Vertex AI offre due opzioni per proiettare i valori futuri utilizzando il modello di previsione addestrato: inferenze online e inferenze batch.
Un'inferenza online è una richiesta sincrona. Utilizza le inferenze online quando effettui richieste in risposta all'input dell'applicazione o in altre situazioni in cui è necessaria un'inferenza tempestiva.
Una richiesta di inferenza batch è una richiesta asincrona. Utilizza l'inferenza batch quando non hai bisogno di una risposta immediata e vuoi elaborare i dati accumulati utilizzando un'unica richiesta.
Questa pagina mostra come proiettare i valori futuri utilizzando le inferenze batch. Per scoprire come proiettare i valori utilizzando le inferenze online, consulta Ottenere inferenze online per un modello di previsione.
Puoi richiedere inferenze batch direttamente dalla risorsa del modello.
Puoi richiedere un'inferenza con spiegazioni (chiamate anche attribuzioni delle caratteristiche) per vedere come il modello è arrivato a un'inferenza. I valori di importanza delle caratteristiche locali indicano in che misura ciascuna caratteristica ha contribuito al risultato dell'inferenza. Per una panoramica concettuale, vedi Attribuzioni delle caratteristiche per la previsione.
Per informazioni sui prezzi delle inferenze batch, consulta la pagina Prezzi di Tabular Workflows.
Prima di iniziare
Prima di effettuare una richiesta di inferenza batch, devi prima addestrare un modello.
Dati di input
I dati di input per le richieste di inferenza batch sono i dati che il modello utilizza per creare previsioni. Puoi fornire i dati di input in uno dei due formati seguenti:
- Oggetti CSV in Cloud Storage
- Tabelle BigQuery
Ti consigliamo di utilizzare lo stesso formato per i dati di input utilizzato per l'addestramento del modello. Ad esempio, se hai addestrato il modello utilizzando i dati in BigQuery, è consigliabile utilizzare una tabella BigQuery come input per l'inferenza batch. Poiché Vertex AI considera tutti i campi di input CSV come stringhe, la combinazione di formati di dati di addestramento e di input può causare errori.
L'origine dati deve contenere dati tabellari che includano tutte le colonne, in qualsiasi ordine, utilizzate per addestrare il modello. Puoi includere colonne che non erano nei dati di addestramento o che erano nei dati di addestramento ma escluse dall'utilizzo per l'addestramento. Queste colonne aggiuntive sono incluse nell'output, ma non influenzano i risultati delle previsioni.
Requisiti dei dati di input
L'input per i modelli di previsione deve rispettare i seguenti requisiti:
- Tutti i valori nella colonna dell'ora devono essere presenti e validi.
- Tutte le colonne utilizzate nella richiesta di inferenza devono essere presenti nei dati di input. Quando le colonne sono vuote o non esistono, Vertex AI esegue il padding dei dati automaticamente.
- La frequenza dei dati di input e dei dati di addestramento deve corrispondere. Se mancano righe nella serie temporale, devi inserirle manualmente in base alle conoscenze del dominio appropriate.
- Le serie temporali con timestamp duplicati vengono rimosse dalle inferenze. Per includerli, rimuovi i timestamp duplicati.
- Fornisci i dati storici per ogni serie temporale da prevedere. Per ottenere previsioni più accurate, la quantità di dati deve essere uguale alla finestra contestuale, che viene impostata durante l'addestramento del modello. Ad esempio, se la finestra contestuale è di 14 giorni, fornisci almeno 14 giorni di dati storici. Se fornisci meno dati, Vertex AI riempie i dati con valori vuoti.
- La previsione inizia nella prima riga di una serie temporale (ordinata in base al tempo)
con un valore nullo nella colonna di destinazione. Il valore nullo deve essere continuo
all'interno della serie temporale. Ad esempio, se la colonna di destinazione è ordinata per
ora, non puoi avere valori come
1,2,null,3,4,null,nullper una singola serie temporale. Per i file CSV, Vertex AI considera una stringa vuota come null, mentre per BigQuery i valori null sono supportati in modo nativo.
Tabella BigQuery
Se scegli una tabella BigQuery come input, devi assicurarti che:
- Le tabelle BigQuery che fungono da origine dati non devono essere più grandi di 100 GB.
- Se la tabella si trova in un progetto diverso, devi concedere il ruolo
BigQuery Data Editorall'account di servizio Vertex AI in quel progetto.
File CSV
Se scegli un oggetto CSV in Cloud Storage come input, devi assicurarti che:
- L'origine dati deve iniziare con una riga di intestazione contenente i nomi delle colonne.
