이 페이지에서는 학습된 예측 모델을 사용하여 예측을 만드는 방법을 보여줍니다.
예측을 만들려면 입력 소스와 예측 결과를 저장할 출력 위치를 지정하여 예측 모델에 직접 일괄 예측 요청을 수행합니다.
AutoML을 통한 예측은 엔드포인트 배포나 온라인 예측과 호환되지 않습니다. 예측 모델에서 온라인 예측을 요청하려면 예측을 위한 테이블 형식 워크플로를 사용하세요.
설명(특성 기여 분석이라고도 함)이 포함된 예측을 요청하여 모델이 예측에 어떻게 도착했는지 확인할 수 있습니다. 로컬 특성 중요도 값은 각 특성이 예측 결과에 얼마나 기여했는지 나타냅니다. 개념 개요는 예측용 특성 기여 분석을 참조하세요.
시작하기 전에
예측을 만들려면 먼저 예측 모델을 학습시켜야 합니다.
입력 데이터
일괄 예측 요청의 입력 데이터는 모델이 예측을 만드는 데 사용하는 데이터입니다. 다음 두 가지 형식 중 하나로 입력 데이터를 제공할 수 있습니다.
- Cloud Storage의 CSV 객체
- BigQuery 테이블
모델 학습에 사용한 형식과 동일한 형식을 입력 데이터에 사용하는 것이 좋습니다. 예를 들어 BigQuery에서 데이터를 사용하여 모델을 학습시켰으면 BigQuery 테이블을 일괄 예측의 입력으로 사용하는 것이 가장 좋습니다. Vertex AI는 모든 CSV 입력 필드를 문자열로 취급하므로 학습 데이터와 입력 데이터 형식을 혼합하면 오류가 발생할 수 있습니다.
데이터 소스에는 모델 학습에 사용된 모든 열을 어떤 순서대로든 포함하는 테이블 형식 데이터가 있어야 합니다. 학습 데이터에 없거나, 학습 데이터에는 있지만 학습에 사용할 수 없는 열을 포함할 수 있습니다. 이러한 추가 열은 출력에 포함되지만 예측 결과에는 영향을 미치지 않습니다.
입력 데이터 요구사항
예측 모델의 입력은 다음 요구사항을 준수해야 합니다.
- 시간 열의 모든 값이 있고 유효해야 합니다.
- 입력 데이터 및 학습 데이터의 데이터 빈도는 일치해야 합니다. 시계열에 누락된 행이 있는 경우 적절한 도메인 지식에 따라 수동으로 행을 삽입해야 합니다.
- 타임스탬프가 중복된 시계열은 예측에서 삭제됩니다. 이러한 시계열을 포함하려면 중복 타임스탬프를 삭제하세요.
- 예측할 각 시계열의 이전 데이터를 제공합니다. 가장 정확한 예측을 얻으려면 데이터 양이 모델 학습 중에 설정된 컨텍스트 윈도우와 동일해야 합니다. 예를 들어 컨텍스트 윈도우가 14일인 경우 최소 14일 이전의 데이터를 제공합니다. 데이터를 더 적게 제공하면 Vertex AI에서 값이 비어 있는 데이터를 패딩합니다.
- 예측은 대상 열의 null 값이 있는 시계열의 첫 번째 행(시간순)에서 시작합니다. null 값은 시계열 내에서 연속적이어야 합니다. 예를 들어 타겟 열을 시간순으로 정렬하는 경우 단일 시계열에
1,2,null,3,4,null,null과 같이 정렬할 수 없습니다. CSV 파일의 경우 Vertex AI가 빈 문자열을 null로 취급하며 BigQuery의 경우 기본적으로 null 값이 지원됩니다.
BigQuery 테이블
BigQuery 테이블을 입력으로 선택하는 경우 다음을 확인해야 합니다.
- BigQuery 데이터 소스 테이블은 100GB를 넘지 않아야 합니다.
- 테이블이 다른 프로젝트에 있으면 해당 프로젝트의 Vertex AI 서비스 계정에
BigQuery Data Editor역할을 부여해야 합니다.
CSV 파일
Cloud Storage에서 입력으로 CSV 객체를 선택할 경우 다음 사항을 확인해야 합니다.
- 데이터 소스는 열 이름이 있는 헤더 행으로 시작해야 합니다.
- 각 데이터 소스 객체는 10GB를 넘지 않아야 합니다. 여러 파일을 포함할 수도 있지만 최대 용량은 100GB로 제한됩니다.
- Cloud Storage 버킷이 다른 프로젝트에 있으면 해당 프로젝트의 Vertex AI 서비스 계정에
Storage Object Creator역할을 부여해야 합니다. - 모든 문자열을 큰따옴표(")로 묶어야 합니다.
