Vertex AI 使用 Shapley 值提供特征归因,这是一种合作博弈论算法,用于根据游戏结果为特定玩家分配积分。应用到机器学习模型中,就意味着每个模型特征都被视作游戏中的一个“玩家”,积分按特定推理结果的比例分配。对于结构化数据模型,Vertex AI 使用精确 Shapley 值的采样近似值,称为采样 Shapley。
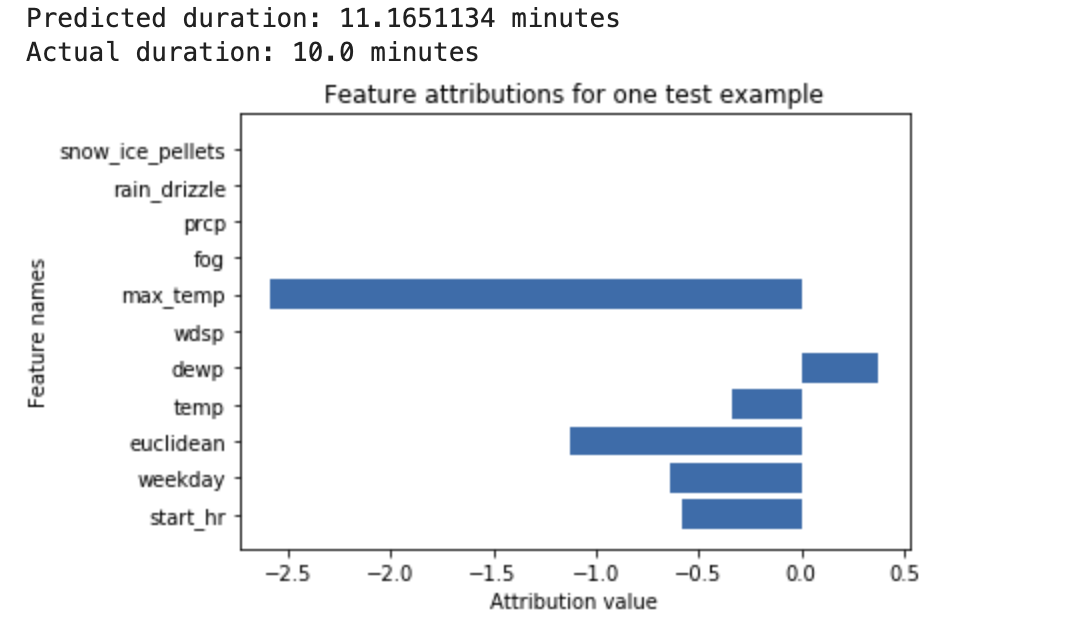
[[["易于理解","easyToUnderstand","thumb-up"],["解决了我的问题","solvedMyProblem","thumb-up"],["其他","otherUp","thumb-up"]],[["很难理解","hardToUnderstand","thumb-down"],["信息或示例代码不正确","incorrectInformationOrSampleCode","thumb-down"],["没有我需要的信息/示例","missingTheInformationSamplesINeed","thumb-down"],["翻译问题","translationIssue","thumb-down"],["其他","otherDown","thumb-down"]],["最后更新时间 (UTC):2025-09-04。"],[],[],null,["# Feature attributions for classification and regression\n\nIntroduction\n------------\n\n\nThis page provides a brief conceptual overview of the feature attribution\nmethods available with Vertex AI. For an in-depth technical\ndiscussion, see our [AI Explanations Whitepaper](https://storage.googleapis.com/cloud-ai-whitepapers/AI%20Explainability%20Whitepaper.pdf).\n\n\u003cbr /\u003e\n\nGlobal feature importance (model feature attributions) shows how each\nfeature impacts a model. The values are a percentage for each\nfeature: the higher the percentage, the more impact the feature had on model\ntraining. To view the global feature importance for your model, examine the\n[evaluation metrics](/vertex-ai/docs/tabular-data/classification-regression/evaluate-model).\n\nLocal feature attributions for time series models indicate how much each feature\nin the data contributed to the predicted result. Use this\ninformation to verify that the model behaves as expected, recognize bias in\nyour models, and get ideas for ways to improve your model and your training\ndata. When you request inferences, you\nget predicted values as appropriate for your model. When you request\n*explanations*, you get the inferences along with feature attribution\ninformation.\n\nConsider the following example: A deep neural network is trained to predict the\nduration of a bike ride, based on weather data and previous ride-sharing data.\nIf you request only inferences from this model, you get predicted durations of\nbike rides in number of minutes. If you request *explanations*, you get the\npredicted bike trip duration, along with an attribution score for each feature\nin your explanations request. The attribution scores show how much the feature\naffected the change in inference value, relative to the baseline value that\nyou specify. Choose a meaningful baseline that makes sense for your model -\nin this case, the median bike ride duration.\n\nYou can plot the feature attribution scores to see which features contributed\nmost strongly to the resulting inference:\n\nGenerate and query local feature attributions when performing an\n[online inference](/vertex-ai/docs/tabular-data/classification-regression/get-online-predictions)\njob or a [batch inference](/vertex-ai/docs/tabular-data/classification-regression/get-batch-predictions)\njob.\n\nAdvantages\n----------\n\n\nIf you inspect specific instances, and also aggregate feature attributions\nacross your training dataset, you can get deeper insight into how your model\nworks. Consider the following advantages:\n\n- **Debugging models**: Feature attributions can help detect issues in the data\n that standard model evaluation techniques would usually miss.\n\n- **Optimizing models**: You can identify and remove features that are less\n important, which can result in more efficient models.\n\n\u003cbr /\u003e\n\nConceptual limitations\n----------------------\n\n\nConsider the following limitations of feature attributions:\n\n- Feature attributions, including local feature importance for AutoML, are\n specific to individual inferences.