本页面介绍如何使用预测表格工作流根据表格数据训练预测模型。
如需了解此工作流使用的服务账号,请参阅表格工作流的服务账号。
如果您在运行预测表格工作流时收到配额错误,则可能需要申请更高的配额。如需了解详情,请参阅管理表格工作流的配额。
预测表格工作流不支持模型导出。
Workflow API
此工作流使用以下 API:
- Vertex AI
- Dataflow
- Compute Engine
- Cloud Storage
获取上一个超参数调节结果的 URI
如果您先前已完成预测表格工作流运行,则可以使用先前运行的超参数调节结果来节省训练时间和资源。您可以使用 Google Cloud 控制台查找先前的超参数调节结果,也可以使用 API 以编程方式加载结果。
Google Cloud 控制台
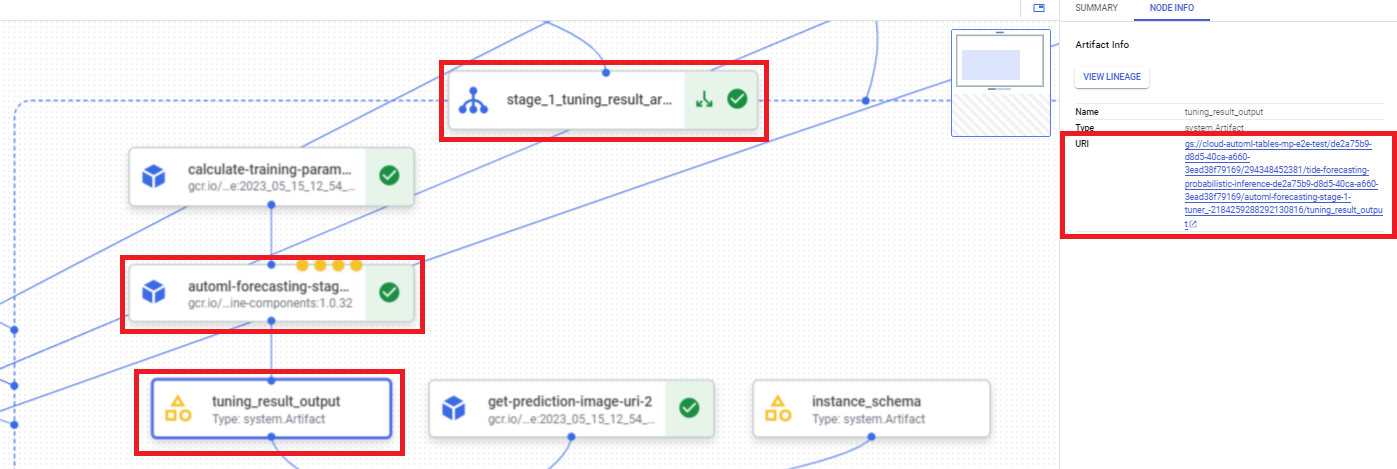
如需使用 Google Cloud 控制台查找超参数调节结果 URI,请执行以下步骤:
在 Google Cloud 控制台的 Vertex AI 部分中,前往流水线页面。
选择运行标签页。
选择要使用的流水线运行。
选择展开工件。
点击组件 exit-handler-1。
点击组件 stage_1_tuning_result_artifact_uri_empty。
找到组件 automl-forecasting-stage-1-tuner。
点击关联的工件 tuning_result_output。
选择节点信息标签页。
复制 URI 以在训练模型步骤中使用。
API:Python
以下示例代码演示如何使用 API 加载超参数调节结果。变量 job 是指之前的模型训练流水线运行。
def get_task_detail(
task_details: List[Dict[str, Any]], task_name: str
) -> List[Dict[str, Any]]:
for task_detail in task_details:
if task_detail.task_name == task_name:
return task_detail
pipeline_task_details = job.gca_resource.job_detail.task_details
stage_1_tuner_task = get_task_detail(
pipeline_task_details, "automl-forecasting-stage-1-tuner"
)
stage_1_tuning_result_artifact_uri = (
stage_1_tuner_task.outputs["tuning_result_output"].artifacts[0].uri
)
训练模型
以下示例代码演示了如何运行模型训练流水线:
job = aiplatform.PipelineJob(
...
template_path=template_path,
parameter_values=parameter_values,
...