출력 형식
일괄 예측 요청의 출력 형식은 입력에 사용한 형식과 동일할 필요가 없습니다. 예를 들어 BigQuery 테이블을 입력으로 사용한 경우 Cloud Storage의 CSV 객체로 예측 결과를 출력할 수 있습니다.
모델에 일괄 예측 요청 보내기
일괄 예측 요청을 수행하려면 Google Cloud 콘솔 또는 Vertex AI API를 사용하면 됩니다. 입력 데이터 소스는 Cloud Storage 버킷이나 BigQuery 테이블에 저장된 CSV 객체일 수 있습니다. 입력으로 제출하는 데이터 양에 따라 일괄 예측 태스크가 완료되는 데 다소 시간이 걸릴 수 있습니다.
Google Cloud 콘솔
Google Cloud 콘솔을 사용하여 일괄 예측을 요청합니다.
- Google Cloud 콘솔의 Vertex AI 섹션에서 일괄 예측 페이지로 이동합니다.
- 만들기를 클릭하여 새 일괄 예측 창을 엽니다.
- 일괄 예측 정의에서 다음 단계를 완료합니다.
- 일괄 예측의 이름을 입력합니다.
- 모델 이름에 이 일괄 예측에 사용할 모델의 이름을 선택합니다.
- 버전에서 모델 버전을 선택합니다.
- 소스 선택에서 소스 입력 데이터가 Cloud Storage의 CSV 파일인지 또는 BigQuery의 테이블인지 여부를 선택합니다.
- CSV 파일의 경우 CSV 입력 파일이 있는 Cloud Storage 위치를 지정합니다.
- BigQuery 테이블의 경우 테이블이 있는 프로젝트 ID, BigQuery 데이터 세트 ID, BigQuery 테이블 또는 뷰 ID를 지정합니다.
- 일괄 예측 출력에 CSV 또는 BigQuery를 선택합니다.
- CSV의 경우 Vertex AI에서 출력을 저장하는 Cloud Storage 버킷을 지정합니다.
- BigQuery의 경우 프로젝트 ID 또는 기존 데이터 세트를 지정할 수 있습니다.
- 프로젝트 ID를 지정하려면 Google Cloud 프로젝트 ID 필드에 프로젝트 ID를 입력합니다. Vertex AI에서 새로운 출력 데이터 세트를 자동으로 만듭니다.
- 기존 데이터 세트를 지정하려면 Google Cloud 프로젝트 ID 필드에 BigQuery 경로를 입력합니다(예:
bq://projectid.datasetid).
- 선택사항. 출력 대상이 Cloud Storage의 BigQuery 또는 JSONL이면 예측 외에 특성 기여 분석을 사용 설정할 수 있습니다. 이렇게 하려면 이 모델의 특성 기여 분석 사용 설정을 선택합니다. Cloud Storage의 CSV에는 특성 기여 분석이 지원되지 않습니다. 자세히 알아보기
- 선택사항: 일괄 예측을 위한 모델 모니터링 분석은 미리보기로 제공됩니다. 일괄 예측 작업에 편향 감지 구성을 추가하는 방법은 기본 요건을 참조하세요.
- 이 일괄 예측에 모델 모니터링 사용 설정을 클릭하여 켜거나 끕니다.
- 학습 데이터 소스를 선택합니다. 선택한 학습 데이터 소스의 데이터 경로 또는 위치를 입력합니다.
- 선택사항: 알림 기준 아래에서 알림을 트리거할 임곗값을 지정합니다.
- 알림 이메일의 경우 모델이 알림 기준을 초과하면 알림을 받을 이메일 주소 하나 이상을 쉼표로 구분하여 입력합니다.
- 선택사항: 알림 채널의 경우 모델이 알림 기준을 초과하면 알림을 받을 Cloud Monitoring 채널을 추가합니다. 기존 Cloud Monitoring 채널을 선택하거나 알림 채널 관리를 클릭하여 새 채널을 만들 수 있습니다. 콘솔에서는 PagerDuty, Slack, Pub/Sub 알림 채널을 지원합니다.
- 만들기를 클릭합니다.
API : BigQuery
REST
batchPredictionJobs.create 메서드를 사용해 일괄 예측을 요청합니다.
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- LOCATION_ID: 모델이 저장되고 일괄 예측 작업이 실행되는 리전입니다. 예를 들면
us-central1입니다. - PROJECT_ID: 프로젝트 ID입니다.
- BATCH_JOB_NAME: 일괄 작업의 표시 이름입니다.
- MODEL_ID: 예측을 수행하는 데 사용할 모델의 ID입니다.
