Dieses Dokument bietet eine Übersicht über die Pipeline und Komponenten von End-to-End-AutoML. Informationen zum Trainieren eines Modells mit End-to-End-AutoML finden Sie unter Modell mit End-to-End-AutoML trainieren.
Tabellarischer Workflow für End-to-End-AutoML ist eine vollständige AutoML-Pipeline für Klassifizierungs- und Regressionsaufgaben. Sie ähnelt der AutoML API, Sie können jedoch auswählen, was Sie steuern möchten und was automatisiert werden soll. Statt Steuerelemente für die gesamte Pipeline haben Sie Steuerelemente für jeden Schritt in der Pipeline. Folgende Steuerelemente der Pipeline sind verfügbar:
- Datenaufteilung
- Feature Engineering
- Architektursuche
- Modelltraining
- Modellsortierung
- Modelldestillation
Vorteile
Der tabellarische Workflow für End-to-End-AutoML bietet folgende Vorteile:
- Unterstützt große Datasets mit mehreren TB und bis zu 1.000 Spalten.
- Ermöglicht die Verbesserung der Stabilität und niedrigere Trainingszeit, indem der Suchbereich der Architekturtypen begrenzt wird oder die Architektursuche übersprungen wird.
- Ermöglicht die Verbesserung der Trainingsgeschwindigkeit durch manuelle Auswahl der Hardware für das Training und die Architektursuche.
- Ermöglicht die Reduzierung der Modellgröße und die Verbesserung der Latenz mit der Destillation oder durch Ändern der Ensemblegröße.
- Jede AutoML-Komponente kann in einer leistungsstarken Benutzeroberfläche für Pipelinediagramme überprüft werden, auf der Sie die transformierten Datentabellen, bewerteten Modellarchitekturen und viele weitere Details sehen können.
- AutoML-Komponenten bieten erweiterte Flexibilität und Transparenz. So können Sie beispielsweise Parameter anpassen, Hardware auswählen, den Prozessstatus und Logs aufrufen und vieles mehr.
End-to-End-AutoML in Vertex AI Pipelines
Der tabellarische Workflow für End-to-End-AutoML ist eine verwaltete Instanz von Vertex AI Pipelines.
Vertex AI Pipelines ist ein serverloser Dienst, der Kubeflow-Pipelines ausführt. Mithilfe von Pipelines können Sie Ihre Aufgaben für maschinelles Lernen und die Datenvorbereitung automatisieren und überwachen. Jeder Schritt in einer Pipeline führt einen Teil des Workflows der Pipeline aus. Eine Pipeline kann beispielsweise Schritte zum Aufteilen von Daten, zum Transformieren von Datentypen und zum Trainieren eines Modells enthalten. Da Schritte Instanzen von Pipeline-Komponenten sind, haben Schritte Eingaben, Ausgaben und ein Container-Image. Schritteingaben können aus den Eingaben der Pipeline festgelegt werden oder von der Ausgabe anderer Schritte in dieser Pipeline abhängen. Diese Abhängigkeiten definieren den Workflow der Pipeline als gerichtetes azyklisches Diagramm.
Pipeline und Komponenten – Übersicht
Das folgende Diagramm zeigt die Modellierungspipeline für den tabellarischen Workflow für End-to-End-AutoML:

Es gibt folgende Pipelinekomponenten:
- feature-transform-engine: Führt Feature Engineering durch. Weitere Informationen finden Sie unter Feature Transform Engine.
- split-materialized-data:
Materialisierte Daten in ein Trainings-Dataset, ein Bewertungs-Dataset und ein Test-Dataset aufteilen.
Eingabe:
- Materialisierte Daten
materialized_data.
Ausgabe:
- Materialisierte Trainingsaufteilung
materialized_train_split. - Materialisierte Bewertungsaufteilung
materialized_eval_split. - Materialisiertes Test-Dataset
materialized_test_split.
- Materialisierte Daten
- merge-materialized-splits: Die materialisierte Bewertungsaufteilung und die materialisierte Trainingsaufteilung werden zusammengeführt.
automl-tabular-stage-1-tuner: Führt eine Modellarchitektursuche durch und stimmt Hyperparameter ab.
- Eine Architektur wird durch eine Reihe von Hyperparametern definiert.
- Hyperparameter enthalten den Modelltyp und die Modellparameter.
- Modelltypen sind neuronale Netzwerke und Boosted Trees.
- Das System trainiert ein Modell für jede berücksichtigte Architektur.
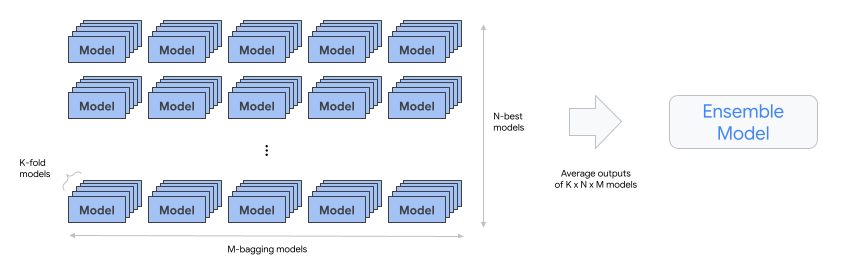
automl-tabular-cv-trainer: Architekturen durch Trainieren von Modellen an verschiedenen Stellen der Eingabedaten kreuzvalidieren.
- Es werden diejenigen Architekturen berücksichtigt, die die besten Ergebnisse im vorherigen Schritt lieferten.
- Das System wählt etwa zehn beste Architekturen aus. Die genaue Anzahl wird durch das Trainingsbudget definiert.
automl-tabular-ensemble: Die besten Architekturen zum Erzeugen eines endgültigen Modells zusammensetzen.
- Das folgende Diagramm veranschaulicht die K-Fold-Kreuzvalidierung mit Bagging:
condition-is-distill: Optional. Erstellt eine kleinere Version des Ensemble-Modells.
- Ein kleineres Modell reduziert die Latenz und die Kosten für die Inferenz.
automl-tabular-infra-validator: Validiert, ob das trainierte Modell ein gültiges Modell ist.
model-upload: Das Modell wird hochgeladen.
condition-is-evaluation – Optional. Verwendet das Test-Dataset, um Bewertungsmesswerte zu berechnen.