本文將概述端對端 AutoML pipeline 和元件。如要瞭解如何使用 End-to-End AutoML 訓練模型,請參閱「使用 End-to-End AutoML 訓練模型」。
端對端 AutoML 的表格工作流程是完整的 AutoML 管道,適用於分類和迴歸工作。這項 API 與 AutoML API 類似,但可讓您選擇要控制及自動執行的項目。您不必控管整個管道,而是控管管道中的每個步驟。這些管道控制項包括:
- 資料分割
- 特徵工程
- 架構搜尋
- 模型訓練
- 模型組合
- 模型蒸餾
優點
以下列舉一些「端對端 AutoML 的表格工作流程」優點:
- 支援大小達數 TB 且最多有 1,000 欄的大型資料集。
- 您可以限制架構類型搜尋空間或略過架構搜尋,提升穩定性並縮短訓練時間。
- 手動選取用於訓練和架構搜尋的硬體,提升訓練速度。
- 您可以透過蒸餾或變更模型組合大小,縮減模型大小並改善延遲時間。
- 您可以在功能強大的管道圖表介面中檢查每個 AutoML 元件,查看轉換後的資料表、評估的模型架構,以及更多詳細資料。
- 每個 AutoML 元件都具備更高的彈性和透明度,例如可自訂參數和硬體、查看程序狀態和記錄等。
Vertex AI Pipelines 的端對端 AutoML
端對端 AutoML 的表格工作流程是 Vertex AI Pipelines 的代管執行個體。
Vertex AI Pipelines 是一項無伺服器服務,可執行 Kubeflow 管道。您可以使用管道自動執行及監控機器學習和資料準備工作。管道中的每個步驟都會執行管道工作流程的一部分。舉例來說,管道可以包含分割資料、轉換資料類型及訓練模型的步驟。由於步驟是管道元件的例項,因此步驟具有輸入內容、輸出內容和容器映像檔。步驟輸入內容可以從管道的輸入內容設定,也可以取決於這個管道中其他步驟的輸出內容。這些依附元件會將管道的工作流程定義為有向非循環圖。
管道和元件總覽
下圖顯示端對端 AutoML 的表格工作流程模型化管道:

管道元件如下:
- feature-transform-engine:執行特徵工程。詳情請參閱「特徵轉換引擎」。
- split-materialized-data:
將具體化資料分割為訓練集、評估集和測試集。
輸入:
- 具體化資料
materialized_data。
輸出:
- 具體化的訓練分割
materialized_train_split。 - 具體化評估分割
materialized_eval_split。 - 具體化測試集
materialized_test_split。
- 具體化資料
- merge-materialized-splits - 合併具體化評估分割和具體化訓練分割。
automl-tabular-stage-1-tuner:執行模型架構搜尋及調整超參數。
- 架構是由一組超參數定義。
- 超參數包括模型類型和模型參數。
- 我們考量的模型類型為類神經網路和強化型樹狀結構。
- 系統會針對每個考量的架構訓練模型。
automl-tabular-cv-trainer:在輸入資料的不同摺疊上訓練模型,以交叉驗證架構。
- 我們會考慮在上一個步驟中獲得最佳結果的架構。
- 系統會選取約十個最佳架構。確切的數量取決於訓練預算。
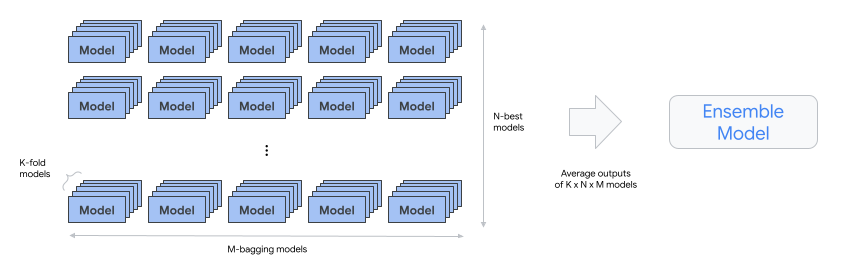
automl-tabular-ensemble - 整合最佳架構,產生最終模型。
- 下圖說明使用 Bagging 的 K 折交叉驗證:
condition-is-distill - 選填。建立較小的模型組合版本。
- 較小的模型可縮短延遲時間,並降低推論成本。
automl-tabular-infra-validator - 驗證訓練好的模型是否為有效模型。
model-upload - 上傳模型。
condition-is-evaluation - 選填。使用測試集計算評估指標。