-
INPUT_URI: BigQuery 데이터 소스에 대한 참조입니다. 다음 안내를 따라 양식을 작성하세요.
bq://bqprojectId.bqDatasetId.bqTableId
-
OUTPUT_URI: 예측이 기록되는 BigQuery 대상에 대한 참조입니다. 프로젝트 ID를 지정하고 선택적으로 기존 데이터 세트 ID를 지정합니다. 다음 형식을 사용합니다.
bq://bqprojectId.bqDatasetId
bq://bqprojectId
- GENERATE_EXPLANATION: 기본값은 false입니다. 특성 기여 분석을 사용 설정하려면 true로 설정합니다. 자세한 내용은 예측용 특성 기여 분석을 참조하세요.
HTTP 메서드 및 URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs
JSON 요청 본문:
{
"displayName": "BATCH_JOB_NAME",
"model": "projects/PROJECT_ID/locations/LOCATION_ID/models/MODEL_ID",
"inputConfig": {
"instancesFormat": "bigquery",
"bigquerySource": {
"inputUri": "INPUT_URI"
}
},
"outputConfig": {
"predictionsFormat": "bigquery",
"bigqueryDestination": {
"outputUri": "OUTPUT_URI"
}
},
"generate_explanation": GENERATE_EXPLANATION
}
요청을 보내려면 다음 옵션 중 하나를 선택합니다.
curl
요청 본문을 request.json 파일에 저장하고 다음 명령어를 실행합니다.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs"
PowerShell
요청 본문을 request.json 파일에 저장하고 다음 명령어를 실행합니다.
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs" | Select-Object -Expand Content
다음과 비슷한 JSON 응답이 표시됩니다.
{
"name": "projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs/67890",
"displayName": "batch_job_1 202005291958",
"model": "projects/12345/locations/us-central1/models/5678",
"state": "JOB_STATE_PENDING",
"inputConfig": {
"instancesFormat": "bigquery",
"bigquerySource": {
"inputUri": "INPUT_URI"
}
},
"outputConfig": {
"predictionsFormat": "bigquery",
"bigqueryDestination": {
"outputUri": bq://12345
}
},
"dedicatedResources": {
"machineSpec": {
"machineType": "n1-standard-32",
"acceleratorCount": "0"
},
"startingReplicaCount": 2,
"maxReplicaCount": 6
},
"manualBatchTuningParameters": {
"batchSize": 4
},
"outputInfo": {
"bigqueryOutputDataset": "bq://12345.reg_model_2020_10_02_06_04
}
"state": "JOB_STATE_PENDING",
"createTime": "2020-09-30T02:58:44.341643Z",
"updateTime": "2020-09-30T02:58:44.341643Z",
}
Java
이 샘플을 사용해 보기 전에 Vertex AI 빠른 시작: 클라이언트 라이브러리 사용의 Java 설정 안내를 따르세요. 자세한 내용은 Vertex AI Java API 참고 문서를 참조하세요.
Vertex AI에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
다음 샘플에서 INSTANCES_FORMAT 및 PREDICTIONS_FORMAT을 `bigquery`로 바꿉니다. 다른 자리표시자를 교체하는 방법을 알아보려면 이 섹션의 `REST & CMD LINE` 탭을 참조하세요.Vertex AI SDK for Python
Vertex AI SDK for Python을 설치하거나 업데이트하는 방법은 Vertex AI SDK for Python 설치를 참조하세요. 자세한 내용은 Vertex AI SDK for Python API 참조 문서를 확인하세요.
API : Cloud Storage
REST
batchPredictionJobs.create 메서드를 사용해 일괄 예측을 요청합니다.
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- LOCATION_ID: 모델이 저장되고 일괄 예측 작업이 실행되는 리전입니다. 예를 들면
us-central1입니다. - PROJECT_ID: 프로젝트 ID입니다.
- BATCH_JOB_NAME: 일괄 작업의 표시 이름입니다.
- MODEL_ID: 예측을 수행하는 데 사용할 모델의 ID입니다.
-
URI: 학습 데이터가 포함된 Cloud Storage 버킷의 경로(URI)입니다.
두 개 이상 있을 수 있습니다. 각 URI의 형식은 다음과 같습니다.
gs://bucketName/pathToFileName
-
OUTPUT_URI_PREFIX: 예측이 기록되는 Cloud Storage 대상의 경로입니다. Vertex AI에서 이 경로의 타임스탬프가 적용된 하위 디렉터리에 일괄 예측을 기록합니다. 이 값을 다음 형식의 문자열에 설정합니다.
gs://bucketName/pathToOutputDirectory
- GENERATE_EXPLANATION: 기본값은 false입니다. 특성 기여 분석을 사용 설정하려면 true로 설정합니다. 이 옵션은 출력 대상이 JSONL인 경우에만 사용 가능합니다. Cloud Storage의 CSV에서는 특성 기여 분석이 지원되지 않습니다. 자세한 내용은 예측용 특성 기여 분석을 참조하세요.