- Ogni oggetto dell'origine dati non deve essere più grande di 10 GB. Puoi includere più file, fino a un massimo di 100 GB.
- Se il bucket Cloud Storage si trova in un progetto diverso, devi concedere il ruolo
Storage Object Creatorall'account di servizio Vertex AI in quel progetto. - Devi racchiudere tutte le stringhe tra virgolette doppie (").
Formato di output
Il formato di output della richiesta di inferenza batch non deve essere lo stesso del formato di input. Ad esempio, se utilizzi una tabella BigQuery come input, puoi generare l'output dei risultati della previsione in un oggetto CSV in Cloud Storage.
Invia una richiesta di inferenza batch al modello
Per effettuare richieste di inferenza batch, puoi utilizzare la console Google Cloud o l'API Vertex AI. L'origine dati di input può essere costituita da oggetti CSV archiviati in un bucket Cloud Storage o da tabelle BigQuery. A seconda della quantità di dati che invii come input, un'attività di inferenza batch può richiedere un po' di tempo per essere completata.
Console Google Cloud
Utilizza la console Google Cloud per richiedere un'inferenza batch.
- Nella console Google Cloud , nella sezione Vertex AI, vai alla pagina Inferenze batch.
- Fai clic su Crea per aprire la finestra Nuova inferenza batch.
- Per Definisci l'inferenza batch, completa i seguenti passaggi:
- Inserisci un nome per l'inferenza batch.
- In Nome modello, seleziona il nome del modello da utilizzare per questa inferenza batch.
- In Versione, seleziona la versione del modello.
- Per Seleziona origine, seleziona se i dati di input dell'origine sono un file CSV
su Cloud Storage o una tabella in BigQuery.
- Per i file CSV, specifica la posizione Cloud Storage in cui si trova il file di input CSV.
- Per le tabelle BigQuery, specifica l'ID progetto in cui si trova la tabella, l'ID set di dati BigQuery e l'ID tabella o visualizzazione BigQuery.
- Per Output dell'inferenza batch, seleziona CSV o BigQuery.
- Per CSV, specifica il bucket Cloud Storage in cui Vertex AI memorizza l'output.
- Per BigQuery, puoi specificare un ID progetto o un set di dati
esistente:
- Per specificare l'ID progetto, inseriscilo nel campo ID progetto Google Cloud. Vertex AI crea un nuovo set di dati di output.
- Per specificare un set di dati esistente, inserisci il relativo percorso BigQuery
nel campo ID progetto Google Cloud, ad esempio
bq://projectid.datasetid.
- (Facoltativo) Se la destinazione di output è BigQuery o JSONL su Cloud Storage, puoi attivare le attribuzioni delle funzionalità oltre alle inferenze. Per farlo, seleziona Abilita attribuzioni delle caratteristiche per questo modello. Le attribuzioni delle funzionalità non sono supportate per i file CSV su Cloud Storage. Scopri di più.
- (Facoltativo) L'analisi Model Monitoring
per le inferenze batch è disponibile in Anteprima. Consulta i
Prerequisiti
per aggiungere la configurazione del rilevamento dello skew al job di inferenza batch.
- Fai clic per attivare l'opzione Abilita il monitoraggio dei modelli per questa inferenza batch.
- Seleziona un'origine dati di addestramento. Inserisci il percorso o la posizione dei dati per l'origine dati di addestramento selezionata.
- (Facoltativo) Nella sezione Soglie di avviso, specifica le soglie in corrispondenza delle quali attivare gli avvisi.
- Per Email di notifica, inserisci uno o più indirizzi email separati da virgole per ricevere avvisi quando un modello supera una soglia di avviso.
- (Facoltativo) Per Canali di notifica, aggiungi canali Cloud Monitoring per ricevere avvisi quando un modello supera una soglia di avviso. Puoi selezionare i canali Cloud Monitoring esistenti o crearne uno nuovo facendo clic su Gestisci canali di notifica. La console supporta i canali di notifica PagerDuty, Slack e Pub/Sub.
- Fai clic su Crea.
API : BigQuery
REST
Utilizzi il metodo batchPredictionJobs.create per richiedere un'inferenza batch.
Prima di utilizzare i dati della richiesta, apporta le seguenti sostituzioni:
- LOCATION_ID: la regione in cui viene archiviato il modello ed eseguito il job di inferenza batch. Ad esempio,
us-central1. - PROJECT_ID: il tuo ID progetto
- BATCH_JOB_NAME: Nome visualizzato per il job batch
- MODEL_ID: L'ID del modello da utilizzare per fare inferenze
-
INPUT_URI: riferimento all'origine dati BigQuery. Nel modulo:
bq://bqprojectId.bqDatasetId.bqTableId
-
OUTPUT_URI: riferimento alla destinazione BigQuery (dove vengono scritte le
inferenze). Specifica l'ID progetto e, facoltativamente,
un ID set di dati esistente. Utilizza il seguente modulo:
bq://bqprojectId.bqDatasetId
bq://bqprojectId
- GENERATE_EXPLANATION: il valore predefinito è false. Imposta su true per attivare le attribuzioni delle funzionalità. Per saperne di più, consulta Attribuzioni delle funzionalità per le previsioni.
