Vertex AI ofrece dos opciones para proyectar valores futuros con el modelo de previsión entrenado: inferencias online e inferencias por lotes.
Una inferencia online es una solicitud síncrona. Usa inferencias online cuando hagas solicitudes en respuesta a la entrada de una aplicación o en otras situaciones en las que necesites una inferencia oportuna.
Una solicitud de inferencia por lotes es una solicitud asíncrona. Puedes usar la inferencia por lotes si no necesitas una respuesta inmediata y quieres procesar los datos acumulados a partir de una sola solicitud.
En esta página se explica cómo proyectar valores futuros mediante inferencias por lotes. Para saber cómo proyectar valores mediante inferencias online, consulta Obtener inferencias online para un modelo de previsión.
Puedes solicitar inferencias por lotes directamente desde el recurso del modelo.
Puedes solicitar una inferencia con explicaciones (también llamadas atribuciones de características) para ver cómo ha llegado tu modelo a una inferencia. Los valores de importancia de las funciones locales te indican cuánto ha contribuido cada función al resultado de la inferencia. Para obtener una descripción general conceptual, consulta Atribuciones de funciones para la previsión.
Para obtener información sobre los precios de las inferencias por lotes, consulta la sección Precios de los flujos de trabajo tabulares.
Antes de empezar
Antes de enviar una solicitud de inferencia por lotes, entrena un modelo.
Datos de entrada
Los datos de entrada de las solicitudes de inferencia por lotes son los que usa tu modelo para crear previsiones. Puedes proporcionar datos de entrada en uno de estos dos formatos:
- Objetos CSV en Cloud Storage
- Tablas de BigQuery
Te recomendamos que utilices el mismo formato para los datos de entrada que usaste para entrenar el modelo. Por ejemplo, si has entrenado tu modelo con datos de BigQuery, lo mejor es usar una tabla de BigQuery como entrada para la inferencia por lotes. Como Vertex AI trata todos los campos de entrada CSV como cadenas, mezclar formatos de datos de entrenamiento y de entrada puede provocar errores.
Su fuente de datos debe contener datos tabulares que incluyan todas las columnas, en cualquier orden, que se hayan usado para entrenar el modelo. Puede incluir columnas que no estuvieran en los datos de entrenamiento o que sí estuvieran, pero que se excluyeran del entrenamiento. Estas columnas adicionales se incluyen en la salida, pero no afectan a los resultados de las previsiones.
Requisitos de los datos de entrada
Los datos de entrada de los modelos de previsión deben cumplir los siguientes requisitos:
- Todos los valores de la columna de tiempo deben estar presentes y ser válidos.
- Todas las columnas que se usen en la solicitud de inferencia deben estar presentes en los datos de entrada. Cuando las columnas están vacías o no existen, Vertex AI rellena los datos automáticamente.
- La frecuencia de los datos de entrada y de los datos de entrenamiento debe coincidir. Si faltan filas en la serie temporal, debes insertarlas manualmente según el conocimiento del dominio adecuado.
- Las series temporales con marcas de tiempo duplicadas se eliminan de las inferencias. Para incluirlos, quita las marcas de tiempo duplicadas.
- Proporciona datos históricos de cada serie temporal que quieras predecir. Para obtener las previsiones más precisas, la cantidad de datos debe ser igual a la ventana de contexto, que se define durante el entrenamiento del modelo. Por ejemplo, si la ventana de contexto es de 14 días, proporcione al menos 14 días de datos históricos. Si proporcionas menos datos, Vertex AI rellena los datos con valores vacíos.
- La previsión empieza en la primera fila de una serie temporal (ordenada por tiempo) con un valor nulo en la columna de destino. El valor nulo debe ser continuo en la serie temporal. Por ejemplo, si la columna de destino está ordenada por tiempo, no puedes tener algo como
1,2,null,3,4,null,nullen una sola serie temporal. En el caso de los archivos CSV, Vertex AI trata las cadenas vacías como nulas, mientras que BigQuery admite de forma nativa los valores nulos.
Tabla de BigQuery
Si elige una tabla de BigQuery como entrada, debe asegurarse de que se cumplan los siguientes requisitos:
- Las tablas de fuentes de datos de BigQuery no pueden superar los 100 GB.
- Si la tabla está en otro proyecto, debes conceder el rol
BigQuery Data Editora la cuenta de servicio de Vertex AI en ese proyecto.
Archivo CSV
Si eliges un objeto CSV de Cloud Storage como entrada, debes asegurarte de lo siguiente:
- La fuente de datos debe empezar por una fila de encabezado con los nombres de las columnas.
