Vertex AI의 NVIDIA Triton
Vertex AI는 NVIDIA GPU Cloud(NGC) - NVIDIA Triton 추론 서버 이미지로 게시된 커스텀 컨테이너에서 실행되는 Triton 추론 서버에 모델 배포를 지원합니다. NVIDIA의 Triton 이미지에는 커스텀 제공 컨테이너 이미지에 대한 Vertex AI 요구사항을 충족하는 모든 필수 패키지 및 구성이 포함되어 있습니다. 이미지에는 TensorFlow, PyTorch, TensorRT, ONNX, OpenVINO 모델 지원과 함께 Triton 추론 서버가 포함되어 있습니다. 이 이미지에는 또한 XGBoost, LightGBM, Scikit-Learn과 같은 ML 프레임워크 실행을 지원하는 FIL(포레스트 추론 라이브러리) 백엔드가 포함되어 있습니다.
Triton은 모델을 로드하고 표준 추론 프로토콜을 사용하는 모델 관리 REST 엔드포인트, 추론, 상태를 노출합니다. 모델을 Vertex AI에 배포하는 동안 Triton은 Vertex AI 환경을 인식하여 상태 점검 및 추론 요청에 Vertex AI 추론 프로토콜을 적용합니다.
다음은 NVIDIA Triton 추론 서버의 주요 기능 및 사용 사례를 요약한 목록입니다.
- 여러 딥 러닝 및 머신러닝 프레임워크 지원: Triton은 여러 모델 및 혼합된 프레임워크와 모델 형식의 배포를 지원합니다. 여기에는 XGBoost, LightGBM, Scikit-Learn, C++ 모델 형식의 모든 커스텀 Python 등의 프레임워크를 지원하는 TensorFlow(SavedModel과 GraphDef), PyTorch(TorchScript), TensorRT, ONNX, OpenVINO, FIL 백엔드가 포함됩니다.
- 동시 다중 모델 실행: Triton을 사용하면 여러 모델, 동일 모델의 여러 인스턴스, 또는 두 가지 모두가 GPU 0개 이상의 동일한 컴퓨팅 리소스에서 동시에 실행될 수 있습니다.
- 모델 앙상블(연결 또는 파이프라인): Triton 앙상블은 여러 모델이 서로간에 입력 및 출력 텐서가 연결된 파이프라인(또는 DAG, 방향성 비순환 그래프)으로 구성된 사용 사례를 지원합니다. 또한 Triton Python 백엔드를 사용하면 비즈니스 로직 스크립팅(BLS)에 정의된 모든 사전 처리, 사후 처리 또는 제어 흐름 로직을 포함할 수 있습니다.
- CPU 및 GPU 백엔드에서 실행: Triton은 CPU 및 GPU 포함 노드에 배포된 모델에 대한 추론을 지원합니다.
- 추론 요청의 동적 일괄 처리: 일괄 처리를 지원하는 모델을 위해 Triton에는 기본 제공되는 예약 및 일괄 처리 알고리즘이 포함되어 있습니다. 이러한 알고리즘은 추론 처리량 향상 및 GPU 사용률 증가를 위해 서버 측에서 개별 추론 요청을 일괄 처리로 동적으로 조합합니다.
NVIDIA Triton 추론 서버에 대한 자세한 내용은 Triton 문서를 참조하세요.
사용 가능한 NVIDIA Triton 컨테이너 이미지
다음 표에서는 NVIDIA NGC 카탈로그에서 사용 가능한 Triton Docker 이미지를 보여줍니다. 모델 프레임워크, 백엔드, 사용되는 컨테이너 이미지 크기를 기준으로 이미지를 선택합니다.
xx 및 yy는 각각 Triton의 주 버전과 부 버전을 나타냅니다.
| NVIDIA Triton 이미지 | 지원 |
|---|---|
xx.yy-py3 |
TensorFlow, PyTorch, TensorRT, ONNX, OpenVINO 모델 지원이 포함된 전체 컨테이너 |
xx.yy-pyt-python-py3 |
PyTorch 및 Python 백엔드만 |
xx.yy-tf2-python-py3 |
TensorFlow 2.x 및 Python 백엔드만 |
xx.yy-py3-min |
필요에 따라 Triton 컨테이너 맞춤설정 |
시작하기: NVIDIA Triton으로 추론 제공
다음 그림은 Vertex AI 추론에 대한 Triton의 고수준 아키텍처를 보여줍니다.