HTTP 메서드 및 URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs
JSON 요청 본문:
{
"displayName": "BATCH_JOB_NAME",
"model": "projects/PROJECT_ID/locations/LOCATION_ID/models/MODEL_ID",
"inputConfig": {
"instancesFormat": "csv",
"gcsSource": {
"uris": [
URI1,...
]
},
},
"outputConfig": {
"predictionsFormat": "csv",
"gcsDestination": {
"outputUriPrefix": "OUTPUT_URI_PREFIX"
}
},
"generate_explanation": GENERATE_EXPLANATION
}
요청을 보내려면 다음 옵션 중 하나를 선택합니다.
curl
요청 본문을 request.json 파일에 저장하고 다음 명령어를 실행합니다.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs"
PowerShell
요청 본문을 request.json 파일에 저장하고 다음 명령어를 실행합니다.
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs" | Select-Object -Expand Content
다음과 비슷한 JSON 응답이 표시됩니다.
{
"name": "projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs/67890",
"displayName": "batch_job_1 202005291958",
"model": "projects/12345/locations/us-central1/models/5678",
"state": "JOB_STATE_PENDING",
"inputConfig": {
"instancesFormat": "csv",
"gcsSource": {
"uris": [
"gs://bp_bucket/reg_mode_test"
]
}
},
"outputConfig": {
"predictionsFormat": "csv",
"gcsDestination": {
"outputUriPrefix": "OUTPUT_URI_PREFIX"
}
},
"dedicatedResources": {
"machineSpec": {
"machineType": "n1-standard-32",
"acceleratorCount": "0"
},
"startingReplicaCount": 2,
"maxReplicaCount": 6
}
"outputInfo": {
"gcsOutputDataset": "OUTPUT_URI_PREFIX/prediction-batch_job_1 202005291958-2020-09-30T02:58:44.341643Z"
}
"state": "JOB_STATE_PENDING",
"createTime": "2020-09-30T02:58:44.341643Z",
"updateTime": "2020-09-30T02:58:44.341643Z",
}
Vertex AI SDK for Python
Vertex AI SDK for Python을 설치하거나 업데이트하는 방법은 Vertex AI SDK for Python 설치를 참조하세요. 자세한 내용은 Vertex AI SDK for Python API 참조 문서를 확인하세요.
일괄 예측 결과 검색
Vertex AI는 일괄 예측 출력을 지정된 대상(BigQuery 또는 Cloud Storage)으로 전송합니다.
특성 기여 분석을 위한 Cloud Storage 출력은 현재 지원되지 않습니다.
BigQuery
출력 데이터 세트
BigQuery를 사용하는 경우 일괄 예측의 출력은 출력 데이터 세트에 저장됩니다. Vertex AI에 데이터 세트를 제공한 경우 데이터 세트 이름(BQ_DATASET_NAME)은 이전에 제공한 이름입니다. 출력 데이터 세트를 제공하지 않은 경우 Vertex AI가 자동으로 데이터 세트를 생성합니다. 다음 단계에 따라 이름(BQ_DATASET_NAME)을 찾을 수 있습니다.
- Google Cloud 콘솔에서 Vertex AI 일괄 예측 페이지로 이동합니다.
- 생성한 예측을 선택합니다.
-
출력 데이터 세트는 내보내기 위치에 지정됩니다. 데이터 세트 이름은
prediction_MODEL_NAME_TIMESTAMP형식입니다.
출력 테이블
출력 데이터 세트에는 다음 세 가지 출력 테이블 중 하나 이상이 포함됩니다.
-
예측 테이블
이 테이블에는 예측이 요청된 입력 데이터의 모든 행에 대한 행이 포함됩니다(즉, TARGET_COLUMN_NAME = null). 예를 들어 타겟 열에 대한 null 항목 14개(예: 다음 14일 동안의 판매)가 입력에 포함된 경우 예측 요청은 각 날짜의 판매 번호인 14개 행을 반환합니다. 예측 요청이 모델 예측 범위를 초과하면 Vertex AI는 예측 범위까지의 예측만 반환합니다.
-
오류 검증 테이블
이 테이블에는 일괄 예측 전에 발생하는 집계 단계 중에 발생하는 중요하지 않은 오류에 대한 행이 포함됩니다. 중요하지 않은 각 오류는 Vertex AI가 예측을 반환할 수 없는 입력 데이터의 행에 해당합니다.
-
오류 테이블
이 테이블에는 일괄 예측 중에 발생하는 중요하지 않은 오류에 대한 행이 포함됩니다. 중요하지 않은 각 오류는 Vertex AI가 예측을 반환할 수 없는 입력 데이터의 행에 해당합니다.