- El tamaño de cada objeto de fuente de datos no debe superar los 10 GB. Puedes incluir varios archivos siempre que no sobrepases el máximo de 100 GB.
- Si el segmento de Cloud Storage está en otro proyecto, debes asignar el rol
Storage Object Creatora la cuenta de servicio de Vertex AI en ese proyecto. - Todas las cadenas deben ir entre comillas dobles (").
Formato de salida
El formato de salida de tu solicitud de inferencia por lotes no tiene por qué ser el mismo que el formato de entrada. Por ejemplo, si usas una tabla de BigQuery como entrada, puedes generar los resultados de las previsiones en un objeto CSV de Cloud Storage.
Enviar una solicitud de inferencia por lotes a tu modelo
Para hacer solicitudes de inferencia por lotes, puedes usar la Google Cloud consola o la API de Vertex AI. La fuente de datos de entrada pueden ser objetos CSV almacenados en un segmento de Cloud Storage o tablas de BigQuery. En función de la cantidad de datos que envíe como entrada, una tarea de inferencia por lotes puede tardar en completarse.
Google Cloud consola
Usa la consola Google Cloud para solicitar una inferencia por lotes.
- En la consola de Google Cloud , en la sección Vertex AI, ve a la página Inferencias por lotes.
- Haz clic en Crear para abrir la ventana Nueva inferencia por lotes.
- En Define your batch inference (Define tu inferencia por lotes), sigue estos pasos:
- Escribe un nombre para la inferencia por lotes.
- En Nombre del modelo, selecciona el nombre del modelo que quieras usar para esta inferencia por lotes.
- En Versión, selecciona la versión del modelo.
- En Seleccionar fuente, indica si los datos de entrada de la fuente son un archivo CSV en Cloud Storage o una tabla de BigQuery.
- En el caso de los archivos CSV, especifica la ubicación de Cloud Storage en la que se encuentra el archivo de entrada CSV.
- En el caso de las tablas de BigQuery, especifica el ID del proyecto en el que se encuentra la tabla, el ID del conjunto de datos de BigQuery y el ID de la tabla o la vista de BigQuery.
- En Salida de inferencia por lotes, seleccione CSV o BigQuery.
- En el caso de los archivos CSV, especifica el segmento de Cloud Storage en el que Vertex AI almacena los resultados.
- En BigQuery, puede especificar un ID de proyecto o un conjunto de datos:
- Para especificar el ID del proyecto, introdúcelo en el campo ID de proyecto de Google Cloud. Vertex AI crea un nuevo conjunto de datos de salida.
- Para especificar un conjunto de datos, introduce su ruta de BigQuery en el campo ID de proyecto de Google Cloud, como
bq://projectid.datasetid.
- Opcional. Si el destino de salida es BigQuery o JSONL en Cloud Storage, puedes habilitar las atribuciones de características además de las inferencias. Para ello, selecciona Habilitar atribuciones de funciones para este modelo. Las atribuciones de funciones no se admiten en los archivos CSV de Cloud Storage. Más información
- Opcional: Monitorización de modelos
El análisis de las inferencias por lotes está disponible en Vista previa. Consulta los requisitos para añadir la configuración de detección de sesgos a tu trabajo de inferencia por lotes.
- Haz clic para activar Habilitar la monitorización del modelo para esta inferencia por lotes.
- Seleccione una fuente de datos de entrenamiento. Introduce la ruta de datos o la ubicación de la fuente de datos de entrenamiento que hayas seleccionado.
- Opcional: En Umbrales de alerta, especifica los umbrales en los que se activarán las alertas.
- En Correos de notificación, introduzca una o varias direcciones de correo separadas por comas para recibir alertas cuando un modelo supere un umbral de alerta.
- Opcional: En Canales de notificación, añade canales de Cloud Monitoring para recibir alertas cuando un modelo supere un umbral de alerta. Puedes seleccionar canales de Cloud Monitoring o crear uno haciendo clic en Gestionar canales de notificaciones. La consola admite canales de notificación de PagerDuty, Slack y Pub/Sub.
- Haz clic en Crear.
API : BigQuery
REST
Para solicitar una inferencia por lotes, usa el método batchPredictionJobs.create.
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
- LOCATION_ID: región en la que se almacena el modelo y se ejecuta el trabajo de inferencia por lotes. Por ejemplo,
us-central1. - PROJECT_ID: tu ID de proyecto
- BATCH_JOB_NAME: nombre visible del trabajo por lotes
- MODEL_ID: ID del modelo que se va a usar para hacer inferencias.