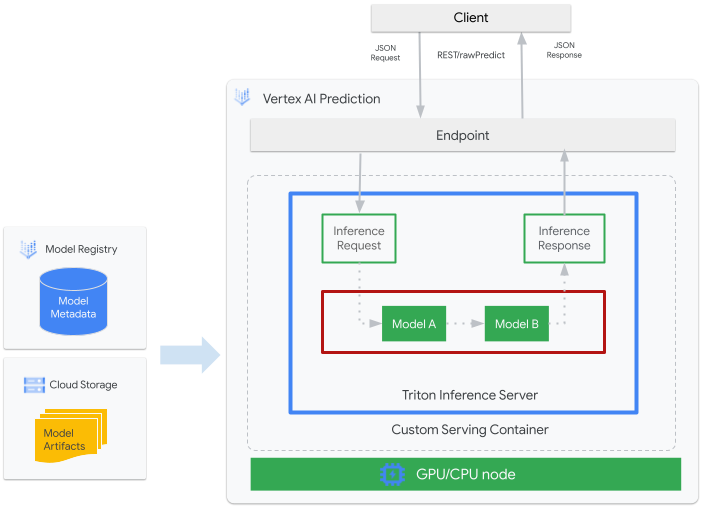
- Triton에서 제공되는 ML 모델이 Vertex AI Model Registry에 등록됩니다. 이 모델의 메타데이터는 Cloud Storage의 모델 아티팩트의 위치, 커스텀 제공 컨테이너, 해당 구성을 참조합니다.
- Vertex AI Model Registry의 모델이 CPU 및 GPU 포함 컴퓨팅 노드에서 커스텀 컨테이너로 Triton 추론 서버를 실행 중인 Vertex AI Inference 엔드포인트에 배포됩니다.
- 추론 요청은 Vertex AI 추론 엔드포인트를 통해 Triton 추론 서버에 도달하여 적절한 스케줄러로 라우팅됩니다.
- 백엔드가 일괄 요청에 제공된 입력을 사용하여 추론을 수행하고 응답을 반환합니다.
- Triton은 Vertex AI와 같은 배포 환경에 Triton을 통합할 수 있는 준비 상태 및 활성 상태 엔드포인트를 제공합니다.
이 튜토리얼에서는 Vertex AI에서 머신러닝 (ML) 모델을 배포하기 위해 NVIDIA Triton 추론 서버를 실행 중이고, 온라인 추론을 제공하는 커스텀 컨테이너를 사용하는 방법을 보여줍니다. COCO 2017 데이터 세트로 사전 학습된 TensorFlow Hub의 객체 감지 모델에서 추론을 제공하기 위해 Triton을 실행하는 컨테이너를 배포합니다. 그런 후 Vertex AI를 사용하여 이미지에서 객체를 감지할 수 있습니다.
노트북 형식으로 이 튜토리얼을 실행하려면 다음 단계를 따르세요.
Colab에서 열기 | Colab Enterprise에서 열기 | GitHub에서 보기 | Vertex AI Workbench에서 열기 |시작하기 전에
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API and Artifact Registry API APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API and Artifact Registry API APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
-
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init - Artifact Registry 문서에 따라 Docker를 설치합니다.
- LOCATION_ID: 이전 섹션에 지정된 대로 Artifact Registry 저장소의 리전
- PROJECT_ID: Google Cloud프로젝트 ID
컨테이너 이미지를 로컬에서 실행하려면 셸에서 다음 명령어를 실행합니다.
docker run -t -d -p 8000:8000 --rm \ --name=local_object_detector \ -e AIP_MODE=True \ LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference \ --model-repository MODEL_ARTIFACTS_REPOSITORY \ --strict-model-config=false이전 섹션에서 한 것처럼 다음을 바꿉니다.
