Ce document présente le pipeline et les composants AutoML de bout en bout. Pour apprendre à entraîner un modèle avec AutoML de bout en bout, consultez la section Entraîner un modèle avec AutoML de bout en bout.
Le workflow tabulaire pour AutoML de bout en bout est le pipeline AutoML complet pour les tâches de classification et de régression. Il est semblable à l'API AutoML, mais vous permet de choisir les éléments à contrôler et les éléments à automatiser. Au lieu de disposer de contrôles pour la totalité du pipeline, vous disposez de contrôles pour chaque étape du pipeline. Ces contrôles du pipeline incluent les éléments suivants :
- Division des données
- Ingénierie des caractéristiques
- Recherche d'architecture
- Entraînement du modèle
- Assemblage du modèle
- Distillation du modèle
Avantages
Voici quelques-uns des avantages du workflow tabulaire pour AutoML de bout en bout :
- Il accepte les ensembles de données volumineux de plusieurs To et comportant jusqu'à 1 000 colonnes.
- Il permet d'améliorer la stabilité et de réduire le temps d'entraînement en limitant l'espace de recherche des types d'architecture ou en ignorant la recherche d'architecture.
- Il permet d'améliorer la vitesse d'entraînement en sélectionnant manuellement le matériel utilisé pour l'entraînement et la recherche d'architecture.
- Il permet de réduire la taille du modèle et d'améliorer la latence avec la distillation ou en modifiant la taille de l'ensemble.
- Chaque composant AutoML peut être inspecté dans une interface graphique de pipelines puissante qui vous permet de voir les tables de données transformées, les architectures de modèle évaluées et bien d'autres détails.
- Chaque composant AutoML offre une flexibilité et une transparence accrues, telles que la possibilité de personnaliser les paramètres et le matériel, d'afficher l'état des processus et les journaux, etc.
AutoML de bout en bout sur Vertex AI Pipelines
Le workflow tabulaire pour AutoML de bout en bout est une instance gérée de Vertex AI Pipelines.
Vertex AI Pipelines est un service sans serveur qui exécute des pipelines Kubeflow. Vous pouvez utiliser des pipelines pour automatiser et surveiller vos tâches de machine learning et de préparation des données. Chaque étape d'un pipeline effectue une partie du workflow du pipeline. Par exemple, un pipeline peut inclure des étapes permettant de diviser les données, de transformer les types de données et d'entraîner un modèle. Comme les étapes sont des instances de composants du pipeline, elles comportent des entrées, des sorties et une image de conteneur. Les entrées d'étape peuvent être définies à partir des entrées du pipeline ou elles peuvent dépendre de la sortie d'autres étapes dans ce pipeline. Ces dépendances définissent le workflow du pipeline en tant que graphe orienté acyclique.
Présentation du pipeline et des composants
Le diagramme suivant illustre le pipeline de modélisation du workflow tabulaire pour AutoML de bout en bout :

Les composants du pipeline sont les suivants :
- feature-transform-engine : effectue extraction de caractéristiques. Pour en savoir plus, consultez la page Feature Transform Engine.
- split-materialized-data : divise les données matérialisées en un ensemble d'entraînement, un ensemble d'évaluation et un ensemble de test.
Entrée :
- Données matérialisées (
materialized_data).
Sortie :
- Division d'entraînement matérialisée (
materialized_train_split). - Division d'évaluation matérialisée (
materialized_eval_split). - Ensemble de test matérialisé (
materialized_test_split).
- Données matérialisées (
- merge-materialized-splits : fusionne la division d'évaluation matérialisée et la division d'entraînement matérialisée.
automl-tabular-stage-1-tuner : effectue une recherche de l'architecture du modèle et ajuste les hyperparamètres.
- Une architecture est définie par un ensemble d'hyperparamètres.
- Les hyperparamètres incluent le type de modèle et les paramètres du modèle.
- Les types de modèles pris en compte sont les réseaux de neurones et les arbres de décision à boosting.
- Le système entraîne un modèle pour chaque architecture prise en compte.
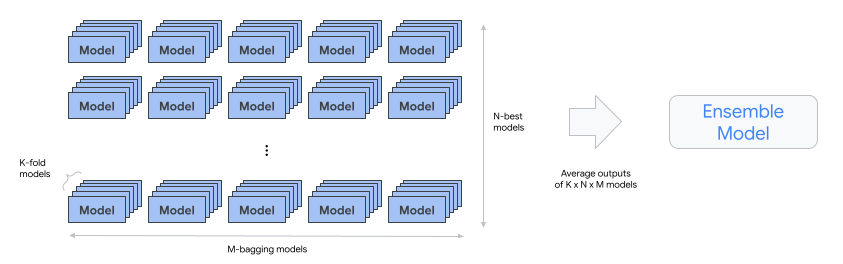
automl-tabular-cv-trainer : effectue une validation croisée des architectures en entraînant les modèles sur les différents sous-ensembles des données d'entrée.
- Les architectures considérées sont celles qui ont donné les meilleurs résultats à l'étape précédente.
- Le système sélectionne environ les dix meilleures architectures. Le nombre précis est défini par le budget d'entraînement.
automl-tabular-ensemble : assemble les meilleures architectures pour produire un modèle final.
- Le diagramme suivant illustre la validation croisée à k blocs avec bagging :
condition-is-distill - Facultatif : crée une version plus petite du modèle d'ensemble.
- Un modèle plus petit réduit la latence et les coûts liés à l'inférence.
automl-tabular-infra-validator : vérifie si le modèle entraîné est un modèle valide.
model-upload : importe le modèle.
condition-is-evaluation - Facultatif : utilise l'ensemble de test pour calculer les métriques d'évaluation.