Metodo HTTP e URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs
Corpo JSON della richiesta:
{
"displayName": "BATCH_JOB_NAME",
"model": "projects/PROJECT_ID/locations/LOCATION_ID/models/MODEL_ID",
"inputConfig": {
"instancesFormat": "bigquery",
"bigquerySource": {
"inputUri": "INPUT_URI"
}
},
"outputConfig": {
"predictionsFormat": "bigquery",
"bigqueryDestination": {
"outputUri": "OUTPUT_URI"
}
},
"generate_explanation": GENERATE_EXPLANATION
}
Per inviare la richiesta, scegli una di queste opzioni:
curl
Salva il corpo della richiesta in un file denominato request.json,
ed esegui questo comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs"
PowerShell
Salva il corpo della richiesta in un file denominato request.json,
quindi esegui il comando seguente:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs" | Select-Object -Expand Content
Dovresti ricevere una risposta JSON simile alla seguente:
{
"name": "projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs/67890",
"displayName": "batch_job_1 202005291958",
"model": "projects/12345/locations/us-central1/models/5678",
"state": "JOB_STATE_PENDING",
"inputConfig": {
"instancesFormat": "bigquery",
"bigquerySource": {
"inputUri": "INPUT_URI"
}
},
"outputConfig": {
"predictionsFormat": "bigquery",
"bigqueryDestination": {
"outputUri": bq://12345
}
},
"dedicatedResources": {
"machineSpec": {
"machineType": "n1-standard-32",
"acceleratorCount": "0"
},
"startingReplicaCount": 2,
"maxReplicaCount": 6
},
"manualBatchTuningParameters": {
"batchSize": 4
},
"outputInfo": {
"bigqueryOutputDataset": "bq://12345.reg_model_2020_10_02_06_04
}
"state": "JOB_STATE_PENDING",
"createTime": "2020-09-30T02:58:44.341643Z",
"updateTime": "2020-09-30T02:58:44.341643Z",
}
Java
Prima di provare questo esempio, segui le istruzioni di configurazione di Java nella guida rapida di Vertex AI per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API Vertex AI Java.
Per autenticarti in Vertex AI, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Nell'esempio seguente, sostituisci INSTANCES_FORMAT e PREDICTIONS_FORMAT con `bigquery`. Per scoprire come sostituire gli altri segnaposto, consulta la scheda `REST & CMD LINE` di questa sezione.Python
Per scoprire come installare o aggiornare l'SDK Vertex AI Python, consulta Installare l'SDK Vertex AI Python. Per saperne di più, consulta la documentazione di riferimento dell'API Python.
API : Cloud Storage
REST
Utilizzi il metodo batchPredictionJobs.create per richiedere un'inferenza batch.
Prima di utilizzare i dati della richiesta, apporta le seguenti sostituzioni:
- LOCATION_ID: la regione in cui viene archiviato il modello ed eseguito il job di inferenza batch. Ad esempio,
us-central1. - PROJECT_ID:
- BATCH_JOB_NAME: Nome visualizzato per il job batch
- MODEL_ID: L'ID del modello da utilizzare per fare inferenze
-
URI: percorsi (URI) dei bucket Cloud Storage contenenti i dati di addestramento.
Può essercene più di uno. Ogni URI ha il seguente formato:
gs://bucketName/pathToFileName
-
OUTPUT_URI_PREFIX: percorso di una destinazione Cloud Storage in cui verranno scritte le inferenze. Vertex AI scrive le inferenze batch in una sottodirectory con timestamp di questo percorso. Imposta questo valore su una stringa con il seguente formato:
gs://bucketName/pathToOutputDirectory
- GENERATE_EXPLANATION: il valore predefinito è false. Imposta su true per attivare le attribuzioni delle funzionalità. Questa opzione è disponibile solo se la destinazione di output è JSONL. Gli attributi delle funzionalità non sono supportati per i file CSV su Cloud Storage. Per saperne di più, consulta Attribuzioni delle funzionalità per le previsioni.
