Dokumen ini memberikan ringkasan pipeline dan komponen AutoML End-to-End. Untuk mempelajari cara melatih model dengan AutoML End-to-End, lihat Melatih model dengan AutoML End-to-End.
Alur Kerja Tabular untuk AutoML End-to-End adalah pipeline AutoML lengkap untuk tugas klasifikasi dan regresi. Hal ini mirip dengan AutoML API, tetapi memungkinkan Anda memilih apa yang akan dikontrol dan diotomatisasi. Alih-alih memiliki kontrol untuk seluruh pipeline, Anda memiliki kontrol untuk setiap langkah di pipeline. Kontrol pipeline ini mencakup:
- Pemisahan data
- Rekayasa fitur
- Penelusuran arsitektur
- Pelatihan model
- Ansambel model
- Distilasi model
Manfaat
Berikut ini beberapa manfaat Tabular Workflow untuk AutoML End-to-End :
- Mendukung set data besar berukuran beberapa TB dan memiliki hingga 1.000 kolom.
- Memungkinkan Anda meningkatkan stabilitas dan menurunkan waktu pelatihan dengan membatasi ruang penelusuran jenis arsitektur atau melewati penelusuran arsitektur.
- Memungkinkan Anda meningkatkan kecepatan pelatihan dengan memilih secara manual hardware yang digunakan untuk penelusuran arsitektur dan pelatihan.
- Memungkinkan Anda mengurangi ukuran model dan meningkatkan latensi dengan distilasi atau dengan mengubah ukuran ansambel.
- Setiap komponen AutoML dapat diperiksa dengan antarmuka grafik pipeline andal yang memungkinkan Anda melihat tabel data yang ditransformasi, arsitektur model yang dievaluasi, dan banyak detail lainnya.
- Setiap komponen AutoML mendapatkan fleksibilitas dan transparansi yang lebih luas, seperti kemampuan untuk menyesuaikan parameter, hardware, status proses tampilan, log, dan lain-lain.
AutoML End-to-End di Vertex AI Pipelines
Alur Kerja Tabular untuk AutoML End-to-End adalah instance terkelola dari Vertex AI Pipelines.
Vertex AI Pipelines adalah layanan serverless yang menjalankan pipeline Kubeflow. Anda dapat menggunakan pipeline untuk mengotomatisasi dan memantau machine learning serta tugas penyiapan data Anda. Setiap langkah di pipeline menjalankan bagian dari alur kerja pipeline. Misalnya, pipeline dapat mencakup langkah-langkah untuk memisahkan data, mengubah jenis data, dan melatih model. Karena langkah tersebut adalah instance komponen pipeline, langkah memiliki input, output, dan image container. Input langkah dapat ditetapkan dari input pipeline atau dapat bergantung pada output langkah lain dalam pipeline ini. Dependensi ini menentukan alur kerja pipeline sebagai directed acyclic graph.
Ringkasan pipeline dan komponen
Diagram berikut menunjukkan pipeline pemodelan untuk Tabular Workflow untuk AutoML End-to-End :

Komponen pipeline adalah:
- feature-transform-engine: Melakukan rekayasa fitur. Lihat Feature Transform Engine untuk mengetahui detailnya.
- split-materialized-data:
Memisahkan data terwujud ke dalam set pelatihan, set evaluasi, dan set pengujian.
Input:
- Data terwujud
materialized_data.
Output:
- Pemisahan pelatihan terwujud
materialized_train_split. - Pemisahan evaluasi terwujud
materialized_eval_split. - Set pengujian terwujud
materialized_test_split.
- Data terwujud
- merge-materialized-splits - Menggabungkan pemisahan evaluasi terwujud dan pemisahan pelatihan terwujud.
automl-tabular-stage-1-tuner - Melakukan penelusuran arsitektur model dan menyesuaikan hyperparameter.
- Arsitektur ditentukan oleh sekumpulan hyperparameter.
- Hyperparameter mencakup jenis model dan parameter model.
- Jenis model yang dipertimbangkan adalah jaringan neural dan hierarki yang ditingkatkan.
- Sistem melatih model untuk setiap arsitektur yang dipertimbangkan.
automl-tabular-cv-trainer - Arsitektur validasi silang dengan melatih model di berbagai batas tampilan data input.
- Arsitektur yang dipertimbangkan adalah arsitektur yang memberikan hasil terbaik pada langkah sebelumnya.
- Sistem memilih sekitar sepuluh arsitektur terbaik. Jumlah persis ditentukan oleh anggaran pelatihan.
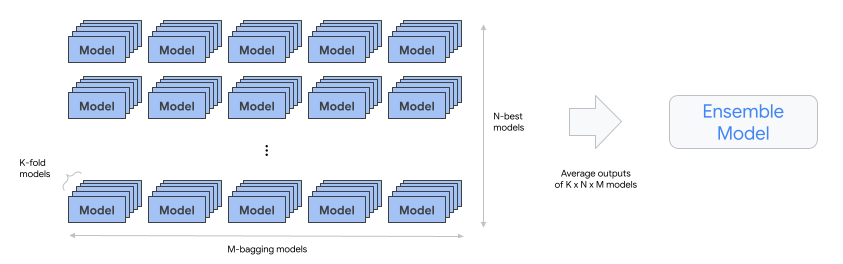
automl-tabular-ensemble - Menggabungkan arsitektur terbaik untuk menghasilkan model akhir.
- Diagram berikut mengilustrasikan validasi silang K-fold dengan bagging:
condition-is-distill - Opsional. Membuat versi model ansambel yang lebih kecil.
- Model yang lebih kecil mengurangi latensi dan biaya untuk inferensi.
automl-tabular-infra-validator - Memvalidasi apakah model yang dilatih adalah model yang valid.
model-upload - Mengupload model.
condition-is-evaluasi - Opsional. Menggunakan set pengujian untuk menghitung metrik evaluasi.