-
INPUT_URI: referencia a la fuente de datos de BigQuery. En el formulario:
bq://bqprojectId.bqDatasetId.bqTableId
-
OUTPUT_URI: referencia al destino de BigQuery (donde se escriben las inferencias). Especifica el ID del proyecto y, opcionalmente,
el ID de un conjunto de datos que ya tengas. Utiliza el siguiente formulario:
bq://bqprojectId.bqDatasetId
bq://bqprojectId
- GENERATE_EXPLANATION: el valor predeterminado es false. Asigna el valor true para habilitar las atribuciones de funciones. Para obtener más información, consulta Atribuciones de funciones para las previsiones.
Método HTTP y URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs
Cuerpo JSON de la solicitud:
{
"displayName": "BATCH_JOB_NAME",
"model": "projects/PROJECT_ID/locations/LOCATION_ID/models/MODEL_ID",
"inputConfig": {
"instancesFormat": "bigquery",
"bigquerySource": {
"inputUri": "INPUT_URI"
}
},
"outputConfig": {
"predictionsFormat": "bigquery",
"bigqueryDestination": {
"outputUri": "OUTPUT_URI"
}
},
"generate_explanation": GENERATE_EXPLANATION
}
Para enviar tu solicitud, elige una de estas opciones:
curl
Guarda el cuerpo de la solicitud en un archivo llamado request.json
y ejecuta el siguiente comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs"
PowerShell
Guarda el cuerpo de la solicitud en un archivo llamado request.json
y ejecuta el siguiente comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs" | Select-Object -Expand Content
Deberías recibir una respuesta JSON similar a la siguiente:
{
"name": "projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs/67890",
"displayName": "batch_job_1 202005291958",
"model": "projects/12345/locations/us-central1/models/5678",
"state": "JOB_STATE_PENDING",
"inputConfig": {
"instancesFormat": "bigquery",
"bigquerySource": {
"inputUri": "INPUT_URI"
}
},
"outputConfig": {
"predictionsFormat": "bigquery",
"bigqueryDestination": {
"outputUri": bq://12345
}
},
"dedicatedResources": {
"machineSpec": {
"machineType": "n1-standard-32",
"acceleratorCount": "0"
},
"startingReplicaCount": 2,
"maxReplicaCount": 6
},
"manualBatchTuningParameters": {
"batchSize": 4
},
"outputInfo": {
"bigqueryOutputDataset": "bq://12345.reg_model_2020_10_02_06_04
}
"state": "JOB_STATE_PENDING",
"createTime": "2020-09-30T02:58:44.341643Z",
"updateTime": "2020-09-30T02:58:44.341643Z",
}
Java
Antes de probar este ejemplo, sigue las Java instrucciones de configuración de la guía de inicio rápido de Vertex AI con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Java de Vertex AI.
Para autenticarte en Vertex AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
En el siguiente ejemplo, sustituya INSTANCES_FORMAT y PREDICTIONS_FORMAT por `bigquery`. Para saber cómo sustituir los demás marcadores de posición, consulte la pestaña `REST & CMD LINE` de esta sección.Python
Para saber cómo instalar o actualizar el SDK de Vertex AI para Python, consulta Instalar el SDK de Vertex AI para Python. Para obtener más información, consulta la documentación de referencia de la API Python.
API : Cloud Storage
REST
Para solicitar una inferencia por lotes, usa el método batchPredictionJobs.create.
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
- LOCATION_ID: región en la que se almacena el modelo y se ejecuta el trabajo de inferencia por lotes. Por ejemplo,
us-central1. - PROJECT_ID:
- BATCH_JOB_NAME: nombre visible del trabajo por lotes
- MODEL_ID: ID del modelo que se va a usar para hacer inferencias.
-
URI: rutas (URIs) a los contenedores de Cloud Storage que contienen los datos de entrenamiento.
Puede haber más de una. Cada URI tiene el siguiente formato:
gs://bucketName/pathToFileName
-
OUTPUT_URI_PREFIX: ruta a un destino de Cloud Storage donde se escribirán las
inferencias. Vertex AI escribe las inferencias por lotes en un subdirectorio con marca de tiempo de esta ruta. Asigna a este campo una cadena con el siguiente formato:
gs://bucketName/pathToOutputDirectory
- GENERATE_EXPLANATION: el valor predeterminado es false. Asigna el valor true para habilitar las atribuciones de funciones. Esta opción solo está disponible si el destino de salida es JSONL. Las atribuciones de funciones no se admiten en los archivos CSV de Cloud Storage. Para obtener más información, consulta Atribuciones de funciones para las previsiones.
Método HTTP y URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs
Cuerpo JSON de la solicitud:
{
"displayName": "BATCH_JOB_NAME",
"model": "projects/PROJECT_ID/locations/LOCATION_ID/models/MODEL_ID",
"inputConfig": {
"instancesFormat": "csv",
"gcsSource": {
"uris": [
URI1,...