Metodo HTTP e URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs
Corpo JSON della richiesta:
{
"displayName": "BATCH_JOB_NAME",
"model": "projects/PROJECT_ID/locations/LOCATION_ID/models/MODEL_ID",
"inputConfig": {
"instancesFormat": "csv",
"gcsSource": {
"uris": [
URI1,...
]
},
},
"outputConfig": {
"predictionsFormat": "csv",
"gcsDestination": {
"outputUriPrefix": "OUTPUT_URI_PREFIX"
}
},
"generate_explanation": GENERATE_EXPLANATION
}
Per inviare la richiesta, scegli una di queste opzioni:
curl
Salva il corpo della richiesta in un file denominato request.json,
ed esegui questo comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs"
PowerShell
Salva il corpo della richiesta in un file denominato request.json,
quindi esegui il comando seguente:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs" | Select-Object -Expand Content
Dovresti ricevere una risposta JSON simile alla seguente:
{
"name": "projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs/67890",
"displayName": "batch_job_1 202005291958",
"model": "projects/12345/locations/us-central1/models/5678",
"state": "JOB_STATE_PENDING",
"inputConfig": {
"instancesFormat": "csv",
"gcsSource": {
"uris": [
"gs://bp_bucket/reg_mode_test"
]
}
},
"outputConfig": {
"predictionsFormat": "csv",
"gcsDestination": {
"outputUriPrefix": "OUTPUT_URI_PREFIX"
}
},
"dedicatedResources": {
"machineSpec": {
"machineType": "n1-standard-32",
"acceleratorCount": "0"
},
"startingReplicaCount": 2,
"maxReplicaCount": 6
}
"outputInfo": {
"gcsOutputDataset": "OUTPUT_URI_PREFIX/prediction-batch_job_1 202005291958-2020-09-30T02:58:44.341643Z"
}
"state": "JOB_STATE_PENDING",
"createTime": "2020-09-30T02:58:44.341643Z",
"updateTime": "2020-09-30T02:58:44.341643Z",
}
Python
Per scoprire come installare o aggiornare l'SDK Vertex AI Python, consulta Installare l'SDK Vertex AI Python. Per saperne di più, consulta la documentazione di riferimento dell'API Python.
Recuperare i risultati dell'inferenza batch
Vertex AI invia l'output delle inferenze batch alla destinazione specificata, che può essere BigQuery o Cloud Storage.
L'output Cloud Storage per le attribuzioni delle funzionalità non è supportato.
BigQuery
Set di dati di output
Se utilizzi BigQuery, l'output dell'inferenza batch viene archiviato in un set di dati di output. Se hai fornito un set di dati a Vertex AI, il nome del set di dati (BQ_DATASET_NAME) è il nome che hai fornito in precedenza. Se non hai fornito un set di dati di output, Vertex AI ne ha creato uno per te. Puoi trovare il suo nome (BQ_DATASET_NAME) seguendo questi passaggi:
- Nella console Google Cloud , vai alla pagina Inferenze batch di Vertex AI.
- Seleziona l'inferenza che hai creato.
-
Il set di dati di output è indicato in Posizione di esportazione. Il nome del set di dati è
formattato come segue:
prediction_MODEL_NAME_TIMESTAMP
Tabelle di output
Il set di dati di output contiene una o più delle seguenti tre tabelle di output:
-
Tabella di inferenza
Questa tabella contiene una riga per ogni riga dei dati di input in cui è stata richiesta un'inferenza (ovvero dove TARGET_COLUMN_NAME = null). Ad esempio, se l'input includeva 14 voci null per la colonna target (ad esempio le vendite per i prossimi 14 giorni), la richiesta di inferenza restituisce 14 righe, il numero di vendite per ogni giorno. Se la tua richiesta di inferenza supera l'orizzonte di previsione del modello, Vertex AI restituisce solo le inferenze fino all'orizzonte di previsione.
-
Tabella di convalida degli errori
Questa tabella contiene una riga per ogni errore non critico rilevato durante la fase di aggregazione che precede l'inferenza batch. Ogni errore non critico corrisponde a una riga nei dati di input per cui Vertex AI non è riuscita a restituire una previsione.
-
Tabella degli errori
Questa tabella contiene una riga per ogni errore non critico rilevato durante l'inferenza batch. Ogni errore non critico corrisponde a una riga nei dati di input per cui Vertex AI non è riuscita a restituire una previsione.
Tabella delle previsioni
Il nome della tabella (BQ_PREDICTIONS_TABLE_NAME) è formato
aggiungendo `predictions_` con il timestamp dell'inizio del job di inferenza batch: predictions_TIMESTAMP
Per recuperare la tabella delle inferenze:
-
Nella console, vai alla pagina BigQuery.