- LOCATION_ID: 이전 섹션에 지정된 대로 Artifact Registry 저장소의 리전
- PROJECT_ID: Google Cloud의 ID입니다. 프로젝트
- MODEL_ARTIFACTS_REPOSITORY: 모델 아티팩트가 있는 Cloud Storage 경로
이 명령어는 컨테이너의 포트
8000을 로컬 환경의 포트8000으로 매핑하여 분리 모드에서 컨테이너를 실행합니다. NGC의 Triton 이미지는 포트8000을 사용하도록 Triton을 구성합니다.컨테이너 서버에 상태 점검을 보내려면 셸에서 다음 명령어를 실행합니다.
curl -s -o /dev/null -w "%{http_code}" http://localhost:8000/v2/health/ready성공하면 서버가 상태 코드를
200으로 반환합니다.다음 명령어를 실행하여 이전에 생성된 페이로드를 사용하여 컨테이너 서버에 추론 요청을 전송하고 추론 응답을 가져옵니다.
curl -X POST \ -H "Content-Type: application/json" \ -d @instances.json \ localhost:8000/v2/models/object_detector/infer | jq -c '.outputs[] | select(.name == "detection_classes")'이 요청에는 TensorFlow 객체 감지 예시에 포함된 테스트 이미지 중 하나가 사용됩니다.
성공하면 서버가 다음 추론을 반환합니다.
{"name":"detection_classes","datatype":"FP32","shape":[1,300],"data":[38,1,...,44]}컨테이너를 중지하려면 셸에서 다음 명령어를 실행합니다.
docker stop local_object_detector선택한 리전의 Artifact Registry로 푸시할 수 있도록 로컬 Docker에 설치 권한을 제공하려면 셸에서 다음 명령어를 실행합니다.
gcloud auth configure-docker LOCATION_ID-docker.pkg.dev- LOCATION_ID을 이전 섹션에서 저장소를 만든 리전으로 바꿉니다.
Artifact Registry에 바로 전에 빌드한 컨테이너 이미지를 푸시하려면 셸에서 다음 명령어를 실행합니다.
docker push LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference이전 섹션에서 한 것처럼 다음을 바꿉니다.
- LOCATION_ID: 이전 섹션에 지정된 대로 Artifact Registry 저장소의 Rhe 리전
- PROJECT_ID: Google Cloud프로젝트의 ID입니다.
- LOCATION_ID: Vertex AI를 사용하는 리전
- PROJECT_ID: Google Cloud프로젝트 ID
-
DEPLOYED_MODEL_NAME:
DeployedModel의 이름.DeployedModel의Model표시 이름도 사용할 수 있습니다. - LOCATION_ID: Vertex AI를 사용하는 리전
- ENDPOINT_NAME: 엔드포인트의 표시 이름
- LOCATION_ID: Vertex AI를 사용하는 리전
- ENDPOINT_NAME: 엔드포인트의 표시 이름
-
DEPLOYED_MODEL_NAME:
DeployedModel의 이름.DeployedModel의Model표시 이름도 사용할 수 있습니다. -
MACHINE_TYPE: (선택사항) 이 배포의 각 노드에 사용되는 머신 리소스. 기본 설정은
n1-standard-2입니다. 머신 유형에 대해 자세히 알아보세요. - MIN_REPLICA_COUNT: 이 배포의 최소 노드 수. 추론 로드 시 필요에 따라 노드 수를 최대 노드 수까지 늘리거나 이 노드 수까지 줄일 수 있습니다.
- MAX_REPLICA_COUNT: 이 배포의 최대 노드 수. 추론 로드 시 필요에 따라 이 노드 수를 노드 수까지 늘리거나 최소 노드 수까지 줄일 수 있습니다.
ACCELERATOR_COUNT: 작업을 실행하는 각 머신에 연결할 가속기 수. 일반적으로 1입니다. 지정하지 않은 경우 기본값은 1입니다.
ACCELERATOR_TYPE: GPU 제공을 위한 가속기 구성을 관리합니다. 또한 Compute Engine 머신 유형으로 모델을 배포할 때는 GPU 가속기를 선택할 수 있고 유형을 지정해야 합니다. 선택지는
nvidia-tesla-a100,nvidia-tesla-p100,nvidia-tesla-p4,nvidia-tesla-t4,nvidia-tesla-v100입니다.- LOCATION_ID: Vertex AI를 사용하는 리전
- ENDPOINT_NAME: 엔드포인트의 표시 이름
엔드포인트에서 모델을 배포 해제하고 엔드포인트를 삭제하려면 셸에서 다음 명령어를 실행합니다.