]
},
},
"outputConfig": {
"predictionsFormat": "csv",
"gcsDestination": {
"outputUriPrefix": "OUTPUT_URI_PREFIX"
}
},
"generate_explanation": GENERATE_EXPLANATION
}
Para enviar tu solicitud, elige una de estas opciones:
curl
Guarda el cuerpo de la solicitud en un archivo llamado request.json
y ejecuta el siguiente comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs"
PowerShell
Guarda el cuerpo de la solicitud en un archivo llamado request.json
y ejecuta el siguiente comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs" | Select-Object -Expand Content
Deberías recibir una respuesta JSON similar a la siguiente:
{
"name": "projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs/67890",
"displayName": "batch_job_1 202005291958",
"model": "projects/12345/locations/us-central1/models/5678",
"state": "JOB_STATE_PENDING",
"inputConfig": {
"instancesFormat": "csv",
"gcsSource": {
"uris": [
"gs://bp_bucket/reg_mode_test"
]
}
},
"outputConfig": {
"predictionsFormat": "csv",
"gcsDestination": {
"outputUriPrefix": "OUTPUT_URI_PREFIX"
}
},
"dedicatedResources": {
"machineSpec": {
"machineType": "n1-standard-32",
"acceleratorCount": "0"
},
"startingReplicaCount": 2,
"maxReplicaCount": 6
}
"outputInfo": {
"gcsOutputDataset": "OUTPUT_URI_PREFIX/prediction-batch_job_1 202005291958-2020-09-30T02:58:44.341643Z"
}
"state": "JOB_STATE_PENDING",
"createTime": "2020-09-30T02:58:44.341643Z",
"updateTime": "2020-09-30T02:58:44.341643Z",
}
Python
Para saber cómo instalar o actualizar el SDK de Vertex AI para Python, consulta Instalar el SDK de Vertex AI para Python. Para obtener más información, consulta la documentación de referencia de la API Python.
Recuperar resultados de inferencia por lotes
Vertex AI envía la salida de las inferencias por lotes al destino que hayas especificado, que puede ser BigQuery o Cloud Storage.
No se admite la salida de Cloud Storage para las atribuciones de características.
BigQuery
Conjunto de datos de salida
Si usas BigQuery, la salida de la inferencia por lotes se almacena en un conjunto de datos de salida. Si has proporcionado un conjunto de datos a Vertex AI, el nombre del conjunto de datos (BQ_DATASET_NAME) es el que habías proporcionado anteriormente. Si no has proporcionado un conjunto de datos de salida, Vertex AI habrá creado uno por ti. Para ver su nombre (BQ_DATASET_NAME), siga estos pasos:
- En la Google Cloud consola, ve a la página Inferencia por lotes de Vertex AI.
- Selecciona la inferencia que has creado.
-
El conjunto de datos de salida se indica en Ubicación de exportación. El nombre del conjunto de datos tiene el siguiente formato:
prediction_MODEL_NAME_TIMESTAMP
Tablas de resultados
El conjunto de datos de salida contiene una o varias de las siguientes tablas de salida:
-
Tabla de inferencia
Esta tabla contiene una fila por cada fila de los datos de entrada en la que se solicitó una inferencia (es decir, donde TARGET_COLUMN_NAME = null). Por ejemplo, si tu entrada incluye 14 entradas nulas para la columna de destino (como las ventas de los próximos 14 días), tu solicitud de inferencia devolverá 14 filas, el número de ventas de cada día. Si tu solicitud de inferencia supera el horizonte de previsión del modelo, Vertex AI solo devuelve inferencias hasta el horizonte de previsión.
-
Tabla de validación de errores
Esta tabla contiene una fila por cada error no crítico que se haya producido durante la fase de agregación que tiene lugar antes de la inferencia por lotes. Cada error no crítico se corresponde con una fila de los datos de entrada para la que Vertex AI no ha podido devolver una previsión.
-
Tabla de errores
Esta tabla contiene una fila por cada error no crítico que se haya producido durante la inferencia por lotes. Cada error no crítico se corresponde con una fila de los datos de entrada para la que Vertex AI no ha podido devolver una previsión.
Tabla de predicciones
El nombre de la tabla (BQ_PREDICTIONS_TABLE_NAME) se forma añadiendo `predictions_` a la marca de tiempo de cuando se inició la tarea de inferencia por lotes: predictions_TIMESTAMP.
Para recuperar la tabla de inferencias, sigue estos pasos:
-
En la consola, ve a la página BigQuery.