Vai a BigQuery -
Esegui questa query:
SELECT * FROM BQ_DATASET_NAME.BQ_PREDICTIONS_TABLE_NAME
Vertex AI archivia le inferenze nella colonna predicted_TARGET_COLUMN_NAME.value.
Se hai addestrato un modello
con il trasformatore di fusione temporale (TFT), puoi trovare l'output di interpretabilità di TFT nella
colonna predicted_TARGET_COLUMN_NAME.tft_feature_importance.
Questa colonna è ulteriormente suddivisa in:
context_columns: funzionalità di previsione i cui valori della finestra contestuale fungono da input per il codificatore LSTM (Long Short-Term Memory) di TFT.context_weights: i pesi dell'importanza delle funzionalità associati a ciascuno deicontext_columnsper l'istanza prevista.horizon_columns: Funzionalità di previsione i cui valori dell'orizzonte di previsione fungono da input per il decodificatore LSTM (Long Short-Term Memory) di TFT.horizon_weights: i pesi dell'importanza delle funzionalità associati a ciascuno deihorizon_columnsper l'istanza prevista.attribute_columns: Funzionalità di previsione che sono invarianti nel tempo.attribute_weights: i pesi associati a ciascuno deiattribute_columns.
Se il modello è
ottimizzato per la perdita quantile e il set di quantili include la mediana,
predicted_TARGET_COLUMN_NAME.value è il valore di inferenza alla
mediana. Altrimenti, predicted_TARGET_COLUMN_NAME.value è il
valore di inferenza nel quantile più basso del set. Ad esempio, se il tuo insieme di quantili
è [0.1, 0.5, 0.9], value è l'inferenza per il quantile 0.5.
Se il tuo insieme di quantili è [0.1, 0.9], value è l'inferenza per
il quantile 0.1.
Inoltre, Vertex AI archivia i valori dei quantili e le inferenze nelle seguenti colonne:
-
predicted_TARGET_COLUMN_NAME.quantile_values: i valori dei quantili, che vengono impostati durante l'addestramento del modello. Ad esempio, possono essere0.1,0.5e0.9. -
predicted_TARGET_COLUMN_NAME.quantile_predictions: i valori di inferenza associati ai valori dei quantili.
Se il modello utilizza l'inferenza probabilistica,
predicted_TARGET_COLUMN_NAME.value contiene il minimizzatore dell'obiettivo di ottimizzazione. Ad esempio, se l'obiettivo di ottimizzazione è minimize-rmse,
predicted_TARGET_COLUMN_NAME.value contiene il valore medio. Se è
minimize-mae, predicted_TARGET_COLUMN_NAME.value
contiene il valore mediano.
Se il modello utilizza l'inferenza probabilistica con quantili, Vertex AI archivia i valori e le inferenze dei quantili nelle seguenti colonne:
-
predicted_TARGET_COLUMN_NAME.quantile_values: i valori dei quantili, che vengono impostati durante l'addestramento del modello. Ad esempio, possono essere0.1,0.5e0.9. -
predicted_TARGET_COLUMN_NAME.quantile_predictions: i valori di inferenza associati ai valori dei quantili.
Se hai attivato gli attributi delle funzionalità, puoi trovarli anche nella tabella delle inferenze. Per accedere alle attribuzioni di una funzionalità BQ_FEATURE_NAME, esegui la seguente query:
SELECT explanation.attributions[OFFSET(0)].featureAttributions.BQ_FEATURE_NAME FROM BQ_DATASET_NAME.BQ_PREDICTIONS_TABLE_NAME
Per saperne di più, consulta Attribuzioni delle funzionalità per le previsioni.
Tabella di convalida degli errori
Il nome della tabella (BQ_ERRORS_VALIDATION_TABLE_NAME)
è formato aggiungendo `errors_validation` con il timestamp dell'inizio del
job di inferenza batch: errors_validation_TIMESTAMP
-
Nella console, vai alla pagina BigQuery.
Vai a BigQuery -
Esegui questa query:
SELECT * FROM BQ_DATASET_NAME.BQ_ERRORS_VALIDATION_TABLE_NAME
- errors_TARGET_COLUMN_NAME
Tabella degli errori
Il nome della tabella (BQ_ERRORS_TABLE_NAME) è formato
aggiungendo `errors_` con il timestamp dell'inizio del job di inferenza batch: errors_TIMESTAMP
-
Nella console, vai alla pagina BigQuery.