예측 테이블
테이블의 이름(BQ_PREDICTIONS_TABLE_NAME)은 일괄 예측 작업이 시작된 타임스탬프와 함께 'predictions_'을 추가하여 형성됩니다. predictions_TIMESTAMP
예측 테이블을 검색하려면 다음 안내를 따르세요.
-
콘솔에서 BigQuery 페이지로 이동합니다.
BigQuery로 이동 -
다음 쿼리를 실행합니다.
SELECT * FROM BQ_DATASET_NAME.BQ_PREDICTIONS_TABLE_NAME
Vertex AI는 predicted_TARGET_COLUMN_NAME.value 열에 예측을 저장합니다.
Temporal Fusion Transformer(TFT)로 모델을 학습시킨 경우 predicted_TARGET_COLUMN_NAME.tft_feature_importance 열에서 TFT 해석 가능성 출력을 찾을 수 있습니다.
이 열은 추가로 다음과 같이 분할됩니다.
context_columns: 컨텍스트 윈도우 값이 TFT 장단기 메모리(LSTM) 인코더 입력으로 사용되는 예측 특성입니다.context_weights: 예측 인스턴스의 각context_columns에 연결된 특성 중요도 가중치입니다.horizon_columns: 예측 범위 값이 TFT 장단기 메모리(LSTM) 디코더 입력으로 사용되는 예측 특성입니다.horizon_weights: 예측 인스턴스의 각horizon_columns에 연결된 특성 중요도 가중치입니다.attribute_columns: 시불변인 예측 특성입니다.attribute_weights: 각attribute_columns에 연결된 가중치입니다.
모델이 분위수 손실에 최적화되고 분위수 집합에 중앙값이 포함되어 있으면 predicted_TARGET_COLUMN_NAME.value가 중앙값의 예측 값입니다. 그렇지 않으면 predicted_TARGET_COLUMN_NAME.value가 집합에서 분위수가 가장 낮은 예측 값입니다. 예를 들어 분위수 집합이 [0.1, 0.5, 0.9]면 value가 0.5 분위수의 예측입니다.
분위수 집합이 [0.1, 0.9]면 value가 0.1 분위수의 예측입니다.
또한 Vertex AI는 다음 열에 분위수 값 및 예측을 저장합니다.
-
predicted_TARGET_COLUMN_NAME.quantile_values: 모델 학습 중에 설정된 분위수의 값입니다. 예를 들어0.1,0.5,0.9일 수 있습니다. -
predicted_TARGET_COLUMN_NAME.quantile_predictions: 분위수 값에 연결된 예측 값입니다.
모델에서 확률적 추론을 사용하는 경우 predicted_TARGET_COLUMN_NAME.value에는 최적화 목표의 최소화 도구가 포함됩니다. 예를 들어 최적화 목표가 minimize-rmse면 predicted_TARGET_COLUMN_NAME.value에는 평균값이 포함됩니다. minimize-mae면 predicted_TARGET_COLUMN_NAME.value에 중앙값이 포함됩니다.
모델에서 분위수로 확률적 추론을 사용하는 경우 Vertex AI는 다음 열에 분위수 값과 예측을 저장합니다.
-
predicted_TARGET_COLUMN_NAME.quantile_values: 모델 학습 중에 설정된 분위수의 값입니다. 예를 들어0.1,0.5,0.9일 수 있습니다. -
predicted_TARGET_COLUMN_NAME.quantile_predictions: 분위수 값에 연결된 예측 값입니다.
특성 기여 분석을 사용 설정한 경우 예측 테이블에서도 기여 분석을 찾을 수 있습니다. 특성 BQ_FEATURE_NAME의 기여 분석에 액세스하려면 다음 쿼리를 실행합니다.
SELECT explanation.attributions[OFFSET(0)].featureAttributions.BQ_FEATURE_NAME FROM BQ_DATASET_NAME.BQ_PREDICTIONS_TABLE_NAME
자세한 내용은 예측용 특성 기여 분석을 참조하세요.
오류 검증 테이블
테이블의 이름(BQ_ERRORS_VALIDATION_TABLE_NAME)은 일괄 예측 작업이 시작된 타임스탬프와 함께 'errors_validation'을 추가하여 형성됩니다. errors_validation_TIMESTAMP
-
콘솔에서 BigQuery 페이지로 이동합니다.
BigQuery로 이동 -
다음 쿼리를 실행합니다.
SELECT * FROM BQ_DATASET_NAME.BQ_ERRORS_VALIDATION_TABLE_NAME
- errors_TARGET_COLUMN_NAME
오류 테이블
테이블의 이름(BQ_ERRORS_TABLE_NAME)은 일괄 예측 작업이 시작된 타임스탬프(errors_TIMESTAMP)와 함께 'errors_'를 추가하여 형성됩니다.