Ir a BigQuery -
Ejecuta la siguiente consulta:
SELECT * FROM BQ_DATASET_NAME.BQ_PREDICTIONS_TABLE_NAME
Vertex AI almacena las inferencias en la columna predicted_TARGET_COLUMN_NAME.value.
Si has entrenado un modelo con Temporal Fusion Transformer (TFT), puedes encontrar los resultados de la interpretabilidad de TFT en la columna predicted_TARGET_COLUMN_NAME.tft_feature_importance.
Esta columna se divide en lo siguiente:
context_columns: funciones de previsión cuyos valores de ventana de contexto sirven como entradas para el codificador de memoria a corto y largo plazo (LSTM) de TFT.context_weights: los pesos de importancia de las funciones asociados a cada uno de loscontext_columnsde la instancia predicha.horizon_columns: funciones de previsión cuyos valores de horizonte de previsión sirven como entradas para el decodificador de memoria a corto y largo plazo (LSTM) de TFT.horizon_weights: los pesos de importancia de las funciones asociados a cada uno de loshorizon_columnsde la instancia predicha.attribute_columns: funciones de previsión que son invariantes en el tiempo.attribute_weights: los pesos asociados a cada uno de losattribute_columns.
Si tu modelo está
optimizado para la pérdida de cuantiles y tu conjunto de cuantiles incluye la mediana,
predicted_TARGET_COLUMN_NAME.value es el valor de inferencia en la mediana. De lo contrario, predicted_TARGET_COLUMN_NAME.value es el valor de inferencia del cuantil más bajo del conjunto. Por ejemplo, si tu conjunto de cuantiles es [0.1, 0.5, 0.9], value es la inferencia del cuantil 0.5.
Si tu conjunto de cuantiles es [0.1, 0.9], value es la inferencia del
cuantil 0.1.
Además, Vertex AI almacena los valores de los cuantiles y las inferencias en las siguientes columnas:
-
predicted_TARGET_COLUMN_NAME.quantile_values: los valores de los cuantiles, que se definen durante el entrenamiento del modelo. Por ejemplo, pueden ser0.1,0.5y0.9. -
predicted_TARGET_COLUMN_NAME.quantile_predictions: los valores de inferencia asociados a los valores de los cuantiles.
Si tu modelo usa inferencia probabilística,
predicted_TARGET_COLUMN_NAME.value contiene el minimizador del
objetivo de optimización. Por ejemplo, si tu objetivo de optimización es minimize-rmse,
predicted_TARGET_COLUMN_NAME.value contiene el valor medio. Si es minimize-mae, predicted_TARGET_COLUMN_NAME.value
contiene el valor mediano.
Si tu modelo usa inferencia probabilística con cuantiles, Vertex AI almacena los valores y las inferencias de los cuantiles en las siguientes columnas:
-
predicted_TARGET_COLUMN_NAME.quantile_values: los valores de los cuantiles, que se definen durante el entrenamiento del modelo. Por ejemplo, pueden ser0.1,0.5y0.9. -
predicted_TARGET_COLUMN_NAME.quantile_predictions: los valores de inferencia asociados a los valores de los cuantiles.
Si has habilitado las atribuciones de funciones, también las encontrarás en la tabla inference. Para acceder a las atribuciones de una función BQ_FEATURE_NAME, ejecuta la siguiente consulta:
SELECT explanation.attributions[OFFSET(0)].featureAttributions.BQ_FEATURE_NAME FROM BQ_DATASET_NAME.BQ_PREDICTIONS_TABLE_NAME
Para obtener más información, consulta Atribuciones de funciones para las previsiones.
Tabla de validación de errores
El nombre de la tabla (BQ_ERRORS_VALIDATION_TABLE_NAME)
se forma añadiendo `errors_validation` a la marca de tiempo de cuando se inició el
trabajo de inferencia por lotes: errors_validation_TIMESTAMP
-
En la consola, ve a la página BigQuery.
Ir a BigQuery -
Ejecuta la siguiente consulta:
SELECT * FROM BQ_DATASET_NAME.BQ_ERRORS_VALIDATION_TABLE_NAME
- errors_TARGET_COLUMN_NAME
Tabla de errores
El nombre de la tabla (BQ_ERRORS_TABLE_NAME) se forma añadiendo `errors_` a la marca de tiempo de cuándo se inició el trabajo de inferencia por lotes: errors_TIMESTAMP.
-
En la consola, ve a la página BigQuery.