Vai a BigQuery -
Esegui questa query:
SELECT * FROM BQ_DATASET_NAME.BQ_ERRORS_TABLE_NAME
- errors_TARGET_COLUMN_NAME.code
- errors_TARGET_COLUMN_NAME.message
Cloud Storage
Se hai specificato Cloud Storage come destinazione di output, i risultati della richiesta di inferenza batch vengono restituiti come oggetti CSV in una nuova cartella nel bucket specificato. Il nome della cartella è il nome del modello, preceduto da "prediction-" e seguito dal timestamp dell'avvio del job di inferenza batch. Puoi trovare il nome della cartella Cloud Storage nella scheda Previsioni batch del modello.
La cartella Cloud Storage contiene due tipi di oggetti:-
Oggetti di inferenza
Gli oggetti di inferenza sono denominati `predictions_1.csv`, `predictions_2.csv` e così via. Contengono una riga di intestazione con i nomi delle colonne e una riga per ogni previsione restituita. Il numero di valori di inferenza dipende dall'input di inferenza e dall'orizzonte di previsione. Ad esempio, se l'input includeva 14 voci null per la colonna target (ad esempio le vendite per i prossimi 14 giorni), la richiesta di inferenza restituisce 14 righe, il numero di vendite per ogni giorno. Se la tua richiesta di inferenza supera l'orizzonte di previsione del modello, Vertex AI restituisce solo le inferenze fino all'orizzonte di previsione.
I valori di previsione vengono restituiti in una colonna denominata `predicted_TARGET_COLUMN_NAME`. Per le previsioni quantili, la colonna di output contiene le inferenze quantili e i valori quantili in formato JSON.
-
Oggetti di errore
Gli oggetti di errore sono denominati `errors_1.csv`, `errors_2.csv` e così via. Contengono una riga di intestazione e una riga per ogni riga dei dati di input per cui Vertex AI non è riuscita a restituire una previsione (ad esempio, se una caratteristica non annullabile era null).
Nota: se i risultati sono di grandi dimensioni, vengono suddivisi in più oggetti.
Query di attribuzione delle funzionalità di esempio in BigQuery
Esempio 1: determinare le attribuzioni per una singola inferenza
Considera la seguente domanda:
Di quanto un annuncio di un prodotto ha aumentato le vendite previste il 24 novembre in un determinato negozio?
La query corrispondente è la seguente:
SELECT
* EXCEPT(explanation, predicted_sales),
ROUND(predicted_sales.value, 2) AS predicted_sales,
ROUND(
explanation.attributions[OFFSET(0)].featureAttributions.advertisement,
2
) AS attribution_advertisement
FROM
`project.dataset.predictions`
WHERE
product = 'product_0'
AND store = 'store_0'
AND date = '2019-11-24'
Esempio 2: determinare l'importanza globale delle funzionalità
Considera la seguente domanda:
In che misura ogni caratteristica ha contribuito alle vendite previste complessive?
Puoi calcolare manualmente l'importanza delle caratteristiche globali aggregando le attribuzioni dell'importanza delle caratteristiche locali. La query corrispondente è la seguente:
WITH
/*
* Aggregate from (id, date) level attributions to global feature importance.
*/
attributions_aggregated AS (
SELECT
SUM(ABS(attributions.featureAttributions.date)) AS date,
SUM(ABS(attributions.featureAttributions.advertisement)) AS advertisement,
SUM(ABS(attributions.featureAttributions.holiday)) AS holiday,
SUM(ABS(attributions.featureAttributions.sales)) AS sales,
SUM(ABS(attributions.featureAttributions.store)) AS store,
SUM(ABS(attributions.featureAttributions.product)) AS product,
FROM
project.dataset.predictions,
UNNEST(explanation.attributions) AS attributions
),
/*
* Calculate the normalization constant for global feature importance.
*/
attributions_aggregated_with_total AS (
SELECT
*,
date + advertisement + holiday + sales + store + product AS total
FROM
attributions_aggregated
)
/*
* Calculate the normalized global feature importance.