ENDPOINT_ID=$(gcloud ai endpoints list \ --region=LOCATION_ID \ --filter=display_name=ENDPOINT_NAME \ --format="value(name)") DEPLOYED_MODEL_ID=$(gcloud ai endpoints describe $ENDPOINT_ID \ --region=LOCATION_ID \ --format="value(deployedModels.id)") gcloud ai endpoints undeploy-model $ENDPOINT_ID \ --region=LOCATION_ID \ --deployed-model-id=$DEPLOYED_MODEL_ID gcloud ai endpoints delete $ENDPOINT_ID \ --region=LOCATION_ID \ --quietLOCATION_ID을 이전 섹션에서 모델을 만든 리전으로 바꿉니다.
모델을 삭제하려면 셸에서 다음 명령어를 실행합니다.
MODEL_ID=$(gcloud ai models list \ --region=LOCATION_ID \ --filter=display_name=DEPLOYED_MODEL_NAME \ --format="value(name)") gcloud ai models delete $MODEL_ID \ --region=LOCATION_ID \ --quietLOCATION_ID을 이전 섹션에서 모델을 만든 리전으로 바꿉니다.
Artifact Registry 저장소 및 그 안의 컨테이너 이미지를 삭제하려면 셸에서 다음 명령어를 실행합니다.
gcloud artifacts repositories delete getting-started-nvidia-triton \ --location=LOCATION_ID \ --quietLOCATION_ID을 이전 섹션에서 Artifact Registry 저장소를 만든 리전으로 바꿉니다.
- Triton 커스텀 컨테이너는 Vertex Explainable AI 또는 Vertex AI Model Monitoring과 호환되지 않습니다.
- Vertex AI에서 NVIDIA Triton 추론 서버를 사용하는 배포 패턴에 대해 자세히 알아보려면 NVIDIA Triton 노트북 튜토리얼을 참고하세요.
이 튜토리얼에서는 Cloud Shell을 사용하여 Google Cloud와 상호작용하는 것이 좋습니다. Cloud Shell 대신 다른 Bash 셸을 사용하려면 다음 추가 구성을 수행하세요.
컨테이너 이미지 빌드 및 푸시
커스텀 컨테이너를 사용하려면 커스텀 컨테이너 요구사항을 충족하는 Docker 컨테이너 이미지를 지정해야 합니다. 이 섹션에서는 컨테이너 이미지를 만들고 이를 Artifact Registry에 푸시하는 방법을 설명합니다.
모델 아티팩트 다운로드
모델 아티팩트는 추론 제공을 위해 사용할 수 있는 ML 학습으로 생성되는 파일입니다. 여기에는 최소한 학습된 ML 모델의 구조 및 가중치가 포함됩니다. 모델 아티팩트의 형식은 학습에 사용하는 ML 프레임워크에 따라 달라집니다.
이 튜토리얼에서는 모델을 처음부터 학습하는 대신 COCO 2017 데이터 세트에서 학습된 TensorFlow Hub에서 객체 감지 모델을 다운로드합니다.
Triton은 TensorFlow SavedModel 형식을 제공하기 위해 모델 저장소가 다음 구조로 구성되어 있기를 기대합니다.
└── model-repository-path
└── model_name
├── config.pbtxt
└── 1
└── model.savedmodel
└── <saved-model-files>
config.pbtxt 파일은 모델에 대한 모델 구성을 설명합니다. 기본적으로 필요한 설정이 포함된 모델 구성 파일을 제공해야 합니다. 하지만 Triton이 --strict-model-config=false 옵션으로 시작된 경우에는 경우에 따라 Triton에서 모델 구성이 자동으로 생성될 수 있고 명시적으로 제공할 필요가 없습니다.
특히 TensorRT, TensorFlow SavedModel, ONNX 모델은 Triton이 모든 필수 설정을 자동으로 파생할 수 있기 때문에 모델 구성 파일을 필요로 하지 않습니다. 다른 모든 모델 유형은 모델 구성 파일을 제공해야 합니다.
# Download and organize model artifacts according to the Triton model repository spec
mkdir -p models/object_detector/1/model.savedmodel/
curl -L "https://tfhub.dev/tensorflow/faster_rcnn/resnet101_v1_640x640/1?tf-hub-format=compressed" | \
tar -zxvC ./models/object_detector/1/model.savedmodel/
ls -ltr ./models/object_detector/1/model.savedmodel/
모델을 로컬로 다운로드한 후 모델 저장소가 다음과 같이 구성됩니다.