Ir a BigQuery -
Ejecuta la siguiente consulta:
SELECT * FROM BQ_DATASET_NAME.BQ_ERRORS_TABLE_NAME
- errors_TARGET_COLUMN_NAME.code
- errors_TARGET_COLUMN_NAME.message
Cloud Storage
Si has especificado Cloud Storage como destino de salida, los resultados de tu solicitud de inferencia por lotes se devolverán como objetos CSV en una carpeta nueva del segmento que hayas especificado. El nombre de la carpeta es el nombre de tu modelo, al que se le añade el prefijo "prediction-" y la marca de tiempo de cuándo se inició el trabajo de inferencia por lotes. Puedes encontrar el nombre de la carpeta de Cloud Storage en la pestaña Predicciones por lotes de tu modelo.
La carpeta Cloud Storage contiene dos tipos de objetos:-
Objetos de inferencia
Los objetos de inferencia se denominan `predictions_1.csv`, `predictions_2.csv`, etc. Contienen una fila de encabezado con los nombres de las columnas y una fila por cada previsión devuelta. El número de valores de inferencia depende de la entrada de inferencia y del horizonte de previsión. Por ejemplo, si en la entrada se incluyen 14 entradas nulas en la columna de destino (como las ventas de los próximos 14 días), la solicitud de inferencia devolverá 14 filas, el número de ventas de cada día. Si tu solicitud de inferencia supera el horizonte de previsión del modelo, Vertex AI solo devolverá inferencias hasta el horizonte de previsión.
Los valores de previsión se devuelven en una columna llamada `predicted_TARGET_COLUMN_NAME`. En el caso de las previsiones de cuantiles, la columna de salida contiene las inferencias y los valores de los cuantiles en formato JSON.
-
Objetos de error
Los objetos de error se denominan `errors_1.csv`, `errors_2.csv`, etc. Contienen una fila de encabezado y una fila por cada fila de los datos de entrada para los que Vertex AI no ha podido devolver una previsión (por ejemplo, si una característica no anulable era nula).
Nota: Si los resultados son grandes, se dividen en varios objetos.
Consultas de ejemplo de atribución de funciones en BigQuery
Ejemplo 1: Determinar las atribuciones de una sola inferencia
Plantéate la siguiente pregunta:
¿Cuánto aumentaron las ventas previstas de un producto el 24 de noviembre en una tienda determinada gracias a un anuncio?
La consulta correspondiente es la siguiente:
SELECT
* EXCEPT(explanation, predicted_sales),
ROUND(predicted_sales.value, 2) AS predicted_sales,
ROUND(
explanation.attributions[OFFSET(0)].featureAttributions.advertisement,
2
) AS attribution_advertisement
FROM
`project.dataset.predictions`
WHERE
product = 'product_0'
AND store = 'store_0'
AND date = '2019-11-24'
Ejemplo 2: Determinar la importancia de las funciones globales
Plantéate la siguiente pregunta:
¿Cuánto ha contribuido cada función a las ventas previstas en general?
Puedes calcular manualmente la importancia de las funciones globales agregando las atribuciones de importancia de las funciones locales. La consulta correspondiente es la siguiente:
WITH
/*
* Aggregate from (id, date) level attributions to global feature importance.
*/
attributions_aggregated AS (
SELECT
SUM(ABS(attributions.featureAttributions.date)) AS date,
SUM(ABS(attributions.featureAttributions.advertisement)) AS advertisement,
SUM(ABS(attributions.featureAttributions.holiday)) AS holiday,
SUM(ABS(attributions.featureAttributions.sales)) AS sales,
SUM(ABS(attributions.featureAttributions.store)) AS store,
SUM(ABS(attributions.featureAttributions.product)) AS product,
FROM
project.dataset.predictions,
UNNEST(explanation.attributions) AS attributions
),
/*
* Calculate the normalization constant for global feature importance.
*/
attributions_aggregated_with_total AS (
SELECT
*,
date + advertisement + holiday + sales + store + product AS total
FROM
attributions_aggregated
)
/*
* Calculate the normalized global feature importance.
*/
SELECT
ROUND(date / total, 2) AS date,
ROUND(advertisement / total, 2) AS advertisement,
ROUND(holiday / total, 2) AS holiday,
ROUND(sales / total, 2) AS sales,
ROUND(store / total, 2) AS store,
ROUND(product / total, 2) AS product,
FROM
attributions_aggregated_with_total
Ejemplo de salida de inferencia por lotes en BigQuery
En un conjunto de datos de ejemplo de ventas de bebidas alcohólicas, hay cuatro tiendas en la ciudad de "Ida Grove": "Ida Grove Food Pride", "Discount Liquors of Ida Grove", "Casey's General Store #3757" y "Brew Ida Grove". store_name es el
series identifier y tres de las cuatro tiendas solicitan inferencias para la columna de destino sale_dollars. Se genera un error de validación porque no se ha solicitado ninguna previsión para "Discount Liquors of Ida Grove".
