使用資料集訓練 AutoML 模型時,Vertex AI 會將資料分成三部分:訓練、驗證和測試。建立資料分割時,主要目標是確保測試集能準確呈現實際工作環境資料。如此可確保評估指標提供的信號準確無誤,能忠實反映這個模型在處理實際資料時的成效。
本頁面說明 Vertex AI 如何使用訓練、驗證和測試資料集訓練 AutoML 模型。此外,本文也會說明如何控管資料在這三組之間的分割方式。分類和迴歸的資料分割演算法,與預測的資料分割演算法不同。
分類和迴歸的資料分割
資料分割的使用方式
訓練程序會使用以下資料分割:
模型試用
訓練集可用來訓練模型,並搭配不同的預先處理、架構和超參數選項組合。Vertex AI 會在驗證集上評估這些模型的品質,並透過這些模型來引導探索其他選項組合。驗證集也會用於從訓練期間的定期評估中,選取最佳檢查點。Vertex AI 會使用平行調整階段決定的最佳參數和架構,訓練兩個集成模型,如下所述。
模型評估
Vertex AI 會使用訓練和驗證集做為訓練資料,訓練評估模型。Vertex AI 會使用測試集,為這個模型產生最終的模型評估指標。這是程序中首次使用測試集。這種做法可確保最終評估指標能毫無偏誤地反映出最終訓練模型在實際工作環境中的效能。
提供模型
預設資料分割
根據預設,Vertex AI 會使用隨機分割演算法,將資料分成三種分割資料。Vertex AI 會隨機選取 80% 的資料列做為訓練集、10% 做為驗證集,另外 10% 則做為測試集。建議您為下列資料集採用預設分割比例:
- 隨時間保持不變。
- 相對平衡。
- 與用於正式版預測的資料類似。
如要使用預設資料分割,請在 Google Cloud 控制台中接受預設值,或將 API 的 split 欄位留空。
控制資料分割的選項
您可以採用下列其中一種方法,控制系統為每個分割選取的資料列:
請只選擇其中一個選項,並在訓練模型時做出選擇。 部分選項需要變更訓練資料 (例如資料分割資料欄或時間資料欄)。加入資料分割選項的資料,不代表您必須使用這些選項,訓練模型時仍可選擇其他選項。
如果出現下列情況,預設分配比例就不是最佳選擇:
您並非訓練預測模型,但資料具有時效性。
測試資料包含實際工作環境中不會出現的客群資料。
舉例來說,假設您要利用數家商店的購買資料來訓練模型,但這個模型的主要功用是為不在訓練資料中的商店做出預測。為確保模型能泛化至未曾出現的商店,請依商店區隔資料集。換句話說,測試集只能包含與驗證集不同的商店,而驗證集只能包含與訓練集不同的商店。
類別數量不平衡。
如果訓練資料中有某個類別的數量比其他類別更多,您可能就要在測試資料中手動加入更多少數類別的範例。Vertex AI 不會執行分層抽樣,因此測試集中包含的少數類別範例可能很少,甚至沒有任何相關內容。
隨機分割
隨機分割也稱為「數學分割」或「分數分割」。
根據預設,用於訓練、驗證和測試集的訓練資料百分比分別為 80%、10% 和 10%。如果使用 Google Cloud 控制台,您可以將百分比變更為加總為 100 的任何值。如果您使用 Vertex AI API,請使用總和為 1.0 的分數。
如要變更百分比 (分數),請使用 FractionSplit 物件定義分數。
Vertex AI 會隨機 (但決定性的) 選取列做為資料分割。若您對系統產生的資料分割內容不滿意,請手動分割或變更訓練資料。使用相同的訓練資料來訓練新模型,會產生相同的資料分割。
手動分割
手動分割也稱為「預先定義的分割」。
透過資料分割欄,您可以選取要用來進行訓練、驗證和測試的特定資料列。建立訓練資料時,請新增包含下列其中一個值 (需區分大小寫) 的資料欄:
TRAINVALIDATETESTUNASSIGNED
這個資料欄中的值必須是下列其中一種組合:
- 「
TRAIN」、「VALIDATE」和「TEST」中所有人 - 僅限
TEST和UNASSIGNED
每列都必須有這個資料欄的值,不能是空白字串。
舉例來說,如果指定所有集合:
"TRAIN","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "TRAIN","Roger","Rogers","123-45-6789" "VALIDATE","Sarah","Smith","333-33-3333"