./models
└── object_detector
└── 1
└── model.savedmodel
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.index
모델 아티팩트를 Cloud Storage 버킷에 복사
모델 구성 파일을 포함하는 다운로드한 모델 아티펙트가 Vertex AI 모델 리소스를 만들 때 사용할 수 있는 MODEL_ARTIFACTS_REPOSITORY에 지정된 Cloud Storage 버킷에 푸시됩니다.
gcloud storage cp ./models/object_detector MODEL_ARTIFACTS_REPOSITORY/ --recursive
Artifact Registry 저장소 만들기
다음 섹션에서 만들 컨테이너 이미지를 저장할 Artifact Registry 저장소를 만듭니다.
프로젝트에 Artifact Registry API 서비스를 사용 설정하세요.
gcloud services enable artifactregistry.googleapis.com
셸에서 다음 명령어를 실행하여 Artifact Registry 저장소를 만듭니다.
gcloud artifacts repositories create getting-started-nvidia-triton \
--repository-format=docker \
--location=LOCATION_ID \
--description="NVIDIA Triton Docker repository"
LOCATION_ID을 Artifact Registry의 컨테이너 이미지 저장 리전으로 바꿉니다. 나중에 이 리전과 일치하는 위치 엔드포인트에서 Vertex AI 모델 리소스를 만들어야 하므로, us-central1과 같이 Vertex AI에 위치 엔드포인트가 있는 리전을 선택합니다.
작업이 완료되면 명령어가 다음을 출력합니다.
Created repository [getting-started-nvidia-triton].
컨테이너 이미지 빌드
NVIDIA에서 Triton을 실행 중인 컨테이너 이미지를 빌드할 수 있도록 Docker 이미지를 제공하고 제공에 대한 Vertex AI 커스텀 컨테이너 요구사항에 맞게 조정합니다. docker를 사용하여 이미지를 가져오고 이미지가 게시되는 Artifact Registry 경로에 태그를 지정할 수 있습니다.
NGC_TRITON_IMAGE_URI="nvcr.io/nvidia/tritonserver:22.01-py3"
docker pull $NGC_TRITON_IMAGE_URI
docker tag $NGC_TRITON_IMAGE_URI LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference
다음을 바꿉니다.
이 명령어는 몇 분 동안 실행될 수 있습니다.
추론 요청 테스트를 위한 페이로드 파일 준비
컨테이너 서버에 추론 요청을 전송하려면 Python을 사용하는 샘플 이미지 파일로 페이로드를 준비합니다. 다음 python 스크립트를 실행하여 페이로드 파일을 생성합니다.
import json
import requests
# install required packages before running
# pip install pillow numpy --upgrade
from PIL import Image
import numpy as np
# method to generate payload from image url
def generate_payload(image_url):
# download image from url and resize
image_inputs = Image.open(requests.get(image_url, stream=True).raw)
image_inputs = image_inputs.resize((200, 200))
# convert image to numpy array
image_tensor = np.asarray(image_inputs)
# derive image shape
image_shape = [1] + list(image_tensor.shape)
# create payload request
payload = {
"id": "0",
"inputs": [
{
"name": "input_tensor",
"shape": image_shape,
"datatype": "UINT8",
"parameters": {},
"data": image_tensor.tolist(),
}
],
}
# save payload as json file
payload_file = "instances.json"
with open(payload_file, "w") as f:
json.dump(payload, f)
print(f"Payload generated at {payload_file}")
return payload_file
if __name__ == '__main__':
image_url = "https://github.com/tensorflow/models/raw/master/research/object_detection/test_images/image2.jpg"
payload_file = generate_payload(image_url)
Python 스크립트가 페이로드를 생성하고 다음 응답을 출력합니다.
Payload generated at instances.json
로컬로 컨테이너 실행(선택사항)
컨테이너 이미지를 Vertex AI와 함께 사용하기 위해 Artifact Registry로 푸시하기 전에 로컬 환경에서 컨테이너로 실행하여 서버가 예상한 대로 작동하는지 확인할 수 있습니다.
{kind=link}
컨테이너 이미지를 Artifact Registry에 푸시
Artifact Registry에 액세스하도록 Docker를 구성합니다. 그런 후 컨테이너 이미지를 Artifact Registry 저장소에 푸시합니다.
모델 배포
이 섹션에서는 모델과 엔드포인트를 만든 다음 모델을 엔드포인트에 배포합니다.
모델 만들기
Triton을 실행하는 커스텀 컨테이너가 사용되는 Model 리소스를 만들려면 gcloud ai models upload 명령어를 사용합니다.