\n Inspecting the feature attributions for an individual inference may provide\n good insight, but the insight may not be generalizable to the entire class for\n that individual instance, or the entire model.\n\n To get more generalizable insight for AutoML models, refer to the model\n feature importance. To get more generalizable insight for other models,\n aggregate attributions over subsets over your dataset, or the entire dataset.\n- Each attribution only shows how much the feature affected the inference for\n that particular example. A single attribution might not reflect the overall\n behavior of the model. To understand approximate model behavior on an entire\n dataset, aggregate attributions over the entire dataset.\n\n- Although feature attributions can help with model debugging, they don't\n always indicate clearly whether an issue arises from the model or from the\n data that the model is trained on. Use your best judgment, and diagnose common\n data issues to narrow the space of potential causes.\n\n- The attributions depend entirely on the model and data used to train the model.\n They can only reveal the patterns the model found in the data, and can't\n detect any fundamental relationships in the data. The presence or absence of a\n strong attribution to a certain feature doesn't mean there is or is not a\n relationship between that feature and the target. The attribution merely shows\n that the model is or is not using the feature in its inferences.\n\n- Attributions alone cannot tell if your model is fair, unbiased, or of sound\n quality. Carefully evaluate your training data and evaluation metrics in\n addition to the attributions.\n\nFor more information about limitations, see the\n[AI Explanations Whitepaper](https://storage.googleapis.com/cloud-ai-whitepapers/AI%20Explainability%20Whitepaper.pdf).\n\n\u003cbr /\u003e\n\nImproving feature attributions\n------------------------------\n\n\nThe following factors have the highest impact on feature attributions:\n\n- The attribution methods approximate the Shapley value. You can increase the precision of the approximation by increasing the number of paths for the sampled Shapley method. As a result, the attributions could change dramatically.\n- The attributions only express how much the feature affected the change in inference value, relative to the baseline value. Be sure to choose a meaningful baseline, relevant to the question you're asking of the model. Attribution values and their interpretation might change significantly as you switch baselines.\n\n\u003cbr /\u003e\n\nAlgorithm\n---------\n\n\nVertex AI provides feature attributions using *Shapley Values* , a cooperative\ngame theory algorithm that assigns credit to each player in a game for a\nparticular outcome. Applied to machine learning models, this means that each\nmodel feature is treated as a \"player\" in the game and credit is assigned in\nproportion to the outcome of a particular inference. For structured data\nmodels, Vertex AI uses a sampling approximation of exact Shapley Values called\n*Sampled Shapley*.\n\nFor in-depth information about how the sampled Shapley method works, read the paper\n[Bounding the Estimation Error of Sampling-based Shapley Value Approximation](https://arxiv.org/abs/1306.4265).\n\n\u003cbr /\u003e\n\nWhat's next\n-----------\n\n\nThe following resources provide further useful educational material:\n\n- [Interpretable Machine Learning: Shapley values](https://christophm.github.io/interpretable-ml-book/shapley.html)\n- [Introduction to Shapley values](https://www.kaggle.com/dansbecker/shap-values#Introduction)\n\n\u003cbr /\u003e"]]