A continuación, se muestra un extracto del conjunto de datos de entrada utilizado para la inferencia:
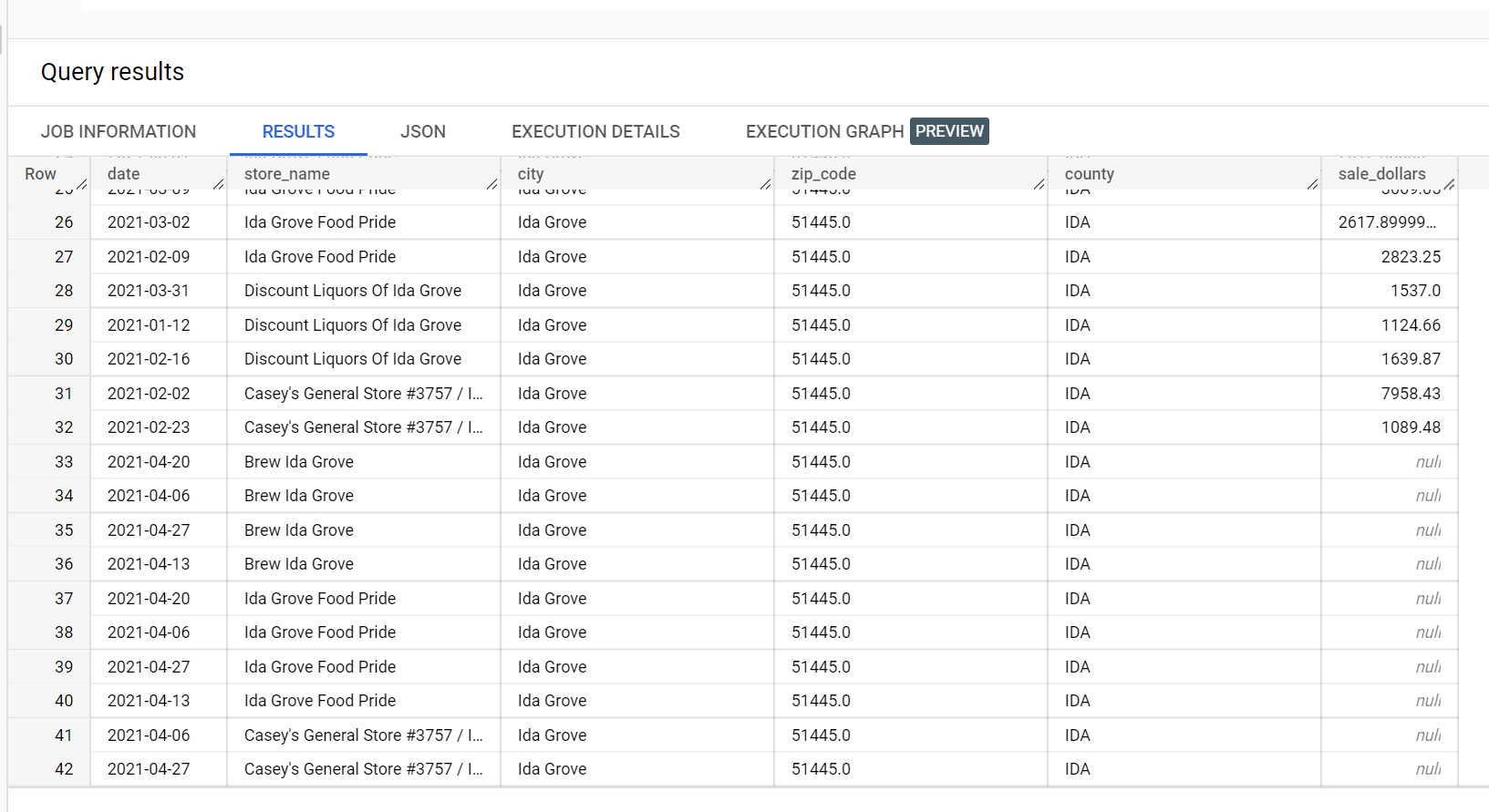
A continuación, se muestra un extracto de los resultados de la inferencia:
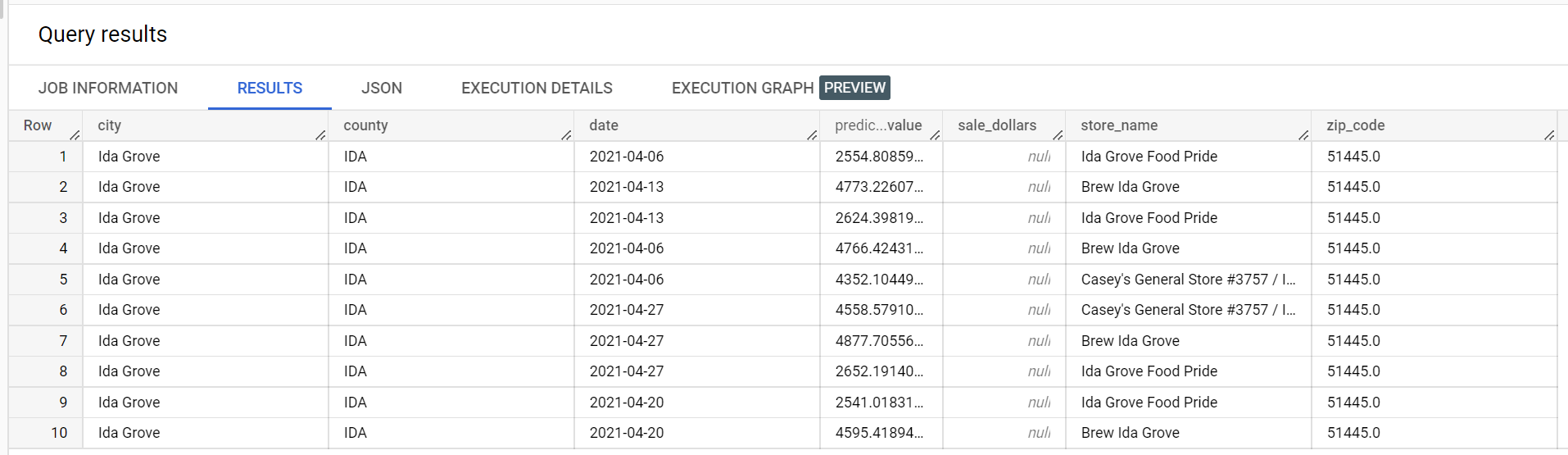
A continuación, se muestra un extracto de los errores de validación:

Ejemplo de salida de inferencia por lotes de un modelo optimizado para la pérdida de cuantiles
En el siguiente ejemplo se muestra el resultado de la inferencia por lotes de un modelo optimizado para la pérdida de cuantiles. En este caso, el modelo de previsión predijo las ventas de los próximos 14 días de cada tienda.
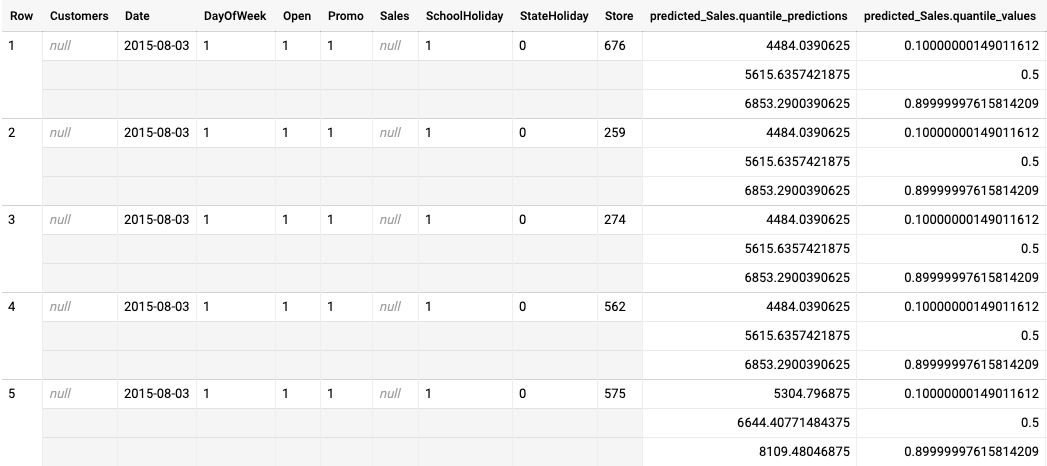
Los valores de los cuantiles se indican en la columna predicted_Sales.quantile_values. En este ejemplo, el modelo ha predicho los valores de los cuantiles 0.1, 0.5 y 0.9.
Los valores de inferencia se indican en la columna predicted_Sales.quantile_predictions.
Se trata de una matriz de valores de ventas que se corresponden con los valores de los cuantiles de la columna predicted_Sales.quantile_values. En la primera fila, vemos que la probabilidad de que el valor de las ventas sea inferior a 4484.04 es del 10%. La probabilidad de que el valor de las ventas sea inferior a 5615.64 es del 50%. La probabilidad de que el valor de las ventas sea inferior a 6853.29 es del 90%. La inferencia de la primera fila, representada como un solo valor, es
5615.64.
Siguientes pasos
- Consulta información sobre los precios de las inferencias por lotes.