모델을 만들기 전에 커스텀 컨테이너 설정을 읽고 컨테이너에 선택사항인 sharedMemorySizeMb, startupProbe, healthProbe 필드를 지정해야 하는지 알아보세요.
gcloud ai models upload \
--region=LOCATION_ID \
--display-name=DEPLOYED_MODEL_NAME \
--container-image-uri=LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference \
--artifact-uri=MODEL_ARTIFACTS_REPOSITORY \
--container-args='--strict-model-config=false'
--container-args='--strict-model-config=false' 인수는 Triton이 모델 구성을 자동으로 생성하도록 허용합니다.
엔드포인트 만들기
온라인 추론 제공을 위해 모델을 사용하려면 먼저 모델을 엔드포인트에 배포해야 합니다. 기존 엔드포인트에 모델을 배포하는 경우 이 단계를 건너뛸 수 있습니다. 다음 예시에서는 gcloud ai endpoints create 명령어를 사용합니다.
gcloud ai endpoints create \
--region=LOCATION_ID \
--display-name=ENDPOINT_NAME
다음을 바꿉니다.
Google Cloud CLI 도구가 엔드포인트를 만드는 데 몇 초 정도 걸릴 수 있습니다.
엔드포인트에 모델 배포
엔드포인트가 준비되면 엔드포인트에 모델을 배포합니다. 엔드포인트에 모델을 배포하면 서비스가 물리적 리소스를 Triton 실행 모델과 연결하여 온라인 추론을 제공합니다.
다음 예시에서는 gcloud ai endpoints deploy-model 명령어를 사용하여 GPU에 Triton을 실행하는 endpoint에 Model을 배포하여 여러 DeployedModel 리소스 간 트래픽을 분할하지 않고 추론 제공을 가속화합니다.
ENDPOINT_ID=$(gcloud ai endpoints list \ --region=LOCATION_ID\ --filter=display_name=ENDPOINT_NAME\ --format="value(name)") MODEL_ID=$(gcloud ai models list \ --region=LOCATION_ID\ --filter=display_name=DEPLOYED_MODEL_NAME\ --format="value(name)") gcloud ai endpoints deploy-model $ENDPOINT_ID \ --region=LOCATION_ID\ --model=$MODEL_ID \ --display-name=DEPLOYED_MODEL_NAME\ --machine-type=MACHINE_TYPE\ --min-replica-count=MIN_REPLICA_COUNT\ --max-replica-count=MAX_REPLICA_COUNT\ --accelerator=count=ACCELERATOR_COUNT,type=ACCELERATOR_TYPE\ --traffic-split=0=100
다음을 바꿉니다.
Google Cloud CLI 도구로 모델을 엔드포인트에 배포하려면 몇 초 정도 걸릴 수 있습니다. 모델이 성공적으로 배포되면 이 명령어가 다음 출력을 표시합니다.
Deployed a model to the endpoint xxxxx. Id of the deployed model: xxxxx.
배포된 모델에서 온라인 추론 가져오기
Vertex AI 추론 엔드포인트를 통해 모델을 호출하려면 표준 추론 요청 JSON 객체
또는 바이너리 확장자가 있는 추론 요청 JSON 객체
를 사용하여 추론 요청의 형식을 지정하고 Vertex AI REST rawPredict 엔드포인트에 요청을 제출합니다.
다음 예시에서는 gcloud ai endpoints raw-predict 명령어를 사용합니다.
ENDPOINT_ID=$(gcloud ai endpoints list \
--region=LOCATION_ID \
--filter=display_name=ENDPOINT_NAME \
--format="value(name)")
gcloud ai endpoints raw-predict $ENDPOINT_ID \
--region=LOCATION_ID \
--http-headers=Content-Type=application/json \
--request=@instances.json
다음을 바꿉니다.
엔드포인트가 유효한 요청에 대해 다음 응답을 반환합니다.
{
"id": "0",
"model_name": "object_detector",
"model_version": "1",
"outputs": [{
"name": "detection_anchor_indices",
"datatype": "FP32",
"shape": [1, 300],
"data": [2.0, 1.0, 0.0, 3.0, 26.0, 11.0, 6.0, 92.0, 76.0, 17.0, 58.0, ...]
}]
}
삭제
Vertex AI 요금 및 Artifact Registry 요금이 계속 청구되지 않게 하려면 이 튜토리얼에서 만든 Google Cloud 리소스를 삭제합니다.