que la probabilité que la valeur des ventes soit inférieure à 4484.04 est de 10 %. La probabilité que la valeur des ventes soit inférieure à 5615.64 est de 50 %. La probabilité que la valeur des ventes soit inférieure à 6853.29 est de 90 %. La prédiction pour la première ligne, représentée sous la forme d'une valeur unique, est 5615.64.
Étapes suivantes
- Découvrez les tarifs des prédictions par lots.