En este documento se ofrece una descripción general del proceso y los componentes de AutoML de extremo a extremo. Para saber cómo entrenar un modelo con AutoML de principio a fin, consulta Entrenar un modelo con AutoML de principio a fin.
El flujo de trabajo tabular de AutoML integral es una canalización de AutoML completa para tareas de clasificación y regresión. Es similar a la API AutoML, pero te permite elegir qué quieres controlar y qué quieres automatizar. En lugar de tener controles para toda la canalización, tienes controles para cada paso de la canalización. Estos controles de la canalización incluyen lo siguiente:
- División de datos
- Ingeniería de funciones
- Búsqueda de arquitectura
- Preparación de modelos
- Ensamblado de modelos
- Destilación de modelos
Ventajas
A continuación, se enumeran algunas de las ventajas de Tabular Workflow for End-to-End AutoML :
- Admite conjuntos de datos de gran tamaño de varios terabytes y hasta 1000 columnas.
- Te permite mejorar la estabilidad y reducir el tiempo de entrenamiento limitando el espacio de búsqueda de tipos de arquitectura u omitiendo la búsqueda de arquitectura.
- Te permite mejorar la velocidad de entrenamiento seleccionando manualmente el hardware que se va a usar para el entrenamiento y la búsqueda de arquitectura.
- Te permite reducir el tamaño del modelo y mejorar la latencia con la destilación o cambiando el tamaño del conjunto.
- Cada componente de AutoML se puede inspeccionar en una interfaz de gráfico de canalizaciones potente que te permite ver las tablas de datos transformadas, las arquitecturas de modelos evaluadas y muchos más detalles.
- Cada componente de AutoML obtiene más flexibilidad y transparencia, como la posibilidad de personalizar parámetros y hardware, ver el estado del proceso y los registros, entre otras opciones.
AutoML de extremo a extremo en Vertex AI Pipelines
Tabular Workflow for End-to-End AutoML es una instancia gestionada de Vertex AI Pipelines.
Vertex AI Pipelines es un servicio sin servidor que ejecuta flujos de procesamiento de Kubeflow. Puedes usar las pipelines para automatizar y monitorizar tus tareas de aprendizaje automático y preparación de datos. Cada paso de una pipeline realiza una parte del flujo de trabajo de la canalización. Por ejemplo, una canalización puede incluir pasos para dividir datos, transformar tipos de datos y entrenar un modelo. Como los pasos son instancias de componentes de flujo de trabajo, tienen entradas, salidas y una imagen de contenedor. Las entradas de los pasos se pueden definir a partir de las entradas de la canalización o pueden depender de la salida de otros pasos de la canalización. Estas dependencias definen el flujo de trabajo de la canalización como un grafo acíclico dirigido.
Descripción general de los flujos de procesamiento y los componentes
En el siguiente diagrama se muestra el flujo de procesamiento de modelado de Tabular Workflow for End-to-End AutoML :

Los componentes de la canalización son los siguientes:
- feature-transform-engine: realiza la ingeniería de funciones. Para obtener más información, consulta Feature Transform Engine.
- split-materialized-data:
divide los datos materializados en un conjunto de entrenamiento, un conjunto de evaluación y un conjunto de prueba.
Objetivo:
- Datos materializados
materialized_data.
Resultado:
- División de entrenamiento materializada
materialized_train_split. - División de la evaluación materializada
materialized_eval_split. - Conjunto de pruebas materializado
materialized_test_split.
- Datos materializados
- merge-materialized-splits: combina la división de evaluación materializada y la división de entrenamiento materializada.
automl-tabular-stage-1-tuner realiza una búsqueda de la arquitectura del modelo y ajusta los hiperparámetros.
- Una arquitectura se define mediante un conjunto de hiperparámetros.
- Los hiperparámetros incluyen el tipo de modelo y los parámetros del modelo.
- Los tipos de modelos que se tienen en cuenta son las redes neuronales y los árboles de refuerzo.
- El sistema entrena un modelo para cada arquitectura considerada.
automl-tabular-cv-trainer valida las arquitecturas de forma cruzada entrenando modelos con diferentes particiones de los datos de entrada.
- Las arquitecturas que se tienen en cuenta son las que dan los mejores resultados en el paso anterior.
- El sistema selecciona aproximadamente diez de las mejores arquitecturas. El número exacto se define en el presupuesto de formación.
automl-tabular-ensemble: combina las mejores arquitecturas para generar un modelo final.
- En el siguiente diagrama se muestra la validación cruzada de K-fold con bagging:
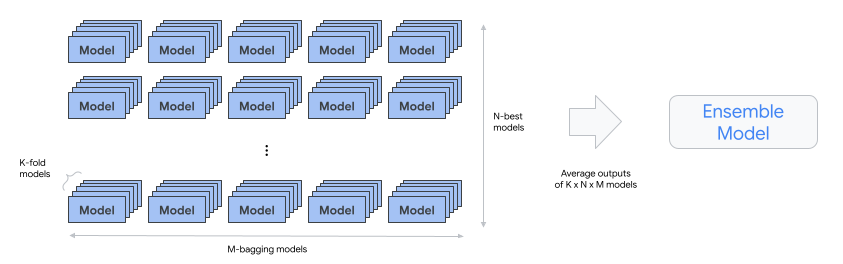
condition-is-distill: opcional. Crea una versión más pequeña del modelo de conjunto.
- Un modelo más pequeño reduce la latencia y el coste de la inferencia.
automl-tabular-infra-validator valida si el modelo entrenado es válido.
model-upload: sube el modelo.
condition-is-evaluation: opcional. Usa el conjunto de prueba para calcular las métricas de evaluación.