)
job.run(service_account=SERVICE_ACCOUNT)
您可以使用 job.run() 中的可选 service_account 参数,将 Vertex AI Pipelines 服务账号设置为您选择的账号。
Vertex AI 支持以下模型训练方法:
Time series Dense Encoder (TiDE)。如需使用此模型训练方法,请使用以下函数定义流水线和参数值:
template_path, parameter_values = automl_forecasting_utils.get_time_series_dense_encoder_forecasting_pipeline_and_parameters(...)Temporal Fusion Transformer (TFT)。如需使用此模型训练方法,请使用以下函数定义流水线和参数值:
template_path, parameter_values = automl_forecasting_utils.get_temporal_fusion_transformer_forecasting_pipeline_and_parameters(...)AutoML (L2L)。如需使用此模型训练方法,请使用以下函数定义流水线和参数值:
template_path, parameter_values = automl_forecasting_utils.get_learn_to_learn_forecasting_pipeline_and_parameters(...)Seq2Seq+。如需使用此模型训练方法,请使用以下函数定义流水线和参数值:
template_path, parameter_values = automl_forecasting_utils.get_sequence_to_sequence_forecasting_pipeline_and_parameters(...)
如需了解详情,请参阅模型训练方法。
训练数据可以是 Cloud Storage 中的 CSV 文件,也可以是 BigQuery 中的表。
以下是模型训练参数的子集:
| 参数名称 | 类型 | 定义 |
|---|---|---|
optimization_objective |
字符串 | 默认情况下,Vertex AI 会最大限度降低均方根误差 (RMSE)。如果您要为预测模型使用其他优化目标,请选择预测模型的优化目标中的一个选项。如果您选择最大限度地减少分位数损失,则还必须为 quantiles 指定值。 |
enable_probabilistic_inference |
布尔值 | 如果设置为 true,则 Vertex AI 会对预测的概率分布建模。概率推理可以通过处理噪声数据并量化不确定性来提高模型质量。如果指定了 quantiles,则 Vertex AI 还会返回分布的分位数。概率推理仅与 Time series Dense Encoder (TiDE) 和 AutoML (L2L) 训练方法兼容。概率推理与 minimize-quantile-loss 优化目标不兼容。 |
quantiles |
List[float] | 用于 minimize-quantile-loss 优化目标和概率推理的分位数。提供一个最多包含五个介于 0 到 1(不含边界值)之间的唯一数字的列表。 |
time_column |
字符串 | 时间列。如需了解详情,请参阅数据结构要求。 |
time_series_identifier_columns |
List[str] | 时序标识符列。如需了解详情,请参阅数据结构要求。 |
weight_column |
字符串 | (可选)权重列。如需了解详情,请参阅向训练数据添加权重。 |
time_series_attribute_columns |
List[str] | (可选)是时序属性的列的名称。如需了解详情,请参阅特征类型和预测时的可用性。 |
available_at_forecast_columns |
List[str] | (可选)在预测时其值已知的协变量列的名称。如需了解详情,请参阅特征类型和预测时的可用性。 |
unavailable_at_forecast_columns |
List[str] | (可选)预测时值未知的协变量列的名称。如需了解详情,请参阅特征类型和预测时的可用性。 |
forecast_horizon |
整数 | (可选)预测范围确定模型预测每行推理数据的目标值的未来时间。如需了解详情,请参阅预测范围、上下文窗口和预测窗口。 |
context_window |
整数 | (可选)上下文窗口设置模型在训练期间的回溯时间(用于预测)。换句话说,对于每个数据点,上下文窗口会确定模型查找回溯模式的时间。 如需了解详情,请参阅预测范围、上下文窗口和预测窗口。 |
window_max_count |
整数 | (可选)Vertex AI 使用滚动窗口策略根据输入数据生成预测窗口。默认策略是计数。最大窗口数的默认值为 100,000,000。设置此参数可为最大窗口数提供自定义值。如需了解详情,请参阅滚动窗口策略。 |
window_stride_length |
整数 | (可选)Vertex AI 使用滚动窗口策略根据输入数据生成预测窗口。如需选择步长策略,请将此参数设置为步长的值。如需了解详情,请参阅滚动窗口策略。 |
window_predefined_column |
字符串 | (可选)Vertex AI 使用滚动窗口策略根据输入数据生成预测窗口。若要选择列策略,请将此参数设置为值为 True 或 False 的列的名称。如需了解详情,请参阅滚动窗口策略。 |
holiday_regions |
List[str] | (可选)您可以选择一个或多个地理区域来启用节假日效应建模。在训练期间,Vertex AI 会根据 time_column 中的日期和指定的地理区域在模型中创建节假日分类特征。默认情况下,节假日效应建模处于停用状态。如需了解详情,请参阅节假日区域。 |
predefined_split_key |
字符串 | (可选)默认情况下,Vertex AI 使用按时间顺序拆分算法将预测数据拆分为三个数据分块。如果要控制将哪些训练数据行用于哪个分块,请提供包含数据拆分值(TRAIN、VALIDATION、TEST)的列的名称。如需了解详情,请参阅用于预测的数据分块。 |
training_fraction |