-
콘솔에서 BigQuery 페이지로 이동합니다.
BigQuery로 이동 -
다음 쿼리를 실행합니다.
SELECT * FROM BQ_DATASET_NAME.BQ_ERRORS_TABLE_NAME
- error_TARGET_COLUMN_NAME.code
- errors_TARGET_COLUMN_NAME.message
Cloud Storage
Cloud Storage를 출력 대상으로 지정하면 일괄 예측 요청의 결과가 지정한 버킷의 새 폴더에 CSV 객체로 반환됩니다. 폴더 이름은 모델 이름 앞에 'prediction_'과 일괄 예측 작업이 시작된 시점의 타임스탬프를 추가해 지정해야 합니다. 모델의 일괄 예측 탭에서 Cloud Storage 폴더 이름을 확인할 수 있습니다.
Cloud Storage 폴더에는 다음과 같은 두 가지 객체가 있습니다.-
예측 객체
예측 객체의 이름은 'predictions_1.csv', 'predictions_2.csv' 등으로 지정됩니다. 이러한 예측 파일에는 열 이름이 지정된 헤더 행과 반환된 모든 예측에 대한 하나의 행이 포함됩니다. 예측 값 수는 예측 입력 및 예측 범위에 따라 다릅니다. 예를 들어 타겟 열에 대한 null 항목 14개(예: 다음 14일 동안의 판매)가 입력에 포함된 경우 예측 요청은 각 날짜의 판매 번호인 14개 행을 반환합니다. 예측 요청이 모델 예측 범위를 초과하면 Vertex AI는 예측 범위까지의 예측만 반환합니다.
예측 값은 이름이 `predicted_TARGET_COLUMN_NAME`인 열에 반환됩니다. 분위수 예측의 경우 출력 열에는 JSON 형식의 분위수 예측 및 분위수 값이 포함됩니다.
-
오류 객체
오류 객체의 이름은 `errors_1.csv`, `errors_2.csv` 등으로 지정됩니다. 여기에는 헤더 행과 Vertex AI가 예측을 반환하지 못하는 입력 데이터의 모든 행에 대한 하나의 행이 포함됩니다. 예를 들어 null 비허용 특성이 null인 경우입니다
참고: 결과가 크면 여러 객체로 분할됩니다.
BigQuery의 특성 기여 분석 쿼리 샘플
예시 1: 단일 예측에 대한 기여 분석 결정
다음 질문을 생각해 봅시다.
11월 24일 특정 매장의 제품 광고 예측 매출이 얼마나 증가했는가?
해당 쿼리는 다음과 같습니다.
SELECT
* EXCEPT(explanation, predicted_sales),
ROUND(predicted_sales.value, 2) AS predicted_sales,
ROUND(
explanation.attributions[OFFSET(0)].featureAttributions.advertisement,
2
) AS attribution_advertisement
FROM
`project.dataset.predictions`
WHERE
product = 'product_0'
AND store = 'store_0'
AND date = '2019-11-24'
예시 2: 전역 특성 중요도 결정
다음 질문을 생각해 봅시다.
각 기능은 전반적인 예상 판매량에 얼마나 기여했는가?
로컬 특성 중요도 기여 분석을 집계하여 전역 특성 중요도를 수동으로 계산할 수 있습니다. 해당 쿼리는 다음과 같습니다.
WITH
/*
* Aggregate from (id, date) level attributions to global feature importance.
*/
attributions_aggregated AS (
SELECT
SUM(ABS(attributions.featureAttributions.date)) AS date,
SUM(ABS(attributions.featureAttributions.advertisement)) AS advertisement,
SUM(ABS(attributions.featureAttributions.holiday)) AS holiday,
SUM(ABS(attributions.featureAttributions.sales)) AS sales,
SUM(ABS(attributions.featureAttributions.store)) AS store,
SUM(ABS(attributions.featureAttributions.product)) AS product,
FROM
project.dataset.predictions,
UNNEST(explanation.attributions) AS attributions
),
/*
* Calculate the normalization constant for global feature importance.
*/
attributions_aggregated_with_total AS (
SELECT
*,
date + advertisement + holiday + sales + store + product AS total
FROM
attributions_aggregated
)
/*
* Calculate the normalized global feature importance.
*/
SELECT
ROUND(date / total, 2) AS date,
ROUND(advertisement / total, 2) AS advertisement,
ROUND(holiday / total, 2) AS holiday,
ROUND(sales / total, 2) AS sales,
ROUND(store / total, 2) AS store,
ROUND(product / total, 2) AS product,
FROM
attributions_aggregated_with_total
BigQuery의 일괄 예측 출력 예시
주류 판매의 예시 데이터 세트에서 'Ida Grove' 도시에는 4개의 매장('Ida Grove Food Pride', 'Discount Liquors of Ida Grove', 'Casey's General Store #3757', 'Brew Ida Grove')이 있습니다. store_name은 series identifier이며 4개의 매장 중 3개는 대상 열 sale_dollars에 대한 예측을 요청합니다. 'Discount Liquors of Ida Grove'에 대한 예측이 요청되지 않았으므로 검증 오류가 발생합니다.