*/
SELECT
ROUND(date / total, 2) AS date,
ROUND(advertisement / total, 2) AS advertisement,
ROUND(holiday / total, 2) AS holiday,
ROUND(sales / total, 2) AS sales,
ROUND(store / total, 2) AS store,
ROUND(product / total, 2) AS product,
FROM
attributions_aggregated_with_total
Esempio di output di inferenza batch in BigQuery
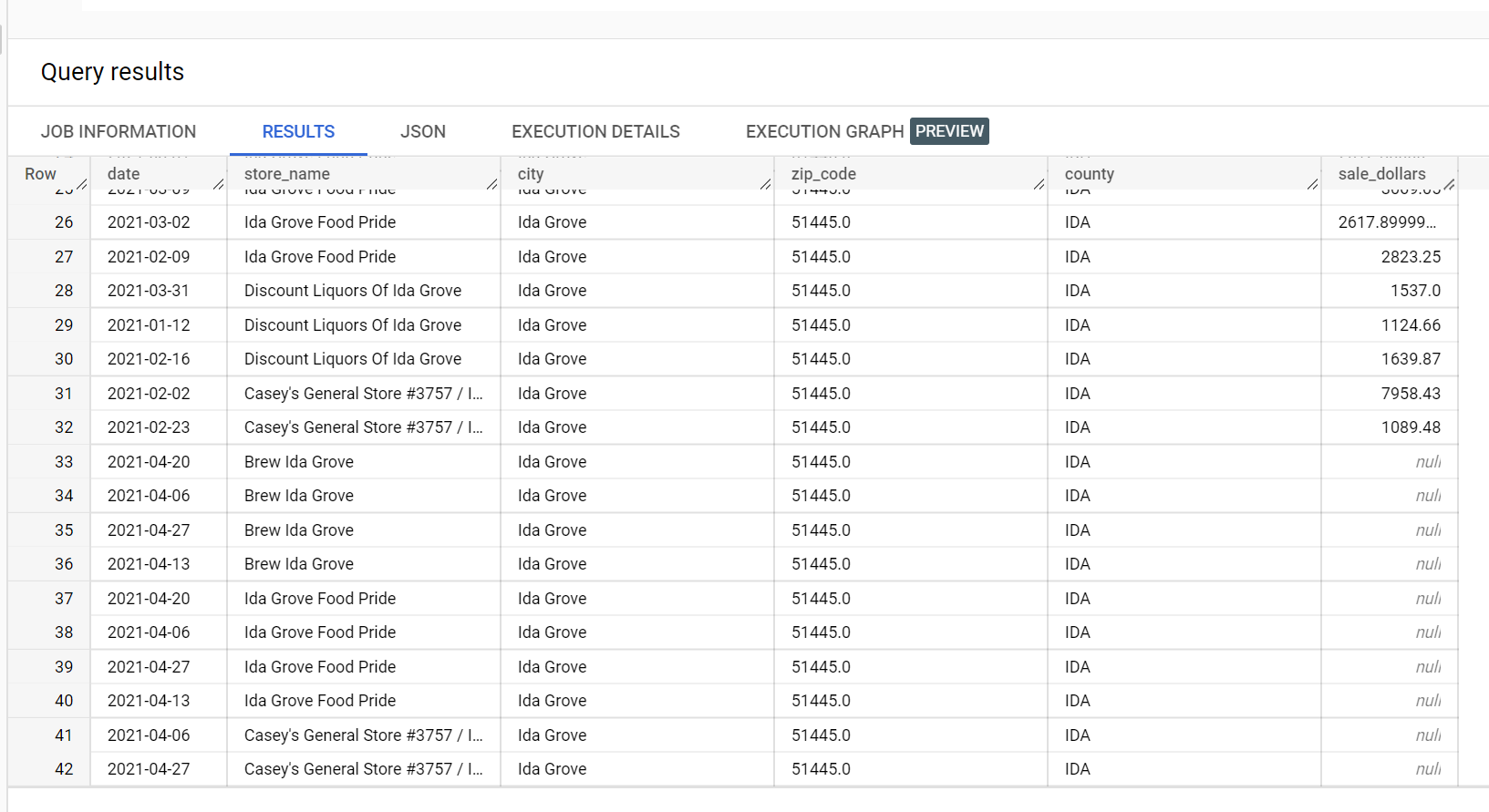
In un set di dati di esempio sulle vendite di liquori, ci sono quattro negozi nella città di
"Ida Grove": "Ida Grove Food Pride", "Discount Liquors of Ida Grove",
"Casey's General Store #3757" e "Brew Ida Grove". store_name è il
series identifier e tre dei quattro negozi richiedono inferenze per la
colonna target sale_dollars. Viene generato un errore di convalida perché
non è stata richiesta alcuna previsione per "Discount Liquors of Ida Grove".