只指定測試集:
"UNASSIGNED","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "UNASSIGNED","Roger","Rogers","123-45-6789" "UNASSIGNED","Sarah","Smith","333-33-3333"
資料分割欄可以有任何有效的欄名,其轉換類型可以是類別、文字或自動。
如果資料分割欄的值為 UNASSIGNED,Vertex AI 會自動將該資料列指派給訓練或驗證集。
在模型訓練期間,將資料欄指定為資料分割資料欄。
依時間順序分割
依時間順序分割也稱為「時間戳記分割」。
如果資料與時間有關,可以將其中一個資料欄指定為「時間」欄。Vertex AI 會使用「時間」欄分割資料,最早的資料列用於訓練,接下來的資料列用於驗證,最新的資料列則用於測試。
Vertex AI 會將每個資料列視為獨立且相同分布的訓練範例;設定「時間」欄不會改變這點。「時間」欄僅用於分割資料集。
如果指定時間欄,請為資料集中的每個資料列加入時間欄的值。請確認「時間」欄有足夠的相異值,驗證和測試集才不會空白。通常至少 20 個不同的值就足夠。
「時間」欄中的資料必須符合時間戳記轉換支援的格式。不過,「時間」欄可使用任何支援的轉換,因為轉換只會影響該欄在訓練時的使用方式,不會影響資料分割。
您也可以指定要指派給每個資料集的訓練資料百分比。
在模型訓練期間,將資料欄指定為時間資料欄。
預測用資料分割
根據預設,Vertex AI 會使用時間順序分割演算法,將預測資料分成三種資料分割。建議您使用預設分割。不過,如要控制哪些訓練資料列用於哪些分割,請使用手動分割。
資料分割的使用方式
訓練程序會使用以下資料分割:
模型試用
訓練集可用來訓練模型,並搭配不同的預先處理、架構和超參數選項組合。Vertex AI 會在驗證集上評估這些模型的品質,並透過這些模型來引導探索其他選項組合。驗證集也會用於從訓練期間的定期評估中,選取最佳檢查點。Vertex AI 會使用平行調整階段決定的最佳參數和架構,訓練兩個集成模型,如下所述。
模型評估
Vertex AI 會使用訓練和驗證集做為訓練資料,訓練評估模型。Vertex AI 會使用測試集,產生這個模型的最終模型評估指標。這是程序中首次使用測試集。這種做法可確保最終評估指標能毫無偏誤地反映出最終訓練模型在實際工作環境中的效能。
提供模型
Vertex AI 會使用訓練和驗證集訓練模型。系統會使用測試集驗證模型 (選取最佳檢查點)。測試集絕不會用於訓練,因為系統會根據測試集計算損失。您可以使用這個模型取得推論結果。
預設分割
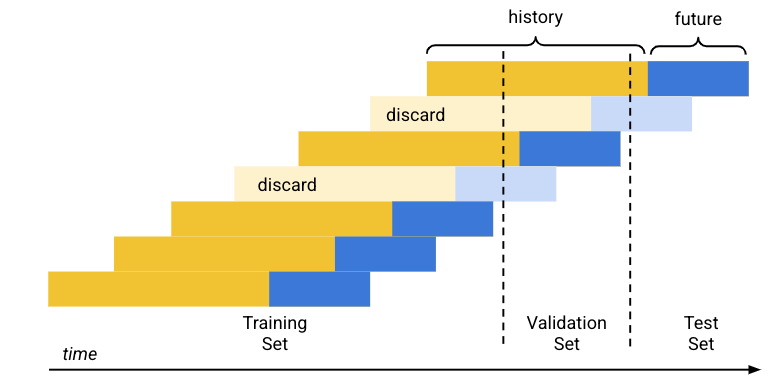
預設 (依時間順序) 資料分割方式的運作方式如下:
- Vertex AI 會依日期排序訓練資料。
- Vertex AI 會根據預先決定的百分比 (80/10/10),將訓練資料涵蓋的時間範圍分成三塊,分別對應一個訓練集。
- Vertex AI 會在每個時間序列的開頭新增空白資料列,讓模型從歷史記錄不足的資料列 (脈絡窗口) 學習。新增的資料列數是在訓練時設定的內容視窗大小。
Vertex AI 會使用在訓練時設定的預測範圍大小,針對該組資料集,使用未來資料 (預測範圍) 完全落入其中一個資料集的每個資料列。(為避免資料外洩,Vertex AI 會捨棄預測範圍跨越兩組的資料列)。
手動分割
透過資料分割欄,您可以選取要用來進行訓練、驗證和測試的特定資料列。建立訓練資料時,請新增包含下列其中一個值 (需區分大小寫) 的資料欄:
TRAINVALIDATETEST
每列都必須有這個資料欄的值,不能是空白字串。
例如:
"TRAIN","sku_id_1","2020-09-21","10" "TEST","sku_id_1","2020-09-22","23" "TRAIN","sku_id_2","2020-09-22","3" "VALIDATE","sku_id_2","2020-09-23","45"
資料分割欄可以有任何有效的欄名,其轉換類型可以是類別、文字或自動。
在模型訓練期間,將資料欄指定為資料分割資料欄。
請務必小心,避免時間序列之間發生資料外洩。