다음은 예측에 사용되는 입력 데이터 세트에서 추출한 것입니다.
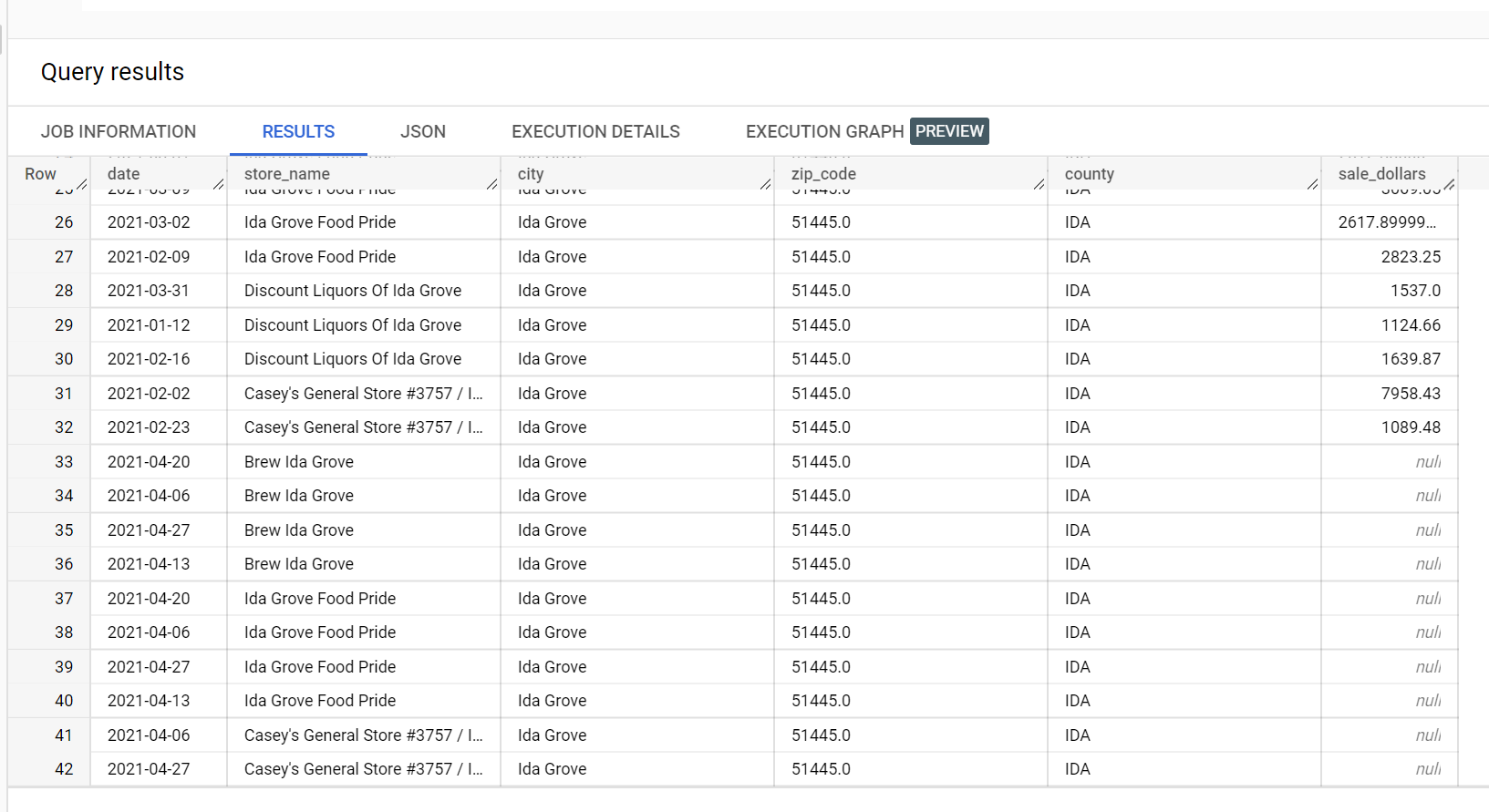
다음은 예측 결과에서 추출한 것입니다.