Di seguito è riportato un estratto del set di dati di input utilizzato per l'inferenza:
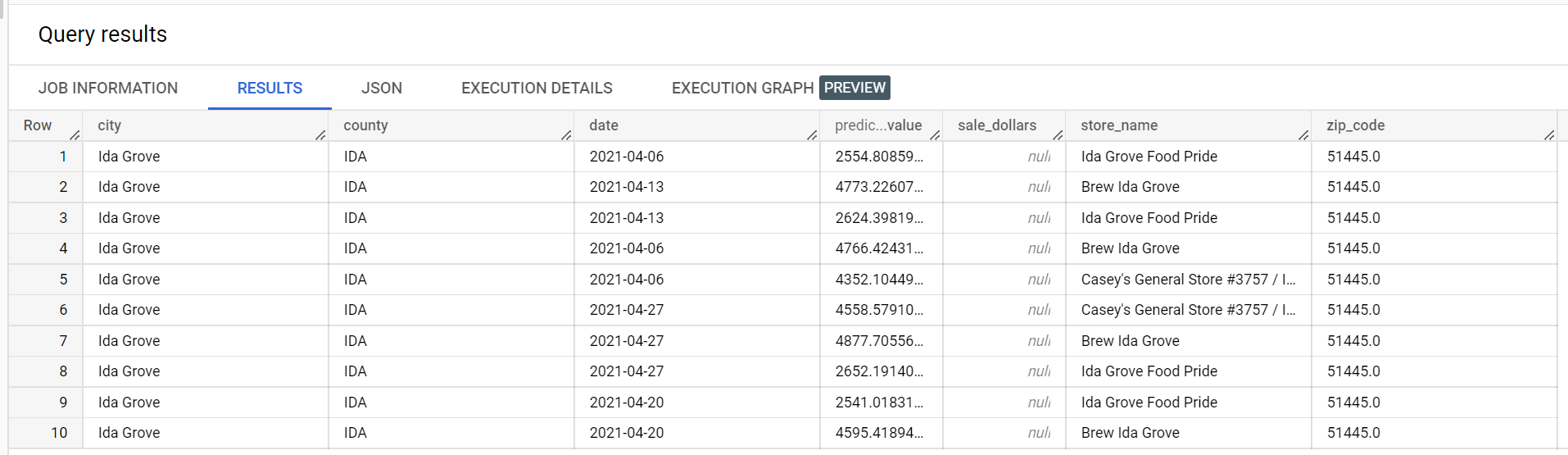
Di seguito è riportato un estratto dei risultati dell'inferenza:
Di seguito è riportato un estratto degli errori di convalida:

Esempio di output di inferenza batch per un modello ottimizzato per la perdita quantile
Il seguente esempio mostra l'output dell'inferenza batch per un modello ottimizzato per la perdita quantile. In questo scenario, il modello di previsione ha previsto le vendite per i prossimi 14 giorni per ogni negozio.
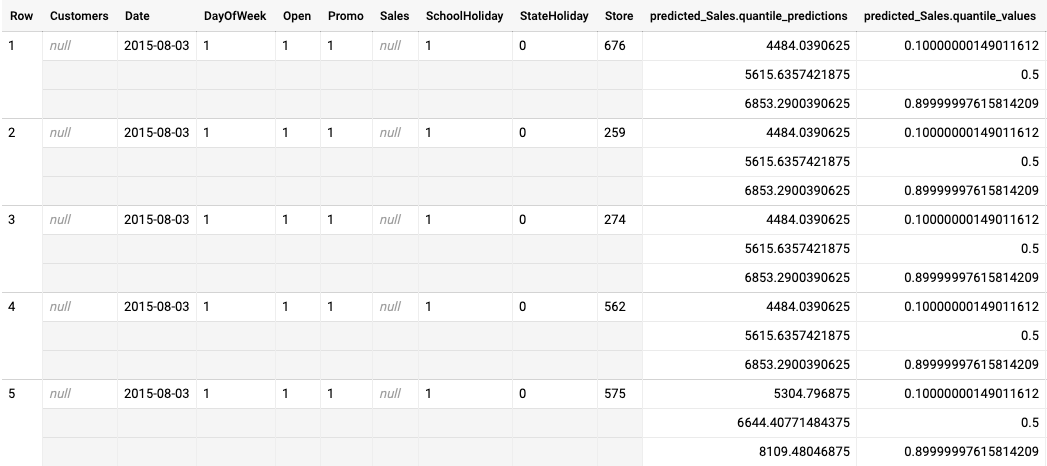
I valori dei quantili sono indicati nella colonna predicted_Sales.quantile_values. In questo
esempio, il modello ha previsto i valori ai quantili 0.1, 0.5 e 0.9.
I valori di inferenza sono indicati nella colonna predicted_Sales.quantile_predictions.
Si tratta di un array di valori di vendita, che corrispondono ai valori dei quantili nella colonna
predicted_Sales.quantile_values. Nella prima riga, vediamo che la probabilità
che il valore delle vendite sia inferiore a 4484.04 è del 10%. La probabilità che il valore delle vendite
sia inferiore a 5615.64 è del 50%. La probabilità che il valore delle vendite sia inferiore a
6853.29 è del 90%. L'inferenza per la prima riga, rappresentata come un singolo valore, è
5615.64.
Passaggi successivi
- Scopri di più sui prezzi per le inferenze batch.