浮点数 | (可选)默认情况下,Vertex AI 使用按时间顺序拆分算法将预测数据拆分为三个数据分块。80% 的数据分配给训练集,10% 分配给验证分块,10% 分配给测试分块。如果想自定义分配给训练集的数据比例,请设置此参数。如需了解详情,请参阅用于预测的数据分块。 |
validation_fraction |
浮点数 | (可选)默认情况下,Vertex AI 使用按时间顺序拆分算法将预测数据拆分为三个数据分块。80% 的数据分配给训练集,10% 分配给验证分块,10% 分配给测试分块。如果想自定义分配给验证集的数据比例,请设置此参数。如需了解详情,请参阅用于预测的数据分块。 |
test_fraction |
浮点数 | (可选)默认情况下,Vertex AI 使用按时间顺序拆分算法将预测数据拆分为三个数据分块。80% 的数据分配给训练集,10% 分配给验证分块,10% 分配给测试分块。如果想自定义分配给测试集的数据比例,请设置此参数。如需了解详情,请参阅用于预测的数据分块。 |
data_source_csv_filenames |
字符串 | 存储在 Cloud Storage 中的 CSV 的 URI。 |
data_source_bigquery_table_path |
字符串 | BigQuery 表的 URI。 |
dataflow_service_account |
字符串 | (可选)用于运行 Dataflow 作业的自定义服务账号。您可以将 Dataflow 作业配置为使用专用 IP 和特定 VPC 子网。此参数充当默认 Dataflow 工作器服务账号的替换值。 |
run_evaluation |
布尔值 | 如果设置为 True,Vertex AI 会评估测试分块上的集成学习模型。 |
evaluated_examples_bigquery_path |
字符串 | 模型评估期间使用的 BigQuery 数据集的路径。该数据集用作预测样本的目标位置。如果 run_evaluation 设置为 True,则必须设置参数值且必须采用以下格式:bq://[PROJECT].[DATASET]。 |
转换
您可以提供自动或类型解析到特征列的字典映射。支持的类型包括自动、数字、分类、文本和时间戳。
| 参数名称 | 类型 | 定义 |
|---|---|---|
transformations |
Dict[str, List[str]] | 自动或类型解析的字典映射 |
以下代码提供了一个用于填充 transformations 参数的辅助函数。它还演示了如何使用此函数将自动转换应用于由 features 变量定义的一组列。
def generate_transformation(
auto_column_names: Optional[List[str]]=None,
numeric_column_names: Optional[List[str]]=None,
categorical_column_names: Optional[List[str]]=None,
text_column_names: Optional[List[str]]=None,
timestamp_column_names: Optional[List[str]]=None,
) -> List[Dict[str, Any]]:
if auto_column_names is None:
auto_column_names = []
if numeric_column_names is None:
numeric_column_names = []
if categorical_column_names is None:
categorical_column_names = []
if text_column_names is None:
text_column_names = []
if timestamp_column_names is None:
timestamp_column_names = []
return {
"auto": auto_column_names,
"numeric": numeric_column_names,
"categorical": categorical_column_names,
"text": text_column_names,
"timestamp": timestamp_column_names,
}
transformations = generate_transformation(auto_column_names=features)
如需详细了解转换,请参阅数据类型和转换。
工作流自定义选项
您可以通过定义在流水线定义期间传入的参数值来自定义预测表格工作流。您可以通过以下方式自定义工作流:
- 配置硬件
- 跳过架构搜索
配置硬件
利用以下模型训练参数,可以配置机器类型和用于训练的机器数量。如果您有大型数据集并希望相应地优化机器硬件,则此选项是一个不错的选择。
| 参数名称 | 类型 | 定义 |
|---|---|---|
stage_1_tuner_worker_pool_specs_override |
Dict[String, Any] | (可选)机器类型的自定义配置和用于训练的机器数量。此参数配置流水线的 automl-forecasting-stage-1-tuner 组件。 |
以下代码演示了如何为 TensorFlow 主节点设置 n1-standard-8 机器类型,以及为 TensorFlow 评估器节点设置 n1-standard-4 机器类型:
worker_pool_specs_override = [
{"machine_spec": {"machine_type": "n1-standard-8"}}, # override for TF chief node
{}, # override for TF worker node, since it's not used, leave it empty
{}, # override for TF ps node, since it's not used, leave it empty
{
"machine_spec": {
"machine_type": "n1-standard-4" # override for TF evaluator node
}
}
]
跳过架构搜索
以下模型训练参数可让您在不进行架构搜索的情况下运行流水线,并提供上一次流水线运行中的一组超参数。
| 参数名称 | 类型 | 定义 |
|---|---|---|
stage_1_tuning_result_artifact_uri |
字符串 | (可选)先前流水线运行中的超参数调节结果的 URI。 |