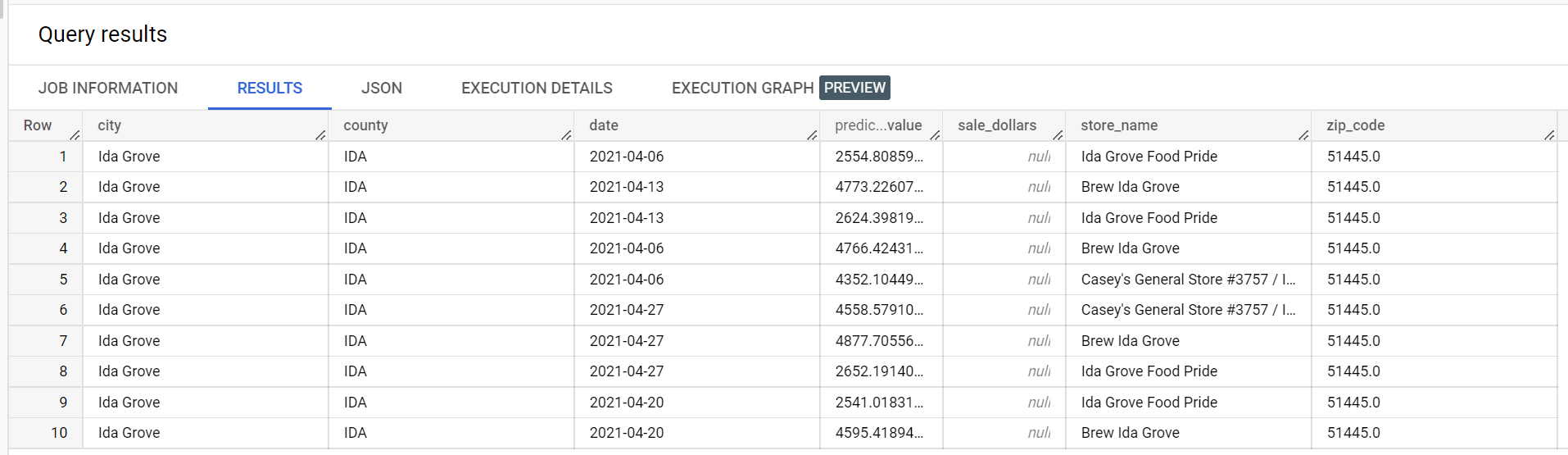
다음은 검증 오류에서 추출한 것입니다.

분위수 손실 최적화 모델의 일괄 예측 출력 예시
다음은 분위수 손실에 최적화된 모델의 일괄 예측 출력을 보여주는 예시입니다. 이 시나리오에서 예측 모델은 각 매장의 다음 14일 동안의 판매를 예측했습니다.
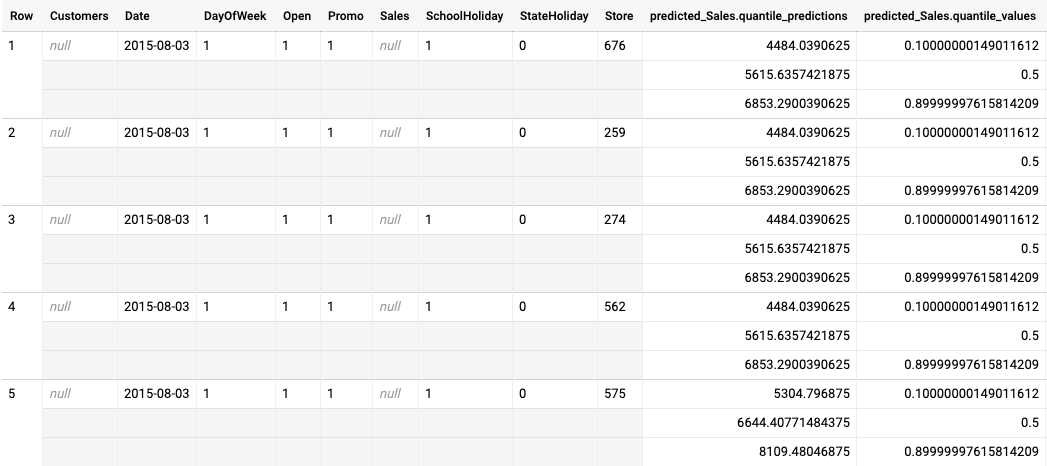
분위수 값은 predicted_Sales.quantile_values 열에 제공됩니다. 이 예시에서는 모델이 0.1, 0.5, 0.9 분위 수에서 값을 예측했습니다.
예측 값은 predicted_Sales.quantile_predictions 열에 제공됩니다.
predicted_Sales.quantile_values 열의 분위수 값에 매핑되는 판매 값의 배열입니다. 첫 번째 행에서 판매 값이 4484.04보다 작을 확률은 10%입니다. 판매 값이 5615.64보다 작을 확률은 50%입니다. 판매 값이 6853.29보다 작을 확률은 90%입니다. 첫 번째 행의 예측은 단일 값으로 표시되며 5615.64입니다.